一、概念
1.聚类
(1)是无监督学习,其实无监督学习就是无中生有,不给你标准答案(标签啊啥的),然后让你自己来。
(2)聚类就是这样,让机器自己根据相似特征把相似的东西放到一块。
(3)聚类就是将集合划分成由类(相)似的对象组成的多个类的过程。
聚类分析是研究(样品或指标)分类问题的一种统计分析方法。
(4)概念:
聚类是把各不相同的个体分割为有更多相似性子集合的工作,聚类生成的子集合称为簇(cluster)。
(5)聚类的要求
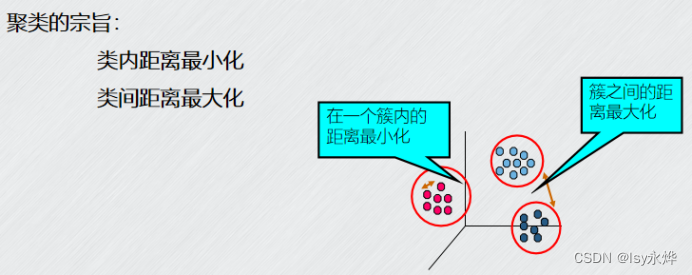
生成的簇内部的任意两个对象之间具有较高的相似度,于不同簇的两个对象间具有较高的相异度。
其中度量就用前面学习的欧氏距离,曼哈顿距离等进行测量。
(6)聚类的好坏不存在绝对标准
如扑克牌可以按花色分,也可以按数字分,具体情况具体分析。
(7)聚类与分类的区别:
聚类所要求划分的类是未知的,是无意识的,一般把它理解为无监督学习。
而分类算法是有训练样本的,属于监督学习。
(下面图,先是分类,后是聚类,可以很明显的看出标签的提示)
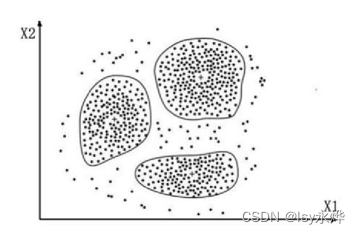
2.K-Means聚类算法
由聚类思想脱胎而生的nb算法之一。
(1)其中K代表要求划分成K个簇,means是均值的意思,也就是说每个簇的中心点是该簇中所有点的均值。
(2)保证每个簇必须包含一个对象,也要保证每个对象有且仅属于一个簇。
(3)流程:
a.随机选择k个点作为初始的聚类中心,注意这些点它可以是样本得到点,也可以不是。
b.对于剩下的点,根据其与聚类中心的距离,将其归入最近的族。
c.对每个族,计算所有点的均值作为新的聚类中心,注意这个点是产生出来的。
d.重复2、3直到聚类中心不再发生改变
(整个过程类似蠕动,中心点不断蠕动,直到发现好的地方)
(4)局限性:
a.图像过于抽象,平均值不靠谱
b.数据量过大是,收敛缓慢
(5)聚类分析的度量指标
a.外部指标:指用事先指定的聚类模型作为参考来评判聚类结果的好坏
b.内部指标:是指不借助任何外部参考,只用参与聚类的样本评判聚类结果好坏
二、习题
多选题:
- 聚类的宗旨是(BD)
A、类内距离最大化
B、类间距离最大化
C、类间距离最小化
D、类内距离最小化
判断题:
- 聚类的目的是对样本集合进行自动分类,以发掘数据中隐藏的信息、结构,从而发现可能的商业价值。 ( T)