一、基本语法
在Oracle中START WITH......CONNECT BY......一般用来查找存在父子关系的数据,也就是树形结构的数据。
sql
SELECT * FROM TABLE WHERE 条件3 START WITH 条件1 CONNECT BY 条件2;-
start with`condition`:设置起点,用来限制第一层的数据,或者叫根节点数据;以这部分数据为基础来查找第二层数据,然后以第二层数据查找第三层数据以此类推。省略后默认以全部行为起点。 -
connect by`condition` :用来指明在查找数据时以怎样的一种关系去查找;比如说查找第二层的数据时用第一层数据某个字段进行匹配,如果这个条件成立那么查找出来的数据就是第二层数据,同理往下递归匹配。 -
prior: 表示上一层级的标识符。经常用来对下一层级的数据进行限制。不可以接伪列。prior在等号前面和后面,查询的数据是不一样的 -
level:伪列(关键字),代表树形结构中的层级编号(数字序列结果集),这个必须配合connect by使用,和rownum是同等效果。 -
connect_by_root:显示根节点列。经常用来分组。 -
connect_by_isleaf:1是叶子节点,0不是叶子节点。在制作树状表格时必用关键字。 -
sys_connect_by_path():将递归过程中的列进行拼接。 -
nocycle、connect_by_iscycle:在有循环结构的查询中使用。 -
siblings: 保留树状结构,对兄弟节点进行排序。
二、数据列表展示
2.1 向下查找
查询以organ_id为2开始的节点的所有直属节点:
sql
select t.organ_id, t.parent_id, t.organ_abbr,level
from tem_organ_0619 t
start with t.organ_id = 2
connect by prior t.organ_id = t.parent_id
order by t.organ_id;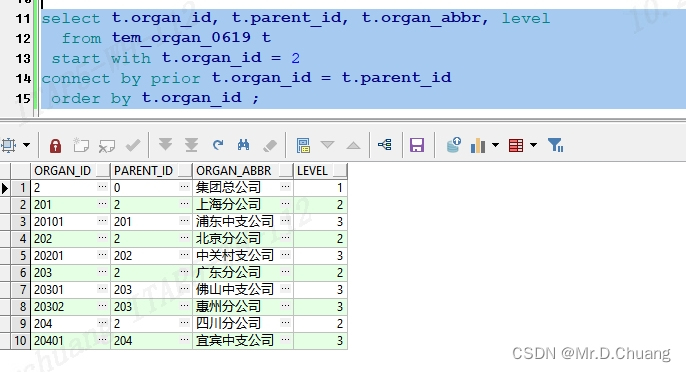
不设置开始节点:
sql
select t.organ_id, t.parent_id, t.organ_abbr,level
from tem_organ_0619 t
-- start with t.organ_id = 2
connect by prior t.organ_id = t.parent_id
order by t.organ_id;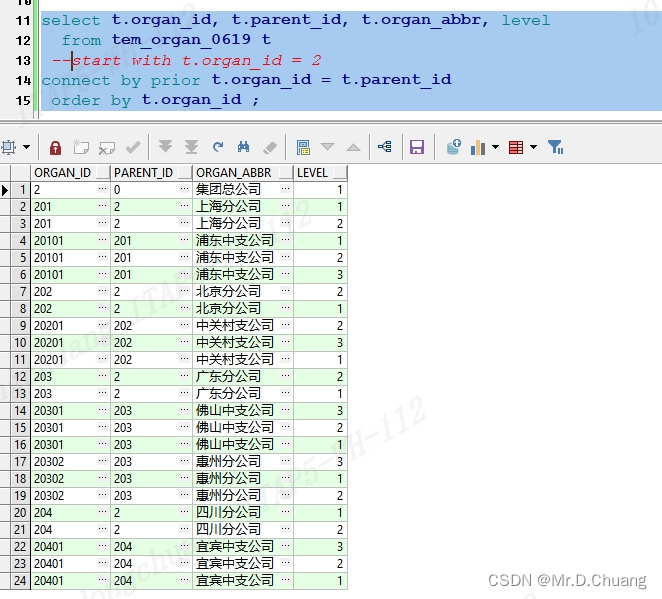
2.2 向上查找
sql
select t.organ_id, t.parent_id, t.organ_abbr,level
from tem_organ_0619 t
start with t.organ_id = 20401
connect by t.organ_id = prior t.parent_id
order by t.organ_id;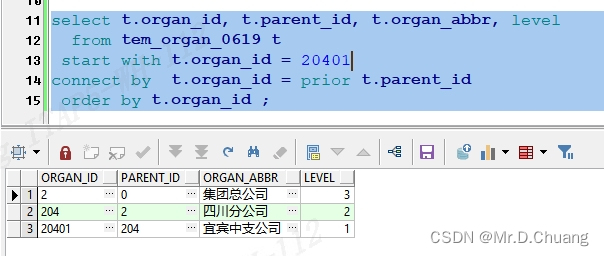
2.3 level伪列的使用,格式化层级
sql
select t.organ_id, t.parent_id, lpad(' ',level*4,' ')||t.organ_abbr organ_abbr,level
from tem_organ_0619 t
start with t.organ_id = 2
connect by t.organ_id = prior t.parent_id
order by t.organ_id;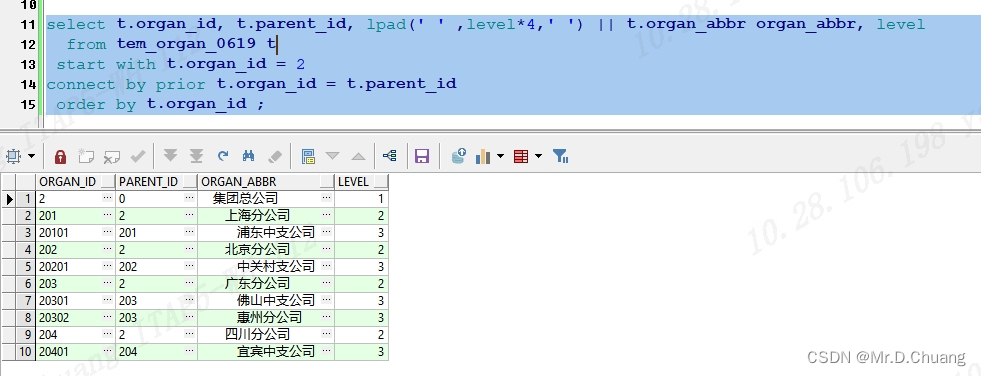
2.4 connect_by_root查找根节点
sql
select t.organ_id,
t.parent_id,
lpad(' ',level*4,' ')||t.organ_abbr organ_abbr,
level ,
connect_by_root t.organ_id
from tem_organ_0619 t
start with t.organ_id = 2
connect by t.organ_id = prior t.parent_id
order by t.organ_id;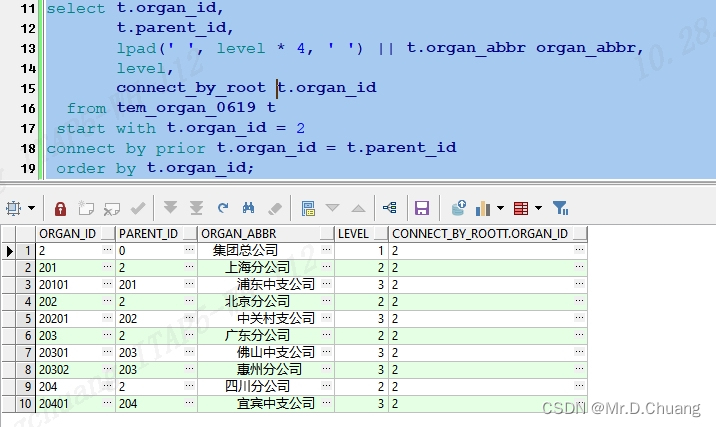
2.5 connect_by_isleaf是否是叶子节点
sql
select t.organ_id,
t.parent_id,
lpad(' ',level*4,' ')||t.organ_abbr organ_abbr,
level ,
connect_by_root t.organ_id,
connect_by_isleaf
from tem_organ_0619 t
start with t.organ_id = 2
connect by t.organ_id = prior t.parent_id
order by t.organ_id;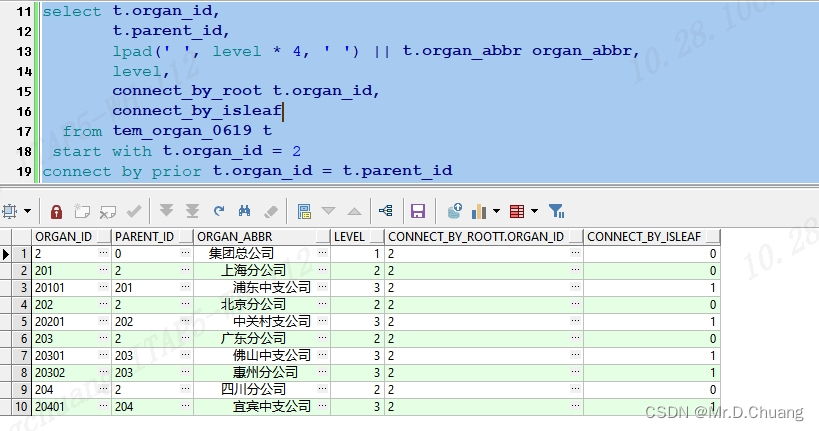
2.6 其他
sql
select t.organ_id,
t.parent_id,
lpad(' ',level*4,' ')||t.organ_abbr organ_abbr,
level 层级,
sys_connect_by_path(t.organ_id, '<-') 合并层次,
PRIOR t.organ_id 父节点,
connect_by_root t.organ_id 根节点,
decode(connect_by_isleaf, 1, '是', '否') 是否子节点,
decode(connect_by_isleaf, 1, t.organ_id, '') 子节点
from tem_organ_0619 t
start with t.organ_id = 2
connect by t.organ_id = prior t.parent_id
order by t.organ_id;