1 mongo同步数据到mysql中
我想把51万8400的计算出来的八字信息,从mongo同步到mysql,看看在mysql中运行会怎么样。
选择mongodb input,这个是在Big Data中。
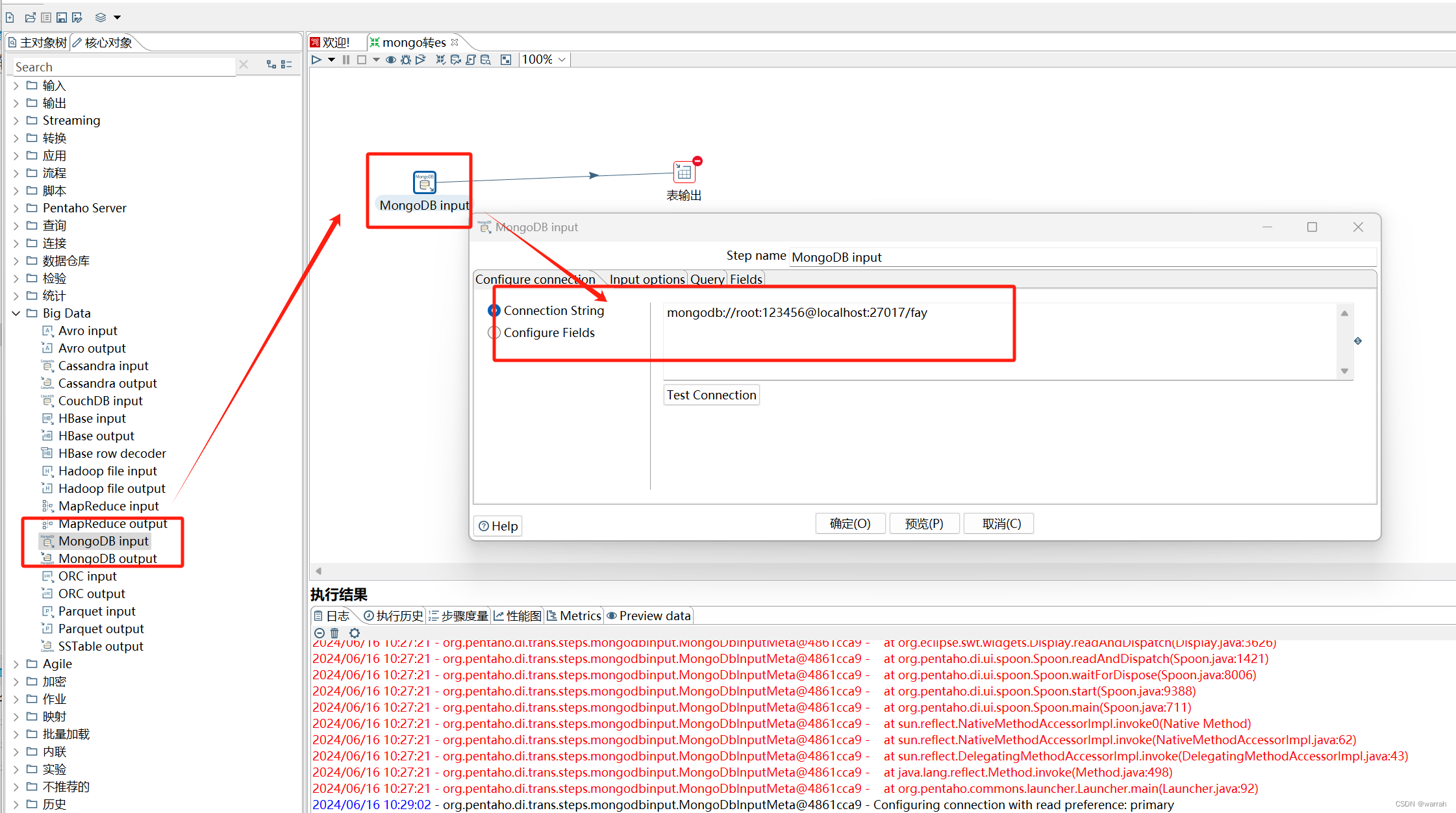
填写数据库和表
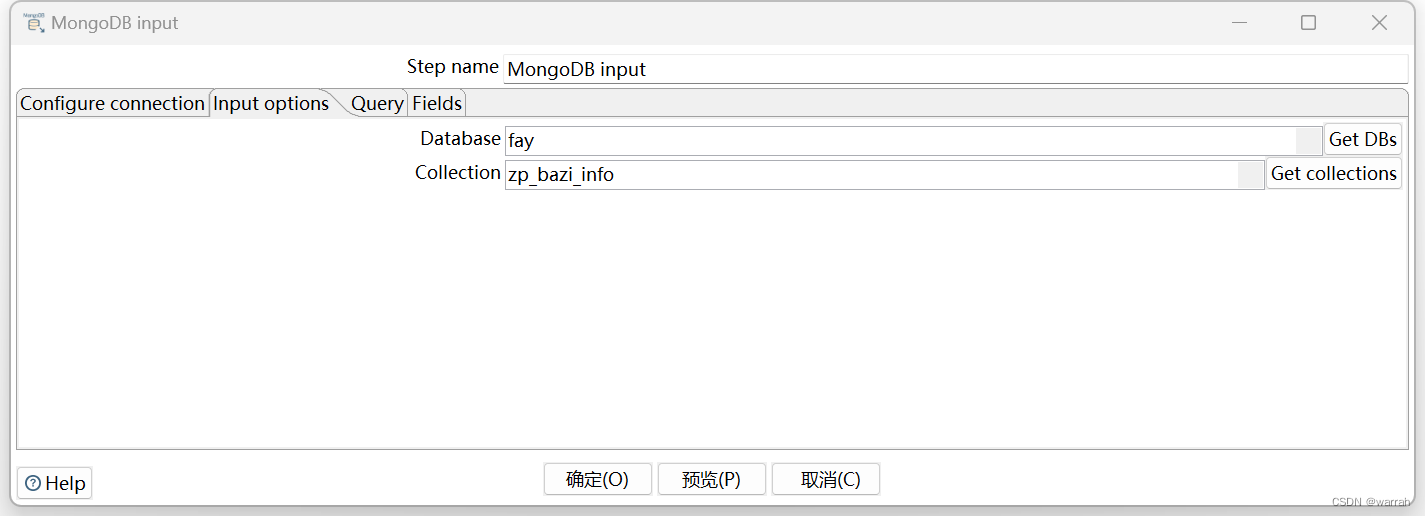
获取到mongodb的字段,获取到mongo的字段,如果某个字段是json结构,则需要自己处理一下,因为mysql中也可以使用json类型。

添加【表输出】,然后按住shift,将mongoDb input与表输出建立一条线

修正mongodb与mysql表之间的关系

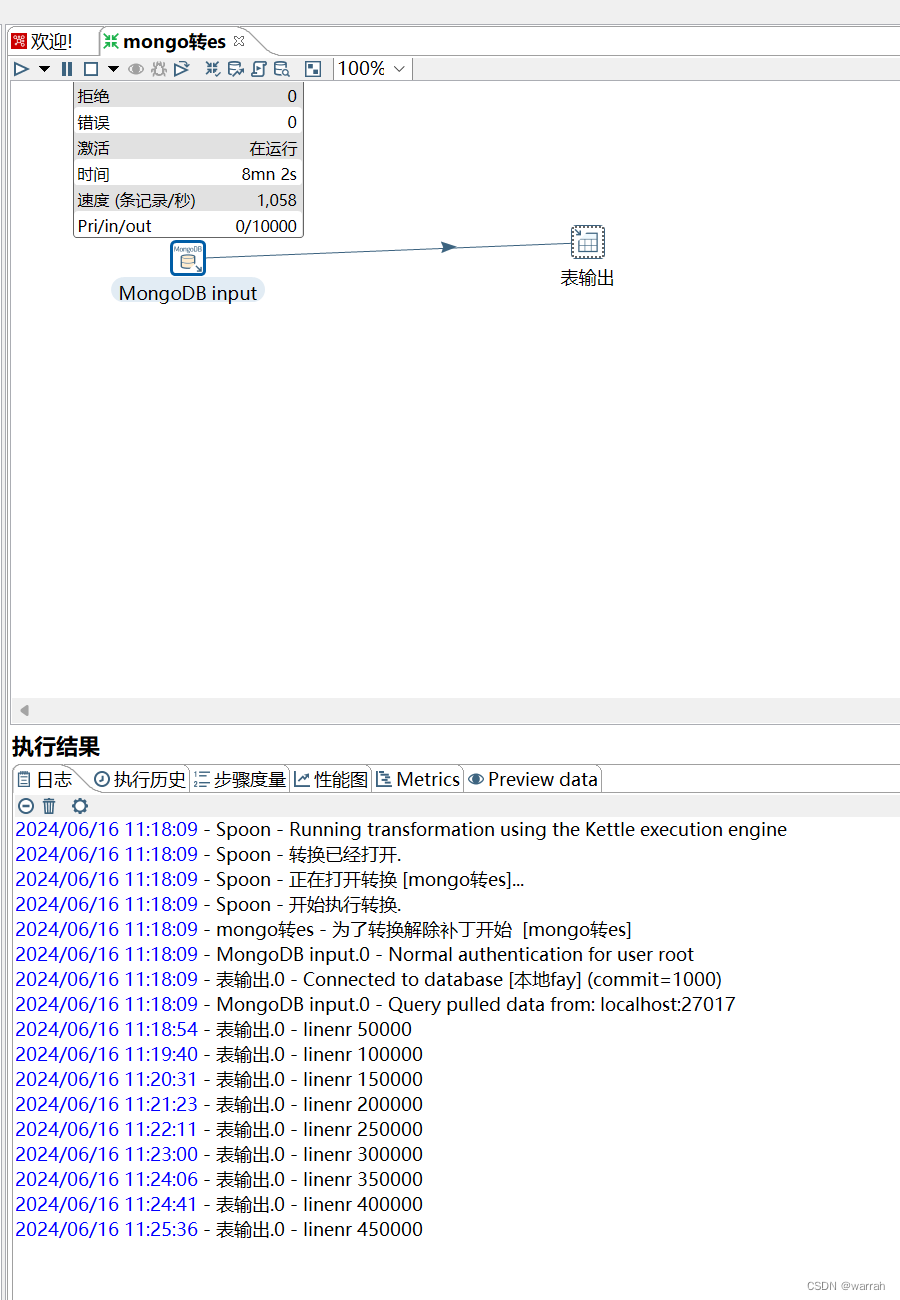
运行后,可以看到执行情况,51万数据同步花了8分钟。
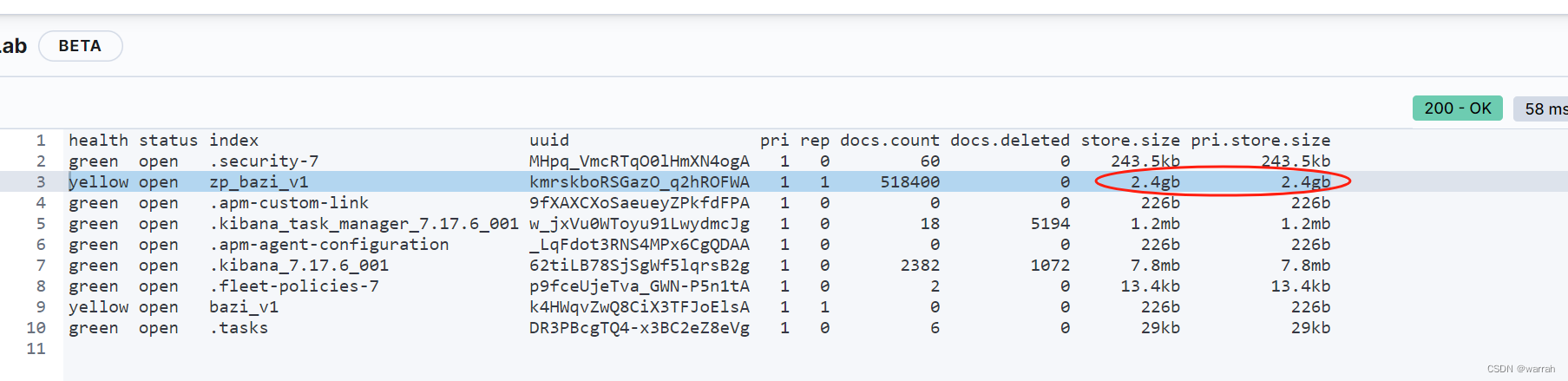
同样的数据,在mongo中存储占用了1.85GB

而mysql居然使用了14.4GB。存储空间是mongo的7.78倍,查询速度比mongo慢168倍。

在没有创建索引情况下,mysql查询需要1m45s,mongodb需要624ms。mysql如果查询没有索引,几乎无法忍受。
2 mongo同步数据到es中
使用kettle同步mongo到es中去,采用的是\elasticsearch-bulk-insert-plugin,肯定有兼容性问题
于是干脆用python写一个同步
py
from pymongo import MongoClient
from elasticsearch7 import Elasticsearch, helpers
# MongoDB连接配置
MONGO_URI = "mongodb://root:123456@127.0.0.1:27017/fay"
MONGO_DB = "fay"
MONGO_COLLECTION = "zp_bazi_info"
# Elasticsearch连接配置
ELASTICSEARCH_HOSTS = [{"host": "localhost", "port": 9200}]
ELASTICSEARCH_INDEX = "zp_bazi_v1"
# 批量提交的大小
BATCH_SIZE = 1000
# 连接MongoDB
mongo_client = MongoClient(MONGO_URI)
mongo_db = mongo_client[MONGO_DB]
mongo_collection = mongo_db[MONGO_COLLECTION]
# 连接Elasticsearch
es_auth = ('elastic', '123456')
es_client = Elasticsearch(hosts=ELASTICSEARCH_HOSTS, http_auth=es_auth)
def sync_data():
cursor = mongo_collection.find()
actions = []
for document in cursor:
es_document = {k: v for k, v in document.items() if k != '_id'}
action = {
'_index': ELASTICSEARCH_INDEX,
"_id": str(document["_id"]),
'_source': es_document
}
actions.append(action)
print('拼接action')
if len(actions) >= BATCH_SIZE:
helpers.bulk(es_client, actions)
actions = [] # 清空列表,为下一批数据做准备
print('批量提交')
if actions: # 提交剩余的数据
helpers.bulk(es_client, actions)
# 执行同步
sync_data()es的查询只需要40ms左右,比mongo的查询块15倍左右,存储空间为2.4GB,比mongodb略高。