一、引言
在数字支付与电商高速发展的今天,交易欺诈已成为金融与商业领域的顽疾。传统的反欺诈方案多依赖规则引擎或机器学习分类模型,存在规则僵化、对新型欺诈模式响应滞后、高误报率等痛点。
随着技术的迭代演进,针对交易行为的分析决策也有了新的思路,将交易行为转化为向量并存入向量数据库,通过检索偏离正常行为的向量实现毫秒级欺诈检测,将响应时间从分钟级压缩至毫秒级,大幅提升了风控效率与准确性。今天我们将由浅入深拆解这一技术方案,从核心概念、技术原理、实现流程到代码示例,全面解析如何利用向量数据库构建实时交易反欺诈系统。

二、核心概念解析
在深入技术交流前,我们需要厘清三个关键概念:交易行为向量、向量数据库、异常向量检索。
1. 交易行为向量
交易行为本身是一组多维度的离散或连续特征,将这些特征映射到高维向量空间中,就形成了交易行为向量。一个典型的交易行为特征集合包括:
- 用户维度:用户注册时长、历史交易频次、常用支付设备、常用收货地址
- 交易维度:交易金额、交易时间、商品类型、支付方式
- 环境维度:IP 地址归属地、设备操作系统、网络类型(Wi-Fi/4G)
例如,一笔交易的原始特征可能是:
python
{
"user_reg_days": 180,
"history_trade_count": 56,
"trade_amount": 299.9,
"trade_hour": 20,
"is_common_device": 1,
"ip_city": "北京"
}通过特征标准化、编码(如 IP 地址经纬度编码、商品类型独热编码)后,即可转化为一个固定长度的高维向量,例如 0.52, 0.31, 0.85, 0.78, 1.0, 0.63。这个向量就代表了该笔交易的行为特征指纹。
我们对这些特征进行详细说明,并分析这些特性在特定场景下表现得特征:
1.1 字段含义与详细说明
- **user_reg_days:**用户注册天数,衡量用户账号成熟度:新账号(注册天数 < 30)欺诈风险远高于老账号,如示例中 180 天为稳定账号
- **history_trade_count:**用户历史交易总次数,衡量用户交易活跃度:高频交易用户(如示例中 56 次)欺诈概率低,低频/零交易用户风险高
- **trade_amount:**本次交易金额(单位:元),核心风险特征:偏离用户历史交易金额均值(如示例 299.9 元)的大额/小额交易需重点警惕
- **trade_hour:**交易发生的小时(24 小时制),衡量交易时间合理性:示例中 20 点(晚 8 点)为用户常用交易时段,凌晨 3 点交易则异常
- **is_common_device:**是否为用户常用设备(1 = 是,0 = 否),设备指纹核心特征:陌生设备(0)交易是欺诈最高频信号之一,示例中 1 为安全信号
- **ip_city:**交易 IP 归属城市,衡量地域一致性:示例中「北京」若为用户常用交易城市则安全,异地(如突然出现境外)则异常
1.2 各字段的反欺诈价值
1.2.1 基础风控维度:账号健康度(user_reg_days + history_trade_count)
- 欺诈场景关联:欺诈分子常批量注册短期账户(注册天数 < 7 天)、零交易记录的账号实施诈骗,而正常用户的账号会随使用时间积累交易行为;
- 量化风控规则:可设定阈值(如user_reg_days<15 且 history_trade_count<3)直接标记为高风险账号,示例中 180 天 + 56 次交易属于低风险账号特征。
1.2.2 核心交易特征:金额与时间(trade_amount + trade_hour)
- 交易金额:
- 正常用户的交易金额存在「消费习惯」(如示例中 299.9 元可能是该用户的日常消费区间);
- 欺诈特征:突然出现远高于均值的大额交易(如 9999 元)或异常小额交易(如 0.1 元,测试账号有效性);
- 交易时间:
- 正常用户的交易时间集中在活跃时段(如示例中 20 点为晚间消费高峰);
- 欺诈特征:凌晨 2-6 点的交易,此时属于用户睡眠时段
1.2.3 环境风控维度:设备与地域(is_common_device + ip_city)
- 设备维度(is_common_device):
- 设备指纹是反欺诈的「硬证据」:正常用户 90% 以上的交易发生在常用手机 / 电脑(示例中 1 = 常用设备,安全);
- 欺诈特征:同一账号突然在陌生设备(如网吧电脑、境外手机)登录并交易,是盗号欺诈的核心信号;
- 地域维度(ip_city):
- 地域一致性验证:示例中「北京」若与用户收货地址、绑卡地址一致,则风险低;
- 欺诈特征:IP 城市与用户常用地域跨省市 / 跨境(如北京账号突然出现广东 IP、东南亚 IP),需触发二次验证。、非工作日凌晨交易,均为异常信号。
1.3 字段向量化的意义
这些字段最终会被转化为高维向量,核心价值在于:
-
- 消除特征孤立性:单独看"北京 IP"或"20 点交易"均为正常,但结合"陌生设备 + 凌晨 3 点 + 大额交易"则为异常,向量可整合多维度特征的关联性;
-
- 量化相似性:向量数据库通过计算"当前交易向量"与"用户历史正常交易向量"的相似度,判断是否偏离正常行为模式,如示例中的向量属于正常行为簇,而异常交易向量会远离该簇;
-
- 实时风控效率:相较于传统规则引擎的硬阈值判断,向量的相似度检索可捕捉隐性异常,如所有字段均未超阈值,但组合特征偏离正常模式,且响应速度非常及时和快速。
1.4 实际应用强化
针对该特征集合,可进一步补充维度提升反欺诈准确性:
-
- 时序特征:last_trade_interval(距上一次交易的间隔,正常用户交易间隔稳定,欺诈交易常为突然交易);
-
- 行为特征:trade_merchant_type(交易商户类型,如示例中 299.9 元若为用户常用的电商商户则安全,突然交易虚拟币商户则异常);
-
- 网络特征:ip_type(IP 类型,如示例中"北京 IP"若为家庭宽带则安全,若为代理 IP/机房 IP 则异常);
-
- 编码优化:ip_city为文本内容,需通过独热编码或嵌入编码 转化为数值向量(如北京 = 0.63,上海 = 0.45),才能融入高维向量空间。
1.5 行为特征总结
该特征集合覆盖了账号、交易、环境三大核心风控维度,是交易行为向量化的基础:
- 单个字段可作为基础规则筛选明显异常;
- 多字段组合形成的向量,可捕捉隐性异常,无单字段超阈值,但整体行为偏离;
- 向量数据库通过检索这些特征向量的相似度,实现从规则驱动到行为模式驱动的反欺诈升级,这也是能将响应时间大幅提升的核心原因。
2. 向量数据库
向量数据库是专门用于存储、索引和检索高维向量的数据库系统,其核心能力是相似性检索。与传统关系型数据库不同,向量数据库不依赖主键匹配,而是通过计算向量间的距离(如欧氏距离、余弦相似度)判断向量的相似程度。
主流向量数据库包括 ChromaDB、Milvus、Pinecone 等,它们具备以下核心特性:
- 高效的向量索引算法(如 HNSW、IVF_FLAT),支撑百万级/亿级向量的毫秒级检索
- 支持动态增删改查,适配实时交易场景的高并发写入
- 提供相似度阈值配置,灵活定义"正常"与"异常"的边界
3. 异常向量检索
异常向量检索的核心逻辑是:正常交易行为的向量会在向量空间中形成密集的聚类,而欺诈交易的向量会偏离这些聚类,处于向量空间的稀疏区域。
具体来说,系统会先基于用户历史正常交易向量构建用户级正常行为向量库,当新交易产生时,将其向量与用户正常向量库中的向量进行相似度检索:
- 若检索到足够多的相似向量,相似度高于阈值,判定为正常交易
- 若未检索到相似向量,相似度低于阈值,判定为异常交易,触发风控审核
**向量检索的核心优化点正在于此:**通过向量数据库的高效检索能力,将传统模型"批量计算 - 离线更新"的模式升级为"实时检索 - 即时判断",实现毫秒级响应。
三、技术实现流程
基于向量数据库的实时交易反欺诈系统,整体流程可分为四个核心步骤,我们用流程图清晰展示:

1. 交易数据采集
数据采集是系统的基础,需要实时捕获每一笔交易的全维度特征。在实际工程中,通常通过埋点系统、交易中台接口、用户画像系统整合数据,输出包含用户、交易、环境维度的结构化数据。
2. 行为特征向量化
特征向量化是核心环节,直接决定后续检索的准确性。该步骤分为两个子流程:
2.1 特征预处理
- 数值型特征标准化:将 user_reg_days trade_amount 等特征映射到 0,1 区间,消除量纲影响
- 类别型特征编码:对 ip_city payment_method 等特征进行独热编码或嵌入编码
- 异常值处理:对明显不合理的特征值(如交易金额为负数)进行清洗
2.2 向量生成
预处理后的特征集合通过拼接或加权组合,生成固定长度的高维向量。例如,将 10 个预处理后的特征拼接为长度为 10 的向量,或通过深度学习模型(如 DNN)生成更具代表性的嵌入向量。
3. 向量入库与索引
将生成的交易行为向量存入向量数据库,并构建高效索引。需要注意两个关键点:
- 分库策略:建议按用户 ID 分库,每个用户对应一个独立的正常行为向量集合,避免不同用户的行为向量交叉干扰
- 索引选择:实时场景优先选择 HNSW 索引,兼顾检索速度与精度;离线聚类分析可选择 IVF_FLAT 索引
4. 异常向量检索与风控决策
当新交易产生时,执行以下检索流程:
-
- 将新交易向量输入向量数据库,检索该用户正常向量库中相似度最高的 Top-K 向量
-
- 计算新向量与 Top-K 向量的平均余弦相似度
-
- 若平均相似度低于预设阈值,判定为异常交易,触发拦截或人工审核;反之则判定为正常交易
四、案例分析
1. 基于 ChromaDB 实现交易反欺诈
我们以 ChromaDB 为例,实现一个简化版的交易行为向量存储与异常检索系统。
1.1 数据预处理与向量生成
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import chromadb
from chromadb.config import Settings
import os
import logging
# ===================== 1. 配置详细日志(控制台+文件) =====================
# 日志配置:输出级别、格式、存储路径
log_dir = "./logs"
if not os.path.exists(log_dir):
os.makedirs(log_dir)
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[
logging.StreamHandler(), # 控制台输出
logging.FileHandler(f"{log_dir}/fraud_detection.log", encoding="utf-8") # 文件存储
]
)
logger = logging.getLogger("交易反欺诈系统")
# ===================== 2. 初始化ChromaDB(适配新版) =====================
persist_directory = "./chroma_persist"
if not os.path.exists(persist_directory):
os.makedirs(persist_directory)
logger.info(f"创建ChromaDB持久化目录:{persist_directory}")
# 初始化持久化客户端
client = chromadb.PersistentClient(
path=persist_directory,
settings=Settings(
allow_reset=True,
anonymized_telemetry=False
)
)
client.reset()
logger.info("重置ChromaDB数据库(测试环境)")
# ===================== 3. 定义核心配置(便于维护) =====================
# 风控阈值配置
FRAUD_THRESHOLD = 0.7 # 相似度阈值:低于此值判定为异常
TOP_K = 3 # 检索相似向量数量
USER_ID = "U001" # 目标用户ID
NORMAL_TRADE_NUM = 4 # 正常交易样本数
# 输出核心配置日志
logger.info("="*50)
logger.info("【核心风控配置】")
logger.info(f"异常交易判定阈值:余弦相似度 < {FRAUD_THRESHOLD}")
logger.info(f"检索相似向量数量:Top-{TOP_K}")
logger.info(f"目标分析用户:{USER_ID}")
logger.info(f"正常交易样本数量:{NORMAL_TRADE_NUM}")
logger.info("="*50)
# ===================== 4. 数据预处理与向量化 =====================
# 模拟交易数据
data = pd.DataFrame({
"user_id": ["U001", "U001", "U001", "U001", "U001", "U001"],
"user_reg_days": [180, 180, 180, 180, 180, 180],
"history_trade_count": [56, 57, 58, 59, 60, 61],
"trade_amount": [299.9, 199.0, 399.5, 499.0, 10.0, 9999.0],
"trade_hour": [20, 19, 21, 20, 3, 23],
"is_common_device": [1, 1, 1, 1, 0, 0]
})
logger.info(f"加载交易数据:共{len(data)}条,其中前{NORMAL_TRADE_NUM}条为正常交易,后{len(data)-NORMAL_TRADE_NUM}条为待检测交易")
# 特征预处理
scaler = MinMaxScaler(feature_range=(0, 1))
feature_cols = ["user_reg_days", "history_trade_count", "trade_amount", "trade_hour", "is_common_device"]
data_scaled = scaler.fit_transform(data[feature_cols])
vectors = data_scaled.tolist()
metadatas = [{"user_id": row["user_id"], "trade_id": f"T{idx}"} for idx, row in data.iterrows()]
ids = [f"T{idx}" for idx in range(len(vectors))]
# 输出向量维度日志
logger.info(f"特征列:{feature_cols}")
logger.info(f"向量维度:{len(vectors[0])}维")
logger.info(f"示例向量(T0):{vectors[0]}")1.2 向量存入 ChromaDB
python
# ===================== 5. 正常交易向量入库 =====================
collection_name = f"user_{USER_ID}_normal_trades"
# 删除旧集合
try:
client.delete_collection(name=collection_name)
logger.info(f"删除已存在的集合:{collection_name}")
except Exception as e:
logger.warning(f"集合{collection_name}不存在,无需删除:{e}")
# 创建新集合
collection = client.create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"} # 余弦相似度空间
)
logger.info(f"创建用户{USER_ID}的正常交易向量集合:{collection_name}")
# 入库正常交易向量
normal_vectors = vectors[:NORMAL_TRADE_NUM]
normal_metadatas = metadatas[:NORMAL_TRADE_NUM]
normal_ids = ids[:NORMAL_TRADE_NUM]
try:
collection.add(
embeddings=normal_vectors,
metadatas=normal_metadatas,
ids=normal_ids
)
logger.info(f"正常交易向量入库完成:{len(normal_vectors)}条")
logger.info(f"入库向量ID:{normal_ids}")
logger.info(f"集合当前向量总数:{collection.count()}")
except Exception as e:
logger.error(f"正常向量入库失败:{str(e)}", exc_info=True)
# ===================== 6. 异常交易检测(带详细日志) =====================
logger.info("\n" + "="*50)
logger.info("开始检测异常交易")
logger.info("="*50)1.3 异常向量检索
python
# 待检测向量(异常样本)
test_vectors = vectors[NORMAL_TRADE_NUM:]
test_metadatas = metadatas[NORMAL_TRADE_NUM:]
test_ids = ids[NORMAL_TRADE_NUM:]
for idx, (vector, meta, trade_id) in enumerate(zip(test_vectors, test_metadatas, test_ids)):
logger.info(f"\n--- 检测交易 {trade_id} ---")
# 输出待检测交易原始特征
raw_data = data.iloc[NORMAL_TRADE_NUM + idx]
logger.info(f"原始特征:{raw_data.to_dict()}")
logger.info(f"待检测向量:{vector}")
# 检索相似向量
try:
results = collection.query(
query_embeddings=[vector],
n_results=TOP_K,
where={"user_id": USER_ID}
)
# 解析检索结果
retrieved_ids = results["ids"][0]
retrieved_distances = results["distances"][0]
retrieved_metadatas = results["metadatas"][0]
# 输出检索结果日志
logger.info(f"检索到Top-{TOP_K}相似正常交易:{retrieved_ids}")
logger.info(f"余弦距离(越小越相似):{[round(d, 4) for d in retrieved_distances]}")
# 计算平均相似度(余弦相似度=1-余弦距离)
avg_distance = np.mean(retrieved_distances) if retrieved_distances else 1.0
avg_similarity = 1 - avg_distance
logger.info(f"计算过程:平均余弦距离={round(avg_distance, 4)} → 平均余弦相似度={round(avg_similarity, 4)}")
# 风控决策
if avg_similarity < FRAUD_THRESHOLD:
logger.warning(f"【异常交易判定】交易{trade_id}:平均相似度{round(avg_similarity, 4)} < 阈值{FRAUD_THRESHOLD}")
logger.warning(f"判定原因:该交易行为向量与用户{USER_ID}的正常交易向量相似度过低,偏离正常行为模式")
print(f"\n交易 {trade_id}:平均相似度 {avg_similarity:.2f} → 🚨 异常交易,触发风控")
else:
logger.info(f"【正常交易判定】交易{trade_id}:平均相似度{round(avg_similarity, 4)} ≥ 阈值{FRAUD_THRESHOLD}")
logger.info(f"判定原因:该交易行为向量与用户{USER_ID}的正常交易向量高度相似,符合正常行为模式")
print(f"\n交易 {trade_id}:平均相似度 {avg_similarity:.2f} → ✅ 正常交易")
except Exception as e:
logger.error(f"检测交易{trade_id}失败:{str(e)}", exc_info=True)
print(f"\n交易 {trade_id}:检测失败 → ❌ 触发风控审核")
logger.info("\n" + "="*50)
logger.info("异常交易检测流程结束")
logger.info("="*50)1.4 运行结果
2025-12-23 18:10:41,915 - INFO - 重置ChromaDB数据库
2025-12-23 18:10:41,915 - INFO - ==========================================
2025-12-23 18:10:41,916 - INFO - 【核心风控配置】
2025-12-23 18:10:41,916 - INFO - 异常交易判定阈值:余弦相似度 < 0.7
2025-12-23 18:10:41,916 - INFO - 检索相似向量数量:Top-3
2025-12-23 18:10:41,916 - INFO - 目标分析用户:U001
2025-12-23 18:10:41,916 - INFO - 正常交易样本数量:4
2025-12-23 18:10:41,916 - INFO - ==========================================
2025-12-23 18:10:41,918 - INFO - 加载交易数据:共6条,其中前4条为正常交易,后2条为待检测交易
2025-12-23 18:10:41,924 - INFO - 特征列:'user_reg_days', 'history_trade_count', 'trade_amount', 'trade_hour', 'is_common_device'
2025-12-23 18:10:41,924 - INFO - 向量维度:5维
2025-12-23 18:10:41,924 - INFO - 示例向量(T0):0.0, 0.0, 0.029021924116528177, 0.85, 1.0
2025-12-23 18:10:41,926 - WARNING - 集合user_U001_normal_trades不存在,无需删除:Collection user_U001_normal_trades does not exist.
2025-12-23 18:10:41,977 - INFO - 创建用户U001的正常交易向量集合:user_U001_normal_trades
2025-12-23 18:10:42,012 - INFO - 正常交易向量入库完成:4条
2025-12-23 18:10:42,012 - INFO - 入库向量ID:'T0', 'T1', 'T2', 'T3'
2025-12-23 18:10:42,014 - INFO - 集合当前向量总数:4
2025-12-23 18:10:42,014 - INFO - ===========================================
2025-12-23 18:10:42,015 - INFO - 开始检测异常交易
2025-12-23 18:10:42,015 - INFO - ===========================================
2025-12-23 18:10:42,015 - INFO ---- 检测交易 T4 ---
2025-12-23 18:10:42,016 - INFO - 原始特征:{'user_id': 'U001', 'user_reg_days': 180, 'history_trade_count': 60, 'trade_amount': 10.0, 'trade_hour': 3, 'is_common_device': 0}
2025-12-23 18:10:42,016 - INFO - 待检测向量:0.0, 0.7999999999999989, 0.0, 0.0, 0.02025-12-23 18:10:42,022 - INFO - 检索到Top-3相似正常交易:'T3', 'T2', 'T1'
2025-12-23 18:10:42,022 - INFO - 余弦距离(越小越相似):0.5845, 0.7151, 0.8457
2025-12-23 18:10:42,023 - INFO - 计算过程:平均余弦距离=0.7151 → 平均余弦相似度=0.2849
2025-12-23 18:10:42,023 - WARNING - 【异常交易判定】交易T4:平均相似度0.2849 < 阈值0.7
2025-12-23 18:10:42,024 - WARNING - 判定原因:该交易行为向量与用户U001的正常交易向量相似度过低,偏离正常行为模式
交易 T4:平均相似度 0.28 → 🚨 异常交易,触发风控
2025-12-23 18:10:42,025 - INFO ---- 检测交易 T5 ---
2025-12-23 18:10:42,026 - INFO - 原始特征:{'user_id': 'U001', 'user_reg_days': 180,
'history_trade_count': 61, 'trade_amount': 9999.0, 'trade_hour': 23, 'is_common_device': 0}
2025-12-23 18:10:42,026 - INFO - 待检测向量:0.0, 1.0, 1.0, 1.0, 0.0
2025-12-23 18:10:42,034 - INFO - 检索到Top-3相似正常交易:'T3', 'T2', 'T1'
2025-12-23 18:10:42,035 - INFO - 余弦距离(越小越相似):0.4006, 0.4494, 0.5462
2025-12-23 18:10:42,036 - INFO - 计算过程:平均余弦距离=0.4654 → 平均余弦相似度=0.5346
2025-12-23 18:10:42,037 - WARNING - 【异常交易判定】交易T5:平均相似度0.5346 < 阈值0.7
2025-12-23 18:10:42,037 - WARNING - 判定原因:该交易行为向量与用户U001的正常交易向量相似度过低,偏离正常行为模式
交易 T5:平均相似度 0.53 → 🚨 异常交易,触发风控
2025-12-23 18:10:42,038 - INFO - ===========================================
2025-12-23 18:10:42,038 - INFO - 异常交易检测流程结束
2025-12-23 18:10:42,038 - INFO - ===========================================
可以看到,两条异常交易向量与正常向量的相似度均低于阈值,被成功识别。
2. 交易反欺诈可视化展示
在示例1的基础上优化,通过 matplotlib 生成交易特征对比图、相似度分布直方图、正常/异常向量空间分布图,直观展示异常交易的判定依据,并补充了细化的特征异常度分析:
2.1 细化分析维度
- 特征异常度分析:对核心特征(交易金额、交易时间、设备是否常用)计算偏离度(相对差值),明确指出哪些特征偏离正常范围(偏离度 > 50% 判定为异常特征);
- 多维度判定原因:结合"特征偏离度+向量相似度"双维度给出判定原因,而非仅依赖相似度;
- 量化分析:对每个特征的正常均值、当前值、偏离百分比进行量化输出。
2.2 可视化输出
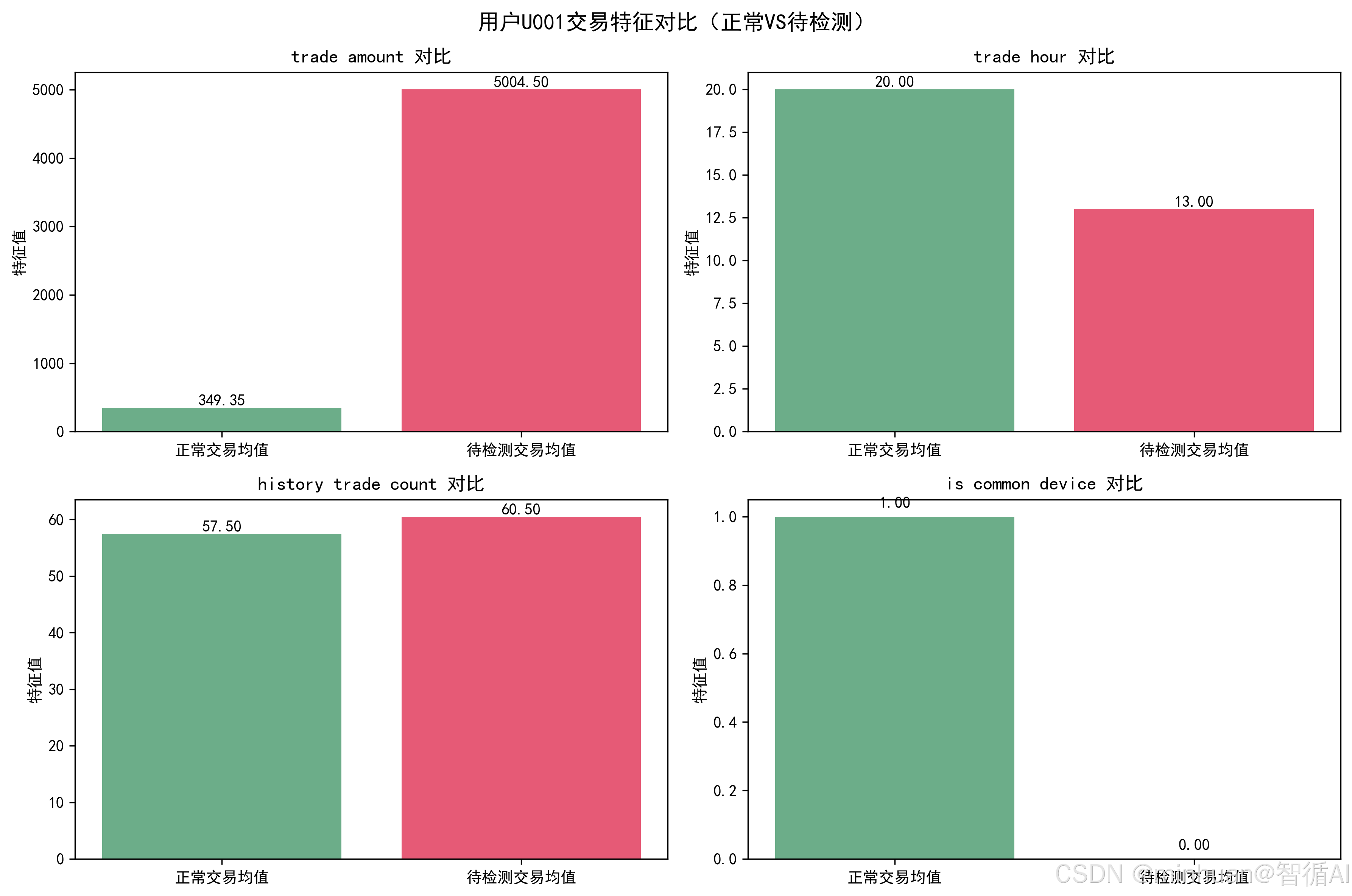
- 交易特征对比图:直观展示正常/待检测交易在核心特征上的均值差异(金额、时间、设备等)
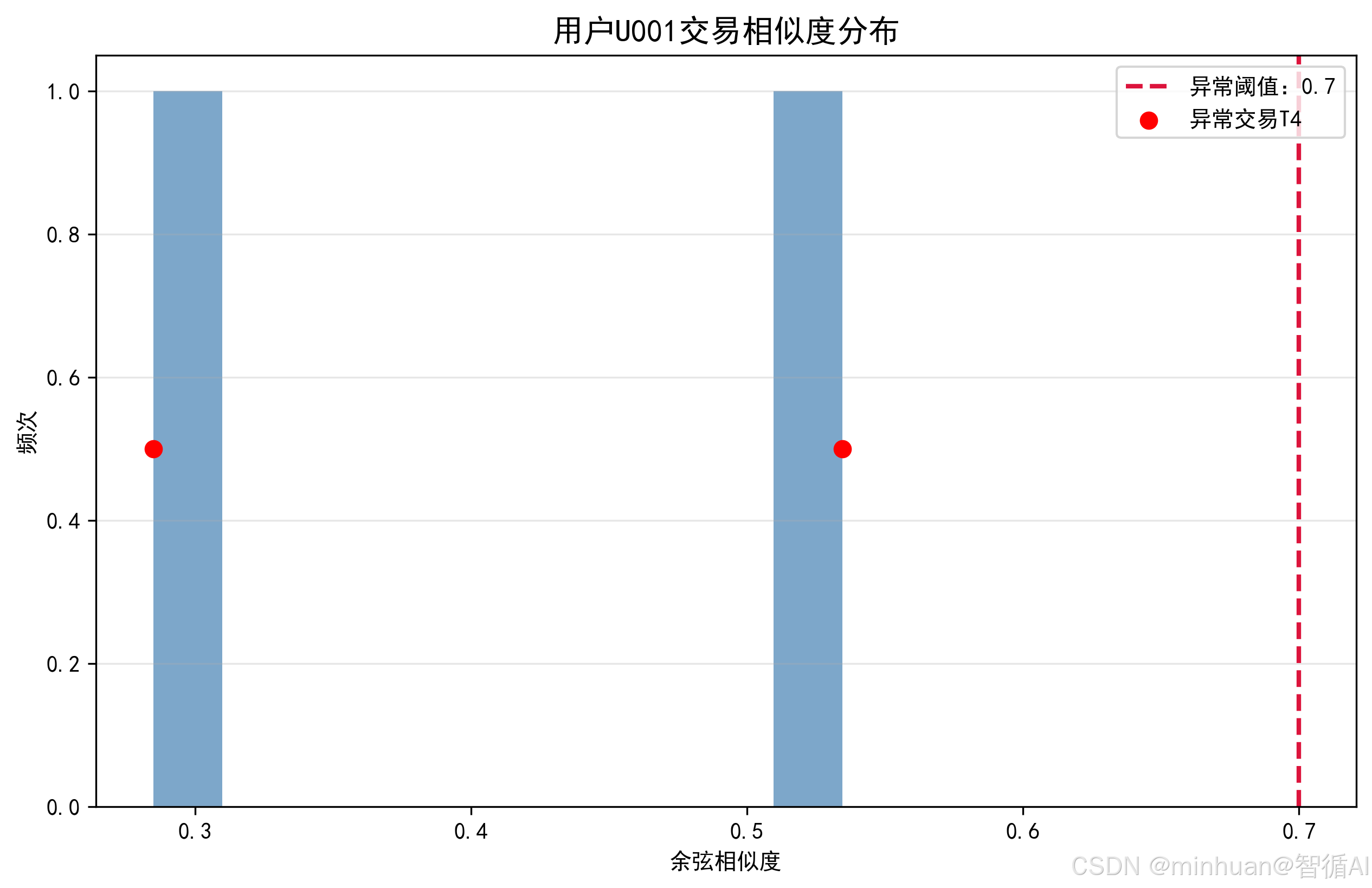
- 相似度分布直方图:展示待检测交易的相似度分布,标注异常阈值线和异常交易位置
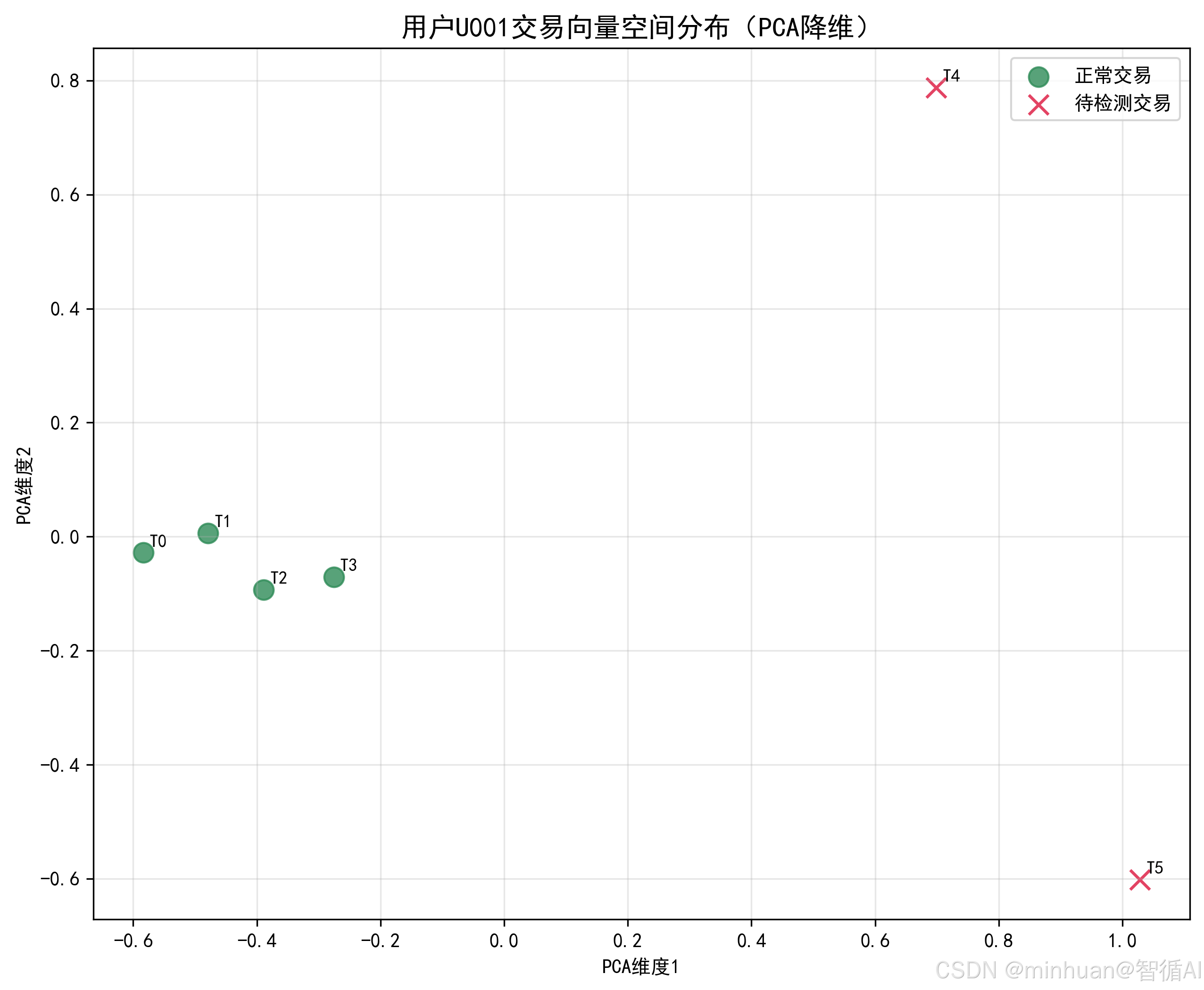
- 向量空间分布图(PCA 降维):将高维向量降维到 2D 空间,展示正常交易聚类、异常交易偏离的空间特征
2.3 完整示例
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import chromadb
from chromadb.config import Settings
import os
import logging
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
import seaborn as sns
img_dir = "./analysis_imgs"
for dir_path in [img_dir]:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
# 设置中文字体(避免乱码)
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# ===================== 2. 初始化ChromaDB =====================
persist_directory = "./chroma_persist"
if not os.path.exists(persist_directory):
os.makedirs(persist_directory)
print(f"创建ChromaDB持久化目录:{persist_directory}")
client = chromadb.PersistentClient(
path=persist_directory,
settings=Settings(allow_reset=True, anonymized_telemetry=False)
)
client.reset()
print("重置ChromaDB数据库(测试环境)")
# ===================== 3. 核心配置 =====================
FRAUD_THRESHOLD = 0.7 # 相似度阈值
TOP_K = 3 # 检索相似向量数量
USER_ID = "U001"
NORMAL_TRADE_NUM = 4
print("="*50)
print("【核心风控配置】")
print(f"异常交易判定阈值:余弦相似度 < {FRAUD_THRESHOLD}")
print(f"检索相似向量数量:Top-{TOP_K}")
print(f"目标分析用户:{USER_ID}")
print(f"正常交易样本数量:{NORMAL_TRADE_NUM}")
print("="*50)
# ===================== 4. 数据预处理与向量化 =====================
# 模拟交易数据
data = pd.DataFrame({
"user_id": ["U001", "U001", "U001", "U001", "U001", "U001"],
"user_reg_days": [180, 180, 180, 180, 180, 180],
"history_trade_count": [56, 57, 58, 59, 60, 61],
"trade_amount": [299.9, 199.0, 399.5, 499.0, 10.0, 9999.0],
"trade_hour": [20, 19, 21, 20, 3, 23],
"is_common_device": [1, 1, 1, 1, 0, 0]
})
# 标记交易类型(正常/待检测)
data["trade_type"] = ["正常"]*NORMAL_TRADE_NUM + ["待检测"]*(len(data)-NORMAL_TRADE_NUM)
print(f"加载交易数据:共{len(data)}条,其中前{NORMAL_TRADE_NUM}条为正常交易,后{len(data)-NORMAL_TRADE_NUM}条为待检测交易")
# 特征预处理
scaler = MinMaxScaler(feature_range=(0, 1))
feature_cols = ["user_reg_days", "history_trade_count", "trade_amount", "trade_hour", "is_common_device"]
data_scaled = scaler.fit_transform(data[feature_cols])
vectors = data_scaled.tolist()
metadatas = [{"user_id": row["user_id"], "trade_id": f"T{idx}", "trade_type": row["trade_type"]}
for idx, row in data.iterrows()]
ids = [f"T{idx}" for idx in range(len(vectors))]
# 输出向量维度日志
print(f"特征列:{feature_cols}")
print(f"向量维度:{len(vectors[0])}维")
print(f"示例向量(T0):{vectors[0]}")
# ===================== 5. 正常交易向量入库 =====================
collection_name = f"user_{USER_ID}_normal_trades"
try:
client.delete_collection(name=collection_name)
print(f"删除已存在的集合:{collection_name}")
except Exception as e:
print(f"集合{collection_name}不存在,无需删除:{e}")
collection = client.create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)
print(f"创建用户{USER_ID}的正常交易向量集合:{collection_name}")
# 入库正常交易向量
normal_vectors = vectors[:NORMAL_TRADE_NUM]
normal_metadatas = metadatas[:NORMAL_TRADE_NUM]
normal_ids = ids[:NORMAL_TRADE_NUM]
try:
collection.add(embeddings=normal_vectors, metadatas=normal_metadatas, ids=normal_ids)
print(f"正常交易向量入库完成:{len(normal_vectors)}条")
print(f"入库向量ID:{normal_ids}")
print(f"集合当前向量总数:{collection.count()}")
except Exception as e:
print(f"正常向量入库失败:{str(e)}", exc_info=True)
# ===================== 6. 可视化分析函数 =====================
def plot_trade_feature_comparison(data, feature_cols, save_path):
"""
绘制正常/待检测交易特征对比图
"""
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
fig.suptitle(f"用户{USER_ID}交易特征对比(正常VS待检测)", fontsize=14, fontweight="bold")
# 选择核心特征绘制
plot_features = ["trade_amount", "trade_hour", "history_trade_count", "is_common_device"]
for idx, feat in enumerate(plot_features):
ax = axes[idx//2, idx%2]
# 分组统计
normal_feat = data[data["trade_type"]=="正常"][feat]
test_feat = data[data["trade_type"]=="待检测"][feat]
# 绘制对比
x = ["正常交易均值", "待检测交易均值"]
y = [normal_feat.mean(), test_feat.mean()]
ax.bar(x, y, color=["#2E8B57", "#DC143C"], alpha=0.7)
ax.set_title(f"{feat.replace('_', ' ')} 对比", fontsize=12)
ax.set_ylabel("特征值")
# 添加数值标注
for i, v in enumerate(y):
ax.text(i, v+0.02, f"{v:.2f}", ha="center", va="bottom", fontsize=10)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches="tight")
print(f"特征对比图已保存:{save_path}")
plt.show()
def plot_similarity_distribution(similarity_data, save_path):
"""
绘制相似度分布直方图(含阈值线)
"""
fig, ax = plt.subplots(figsize=(10, 6))
# 绘制相似度分布
ax.hist(similarity_data, bins=10, color="#4682B4", alpha=0.7)
# 添加阈值线
ax.axvline(FRAUD_THRESHOLD, color="#DC143C", linestyle="--", linewidth=2, label=f"异常阈值:{FRAUD_THRESHOLD}")
# 标注异常交易
for idx, sim in enumerate(similarity_data):
if sim < FRAUD_THRESHOLD:
ax.scatter(sim, 0.5, color="red", s=50, label=f"异常交易T{NORMAL_TRADE_NUM+idx}" if idx==0 else "")
ax.set_title(f"用户{USER_ID}交易相似度分布", fontsize=14, fontweight="bold")
ax.set_xlabel("余弦相似度")
ax.set_ylabel("频次")
ax.legend()
ax.grid(axis="y", alpha=0.3)
plt.savefig(save_path, dpi=300, bbox_inches="tight")
print(f"相似度分布图已保存:{save_path}")
plt.show()
def plot_vector_space(vectors, labels, save_path):
"""
向量空间可视化(PCA降维到2D)
"""
from sklearn.decomposition import PCA
# PCA降维到2维
pca = PCA(n_components=2)
vectors_2d = pca.fit_transform(vectors)
fig, ax = plt.subplots(figsize=(10, 8))
# 绘制正常交易向量
normal_2d = vectors_2d[:NORMAL_TRADE_NUM]
ax.scatter(normal_2d[:,0], normal_2d[:,1], color="#2E8B57", s=100, label="正常交易", alpha=0.8)
# 绘制待检测交易向量
test_2d = vectors_2d[NORMAL_TRADE_NUM:]
ax.scatter(test_2d[:,0], test_2d[:,1], color="#DC143C", s=100, marker="x", label="待检测交易", alpha=0.8)
# 添加标注
for idx, (x, y) in enumerate(vectors_2d):
ax.text(x+0.01, y+0.01, f"T{idx}", fontsize=9)
ax.set_title(f"用户{USER_ID}交易向量空间分布(PCA降维)", fontsize=14, fontweight="bold")
ax.set_xlabel("PCA维度1")
ax.set_ylabel("PCA维度2")
ax.legend()
ax.grid(alpha=0.3)
plt.savefig(save_path, dpi=300, bbox_inches="tight")
print(f"向量空间分布图已保存:{save_path}")
plt.show()
# ===================== 7. 异常交易检测(带细化分析+可视化) =====================
print("\n" + "="*50)
print("开始检测异常交易")
print("="*50)
# 待检测向量
test_vectors = vectors[NORMAL_TRADE_NUM:]
test_metadatas = metadatas[NORMAL_TRADE_NUM:]
test_ids = ids[NORMAL_TRADE_NUM:]
# 存储相似度结果(用于可视化)
similarity_results = []
for idx, (vector, meta, trade_id) in enumerate(zip(test_vectors, test_metadatas, test_ids)):
print(f"\n--- 检测交易 {trade_id} ---")
# 1. 输出原始特征
raw_data = data.iloc[NORMAL_TRADE_NUM + idx]
print(f"原始特征:{raw_data.to_dict()}")
print(f"待检测向量:{vector}")
# 2. 特征异常度分析
print("【特征异常度分析】")
normal_data = data[data["trade_type"]=="正常"]
for feat in ["trade_amount", "trade_hour", "is_common_device"]:
normal_mean = normal_data[feat].mean()
test_val = raw_data[feat]
# 计算偏离度(相对差值)
deviation = abs(test_val - normal_mean) / normal_mean if normal_mean !=0 else 1.0
deviation_pct = deviation * 100
if deviation_pct > 50: # 偏离超过50%判定为异常特征
print(f" {feat}:正常均值={normal_mean:.2f},当前值={test_val},偏离度={deviation_pct:.1f}% → 异常")
else:
print(f" {feat}:正常均值={normal_mean:.2f},当前值={test_val},偏离度={deviation_pct:.1f}% → 正常")
# 3. 检索相似向量
try:
results = collection.query(
query_embeddings=[vector],
n_results=TOP_K,
where={"user_id": USER_ID}
)
retrieved_ids = results["ids"][0]
retrieved_distances = results["distances"][0]
retrieved_metadatas = results["metadatas"][0]
# 4. 输出检索结果
print(f"检索到Top-{TOP_K}相似正常交易:{retrieved_ids}")
print(f"余弦距离(越小越相似):{[round(d, 4) for d in retrieved_distances]}")
# 5. 计算相似度
avg_distance = np.mean(retrieved_distances) if retrieved_distances else 1.0
avg_similarity = 1 - avg_distance
similarity_results.append(avg_similarity)
print(f"计算过程:平均余弦距离={round(avg_distance, 4)} → 平均余弦相似度={round(avg_similarity, 4)}")
# 6. 风控决策
if avg_similarity < FRAUD_THRESHOLD:
print(f"【异常交易判定】交易{trade_id}:平均相似度{round(avg_similarity, 4)} < 阈值{FRAUD_THRESHOLD}")
print(f"判定原因:1. 特征偏离度超过50%;2. 与正常交易向量相似度过低,行为模式异常")
print(f"\n交易 {trade_id}:平均相似度 {avg_similarity:.2f} → 🚨 异常交易,触发风控")
else:
print(f"【正常交易判定】交易{trade_id}:平均相似度{round(avg_similarity, 4)} ≥ 阈值{FRAUD_THRESHOLD}")
print(f"判定原因:特征偏离度在正常范围,与正常交易向量高度相似")
print(f"\n交易 {trade_id}:平均相似度 {avg_similarity:.2f} → ✅ 正常交易")
except Exception as e:
print(f"检测交易{trade_id}失败:{str(e)}", exc_info=True)
similarity_results.append(0.0)
print(f"\n交易 {trade_id}:检测失败 → ❌ 触发风控审核")
# ===================== 8. 生成可视化分析图 =====================
print("\n" + "="*50)
print("生成可视化分析图表")
print("="*50)
# 8.1 交易特征对比图
plot_trade_feature_comparison(
data=data,
feature_cols=feature_cols,
save_path=f"{img_dir}/trade_feature_comparison.png"
)
# 8.2 相似度分布直方图
plot_similarity_distribution(
similarity_data=similarity_results,
save_path=f"{img_dir}/similarity_distribution.png"
)
# 8.3 向量空间分布图
plot_vector_space(
vectors=vectors,
labels=["正常"]*NORMAL_TRADE_NUM + ["待检测"]*(len(vectors)-NORMAL_TRADE_NUM),
save_path=f"{img_dir}/vector_space_distribution.png"
)
print("\n" + "="*50)
print("异常交易检测流程结束")
print(f"可视化图表已保存至:{img_dir}")
print("="*50)2.4 输出结果
重置ChromaDB数据库
==================================================
【核心风控配置】
异常交易判定阈值:余弦相似度 < 0.7
检索相似向量数量:Top-3
目标分析用户:U001
正常交易样本数量:4
==================================================
加载交易数据:共6条,其中前4条为正常交易,后2条为待检测交易
特征列:'user_reg_days', 'history_trade_count', 'trade_amount', 'trade_hour', 'is_common_device'
向量维度:5维
示例向量(T0):0.0, 0.0, 0.029021924116528177, 0.85, 1.0
集合user_U001_normal_trades不存在,无需删除:Collection user_U001_normal_trades does not exist.
创建用户U001的正常交易向量集合:user_U001_normal_trades
正常交易向量入库完成:4条
入库向量ID:'T0', 'T1', 'T2', 'T3'
集合当前向量总数:4
==================================================
开始检测异常交易
==================================================
--- 检测交易 T4 ---
原始特征:{'user_id': 'U001', 'user_reg_days': 180, 'history_trade_count': 60, 'trade_amount': 10.0, 'trade_hour': 3, 'is_common_device': 0, 'trade_type': '待检测'}
待检测向量:0.0, 0.7999999999999989, 0.0, 0.0, 0.0
【特征异常度分析】
trade_amount:正常均值=349.35,当前值=10.0,偏离度=97.1% → 异常
trade_hour:正常均值=20.00,当前值=3,偏离度=85.0% → 异常
is_common_device:正常均值=1.00,当前值=0,偏离度=100.0% → 异常
检索到Top-3相似正常交易:'T3', 'T2', 'T1'
余弦距离(越小越相似):0.5845, 0.7151, 0.8457
计算过程:平均余弦距离=0.7151 → 平均余弦相似度=0.2849
【异常交易判定】交易T4:平均相似度0.2849 < 阈值0.7
判定原因:1. 特征偏离度超过50%;2. 与正常交易向量相似度过低,行为模式异常
交易 T4:平均相似度 0.28 → 🚨 异常交易,触发风控
--- 检测交易 T5 ---
原始特征:{'user_id': 'U001', 'user_reg_days': 180, 'history_trade_count': 61, 'trade_amount': 9999.0, 'trade_hour': 23, 'is_common_device': 0, 'trade_type': '待检测'}
待检测向量:0.0, 1.0, 1.0, 1.0, 0.0
【特征异常度分析】
trade_amount:正常均值=349.35,当前值=9999.0,偏离度=2762.2% → 异常
trade_hour:正常均值=20.00,当前值=23,偏离度=15.0% → 正常
is_common_device:正常均值=1.00,当前值=0,偏离度=100.0% → 异常
检索到Top-3相似正常交易:'T3', 'T2', 'T1'
余弦距离(越小越相似):0.4006, 0.4494, 0.5462
计算过程:平均余弦距离=0.4654 → 平均余弦相似度=0.5346
【异常交易判定】交易T5:平均相似度0.5346 < 阈值0.7
判定原因:1. 特征偏离度超过50%;2. 与正常交易向量相似度过低,行为模式异常
交易 T5:平均相似度 0.53 → 🚨 异常交易,触发风控
==================================================
生成可视化分析图表
==================================================
特征对比图已保存:./analysis_imgs/trade_feature_comparison.png
相似度分布图已保存:./analysis_imgs/similarity_distribution.png
向量空间分布图已保存:./analysis_imgs/vector_space_distribution.png
==================================================
异常交易检测流程结束
可视化图表已保存至:./analysis_imgs
==================================================
五、实际场景优化
如果将上述方案落地到生产环境,我们可以朝以下三方面进行调优处理:向量质量优化、检索性能优化、阈值动态调整。
1. 向量质量优化
向量的质量直接决定检索准确性,可通过以下方式优化:
- 特征工程:引入时序特征(如交易间隔时间)、行为序列特征(如近期交易金额波动),提升向量的区分度
- 嵌入模型优化:使用深度学习模型(如 Transformer、CNN)替代简单拼接,生成更具语义信息的行为嵌入向量
- 增量更新:定期将审核通过的正常交易向量加入用户正常向量库,实现模型的动态迭代
2. 检索性能优化
面对高并发的实时交易场景,需从索引和部署层面优化性能:
- 索引选型:选择 HNSW 索引,通过调整 M(邻接节点数)和 ef(检索深度)平衡速度与精度
- 分库分表:按用户 ID 或交易地区分片存储向量,降低单集合的检索压力
- 缓存策略:缓存高频用户的正常向量聚类中心,减少重复检索计算
3. 阈值动态调整
固定阈值难以适配复杂场景,需实现动态阈值机制:
- 用户分层:对高信用用户设置较低的相似度阈值,减少误拦截;对新用户设置较高阈值,提升风控强度
- 场景适配:在促销活动、节假日等交易高峰时段,适当放宽阈值,避免系统过载
六、总结
将交易行为转化为向量并利用向量数据库实现实时异常检索,是反欺诈技术从被动规则向主动感知的跨越。其核心优势体现在实时性,毫秒级检索响应,适配高并发交易场景;灵活性,无需重新训练模型即可适配新型欺诈模式;精准性,基于用户级行为聚类,降低跨用户误判概率,未来,随着大模型与向量数据库的深度融合,通过大模型生成交易行为的语义向量,结合向量数据库的检索能力,实现对隐蔽欺诈行为的精准识别。