文章目录
-
- 引言:时序数据管理的时代命题
- 一、时序数据库选型的核心维度分析
-
- [1.1 性能指标:从基准测试看硬实力](#1.1 性能指标:从基准测试看硬实力)
- [1.2 架构灵活性:端边云协同的全场景覆盖](#1.2 架构灵活性:端边云协同的全场景覆盖)
- [1.3 工业场景适配度:从理论到实战](#1.3 工业场景适配度:从理论到实战)
- [二、国际视野:Apache IoTDB与主流产品的对比](#二、国际视野:Apache IoTDB与主流产品的对比)
-
- [2.1 全球时序数据库格局分析](#2.1 全球时序数据库格局分析)
- [2.2 Apache IoTDB:性能与性价比的双重突破](#2.2 Apache IoTDB:性能与性价比的双重突破)
- [三、实战演练:快速上手Apache IoTDB](#三、实战演练:快速上手Apache IoTDB)
-
- [3.1 环境准备与快速安装](#3.1 环境准备与快速安装)
- [3.2 Java API示例:工业设备数据采集](#3.2 Java API示例:工业设备数据采集)
- [3.3 Python API示例:能源监控数据实时采集](#3.3 Python API示例:能源监控数据实时采集)
- [3.4 高级查询:时序数据分析SQL](#3.4 高级查询:时序数据分析SQL)
- 四、真实案例:IoTDB的工业级应用验证
-
- [4.1 轨道交通:中车四方智能运维系统](#4.1 轨道交通:中车四方智能运维系统)
- [4.2 能源电力:国家电网精准用电调控系统](#4.2 能源电力:国家电网精准用电调控系统)
- [4.3 智能制造:长安汽车车联网平台](#4.3 智能制造:长安汽车车联网平台)
- [4.4 核能工业:中国核电可靠性管理平台](#4.4 核能工业:中国核电可靠性管理平台)
- 五、选型建议:让技术决策更明智
-
- [5.1 优先选择IoTDB的场景](#5.1 优先选择IoTDB的场景)
- [5.2 选型决策参考框架](#5.2 选型决策参考框架)
- [5.3 迁移路径与实施建议](#5.3 迁移路径与实施建议)
- [5.4 商业支持与企业服务](#5.4 商业支持与企业服务)
- 结语:拥抱开源,构建自主可控的数据底座
引言:时序数据管理的时代命题
随着工业4.0、智慧城市和物联网技术的深入发展,企业每天都在产生海量的时序数据。从智能制造车间的数千台设备实时监控,到能源电力系统的精准调度,再到智能网联汽车的车况分析,时序数据已成为企业数字化转型的核心资产。据统计,一个中型工业企业每天可能产生数十亿条时序数据点,如何高效存储、快速查询和深度分析这些数据,成为技术决策者面临的首要挑战。

一、时序数据库选型的核心维度分析
1.1 性能指标:从基准测试看硬实力
写入性能是时序数据库的生命线。在工业物联网场景中,数千台设备同时产生数据,数据库需要支持千万级每秒的并发写入。2024年,Apache IoTDB在国际权威TPCx-IoT基准测试中登顶榜首,性能指标超越第二名86%,充分证明了其在高并发写入场景下的卓越表现。
存储压缩比 直接关系到企业的长期TCO(总拥有成本)。工业数据往往需要保存数年甚至十年以上,存储成本不容小觑。IoTDB采用自研的TsFile文件格式和专有压缩算法,可实现10倍的无损压缩 和100倍的有损压缩 ,相比传统数据库可节省90%以上的存储成本。在2023年benchANT国际测试中,IoTDB的压缩性能同样位居全球第一。
查询响应速度 决定了数据的可用性。TB级数据量下的毫秒级查询响应,是支撑实时监控、故障诊断等关键业务的基础。IoTDB通过优化的列式存储引擎和时序计算引擎,提供近百种内置聚合与时序计算函数,能够在海量历史数据中实现快速定位和实时分析。
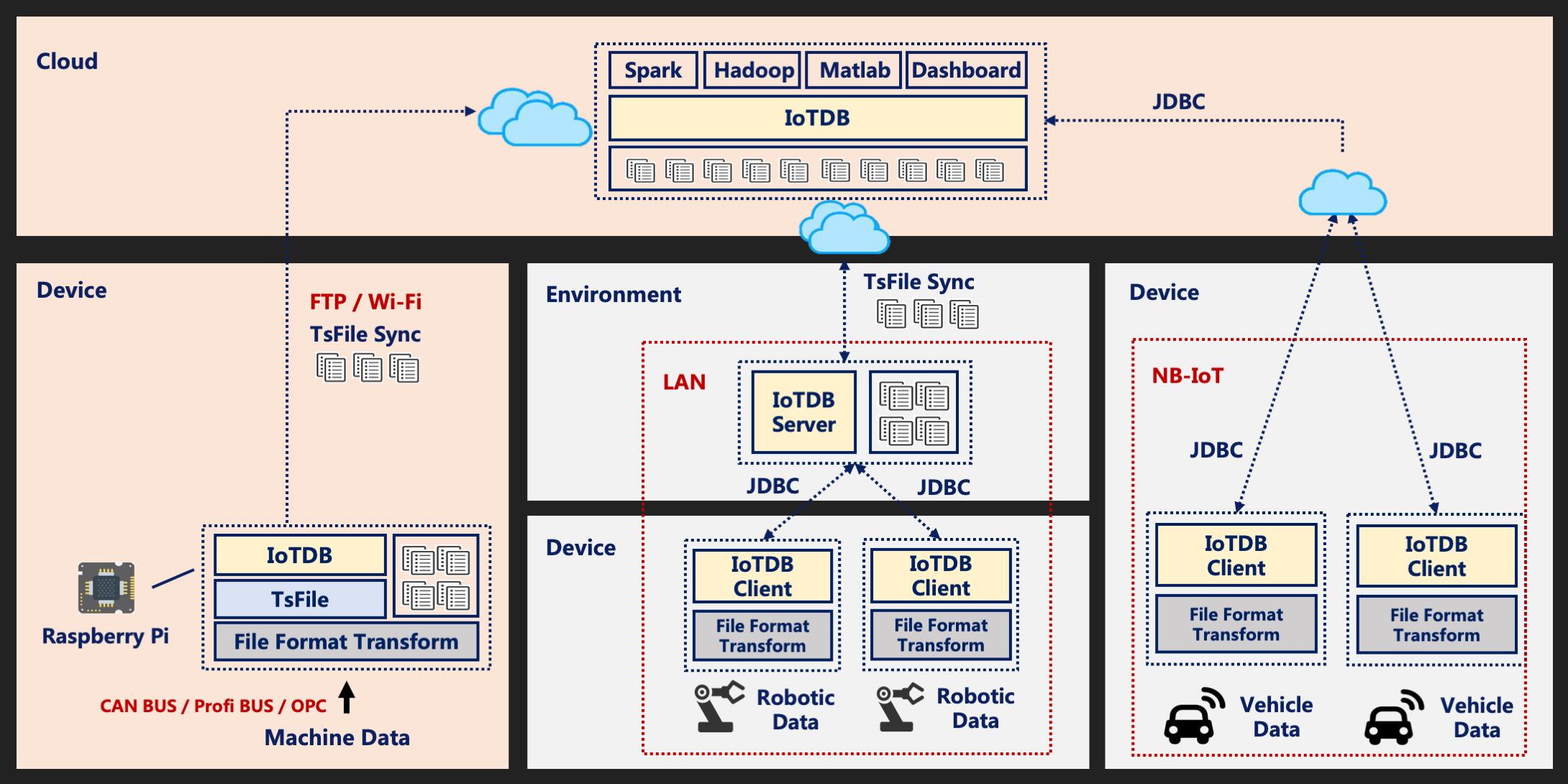
1.2 架构灵活性:端边云协同的全场景覆盖
现代工业场景呈现明显的端-边-云分层架构特征。边缘侧资源受限但需要实时处理,云端资源充足但要求大规模并发。一个优秀的时序数据库应该支持跨层级部署和高效数据同步。
Apache IoTDB采用轻量化架构设计 ,单机版可以运行在边缘网关等资源受限设备上,分布式集群版支持水平扩展到数百个节点。其7×24小时高可用架构保证一个物理节点宕机或网络故障时,系统仍能正常运行。同时,IoTDB提供高效的边云数据同步工具,实现端边云数据的无缝流转。
1.3 工业场景适配度:从理论到实战
工业场景有其特殊性:数据采集协议多样化(Modbus、OPC UA、MQTT等)、数据乱序到达、需要支持设备树形组织结构、对系统稳定性要求极高。
IoTDB原生支持层级化的测点组织管理方式 ,可以根据设备实际层级关系进行建模("工厂-车间-产线-设备"),实现与工业测点管理结构的对齐。同时支持乱序写入、多频采集 等复杂工业读写场景,以及一键备份恢复、审计日志等企业级功能,真正做到"开箱即用"。
二、国际视野:Apache IoTDB与主流产品的对比
2.1 全球时序数据库格局分析
在国际时序数据库市场中,InfluxDB和TimescaleDB是较为知名的产品。InfluxDB作为较早进入市场的时序数据库,在互联网监控场景有一定应用,但在工业物联网场景下存在明显短板:高并发写入时CPU占用率可瞬时达到100%,存储成本较高,且企业版闭源需要商业授权。
TimescaleDB基于PostgreSQL扩展,优势在于SQL兼容性好,但在时序数据处理上并非原生设计。在IoT场景的基准测试中,其写入性能显著低于专用时序数据库,且受限于PostgreSQL的架构特点,横向扩展能力有限。
2.2 Apache IoTDB:性能与性价比的双重突破
相比国外产品,Apache IoTDB在多项国际权威测试中展现出明显优势:
TPCx-IoT国际基准测试(2024年8月):
- 性能指标超越第二名86%
- 系统成本降低68%
- 实现性能与性价比双第一
benchANT时序数据库测试(2023年11月):
- 6项性能及性价比指标全部排名第一
- 读、写、压缩性能全面优于国际主流产品
更重要的是,IoTDB是完全开源的Apache顶级项目,无任何商业版本功能限制,企业可以放心长期使用,避免技术锁定风险。这一点在国产化替代的大背景下尤为重要。
三、实战演练:快速上手Apache IoTDB
3.1 环境准备与快速安装
Apache IoTDB支持多种安装方式,推荐使用官方编译好的二进制包:
官方下载地址:https://iotdb.apache.org/zh/Download/
解压后启动服务非常简单:
bash
# Linux/MacOS环境
cd apache-iotdb-1.3.x
./sbin/start-standalone.sh
# Windows环境
cd apache-iotdb-1.3.x
.\sbin\start-standalone.bat启动成功后,使用CLI工具连接数据库:
bash
./sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root3.2 Java API示例:工业设备数据采集
以下是使用Session API进行高性能批量写入的完整示例,适用于工业设备实时数据采集场景:
java
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.session.SessionDataSet;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import java.util.ArrayList;
import java.util.List;
/**
* IoTDB 工业设备数据采集示例
* 场景:智能制造车间设备实时监控
*/
public class IndustrialDataCollection {
public static void main(String[] args)
throws IoTDBConnectionException, StatementExecutionException {
// 1. 建立连接
Session session = new Session.Builder()
.host("127.0.0.1")
.port(6667)
.username("root")
.password("root")
.build();
session.open(false);
// 2. 定义设备测点结构(按工业场景层级建模)
// 路径格式: root.工厂.车间.产线.设备
String devicePath = "root.factory01.workshop01.line01.machine01";
List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("temperature", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("pressure", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("speed", TSDataType.INT32));
schemaList.add(new MeasurementSchema("vibration", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("status", TSDataType.TEXT));
// 3. 创建Tablet进行高性能批量写入
Tablet tablet = new Tablet(devicePath, schemaList, 1000);
long startTime = System.currentTimeMillis();
// 4. 模拟1000条设备运行数据
for (int i = 0; i < 1000; i++) {
int row = tablet.rowSize++;
tablet.addTimestamp(row, startTime + i * 1000); // 每秒采集一次
tablet.addValue("temperature", row, 75.5f + (float)(Math.random() * 10));
tablet.addValue("pressure", row, 2.5f + (float)(Math.random() * 0.5));
tablet.addValue("speed", row, 1500 + (int)(Math.random() * 100));
tablet.addValue("vibration", row, 0.05f + (float)(Math.random() * 0.02));
tablet.addValue("status", row, i % 100 == 0 ? "warning" : "normal");
}
// 5. 批量插入数据
long writeStart = System.currentTimeMillis();
session.insertTablet(tablet);
long writeEnd = System.currentTimeMillis();
System.out.println("成功写入 " + tablet.rowSize + " 条数据,耗时: "
+ (writeEnd - writeStart) + "ms");
// 6. 查询最近1小时异常数据
String querySQL = String.format(
"SELECT temperature, pressure, vibration, status FROM %s " +
"WHERE time >= %d AND status = 'warning'",
devicePath, startTime
);
SessionDataSet dataSet = session.executeQueryStatement(querySQL);
System.out.println("\n异常数据统计:");
int count = 0;
while (dataSet.hasNext()) {
System.out.println(dataSet.next());
count++;
}
System.out.println("共发现 " + count + " 条异常记录");
// 7. 时间窗口聚合分析(5分钟粒度)
String aggSQL = String.format(
"SELECT AVG(temperature) AS avg_temp, MAX(pressure) AS max_pressure, " +
"STDDEV(vibration) AS vibration_std " +
"FROM %s " +
"GROUP BY ([%d, %d), 5m)",
devicePath, startTime, startTime + 3600000
);
SessionDataSet aggResult = session.executeQueryStatement(aggSQL);
System.out.println("\n设备运行统计(5分钟粒度):");
while (aggResult.hasNext()) {
System.out.println(aggResult.next());
}
dataSet.closeOperationHandle();
aggResult.closeOperationHandle();
session.close();
}
}3.3 Python API示例:能源监控数据实时采集
Python API适合快速原型开发和数据采集脚本,以下是能源监控场景的示例:
python
from iotdb.Session import Session
from iotdb.utils.IoTDBConstants import TSDataType
from iotdb.utils.Tablet import Tablet
import time
import random
"""
IoTDB 能源监控数据采集示例
场景:智慧楼宇能源实时监控系统
"""
# 1. 连接IoTDB
session = Session("127.0.0.1", "6667", "root", "root")
session.open(False)
# 2. 定义能源监控设备结构
# 路径格式: root.建筑.楼层.监控点
device_id = "root.building01.floor03.energy_meter01"
measurements = ["voltage", "current", "active_power", "reactive_power",
"power_factor", "total_energy"]
data_types = [
TSDataType.FLOAT, # 电压(V)
TSDataType.FLOAT, # 电流(A)
TSDataType.FLOAT, # 有功功率(kW)
TSDataType.FLOAT, # 无功功率(kVar)
TSDataType.FLOAT, # 功率因数
TSDataType.DOUBLE # 累计电能(kWh)
]
# 3. 模拟实时数据采集(采集1小时数据,每10秒一次)
print("开始采集能源数据...")
values = []
timestamps = []
total_energy = 0.0
for i in range(360): # 1小时 = 3600秒 / 10秒
timestamp = int(time.time() * 1000) + i * 10000
# 模拟真实场景数据波动
voltage = 220.0 + random.uniform(-5, 5)
current = 15.0 + random.uniform(-3, 3)
active_power = (voltage * current * 0.85) / 1000 # kW
reactive_power = (voltage * current * 0.53) / 1000 # kVar
power_factor = 0.85 + random.uniform(-0.05, 0.05)
total_energy += active_power * (10.0 / 3600.0) # 累加电能
timestamps.append(timestamp)
values.append([voltage, current, active_power, reactive_power,
power_factor, total_energy])
# 每采集100条数据写入一次
if (i + 1) % 100 == 0:
tablet = Tablet(device_id, measurements, data_types,
values[-100:], timestamps[-100:])
session.insert_tablet(tablet)
print(f"已采集并存储 {i + 1} 条能源数据")
print(f"\n数据采集完成!共采集 {len(timestamps)} 条记录")
print(f"总耗电量: {total_energy:.2f} kWh")
# 4. 数据分析查询
# 4.1 查询平均功率
avg_query = f"""
SELECT AVG(active_power) AS avg_power,
MAX(active_power) AS peak_power,
MIN(power_factor) AS min_pf
FROM {device_id}
"""
result = session.execute_statement(avg_query)
print("\n能耗统计分析:")
while result.has_next():
print(result.next())
# 4.2 按15分钟时间窗口聚合
window_query = f"""
SELECT AVG(active_power) AS avg_power,
SUM(active_power) * 0.25 AS energy_kwh
FROM {device_id}
GROUP BY ([now() - 1h, now()), 15m)
"""
result = session.execute_statement(window_query)
print("\n分时段能耗统计(15分钟粒度):")
while result.has_next():
print(result.next())
session.close()
print("\n会话已关闭")3.4 高级查询:时序数据分析SQL
IoTDB支持丰富的时序分析函数,以下是工业场景常用的查询模式:
sql
-- 1. 设备健康度评估(多指标综合分析)
SELECT
AVG(temperature) AS avg_temp,
MAX(temperature) AS max_temp,
STDDEV(vibration) AS vibration_std,
COUNT(status) AS sample_count,
COUNT_IF(status='warning') AS warning_count
FROM root.factory.production.machine1
WHERE time >= 2024-12-01T00:00:00 AND time < 2024-12-02T00:00:00
GROUP BY ([2024-12-01T00:00:00, 2024-12-02T00:00:00), 10m);
-- 2. 异常检测(基于统计偏差)
SELECT
time, temperature, vibration,
(temperature - AVG(temperature) OVER(ORDER BY time ROWS 100 PRECEDING)) AS temp_deviation
FROM root.factory.production.machine1
WHERE ABS(temp_deviation) > 10;
-- 3. 能耗趋势分析(同比环比)
SELECT
DATE_BIN(1d, time) AS day,
SUM(power) AS daily_energy,
LAG(SUM(power), 1) OVER(ORDER BY day) AS prev_day_energy,
(SUM(power) - LAG(SUM(power), 1) OVER(ORDER BY day)) / LAG(SUM(power), 1) * 100 AS growth_rate
FROM root.building.energy.meter
GROUP BY DATE_BIN(1d, time);
-- 4. 设备运行效率OEE计算
SELECT
COUNT_IF(status='running') * 100.0 / COUNT(*) AS availability,
AVG(speed) / MAX(speed) * 100 AS performance,
COUNT_IF(quality='good') * 100.0 / COUNT_IF(status='running') AS quality,
(COUNT_IF(status='running') * AVG(speed) * COUNT_IF(quality='good')) /
(COUNT(*) * MAX(speed) * COUNT_IF(status='running')) * 100 AS OEE
FROM root.factory.production.machine1
WHERE time >= now() - 8h
GROUP BY ([now() - 8h, now()), 1h);四、真实案例:IoTDB的工业级应用验证
4.1 轨道交通:中车四方智能运维系统
应用场景:300辆列车、近100万测点的车辆监控数据存储与分析
实施效果:
- 可管理列车数增加1倍
- 采样时间提升60%
- 需要服务器数降为原来的1/13
- 实现日增4140亿数据点管理
- 月数据增量压缩后大小下降95%
4.2 能源电力:国家电网精准用电调控系统
应用场景:精准用电调控终端、物联管理平台及实时量测中心
实施效果:
- 支持日新增千万级数据
- 累积亿级数据的高效管理
- 支持千万级设备并发
- 千万点数据/秒的实时写入能力
4.3 智能制造:长安汽车车联网平台
应用场景:智能网联车辆车况时序数据处理
核心数据:
- 接入车辆设备约57万
- 测点数约8000万
- 托管时间序列约1.5亿
- 写入量级达到150万条数据/秒
- 诊断系统查询效率从分钟级提升到毫秒级
4.4 核能工业:中国核电可靠性管理平台
应用场景:五大核电基地关键设备可靠性管理
系统能力:
- 支持30台以上服务器
- 至少1000个容器节点
- 每秒40000用户在线处理业务
- 支持至少100TB时序数据存储
- 系统可靠性达到99.9%
五、选型建议:让技术决策更明智
5.1 优先选择IoTDB的场景
如果您的应用符合以下特征,强烈推荐选择Apache IoTDB:
- 工业关键行业应用:能源电力、智能制造、轨道交通、航空航天等
- 大规模测点管理:需要管理千万级以上测点的部署场景
- 长期数据保存需求:对存储成本敏感,需要保存多年历史数据
- 端边云协同架构:数据需要在边缘、区域、云端多层级流转
- 自主可控要求:需要避免技术锁定,确保系统长期演进
5.2 选型决策参考框架
| 评估维度 | IoTDB优势 | 关键指标 |
|---|---|---|
| 性能 | TPCx-IoT全球第一 | 性能超第二名86% |
| 成本 | 超高压缩比 | 节省90%+存储成本 |
| 可靠性 | 7×24高可用 | 系统可用性99.9% |
| 生态 | Apache顶级项目 | 完全开源、无锁定 |
| 服务 | 天谋科技原厂支持 | 企业级商业服务 |
5.3 迁移路径与实施建议
对于已有系统,建议采用"灰度迁移"策略:
第一阶段 :新业务优先 - 新建系统直接采用IoTDB
第二阶段 :并行验证 - 在非核心业务上进行试点验证
第三阶段 :逐步切换 - 验证成功后逐步将历史数据迁移
第四阶段:工具支持 - 利用IoTDB与Kafka、Flink等大数据组件的集成工具
5.4 商业支持与企业服务
作为Apache顶级项目,IoTDB拥有活跃的全球开发者社区。同时,**天谋科技(Timecho)**作为IoTDB的核心贡献团队和原厂商业化公司,基于Apache IoTDB提供企业版产品TimechoDB,为企业客户提供:
- 企业级功能增强:双活部署、多级存储、数据告警、审计日志等
- 专业技术支持:7×24小时技术支持、远程诊断、性能调优
- 培训与咨询:架构设计咨询、最佳实践培训、认证服务
- 定制化开发:针对特定行业场景的功能定制与优化
结语:拥抱开源,构建自主可控的数据底座
时序数据库选型不仅是技术选择,更是对企业长期数字化战略的投资。Apache IoTDB以其卓越的性能、开放的架构、完全开源的生态和活跃的社区,正在成为工业物联网领域的事实标准。无论是能源电力的关键基础设施,还是智能制造的生产线监控,IoTDB都已经用数百个实际案例证明了其可靠性和先进性。
立即开始您的时序数据管理之旅:
