引言
继上篇 Rust 实战丨倒排索引,本篇我们将参考《Rust 程序设计(第二版)》中并发编程篇章来实现高并发构建倒排索引。
本篇主要分为以下几个部分:
- 功能展示:展示我们最终实现的 2 个工具的效果(构建索引、搜索功能)
- 阅读源码:阅读书中源码的实现,理清大体思路。
- 构建索引:实战构建索引的每个具体环节,并对核心逻辑进行解释和阐述缘由。
- 搜索功能:这是书中未曾提供的功能,笔者根据自身理解,对齐上篇提供的功能,实现了一个搜索功能。
能学到:
- Rust 各种迭代器的使用
- Rust 文件常用操作
- Rust 字符串常用操作
- Rust channel 实战
- Rust 并发编程
- 多路合并文件实际应用
- 使用
byteorder进行位操作 - 使用
clap进行 CLI 开发 - 终端高亮输出
- 深入理解倒排索引高性能的核心细节
阅读建议
本篇内容较为冗长,涉及到的细节讲解可能比较啰嗦,推荐直接阅读源码,然后对不理解的地方再来本篇对应的章节进行阅读。
完成源码位于:https://github.com/hedon-rust-road/inverted-index-concurrency
版本声明
- Rust: 1.76
- byteordrr: 1.5.0
- clap: 4.5.0
- 运行环境:macbookPro Apple M2 Max
功能展示
create.rs
bash
Usage: create [OPTIONS] <FILENAMES>...
Arguments:
<FILENAMES>...
Options:
-s, --single-threaded Default false
-h, --help Print help指定文件目录,构建索引,可以使用 -s 使用单线程构建,默认使用并发构建。
执行示例如下:
bash
➜ inverted-index-concurrency git:(master) ✗ cargo run --bin create ./texts
Finished dev [unoptimized + debuginfo] target(s) in 0.08s
Running `/Users/wangjiahan/rust-target/debug/create ./texts`
indexed document 0:"./texts/text1.txt", 22 bytes, 5 words
indexed document 1:"./texts/text3.txt", 27 bytes, 5 words
indexed document 2:"./texts/text2.txt", 39 bytes, 6 words
word count: 16
351 bytes main, 736 bytes total
wrote file "./tmp00000001.dat"search.rs
bash
Usage: search --index-file <INDEX_FILE> --term <TERM>
Options:
-i, --index-file <INDEX_FILE> Specify index file path
-t, --term <TERM> Specify search term
-h, --help Print help指定索引文件和搜索词来进行搜索。
执行示例如下:

阅读源码
书中的源码位于:fingertips
第一部分我们先来阅读源码,书中展示了这样一张图:
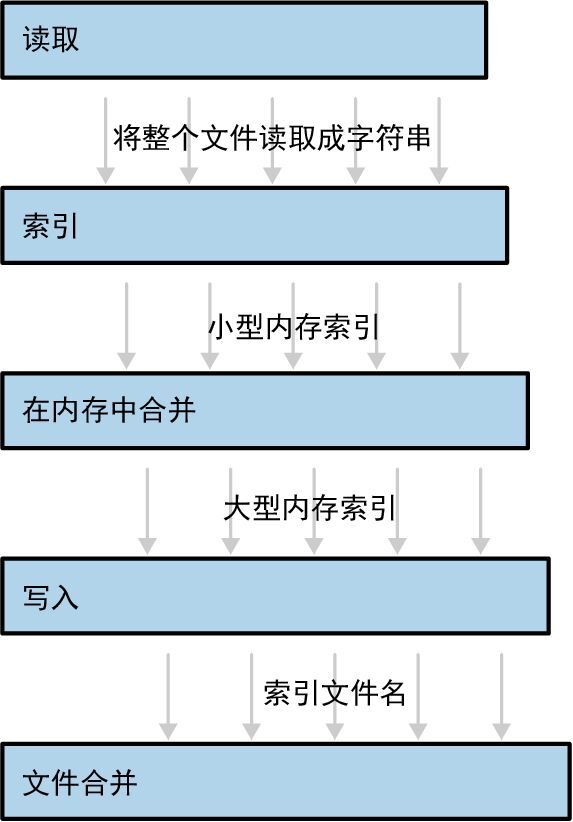
从这张图我们大概可以猜想本案例中构建并发索引的过程可能是:
- 读取文件内容;
- 根据文件内容构建索引;
- 多个索引进行合并;
- 将索引写入文件;
- 多个索引文件进行合并。
按照这个思路的指引,我们打开源码,从 main.rs 的 main() 出发:
rust
fn main() {
let mut single_threaded = false;
let mut filenames = vec![];
// 命令行参数解析
{
let mut ap = ArgumentParser::new();
ap.set_description("Make an inverted index for searching documents.");
ap.refer(&mut single_threaded).add_option(
&["-1", "--single-threaded"],
StoreTrue,
"Do all the work on a single thread.",
);
ap.refer(&mut filenames).add_argument(
"filenames",
Collect,
"Names of files/directories to index. \
For directories, all .txt files immediately \
under the directory are indexed.",
);
ap.parse_args_or_exit();
}
// 构建索引
match run(filenames, single_threaded) {
Ok(()) => {}
Err(err) => println!("error: {}", err),
}
}- 解析命令行参数,这里使用
argparse这个比较古老的 crate 来解析,现在一般是使用clap。single_threaded:是否使用单线程,默认是多线程。filenames: 指定的文本文件或目录。
run函数执行构建索引。
看一下 run:
rust
/// Generate an index for a bunch of text files.
fn run(filenames: Vec<String>, single_threaded: bool) -> io::Result<()> {
let output_dir = PathBuf::from(".");
let documents = expand_filename_arguments(filenames)?;
if single_threaded {
run_single_threaded(documents, output_dir)
} else {
run_pipeline(documents, output_dir)
}
}- 单线程:run_single_threaded
- 多线程:run_pipeline
先从简单看,单线程,忽略掉源码中定义的特殊数据结构,可以发现跟我们上篇介绍的简单版倒排索引思路基本是一致的,只不过本案例中数据是从文件中读,最后又会将索引写入到文件中。
rust
fn run_single_threaded(documents: Vec<PathBuf>, output_dir: PathBuf) -> io::Result<()> {
let mut accumulated_index = InMemoryIndex::new();
let mut merge = FileMerge::new(&output_dir);
let mut tmp_dir = TmpDir::new(&output_dir);
// 迭代每个文本文件
for (doc_id, filename) in documents.into_iter().enumerate() {
// 打开文件,并将内容读取到 `text` 上
let mut f = File::open(filename)?;
let mut text = String::new();
f.read_to_string(&mut text)?;
// 构建索引
let index = InMemoryIndex::from_single_document(doc_id, text);
accumulated_index.merge(index);
if accumulated_index.is_large() {
// 当索引足够大的时候,将其写到文件中
let file = write_index_to_tmp_file(accumulated_index, &mut tmp_dir)?;
merge.add_file(file)?;
accumulated_index = InMemoryIndex::new();
}
}
// 将最后一个索引写入到文件中
if !accumulated_index.is_empty() {
let file = write_index_to_tmp_file(accumulated_index, &mut tmp_dir)?;
merge.add_file(file)?;
}
merge.finish()
}再来看本文的重头戏,多线程:
rust
fn run_pipeline(documents: Vec<PathBuf>, output_dir: PathBuf) -> io::Result<()> {
// 将构建索引分为 5 个过程
let (texts, h1) = start_file_reader_thread(documents);
let (pints, h2) = start_file_indexing_thread(texts);
let (gallons, h3) = start_in_memory_merge_thread(pints);
let (files, h4) = start_index_writer_thread(gallons, &output_dir);
let result = merge_index_files(files, &output_dir);
// 等待所有线程执行完毕
let r1 = h1.join().unwrap();
h2.join().unwrap();
h3.join().unwrap();
let r4 = h4.join().unwrap();
r1?;
r4?;
result
}首先将索引构建分成 5 个阶段:
1. start_file_reader_thread
就是从文件中读取文本信息,并将其扔进 Receiver<String> channel 中,传到下一个阶段。
rust
fn start_file_reader_thread(
documents: Vec<PathBuf>,
) -> (Receiver<String>, JoinHandle<io::Result<()>>) {
let (sender, receiver) = channel();
let handle = spawn(move || {
for filename in documents {
let mut f = File::open(filename)?;
let mut text = String::new();
// 读取文件内容
f.read_to_string(&mut text)?;
if sender.send(text).is_err() {
break;
}
}
Ok(())
});
(receiver, handle)
}2. start_file_indexing_thread
从第 1 步传过来的文本信息中调用 InMemoryIndex::from_single_document 构建索引。
rust
fn start_file_indexing_thread(
texts: Receiver<String>,
) -> (Receiver<InMemoryIndex>, JoinHandle<()>) {
let (sender, receiver) = channel();
let handle = spawn(move || {
for (doc_id, text) in texts.into_iter().enumerate() {
// 构建索引
let index = InMemoryIndex::from_single_document(doc_id, text);
if sender.send(index).is_err() {
break;
}
}
});
(receiver, handle)
}3. start_in_memory_merge_thread
将第 2 步构建的单一索引进行合并,并将合并后的索引传到下一个阶段。
rust
fn start_in_memory_merge_thread(
file_indexes: Receiver<InMemoryIndex>,
) -> (Receiver<InMemoryIndex>, JoinHandle<()>) {
let (sender, receiver) = channel();
let handle = spawn(move || {
let mut accumulated_index = InMemoryIndex::new();
for fi in file_indexes {
// 将索引进行合并
accumulated_index.merge(fi);
if accumulated_index.is_large() {
// 如果索引大小到达阈值,则传到下一阶段
if sender.send(accumulated_index).is_err() {
return;
}
accumulated_index = InMemoryIndex::new();
}
}
if !accumulated_index.is_empty() {
let _ = sender.send(accumulated_index);
}
});
(receiver, handle)
}4. start_index_writer_thread
将第 3 步传来的内存索引写入到临时文件中。
rust
fn start_index_writer_thread(
big_indexes: Receiver<InMemoryIndex>,
output_dir: &Path,
) -> (Receiver<PathBuf>, JoinHandle<io::Result<()>>) {
let (sender, receiver) = channel();
let mut tmp_dir = TmpDir::new(output_dir);
let handle = spawn(move || {
for index in big_indexes {
// 将索引写入临时文件中
let file = write_index_to_tmp_file(index, &mut tmp_dir)?;
if sender.send(file).is_err() {
break;
}
}
Ok(())
});
(receiver, handle)
}5. merge_index_files
将临时文件进行合并,生成最终的索引文件。
rust
fn merge_index_files(files: Receiver<PathBuf>, output_dir: &Path) -> io::Result<()> {
let mut merge = FileMerge::new(output_dir);
for file in files {
merge.add_file(file)?;
}
merge.finish()
}这 5 个步骤跟书中给出的示意图基本一致,我们再来看 run_pipeline 是如何合并并行的:
rust
// 使用 join() 等待所有线程完成
let r1 = h1.join().unwrap();
h2.join().unwrap();
h3.join().unwrap();
let r4 = h4.join().unwrap();
// 阶段 2 和阶段 3 都是纯内存操作,不会有错误
// 阶段 1 是读文件,阶段 4 是写文件,所以有可能会报错
r1?;
r4?;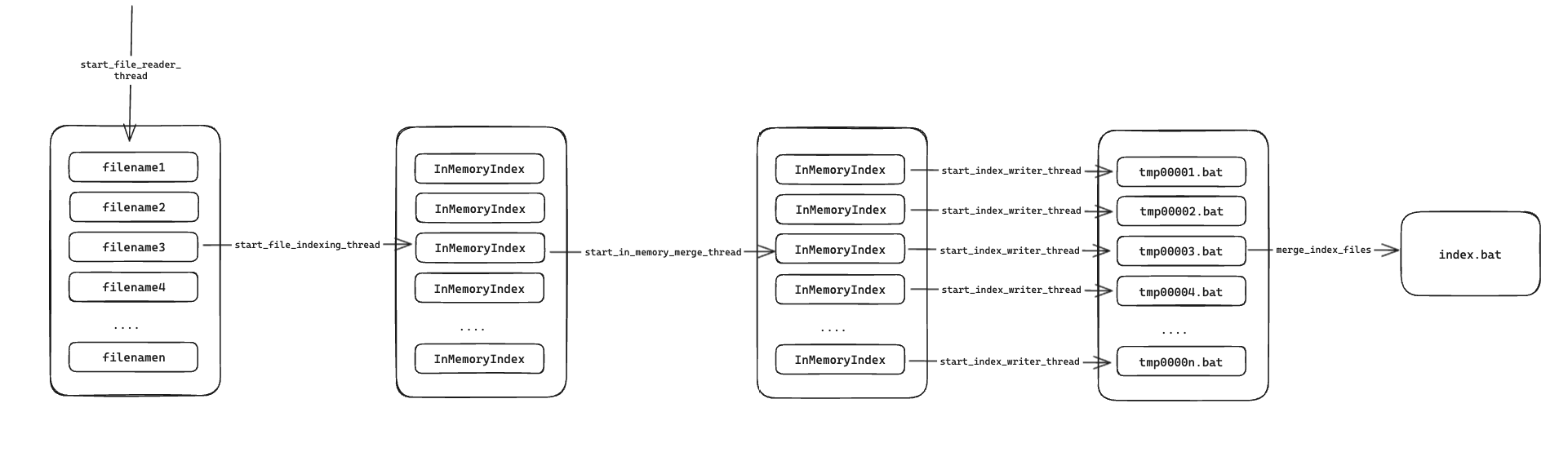
源码阅读部分差不多就到这了,大的思想架构你应该都能 Get 到了,其中每个数据结构的具体实现细节,我们在后面的实战中进行拆解。
构建索引
代码结构
书中源码代码结构如下所示:
➜ fingertips git:(master) ✗ tree
.
├── Cargo.lock
├── Cargo.toml
├── LICENSE-MIT
├── README.md
├── src
│ ├── index.rs
│ ├── main.rs
│ ├── merge.rs
│ ├── read.rs
│ ├── tmp.rs
│ └── write.rs书中给出的源码并没有实现使用构建好的索引文件进行搜索的功能,笔者将在此基础上实现该功能,所以对代码结构进行了简单的调整:
➜ inverted_index git:(master) ✗ tree
.
├── Cargo.lock
├── Cargo.toml
├── index.bat
├── src
│ ├── bin
│ │ ├── create.rs
│ │ └── search.rs
│ ├── index.rs
│ ├── lib.rs
│ ├── merge.rs
│ ├── read.rs
│ ├── tmp.rs
│ └── write.rs
└── texts
├── text1.txt
├── text2.txt
└── text3.txt可以看到我将核心代码从 bin 改成了 lib ,这是为了支持我后面要实现的两个 bin:
create: 构建索引,基本上就是源代码中的main.rssearch: 基于生成的索引文件实现搜索功能
texts 是我提供的文本文件样例。
src 目录中的代码阅读顺序及功能划分如下:
index: 定义了内存索引数据结构 InMemoryIndex,实现了从文件内容中构建内存索引的基本逻辑,也实现了从索引文件重建内存索引的功能。tmp: 定义了临时目录数据结构 TmpDir,用于存放临时索引文件。write: 定义了索引文件写入器 IndexFileWriter,实现了将 InMemoryIndex 写入文件中的逻辑。merge: 定义了文件合并器 FileMerge,用于合并 TmpDir 的所有索引文件。read: 定义了索引文件读取器 IndexFileWrite,实现了解析索引文件的逻辑。
项目准备
bash
cargo new --lib inverted_index_concurrencyCargo.toml
toml
[package]
name = "inverted-index-concurrency"
version = "0.1.0"
edition = "2021"
license = "mit"
authors = ["hedon"]
description = "a tool to concurrently build an inverted index."
[[bin]]
name="create"
path="src/bin/create.rs"
[[bin]]
name="search"
path="src/bin/search.rs"
[dependencies]
byteorder = "1.5.0"
clap = { version = "4.5.4", features = ["derive"] }lib.rs
rust
pub mod index;
pub mod merge;
pub mod read;
pub mod tmp;
pub mod write;在 lib.rs 中我们将这 5 个 mod 公开出去,这样就可以给 bin 目录中的 crate.rs 和 search.rs 使用了。
index.rs
完整源码:index.rs
第一部分是内存索引的构建。
tokenize
我们先定义一个分词函数:
rust
fn tokenize(text: &str) -> Vec<(&str, usize, usize)> {
let mut res = Vec::new();
let mut token_start = None;
for (idx, ch) in text.char_indices() {
match (ch.is_alphanumeric(), token_start) {
(true, None) => token_start = Some(idx), // 每个单词的开始
(false, Some(start)) => { // 每个单词的结尾
res.push((&text[start..idx], start, idx - 1));
token_start = None
}
_ => {}
}
}
if let Some(start) = token_start {
res.push((&text[start..], start, text.len() - 1))
}
res
}这个分词函数跟书中源码提供的不一样,为了实现文本高亮,我们需要记录每个分词在原文本中的起始位置和结束位置。它的核心逻辑如下:
-
通过
char_indices()获取text的字符迭代器,这是一种懒加载的方法,避免一次性将所有 char 加载到内存中。 -
匹配
(ch.is_alphanumeric(), token_start):- 如果是
(true, None)则表示这是一个单词的开始,我们纪录其开始的位置Some(idx); - 如果是
(false, Some(idx))则表示这是一个单词的结束,我们将其加入到res中,并记录起始位置和结束位置。 - 其他情况,不做处理,要么是非法字符,要么是处于单词中间。
从这个简单的理解中,你应该可以感受到 Rust 中 match pattern 的强大和便捷了,666 👍🏻
- 如果是
struct: InMemoryIndex
在 index.rs 中,我们定义了三个数据结构:
rust
pub struct InMemoryIndex {
pub word_count: usize,
pub terms: HashMap<String, Vec<Hit>>,
pub docs: HashMap<usize, Document>,
}
pub struct Document {
pub id: u32,
pub path: PathBuf,
}
pub type Hit = Vec<u8>;-
Document: 文档封装。id: 文档 id,唯一标识符。path: 源文件路径。
-
Hit: 它是一个字节数组,我们按照小端序进行存储,它的存储结构如下:- 0...3 存储一个
HITS_SEPERATOR = -1,表示一个Hit的开始。 - 4...7 存储一个 u32 的
document_id。 - 后面每 8 个 u8 会存在一个 u32 的
start_pos和一个 u32 的end_pos。
- 0...3 存储一个
-
InMemoryIndex: 内存索引。word_count: 包含的单词(word/term)个数,记录它是为了判断索引是否过大,以便对索引进行分片存储。terms: 存储 word 到 Hits 的映射,每个word是一个搜索项。docs: 存储了 document_id 到文档的映射,用于查询原始文档信息。
接下来我们来为 InMemoryIndex 实现一系列方法,因为我们期望使用小端序存储 Hit 中的数据,所以我们需要引入 byteorder 这个 crate:
bash
cargo add byteorder具体实现可参考源码,核心逻辑是 from_single_document 和 merge。
from_single_document
from_single_document 的核心逻辑在这一段,它其实跟我们之前实现的简易版倒排索引很相似:
rust
for (token, start_pos, end_pos) in tokens.iter() {
let hits = index.terms.entry(token.to_string()).or_insert_with(|| {
let mut hits = Vec::with_capacity(4 + 4 + 4 + 4);
hits.write_i32::<LittleEndian>(Self::HITS_SEPERATOR)
.unwrap();
hits.write_u32::<LittleEndian>(document_id).unwrap();
vec![hits]
});
hits[0].write_u32::<LittleEndian>(*start_pos as u32).unwrap();
hits[0].write_u32::<LittleEndian>(*end_pos as u32).unwrap();
index.word_count += 1;
}- 遍历每个
token和它在文本中的位置。 - 对于每个
token,尝试在索引的map中查找一个现有的条目。如果不存在,则创建一个新的Hit记录,并初始化它:- 创建一个新的
Hit向量,预留 24 字节的容量,这是因为至少要存储 1 个分隔符、1 个 document_id、1 个 start_pos 和 1 个 end_pos。 - 首先写入
HITS_SEPERATOR和document_id(使用小端序)。
- 创建一个新的
- 向对应的
Hit向量中添加当前单词的位置。 - 累加处理的单词总数到
index.word_count。
这里给个示例,希望可以帮助你理解 InMemoryIndex 的内存结构:
yaml
InMemoryIndex
│
├── word_count: usize
│
├── terms: HashMap<String, Vec<Hit>>
│ │
│ ├── Key: "example" (String)
│ │ └── Value: Vec<Hit>
│ │ ├── [HITS_SEPERATOR, Document ID: 1, Positions: [10, 19, 30, 39]] (Hit)
│ │ └── [HITS_SEPERATOR, Document ID: 2, Positions: [15, 25]] (Hit)
│ │
│ └── Key: "test"
│ └── Value: Vec<Hit>
│ └── [HITS_SEPERATOR, Document ID: 1, Positions: [20, 24, 50, 69]] (Hit)
│
└── docs: HashMap<u32, Document>
├── Key: 1 (u32)
│ └── Value: Document { id: 1, path: "path/to/file1.txt"}
└── Key: 2
└── Value: Document { id: 2, path: "path/to/file2.txt"}merge
merge 是用于合并多个 InMemoryIndex,起到批处理的目的。
rust
pub fn merge(&mut self, other: InMemoryIndex) {
for (term, hits) in other.terms {
self.terms.entry(term).or_default().extend(hits)
}
self.word_count += other.word_count;
self.docs.extend(other.docs);
}实现完了 InMemoryIndex 后,我们就可以先来完成 create.rs 的 run_pipeline 的前 3 个阶段了。
step1: start_file_reader_thread
- 读取文件信息:我们需要在独立的线程中依次打开给定的文件列表,并将文件内容读取到一个 String 中,并利用 channel 传送出去。
rust
fn start_file_reader_thread(
documents: Vec<PathBuf>,
) -> (Receiver<(PathBuf, String)>, JoinHandle<io::Result<()>>) {
let (sender, receiver) = channel();
let handler = spawn(move || {
for filename in documents {
let mut f = File::open(filename.clone())?;
let mut text = String::new();
f.read_to_string(&mut text)?;
if sender.send((filename, text)).is_err() {
break;
}
}
Ok(())
});
(receiver, handler)
}step2: start_file_indexing_thread
- 构建索引:通过 channel 从第 1 阶段中获取文档文本信息,通过 from_single_document 构建索引 InMemoryIndex 后,将索引通过 channel 传送出去。
rust
fn start_file_indexing_thread(
docs: Receiver<(PathBuf, String)>,
) -> (Receiver<InMemoryIndex>, JoinHandle<()>) {
let (sender, receiver) = channel();
let handler = spawn(move || {
for (doc_id, (path, text)) in docs.into_iter().enumerate() {
let index = InMemoryIndex::from_single_document(doc_id as u32, path, text);
if sender.send(index).is_err() {
break;
}
}
});
(receiver, handler)
}step3: start_in_memory_merge_thread
- 合并索引:通过 channel 从第 2 阶段中获得构建的 InMemoryIndex 并将其合并成大索引,然后通过 channel 传送出去。
rust
fn start_in_memory_merge_thread(
indexes: Receiver<InMemoryIndex>,
) -> (Receiver<InMemoryIndex>, JoinHandle<()>) {
let (sender, receiver) = channel();
let handle = spawn(move || {
let mut accumulated_index = InMemoryIndex::new();
for i in indexes {
accumulated_index.merge(i);
if accumulated_index.is_large() {
if sender.send(accumulated_index).is_err() {
return;
}
accumulated_index = InMemoryIndex::new();
}
}
if !accumulated_index.is_empty() {
let _ = sender.send(accumulated_index);
}
});
(receiver, handle)
}{% note info %}
补充:为什么采用这种"复杂"的方式来存储数据呢?可否使用 JSON 或者 Protobuf 呢?
选择如何组织和存储数据,特别是在实现一个搜索引擎或数据库索引时,是一个关键决策,这会直接影响到程序的性能、可维护性以及扩展性。在这些情况下,使用像 byteorder 这样的低级数据格式存储索引信息可能比使用 JSON 或 Protobuf 等高级格式更有优势。
读写速度:
- 二进制格式:直接操作二进制格式通常比解析文本或半结构化的数据格式(如 JSON)要快,因为它减少了解析时间和内存使用。在二进制格式中,数据通常是紧密打包的,没有额外的格式标记(如 JSON 中的花括号和逗号),这减少了磁盘 I/O 需求。
- 文本/半结构化格式:例如 JSON,每次读取时都需要解析文本,转换数据类型,这会增加 CPU 的负担,尤其是在大规模数据处理时。
空间效率:
- 二进制格式:使用最少的字节表示数据,例如使用定长的整数存储文档 ID 和位置索引,不仅节省空间,还能提高缓存利用率。
- 文本/半结构化格式:文本格式需要存储额外的字符来标识数据(例如引号和键名),这增加了存储需求。
适用场景:
- 二进制格式:非常适合需要高性能和大数据处理的后端系统,如搜索引擎和数据库索引。这种格式可以有效地支持快速的数据读取和写入,特别是在资源受限的环境中(如嵌入式系统或低延迟应用)。
- JSON/Protobuf:更适合需要跨平台兼容性和易于调试的应用场景。例如,在 Web 应用中使用 JSON 作为数据交换格式,可以简化前后端的集成和测试。
{% endnote %}
tmp.rs
完成内存索引的构建后,我们需要将构建过程中产生的大索引先临时落盘,后面再进行合并。为了临时存储这些数据文件,我们需要将他们放在一个临时目录中,为此,我们定义了 TmpDir 数据结构:
rust
#[derive(Clone)]
pub struct TmpDir {
dir: PathBuf,
n: usize,
}dir: 目录n: 自增器,用于区分临时文件命名
接下来为 TmpDir 实现 2 个方法:
rust
impl TmpDir {
pub fn new<P: AsRef<Path>>(dir: P) -> TmpDir {
TmpDir {
dir: dir.as_ref().to_owned(),
n: 1,
}
}
pub fn create(&mut self) -> io::Result<(PathBuf, BufWriter<File>)> {
let mut r#try = 1;
loop {
let filename = self
.dir
.join(PathBuf::from(format!("tmp{:08x}.dat", self.n)));
self.n += 1;
match fs::OpenOptions::new()
.write(true)
.create_new(true)
.open(&filename)
{
Ok(f) => return Ok((filename, BufWriter::new(f))),
Err(exc) => {
if r#try < 999 && exc.kind() == io::ErrorKind::AlreadyExists {
// keep going
} else {
return Err(exc);
}
}
}
r#try += 1;
}
}
}new 方法是 TmpDir 的构造函数,其中我们将 n 设置为 1,即文件名从 1 开始生成。dir.as_ref().to_owned() 接受一个可能是任何类型的路径,将其标准化为一个 Path 类型的引用,然后再复制这个引用,创建一个完全独立的、拥有所有权的 PathBuf 对象,
create 方法是在 TmpDir 目录下创建一个临时文件。
write.rs
完整源码:write.rs
准备好内存索引和临时文件,那我们就需要实现将内存索引写入到文件中的功能了。
struct: InMemoryIndex
我们先来分析一下如何将 InMemoryIndex 落盘。首先 InMemoryIndex 的结构如下:
rust
pub struct InMemoryIndex {
pub word_count: usize,
pub terms: HashMap<String, Vec<Hit>>,
pub docs: HashMap<u32, Document>,
}
pub struct Document {
pub id: u32,
pub path: PathBuf,
}其中 word_count 不需要存储,我们可以计算出来。那我们就需要存储索引 map 和文档原数据 docs。为了能精确定位到各个数据,我们需要:
terms:
- 写入 Vec<Hit>
docs:
- 写入 docs 中的每个 Document
- 写入 id
- 写入 path 大小
- 写入 path
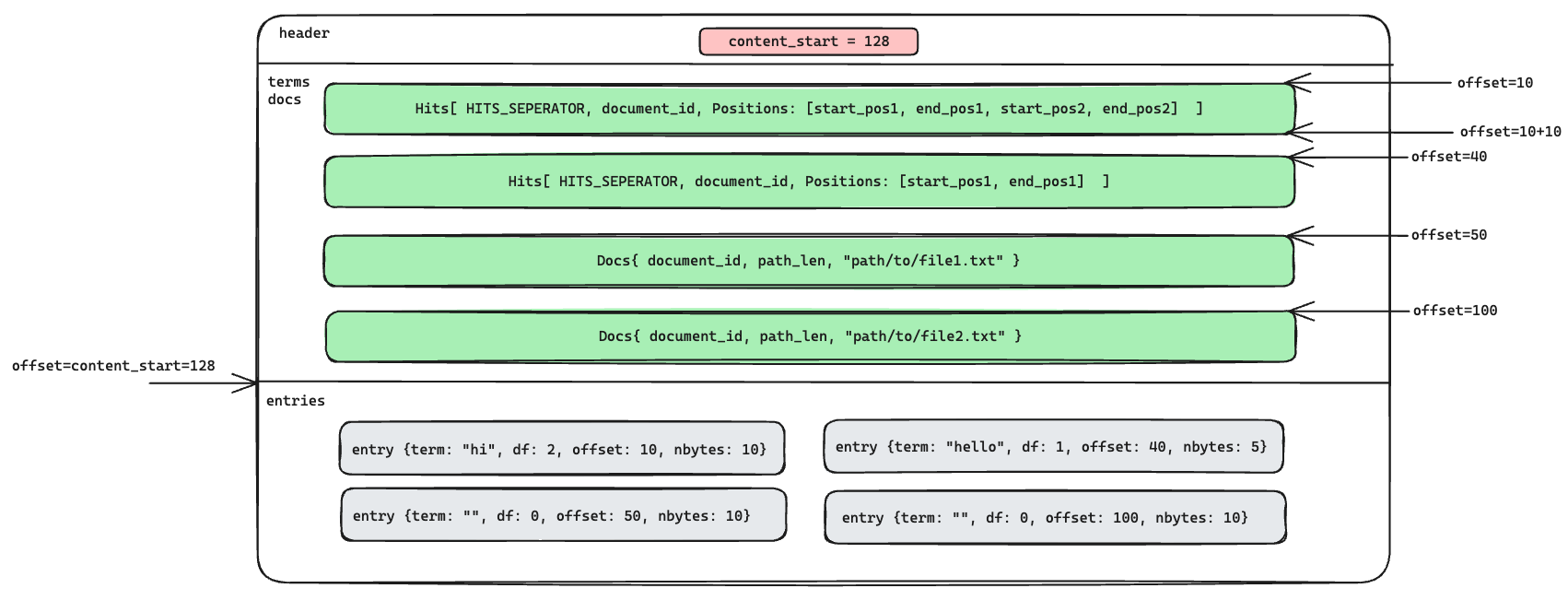
而为了快速定位到每个 term 和 doc 的位置,我们需要下面几个值,这几个值将组合起来辅助我们快速定位 terms 或 docs,我们后面会将其称为 Entry,它包含以下几个值:
term: 索引单词。为了统一,如果term为空,则表示当前表示的是 doc,否则为 terms。df: term 的出现次数。为了统一,如果df为 0,则表示当前表示的是 doc,否则为 terms。offset: 对应的 terms 或 docs 在文件中的偏移。nbytes: 对应的 terms 或 docs 的总长度。
所以文件的内存结构大概如下:
| 文件区域 | 描述 | 指向内容 |
|---|---|---|
| 头部 (8 字节) | 包含一个指向目录表开始位置的偏移量。 | header |
| 主条目 | 这些条目按顺序紧密存储,没有额外的元数据。这部分包含实际的数据条目。 | terms + docs |
| 目录表 | 存储在文件的最后,包括每个条目的术语信息、文档频率、偏移和大小。 | entries |
示意图如下:
为此我们定义了 IndexFileWriter,它专门用于将 InMemoryIndex 写入到临时文件中,定义如下:
rust
/// A structure to manage writing to an index file efficiently.
pub struct IndexFileWriter {
offset: u64,
writer: BufWriter<File>,
contents_buf: Vec<u8>,
}offset: 用于追踪文件中当前的写入位置。writer: 一个缓冲写入器,它包装了一个文件,用于输出操作。contents_buf: 一个向量,用来存储内容条目,在全部写入文件之前暂存在这个缓冲区。
接下来我们为 IndexFileWriter 实现几个方法:
new: 这是一个构造函数,它初始化文件并设置初始偏移量。在文件的开始处写入一个占位符作为头部,这个头部最终会存储主数据区的大小。write_document: 用于将一个文档以二进制格式写入到文件中,同时更新偏移量。write_main: 这个方法接受一段数据,并将它写入文件中,同时更新偏移量。write_contents_entry: 将一个内容 Entry 追加到内部的缓冲区中。Entry 包括一个术语、文档频率、术语数据的起始偏移和大小,它用于快速定位 terms 或 docs。finish: 完成文件写入过程,将内部缓冲区的内容写入文件,并更新文件头部的主数据大小。
new
我们先来看构造方法:
rust
pub fn new(mut f: BufWriter<File>) -> io::Result<IndexFileWriter> {
const HEADER_SIZE: u64 = 8;
f.write_u64::<LittleEndian>(0)?; // content start
Ok(IndexFileWriter {
offset: HEADER_SIZE,
writer: f,
contents_buf: vec![],
})
}new 分为以下几步:
- 定义头部大小 :
const HEADER_SIZE: u64 = 8;:定义一个常量HEADER_SIZE,其值为 8 字节,这表示文件头部的大小。这个头部将用于后续在文件的开始处写入主数据区的起始位置。 - 写入头部占位符 :
f.write_u64::<LittleEndian>(0)?;:在文件的开始处写入一个 8 字节的占位符,这个值是以小端字节序(LittleEndian)存储的。初始时这里写入的是 0,意味着"主数据区的起始位置未知",这个值在后续的finish函数中会被更新。 - 返回一个新的 IndexFileWriter 实例 :
Ok(IndexFileWriter { offset: HEADER_SIZE, writer: f, contents_buf: vec![], }):构造并返回一个IndexFileWriter实例。这个实例的offset字段被初始化为HEADER_SIZE(8 字节),表示实际数据将从文件的第 17 个字节开始写入。writer字段就是传入的文件写入器,contents_buf是一个新的空向量,用于临时存储内容条目数据。
{% note info %}
为什么这样设计?
这个实现方式有几个设计上的考虑:
- 预留头部空间:通过在文件开始处预留 8 字节空间来存储主数据区的大小,这样做可以在数据写入完成后,方便地回填这个信息。这是文件格式设计中常见的做法,允许读取者快速定位主数据区和内容索引区。
- 使用小端字节序:小端字节序是一种在二进制文件中常用的字节序,尤其是在 Windows 平台下。使用小端字节序可以提高文件的兼容性,并且对于多数处理器架构来说,小端字节序的读写操作更为高效。
- 灵活的数据写入 :通过将
writer和contents_buf组合使用,这个结构体可以灵活地处理不同的数据写入需求。writer直接写入文件,适合连续大块数据的写入;而contents_buf用于聚集多个小片段的数据,可以在最后统一写入,减少磁盘操作次数。
总的来说,这个构造函数的实现为高效和灵活的文件写操作提供了良好的基础,同时通过合理的错误处理和数据组织方式,确保了程序的健壮性和高性能。
{% endnote %}
write_main
Hit 本身就是一个 Vec<u8>, 将其写入文件很简单,调用 write_all,即可,我们为其封装 write_main 方法:
rust
pub fn write_main(&mut self, buf: &[u8]) -> io::Result<()> {
self.writer.write_all(buf)?;
self.offset += buf.len() as u64;
Ok(())
}write_document
为了将 Docuemnt 本以二进制结构写入到文件中,我们需要拆分成几个部分:
- 文件 id
- 文件路径大小
- 文件路径
为此我们为 IndexFileWriter 封装了 write_document:
rust
pub fn write_document(&mut self, doc: &Document) -> io::Result<()> {
self.writer.write_u32::<LittleEndian>(doc.id)?;
self.writer
.write_u64::<LittleEndian>(doc.path.as_os_str().len() as u64)?;
self.writer.write_all(doc.path.as_os_str().as_bytes())?;
self.offset += 4 + 8 + doc.path.as_os_str().len() as u64;
Ok(())
}write_contents_entry
Entry 的数据量一般较小,我们会先写入缓冲中,后面再一次性刷盘,为此我们为 IndexFileWriter 封装了 write_contents_entry:
rust
/// Appends a content entry to the internal buffer.
///
/// # Arguments
/// * `term` - The term associated with the entry
/// * `df` - Document frequency for the term
/// * `offset` - Offset where the term data starts in the file
/// * `nbytes` - Number of bytes of the term data
pub fn write_contents_entry(&mut self, term: String, df: u32, offset: u64, nbytes: u64) {
self.contents_buf.write_u64::<LittleEndian>(offset).unwrap();
self.contents_buf.write_u64::<LittleEndian>(nbytes).unwrap();
self.contents_buf.write_u32::<LittleEndian>(df).unwrap();
let bytes = term.bytes();
self.contents_buf
.write_u32::<LittleEndian>(bytes.len() as u32)
.unwrap();
self.contents_buf.extend(bytes);
}finish
刷盘的过程我们封装在 finish 中:
rust
pub fn finish(mut self) -> io::Result<()> {
let contents_start = self.offset;
self.writer.write_all(&self.contents_buf)?;
self.writer.seek(SeekFrom::Start(0))?;
self.writer.write_u64::<LittleEndian>(contents_start)?;
Ok(())
}write_index_to_tmp_file
综合下来,我们就可以实现最核心的函数 write_index_to_tmp_file 了:
rust
pub fn write_index_to_tmp_file(index: InMemoryIndex, tmp_dir: &mut TmpDir) -> io::Result<PathBuf> {
let (filename, f) = tmp_dir.create()?;
let mut writer = IndexFileWriter::new(f)?;
let mut index_as_vec: Vec<_> = index.terms.into_iter().collect();
index_as_vec.sort_by(|(a, _), (b, _)| a.cmp(b));
for (term, hits) in index_as_vec {
let df = hits.len() as u32;
let start = writer.offset;
for buffer in hits {
writer.write_main(&buffer)?;
}
let stop = writer.offset;
writer.write_contents_entry(term, df, start, stop - start);
}
// if term == "" && df == 0 { type = document }
for (_, doc) in index.docs {
let start = writer.offset;
writer.write_document(&doc)?;
let stop = writer.offset;
writer.write_contents_entry("".to_string(), 0, start, stop - start)
}
writer.finish()?;
println!("wrote file {:?}", filename);
Ok(filename)
}- 我们在临时目录中创建一个临时文件,并初始化 IndexFileWriter;
- 将索引的
terms转换成一个向量并按照键排序; - 对于每个
term,计算文档频率(df),记录开始和结束位置,然后调用write_main方法将数据写入文件,然后使用write_contents_entry方法写入Entry的元数据到目录表; - 对于
index.docs中的每个文档,计算起止位置,并使用一个特殊的条目(空字符串作为条目名和 0 作为文档频率)标记在文件中; - 最后我们使用
finish将缓存中所有的Entry刷盘,并设置entries的起始位置。
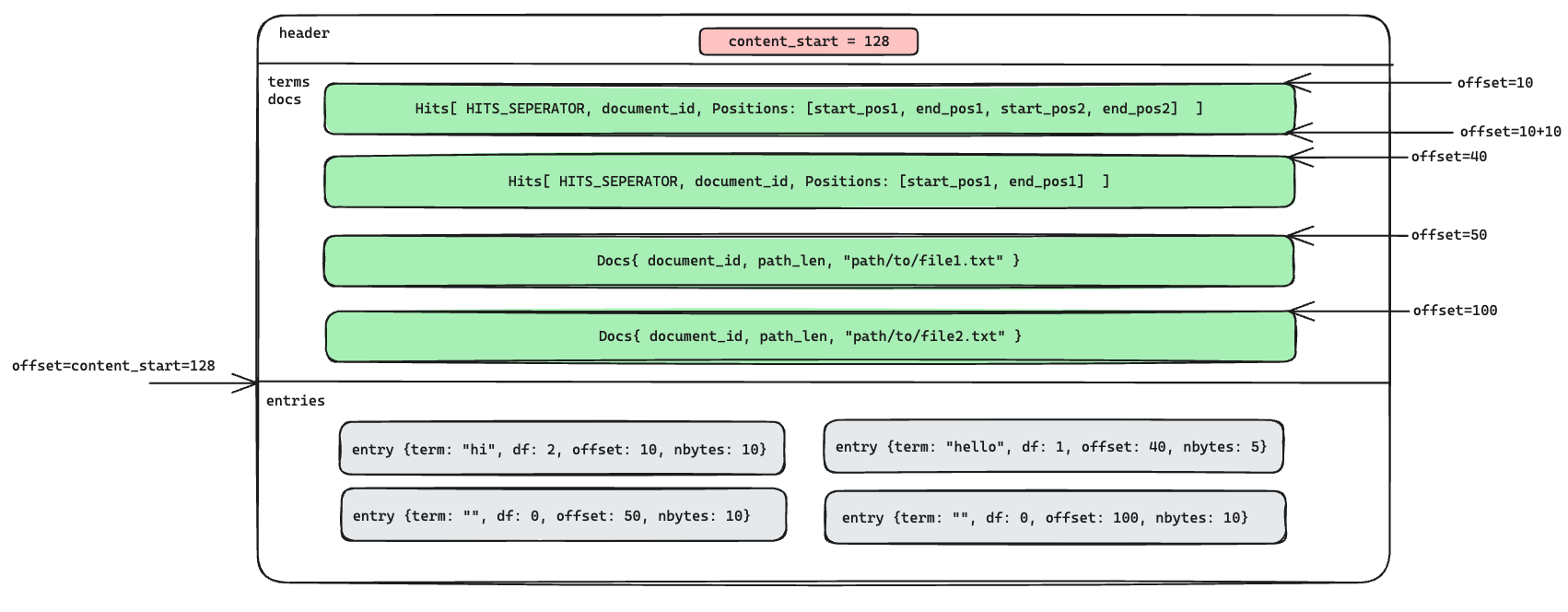
文件的内存结构如上面给出的图一样,这里我们可以再看一次:
step4: start_index_writer_thread
实现了将内存索引写入到文件的功能后,我们就可以继续在 create.rs 中实现下一个流程了:
rust
fn start_index_writer_thread(
big_indexes: Receiver<InMemoryIndex>,
output_dir: &Path,
) -> (Receiver<PathBuf>, JoinHandle<io::Result<()>>) {
let (sender, receiver) = channel();
let mut tmp_dir = TmpDir::new(output_dir);
let handle = spawn(move || {
for i in big_indexes {
println!("word count: {}", i.word_count);
let file = write_index_to_tmp_file(i, &mut tmp_dir)?;
if sender.send(file).is_err() {
break;
}
}
Ok(())
});
(receiver, handle)
}在 start_index_writer_thread 流程中,我们将构建好的内存索引一个个写入到文件中,并将生成的文件句柄传入下一个流程。
merge.rs
完整源码:merge.rs
前面 start_index_writer_thread 是将一个个 InMemoryIndex 写入到 TmpDir 临时目录中。现在我们要将这些临时文件合并成一个最终的索引文件,以优化查询效率和节省存储空间。
srtuct: FileMerge
我们定义一下结构:
rust
pub struct FileMerge {
output_dir: PathBuf,
tmp_dir: TmpDir,
stacks: Vec<Vec<PathBuf>>,
}output_dir: 用于存储最终合并文件的输出目录。tmp_dir: 前面tmp.rs定义的结构,用于管理合并过程中产生的临时文件。stacks: 这是一个二维向量,每个内部向量代表一个合并"层",存储了该层待合并的文件路径。
关于 stacks,再多说两点:
- 多级合并策略 :
FileMerge使用一个多层合并策略,这种策略在处理大量文件时尤为有效。基本思想是,当一层的文件数量达到一个预设的阈值(NSTREAMS)时,这些文件会被合并成一个新的文件,新文件则被推送到上一层。这种层级式的处理方式可以显著减少最终合并步骤需要处理的文件数量,从而优化性能。 - 动态扩展 :使用
Vec<Vec<PathBuf>>允许动态地添加新的合并层,这在处理不确定数量的文件时非常有用。向量的灵活性意味着无需预先知道将处理多少文件,它可以根据实际需要进行扩展。
接下来我们会为 FileMerge 实现 2 个方法:
add_file: 添加一个文件到合并栈中,并使用多级合并策略进行合并。finish: 执行最后的合并操作,生成最终的索引文件,输出到output_dir中。
add_file
首先我们来看add_file,它的实现如下:
rust
pub fn add_file(&mut self, mut file: PathBuf) -> io::Result<()> {
// 从第一层开始检查
let mut level = 0;
// 使用循环来处理文件的添加和可能的合并。
loop {
// 如果当前的 level (层级)不存在于 stacks 中,
// 就在 stacks 中添加一个新的空向量。
// 这是为了存放该层级的文件。
if level == self.stacks.len() {
self.stacks.push(vec![]);
}
// 将当前的文件添加到对应层级的向量中。
self.stacks[level].push(file);
// 如果这个级别的堆栈已满,就合并这个级别的文件。
// 如果没满,则不进行合并,直接退出。
if self.stacks[level].len() < NSTREAMS {
break;
}
// 创建一个新文件来存储合并结果,并更新堆栈。
let (filename, out) = self.tmp_dir.create()?;
// 初始化一个空的 to_merge 向量,
// 然后使用 mem::swap 交换当前层级的文件列表和这个空向量,
// 这样 to_merge 向量就包含了需要合并的文件,
// 而当前层级变为空,可以用来存放新的合并文件。
let mut to_merge = vec![];
mem::swap(&mut self.stacks[level], &mut to_merge);
// 调用 merge_streams 函数将 to_merge 中的文件合并到新创建的文件中。
merge_streams(to_merge, out)?;
// 将合并后得到的新文件路径赋值给 file 变量,用于下一轮循环。
file = filename;
// level 加一,表示移动到下一个层级。
level += 1;
}
Ok(())
}这个方法通过层级的方式管理文件合并,每个层级可以有多个文件,但数量上限为 NSTREAMS。如果某层满了,就将该层的文件合并成一个新文件,并将这个新文件移动到上一层继续参与合并。这种设计有效地将多个文件逐步合并成一个文件,同时控制内存和 I/O 资源的使用。
其中 merge_streams 就是具体的合并过程,它的实现如下:
rust
fn merge_streams(files: Vec<PathBuf>, out: BufWriter<File>) -> io::Result<()> {
// 从索引文件中构建 IndexFileReader 列表
let mut streams: Vec<IndexFileReader> = files
.into_iter()
.map(|p| IndexFileReader::open_and_delete(p, true))
.collect::<io::Result<_>>()?;
// 针对输出文件生成一个 IndexFileWriter 用于写入索引信息
let mut output = IndexFileWriter::new(out)?;
// 用于记录当前写入的位置(或者数据偏移量)。
let mut point: u64 = 0;
// 记录还有数据未处理的文件流数量,用 peek() 方法检查。
let mut count = streams.iter().filter(|s| s.peek().is_some()).count();
// 只要 count 大于0,表示还有文件未完全处理,就继续循环。
while count > 0 {
let mut term = None;
let mut nbytes = 0;
let mut df = 0;
// 这段代码通过遍历每个文件流,使用 peek() 方法预览每个文件的当前数据条目
for s in &streams {
match s.peek() {
None => {}
Some(entry) => {
// term 是空的,则说明这是表示 doc 的 entry。
// 直接退出 for 循环,因为 doc 的 entry 没有顺序且唯一,不会进行累加。
if entry.term.is_empty() {
term = Some(entry.term.clone());
nbytes = entry.nbytes;
df = entry.df;
break;
}
// term 不是空的,则说明这是表示 terms 的 entry。
// 选择词条最小的一个(字典序),并且累加其出现的频次和字节大小。
// 这是多路归并的核心,确保输出文件是有序的。
if term.is_none() || entry.term < *term.as_ref().unwrap() {
term = Some(entry.term.clone());
nbytes = entry.nbytes;
df = entry.df
} else if entry.term == *term.as_ref().unwrap() {
nbytes += entry.nbytes;
df += entry.df
}
}
}
}
let term = term.expect("bug in algorithm");
// 对于每个文件流,如果当前数据条目与选择的 term 相同,
// 则将该条目写入输出文件,并更新该流的读取位置。
for s in &mut streams {
if s.is_at(&term) {
s.move_entry_to(&mut output)?;
if s.peek().is_none() {
count -= 1;
}
if term.is_empty() {
break;
}
}
}
output.write_contents_entry(term, df, point, nbytes);
point += nbytes
}
Ok(())
}这里涉及到了一个新的结构 IndexFileReader,它是索引文件的读取器,我们将在 read.rs 中实现它。这里先不展开,你只需要知道:
IndexFileReader::open_and_delete(p, true): 打开一个索引文件,并根据传入的参数判断是否要删除这个文件,在合并过程中,因为都是临时文件,所以我们会指定为删除文件。但是在后面从索引文件中重建InMemoryIndex的时候,我们不希望删除原始的索引文件。s.peek(): 查看下一个 Entry,它的返回值是 Option<Entry>。s.move_entry_to(&mut output): 将s.peek()指向的 Entry 写入到 output 文件中,并移动到一下 Entry。
总结下来,这个函数实现多路归并的核心部分,它将多个索引文件合并成一个单一的有序文件。
finish
我们再来看 FileMerge 的另外一个方法 finish:
rust
pub fn finish(mut self) -> io::Result<()> {
// 初始化一个临时向量 tmp,用来暂存需要合并的文件路径。
// 这个向量的容量设置为 NSTREAMS,这是预先定义的常量,表示一次可以合并的最大文件数。
let mut tmp = Vec::with_capacity(NSTREAMS);
// 方法遍历 self.stacks 中的每个堆栈。每个堆栈代表一个合并层级,包含若干待合并的文件。
for stack in self.stacks {
// 对于每个堆栈,方法使用 .into_iter().rev() 迭代器反向遍历文件,
// 以确保按正确的顺序处理(先进后出)。
for file in stack.into_iter().rev() {
// 将文件逐个添加到 tmp 向量中。
tmp.push(file);
// 当 tmp 的长度达到 NSTREAMS 时,
// 调用 merge_reversed 函数进行合并。
if tmp.len() == NSTREAMS {
merge_reversed(&mut tmp, &mut self.tmp_dir)?;
}
}
}
// 对于剩余文件进行最终的合并。
if tmp.len() > 1 {
merge_reversed(&mut tmp, &mut self.tmp_dir)?;
}
// 最后应该只有一个最终文件
assert!(tmp.len() == 1);
match tmp.pop() {
// 对文件进行重命名
Some(last_file) => fs::rename(last_file, self.output_dir.join(MERGED_FILENAME)),
None => Err(io::Error::new(
io::ErrorKind::Other,
"no ducuments were parsed or none contained any words",
)),
}
}这里涉及到了另外一个函数 merge_reversed:
rust
fn merge_reversed(filenames: &mut Vec<PathBuf>, tmp_dir: &mut TmpDir) -> io::Result<()> {
filenames.reverse();
let (merge_filename, out) = tmp_dir.create()?;
let mut to_merge = Vec::with_capacity(NSTREAMS);
mem::swap(filenames, &mut to_merge);
merge_streams(to_merge, out)?;
filenames.push(merge_filename);
Ok(())
}它其实就是将 filenames 翻转,清空并将内容转移到 to_merge,然后调用 merge_streams 合并,并将合并后的文件重新放回被清空的 filenames,也就是我们在 finish 中声明的 tmp 变量。
{% note info %}
为什么这里需要翻转 filenames?
假设 NSTREAMS = 3,我们执行 add_file,从 file1 到 file8,那么过程如下:
| Action | Stack 0 | Stack 1 | Notes |
|---|---|---|---|
| Add file1 | file1 | ||
| Add file2 | file1, file2 | ||
| Add file3 | file1, file2, file3 | ||
| Merge S1 | (empty) | merge1 | merge1 is the result of merging file1-file3 |
| Add file4 | file4 | merge1 | |
| Add file5 | file4, file5 | merge1 | |
| Add file6 | file4, file5, file6 | merge1 | |
| Merge S2 | (empty) | merge1, merge2 | merge2 is the result of merging file4-file6 |
| Add file7 | file7 | merge1, merge2 | |
| Add file8 | file7, file8 | merge1, merge2 | Trigger merge because 8 files are reached |
最后我们获得的结果是:
| stack0 | stack1 |
|---|---|
| file7, file8 | merge1, merge2 |
按照文件的添加顺序,我们期望在 finish 中合并的顺序应该是:merge1, merge2, file7, file8。所以我们遍历 stacks 的时候,从第 1 层开始遍历的话,我们就需要反向遍历 rev(),这个时候我们组成的 tmp 就是:file8, file7, merge2, merge1。最后我们传入 merge_reversed 的时候,再进行 reverse(),就可以获得我们期望的顺序 merge1, merge2, file7, file8。
{% endnote %}
回过头来,我们总结一下 finish:这个方法通过多级合并的方式,逐层处理并最终合并所有文件到一个文件。这个方法确保在多个文件频繁合并的环境中,能有效地管理和减少临时存储使用,并保持合并操作的效率。通过最后的重命名操作,它还处理了文件的最终存放,确保合并结果的正确性和可用性。
实现了 merge.rs 的相关内容,我们就可以来实现 create.rs 中的最后一步了。
step5: merge_index_files
我们将第 4 阶段构建的临时文件合并成一个最终的索引文件并输出到 output_dir 目录中。
rust
fn merge_index_files(files: Receiver<PathBuf>, output_dir: &Path) -> io::Result<()> {
let mut merge = FileMerge::new(output_dir);
for file in files {
merge.add_file(file)?;
}
merge.finish()
}run_pipeline
至此,我们就完成了并发构建倒排索引的 5 个步骤了,对其进行组织,就可以实现我们的并发构建函数 run_pipeline:
rust
fn run_pipeline(documents: Vec<PathBuf>, output_dir: PathBuf) -> io::Result<()> {
// Launch all five stages of the pipeline.
let (texts, h1) = start_file_reader_thread(documents);
let (pints, h2) = start_file_indexing_thread(texts);
let (gallons, h3) = start_in_memory_merge_thread(pints);
let (files, h4) = start_index_writer_thread(gallons, &output_dir);
let result = merge_index_files(files, &output_dir);
// Wait for threads to finish, holding on to any errors that they encounter.
let r1 = h1.join().unwrap();
h2.join().unwrap();
h3.join().unwrap();
let r4 = h4.join().unwrap();
// Return the first error encountered, if any.
// (As it happens, h2 and h3 can't fail: those threads
// are pure in-memory data processing.)
r1?;
r4?;
result
}read.rs
完整源码:read.rs
在 merge.rs 中,我们还剩最后一个结构没有解析,那就是 IndexFileReader,它是索引文件的读取器。
struct: IndexFileReader
rust
pub struct IndexFileReader {
pub terms_docs: BufReader<File>,
entries: BufReader<File>,
next: Option<Entry>,
}
pub struct Entry {
pub term: String,
pub df: u32,
pub offset: u64,
pub nbytes: u64,
}我们在 IndexFileReader 结构体中定义两个 BufReader<File> ,这是为了有效管理和操作索引文件中的不同数据段。具体来说,这种设计使得代码能够更加灵活和高效地处理索引文件中的"主数据区"和"内容表区"。
即用来分别处理下图的 terms&doc 和 entries 两个区域:
这有几个好处:
- 独立的文件指针 :每个
BufReader<File>维护自己的文件读取位置(文件指针)。这意味着读取或搜索内容表时,不会影响主数据区的文件指针,反之亦然。这样可以避免频繁地重新定位文件指针,提高文件操作的效率。 - 缓冲读取 :
BufReader提供了缓冲读取功能,可以减少直接对硬盘的读取次数,从而优化读取性能。对于需要频繁读取小块数据的索引操作,使用缓冲读取可以显著提高效率。 - 并行操作 :在多线程环境中,可能需要同时读取主数据区和内容表区。使用两个独立的
BufReader实例可以简化并行读取的管理,每个读取操作都可以在不干扰另一个操作的情况下独立进行。
Entry 就是我们在 write.rs 中 write_contents_entry 时传入的参数,这里我们将其封装成一个 struct,再次回顾下这几个字段的含义:
term: 索引单词。为了统一,如果term为空,则表示当前表示的是 doc,否则为 terms。df: term 的出现次数。为了统一,如果df为 0,则表示当前表示的是 doc,否则为 terms。offset: 对应的 terms 或 docs 在文件中的偏移。nbytes: 对应的 terms 或 docs 的总长度。
read_entry
这里我们重点解释一下 read_entry 方法,其他的都比较简单,请在源码中查找。
rust
fn read_entry(f: &mut BufReader<File>) -> io::Result<Option<Entry>> {
// 获取偏移值
let offset = match f.read_u64::<LittleEndian>() {
Ok(value) => value,
Err(err) => {
if err.kind() == io::ErrorKind::UnexpectedEof {
return Ok(None);
} else {
return Err(err);
}
}
};
// 读取 nbytes
let nbytes = f.read_u64::<LittleEndian>()?;
// 读取 df
let df = f.read_u32::<LittleEndian>()?;
// 读取 term_len,并初始化一块内存 bytes 用来读取完整的 term
let term_len = f.read_u32::<LittleEndian>()? as usize;
let mut bytes = vec![0; term_len];
f.read_exact(&mut bytes)?;
let term = match String::from_utf8(bytes) {
Ok(s) => s,
Err(_) => return Err(io::Error::new(io::ErrorKind::Other, "unicode fail")),
};
// 返回构建的 Entry
Ok(Some(Entry {
term,
df,
offset,
nbytes,
}))
}结合下面这张图,很容易理解 read_entry 就是前面 write_contents_entry 的逆向过程。

create.rs
完整源码:create.rs
至此,我们就分析完并发构建索引的整个过程了,在 create.rs 中,我们使用 clap 命令解析框架来构建一个 CLI 工具用以支持构建索引,我们同时支持单线程构建和并发构建,具体可看完整源码。
如果对 clap 不熟悉的读者,可参考:深入探索 Rust 的 clap 库:命令行解析的艺术
rust
#[derive(Parser)]
struct Opts {
#[arg(short, long, default_value_t = false, help = "Default false")]
single_threaded: bool,
#[arg(required = true)]
filenames: Vec<String>,
}
fn main() {
let opts = Opts::parse();
match run(opts.filenames, opts.single_threaded) {
Ok(()) => {}
Err(err) => println!("error: {}", err),
}
}搜索功能
在《Rust 程序设计(第二版)》中,作者并没有实现搜索功能,笔者对其进行扩展,目标是对标我们前篇所构建的 Rust 实战丨倒排索引。这个搜索功能,会根据现有的索引文件重建内存索引 InMemoryIndex,支持指定 term 进行搜索,并将包含这个 term 的文件在响应的位置中进行高亮显示并输出到终端。
search.rs
完整源码:search.rs
程序入口如下所示,比较简单,就不赘述了。
rust
#[derive(Parser)]
struct Opts {
#[arg(short, long, required = true, help = "Specify index file path")]
index_file: String,
#[arg(short, long, required = true, help = "Specify search term")]
term: String,
}
fn main() -> io::Result<()> {
let opts = Opts::parse();
let index = InMemoryIndex::from_index_file(opts.index_file)?;
index.search(&opts.term)?;
Ok(())
}这里有 2 个核心逻辑:
InMemoryIndex::from_index_file: 根据索引文件重建内存索引。index.search(term): 搜索。
index.rs
我们在 index.rs 中为 InMemoryIndex 实现上述 2 个方法。
from_index_file
rust
pub fn from_index_file<P: AsRef<Path>>(filename: P) -> io::Result<InMemoryIndex> {
let mut index = InMemoryIndex::new();
// 获取 IndexFileReader
let mut reader = IndexFileReader::open_and_delete(filename, false)?;
// 依次解析每个 Entry
while let Some(entry) = reader.iter_next_entry() {
if entry.term.is_empty() && entry.df == 0 {
// 当前 Entry 指向的是一个 Document。
// 通过 terms_docs 读取 Document 所在位置并进行解析。
reader.terms_docs.seek(io::SeekFrom::Start(entry.offset))?;
let doc_id = reader.terms_docs.read_u32::<LittleEndian>()?;
let path_len = reader.terms_docs.read_u64::<LittleEndian>()?;
let mut path = vec![0u8; path_len as usize];
reader.terms_docs.read_exact(&mut path)?;
index.docs.insert(
doc_id,
Document {
id: doc_id,
path: vec_to_pathbuf(path),
},
);
} else {
// 当前 Entry 指向的是一个 terms。
// 通过 terms_docs 读取 terms 所在位置并进行解析。
let mut hits = vec![];
reader.terms_docs.seek(io::SeekFrom::Start(entry.offset))?;
let mut data = vec![0u8; entry.nbytes as usize];
reader.terms_docs.read_exact(&mut data)?;
let mut cursor = Cursor::new(data);
let mut i = entry.df;
let mut has_hit = false;
let mut quit = false;
while i > 0 && !quit {
let mut hit = Vec::with_capacity(4 + 4 + 4); // cannot use vec![0;12]
loop {
if let Ok(item) = cursor.read_i32::<LittleEndian>() {
// the start of next hit
if item == Self::HITS_SEPERATOR && has_hit {
hits.push(hit);
i -= 1;
index.word_count -= 2;
hit = Vec::with_capacity(4 + 4 + 4);
}
has_hit = true;
hit.write_u32::<LittleEndian>(item as u32).unwrap();
index.word_count += 1;
} else {
quit = true;
if !hit.is_empty() {
hits.push(hit);
index.word_count -= 2;
}
break;
}
}
}
index.terms.insert(entry.term, hits);
}
}
index.word_count /= 2;
Ok(index)
}search
rust
pub fn search(&self, term: &str) -> io::Result<()> {
// 获取 term 出现的位置
let m: Option<&Vec<Vec<u8>>> = self.terms.get(term);
if m.is_none() {
println!("can not found {} in all documents", term);
return Ok(());
}
let hits = m.unwrap();
// 遍历每个出现的位置
for hit in hits {
let mut cursor = Cursor::new(hit);
let _ = cursor.read_i32::<LittleEndian>().unwrap();
// 获取文档原始信息
let document_id = cursor.read_u32::<LittleEndian>().unwrap();
let doc = self.docs.get(&document_id);
if doc.is_none() {
println!("cannot found document {}", document_id);
continue;
}
let doc = doc.unwrap();
// hits 存储的内容:[HITS_SEPERATOR, document_id, start_pos1, end_pos1, ...]
// 解析 term 出现在 doc 中的每个位置
let mut poss = Vec::with_capacity(hits.len() / 4);
let mut pos = TokenPos::default();
let mut has_pos = false;
while let Ok(p) = cursor.read_u32::<LittleEndian>() {
if !has_pos {
pos.start_pos = p;
has_pos = true;
} else {
pos.end_pos = p;
poss.push(pos);
pos = TokenPos::default();
has_pos = false;
}
}
// 对每个出现的位置进行高亮处理
let result = highlight_file(doc.path.clone(), &mut poss)?;
// 输出高亮后的结果
println!("\n{:?}: \n{}", doc.path, result);
}
Ok(())
}至此,我们就实现了高并发构建索引和根据索引进行搜索的功能,本篇某些部分可能比较复杂,篇幅也比较冗长,笔者在阅读书中原实现的时候,也是获益颇丰,想不到一个简单的倒排索引竟涉及这么多的处理细节。也希望本篇文章能对感兴趣的读者有些许帮助。
peace! enjoy coding~