一、背景
假设mysql库中有一张近千万的客户信息表(未分表),其中有客户性别,等级(10个等级),参与某某活动等字段
1、如果要通过等级+性别+其他条件(离散度也低)筛选出客户,如何处理查询?
2、参与活动是记录活动ID,客户每参与一个活动,就要记录客户和该活动id的关联,活动记录字段如何存储?
使用mysql存储,对应上方场景,可能会面临以下问题
1、查询条件关联字段虽然建立了索引,但是由于字段值离散度较低,导致索引失效,直接变成全表扫描
2、活动记录字段,由于要存储多值,只能设计存活动ID的json串或者符号分隔存储,直接导致该字段无法建立有效的索引
可以发现,传统的关系型数据库,面对以上场景,暂时没办法设计出合理的索引,所以会导致无法查询的情况。
为了解决以上问题,一开始方向也是使用mongoDB或者ES去进行数据异构存储,借助NoSql的结构,存储频繁变更的数据,比如,活动id字段可以直接存储为数组,也可以建立索引。
但是,由于时间、资源等关系,进行数据异构存储成本较大,所以只能寻找替代方案。
在存储方式还是使用Mysql的情况下,如何进行数据检索呢,基于上面的场景,很明显直接使用mysql查询已经走不通了,需要使用标签操作数据,在内存中进行数据的交并集操作。
所以问题就转变成了,什么样的数据结构,可以以较低的内存占用,存储海量数据,还支持交差并集等逻辑操作呢?
位图结构,完美适合标签场景,位图是过bit数组来存储数据的数据结构,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
二、技术选型
接上背景,既然选择了位图作为标签场景下的查询方案,那么应该选取哪种Bitmap实现呢?
java原生的BitSet,guava的EWAHCompressedBitmap,第三方的RoaingBitmap
注:由于标签可能每日全量更新,需要考虑内存操作且能够持久化,redis的Bitmap,在一亿数据量情况下,不拆分(取余,hash等),size为12M,推算5千万数据量size为6M,属于大key( >5M ),且大数据量Bitmap初始化,可能造成redis阻塞延迟,故暂时不考虑。
巧用RoaringBitMap处理海量数据内存diff问题 - 知乎
这里借用上方引文的测试结果:
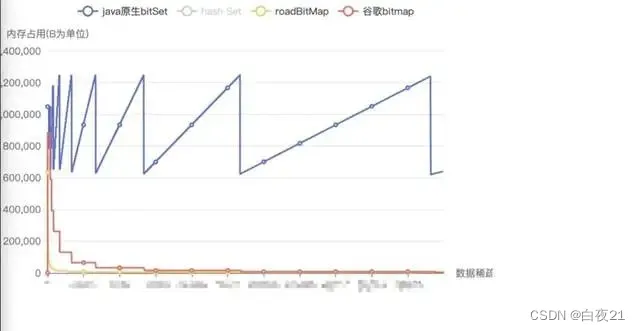
内存占用测试:往Bitmap中添加1、N+1、2N+1.....5000000数据,其中N为数据的步长(稀疏度) 来计算各个Bitmap在不同稀疏度下(N)的内存占用情况。通过下图可以看出,除了在稀疏度为1时,EWAHCompressedBitmap内存占用最低以外,其余稀疏度下的内存占用:RoaingBitmap<EWAHCompressedBitmap<BitSet。
CPU耗时测试:往各个Bitmap中添加1、N+1、2N+1.....5000000数据,其中N为数据的步长(稀疏度),然后与有5000000满数据的Bitmap分别求2000次差集并取2000次中的最大耗时,得到在每个稀疏度下每种Bitmap的耗时情况。通过下图可以看出,各个稀疏度下的cpu耗时:RoaingBitmap≈EWAHCompressedBitmap<BitSet.
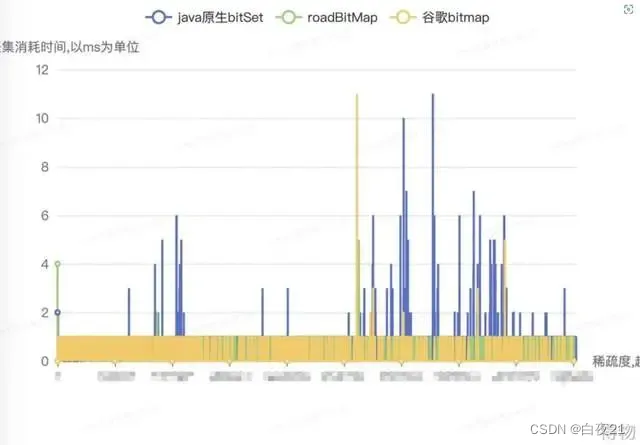
基于上方的测试数据,从内存占用,CPU耗时等方面,RoaingBitmap均要优于其他类型的位图,所以,选择RoaingBitmap作为新方案的Bitmap实现。
持久化存储:Bitmap、BitSet、RoaringBitmap持久化存储_bitset持久化-CSDN博客
api文档:RoaringBitmap 1.0.1 javadoc (org.roaringbitmap)
三、RoaingBitmap简单介绍及原理
如果你只是简单使用,那么记住:RoaringBitmap是高效压缩位图。其实就够了。
RoaringBitmap的核心思想是将整数集合按照高位划分成不同的容器,每个容器内部再使用不同的存储策略。具体而言,它将一个32位的整数分成两部分:
1、高16位作为容器的索引(container index)。
2、低16位则存储在相应的容器中。
RoaringBitmap支持两种类型的容器:
1、ArrayContainer:当一个容器内的元素数量较少(通常少于4096个)时,使用一个简单的数组来存储这些元素。这种容器适合存储稀疏的数据。
2、BitmapContainer:当容器内元素数量较多时,使用位图存储。位图是一个长数组,每个位代表一个低16位的整数是否存在。这适合存储密集型数据。
传送门:RoaringBitmap的原理与应用,看这个就够了-CSDN博客
四、存储设计
使用Mysql的longtext类型存储持久化后的RoaingBitmap。
注意:
1、Mysql字段类型:text 字段类型的字节限制为 65535 字节, 约为0.06MB;longtext 字段类型的字节限制为 2147483647 字节,约为2047MB;mediumtext 字段类型的字节限制为 16777215 字节,约为16MB。
2、mysql单次最大传输数据量限制约为16M

3、RoatingBitMap 5千万全量数据,持久化存储需要 6259385 字节,约 6M;
持久化关联Java代码,以及RoaringBitMap的逻辑i操作:
java
/**
* roaringBitmap 转 string
*
* @param roaringBitmap 入参
* @return str
*/
public static String roaringBitMapToString(RoaringBitmap roaringBitmap) {
// RoaringBitMap 转为byte数组
byte[] array = new byte[roaringBitmap.serializedSizeInBytes()];
roaringBitmap.serialize(ByteBuffer.wrap(array));
// byte转为字符串
return new String(array, StandardCharsets.ISO_8859_1);
}
/**
* string 转 roaringBitmap
*
* @param bitMapStr bitmap序列化字符串
* @return RoaringBitmap
*/
public static RoaringBitmap stringToRoaringBitMap(String bitMapStr) {
RoaringBitmap roaringBitmap = new RoaringBitmap();
try {
// str 转为 byte数组
byte[] redisArray = bitMapStr.getBytes(StandardCharsets.ISO_8859_1);
roaringBitmap.deserialize(ByteBuffer.wrap(redisArray));
} catch (IOException e) {
log.error("stringToRoaringBitMap {} Error", bitMapStr.length(), e);
}
return roaringBitmap;
}
/**
* bitMap操作
*
* @param oldBitMap bitMap_1
* @param newSubBitMap bitMap_2
* @param operate 操作符
* @return RoaringBitmap
*/
public static RoaringBitmap roaringBitMapOperate(
RoaringBitmap oldBitMap, RoaringBitmap newSubBitMap, String operate) {
switch (operate) {
case "add":
case "or":
oldBitMap.or(newSubBitMap);
break;
case "remove":
oldBitMap.andNot(newSubBitMap);
break;
case "replace":
oldBitMap = newSubBitMap;
break;
case "and":
oldBitMap.and(newSubBitMap);
break;
default:
throw new IllegalArgumentException("operate 异常" + operate);
}
return oldBitMap;
}五、压测数据准备
目标数据量 五千万 客户,10个标签,总数据量在一亿两千万左右,存储空间53MB
六、本地环境(4核8G机器)测试结果
5千万客户,标签覆盖率约为 50%,40%,30% ,20%,10%五个批次;客户随机离散分布在10个标签, 单标签平均客户量一千二百万左右,测试随机取交,并集耗时。
jmeter单线程循环调用
| 参与筛选标签数据 | 交/并集 | 取样次数 | 响应耗时中位数 | 平均数 | 响应耗时90% | 响应耗时95% | 响应耗时99% | 最小 | 最大 |
|---|---|---|---|---|---|---|---|---|---|
| 2个 | 交 | 50 | 277 | 276 | 286 | 289 | 303 | 263 | 303 |
| 2个 | 并 | 50 | 273 | 276 | 286 | 288 | 308 | 262 | 308 |
| 2个 | 随机 | 50 | 282 | 283 | 299 | 302 | 307 | 265 | 307 |
| 5个 | 交 | 50 | 702 | 712 | 746 | 755 | 792 | 664 | 792 |
| 5个 | 并 | 50 | 701 | 710 | 727 | 733 | 761 | 667 | 761 |
| 5个 | 随机 | 50 | 685 | 690 | 715 | 729 | 742 | 665 | 742 |
| 8个 | 随机 | 50 | 1145 | 1140 | 1175 | 1187 | 1202 | 1075 | 1202 |
| 10个 | 随机 | 50 | 1379 | 1387 | 1433 | 1450 | 1481 | 1336 | 1481 |
jmeter多线程循环调用 开发环境单副本 5个线程循环20次
| 参与筛选标签数据 | 交/并集 | 取样次数 | 响应耗时中位数 | 平均数 | 响应耗时90% | 响应耗时95% | 响应耗时99% | 最小 | 最大 |
|---|---|---|---|---|---|---|---|---|---|
| 2个 | 随机 | 100 | 526 | 525 | 601 | 609 | 623 | 299 | 658 |
| 5个 | 随机 | 100 | 1409 | 1448 | 1685 | 1723 | 1816 | 871 | 1897 |
| 8个 | 随机 | 100 | 2210 | 2219 | 2433 | 2468 | 2605 | 1650 | 2760 |
| 10个 | 随机 | 100 | 2789 | 2815 | 3094 | 3125 | 3308 | 2194 | 3440 |
1、任意2个标签取交、并集耗时, 各采样50次
并集测试结果

2、任意5个标签取交、并集耗时, 各采样50次
交集测试结果

3、任意8个标签随机交、并集耗时, 采样50次


4、任意10个标签随机取交、并集耗时, 各采样50次

