1、MySQL数据表的约束
1.1、MySQL主键
"主键(PRIMARY KEY)"的完整称呼是"主键约束"。 MySQL 主键约束是一个列或者列的组合,其值能唯一地标识表中的每一行。这样的一列或多列称为表的主键,通过它可以强制表的实体完整性。
主键约束即在表中定义一个主键来唯一确定表中每一行数据的标识符。主键可以是表中的某一列或者多列的组合,其中由多列组合的主键称为复合主键。主键应该遵守下面的规则:
- 每个表只能定义一个主键。
- 主键值必须唯一标识表中的每一行,且不能为 NULL,即表中不可能存在两行数据有相同的主键值。这是唯一性原则。
- 一个列名只能在复合主键列表中出现一次。
- 复合主键不能包含不必要的多余列。当把复合主键的某一列删除后,如果剩下的列构成的主键仍然满足唯一性原则,那么这个复合主键是不正确的。这是最小化原则。
在创建表时设置主键约束
【实例 1】在 test_db 数据库中创建 tb_emp 4 数据表,其主键为 id,输入的 SQL 语句和运行结果如下所示。
mysql> CREATE TABLE tb_emp4
-> (
-> id INT(11),
-> name VARCHAR(25),
-> deptId INT(11),
-> salary FLOAT,
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.37 sec)
mysql> DESC tb_emp4;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(25) | YES | | NULL | |
| deptId | int(11) | YES | | NULL | |
| salary | float | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
4 rows in set (0.14 sec)【实例 2】创建数据表 tb_emp5,假设表中没有主键 id,为了唯一确定一个员工,可以把 name、deptId 联合起来作为主键,输入的 SQL 语句和运行结果如下所示。
mysql> CREATE TABLE tb_emp5
-> (
-> name VARCHAR(25),
-> deptId INT(11),
-> salary FLOAT,
-> PRIMARY KEY(id,deptId)
-> );
Query OK, 0 rows affected (0.37 sec)
mysql> DESC tb_emp5;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| name | varchar(25) | NO | PRI | NULL | |
| deptId | int(11) | NO | PRI | NULL | |
| salary | float | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
3 rows in set (0.14 sec)在修改表时添加主键约束
【实例 1】修改数据表 tb_emp2,将字段 id 设置为主键,输入的 SQL 语句和运行结果如下所示。
mysql> ALTER TABLE tb_emp2
-> ADD PRIMARY KEY(id);
Query OK, 0 rows affected (0.94 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> DESC tb_emp2;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(30) | YES | | NULL | |
| deptId | int(11) | YES | | NULL | |
| salary | float | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
4 rows in set (0.12 sec)1.2、MySQL外键约束(FOREIGN KEY)
MySQL 外键约束(FOREIGN KEY)用来在两个表的数据之间建立链接,它可以是一列或者多列。一个表可以有一个或多个外键。
外键对应的是参照完整性,一个表的外键可以为空值,若不为空值,则每一个外键的值必须等于另一个表中主键的某个值。
外键是表的一个字段,不是本表的主键,但对应另一个表的主键。定义外键后,不允许删除另一个表中具有关联关系的行。
外键的主要作用是保持数据的一致性、完整性。例如,部门表 tb_dept 的主键是 id,在员工表 tb_emp5 中有一个键 deptId 与这个 id 关联。
-
主表(父表):对于两个具有关联关系的表而言,相关联字段中主键所在的表就是主表。
从表(子表):对于两个具有关联关系的表而言,相关联字段中外键所在的表就是从表。
定义一个外键时,需要遵守下列规则: -
父表必须已经存在于数据库中,或者是当前正在创建的表。如果是后一种情况,则父表与子表是同一个表,这样的表称为自参照表,这种结构称为自参照完整性。
-
必须为父表定义主键。
-
主键不能包含空值,但允许在外键中出现空值。也就是说,只要外键的每个非空值出现在指定的主键中,这个外键的内容就是正确的。
-
在父表的表名后面指定列名或列名的组合。这个列或列的组合必须是父表的主键或候选键。 外键中列的数目必须和父表的主键中列的数目相同。
-
外键中列的数据类型必须和父表主键中对应列的数据类型相同。

创建 tb_dept1 的 SQL 语句运行结果如下所示。mysql> CREATE TABLEtb_dept1
-> (
-> id INT(11) PRIMARY KEY,
-> name VARCHAR(22) NOT NULL,
-> location VARCHAR(50)
-> );
Query OK, 0 rows affected (0.37 sec)
创建数据表 tb_emp6,并在表 tb_emp6 上创建外键约束,让它的键 deptId 作为外键关联到表 tb_dept1 的主键 id,输入的 SQL 语句和运行结果如下所示。
mysql> CREATE TABLE tb_emp6
-> (
-> id INT(11) PRIMARY KEY,
-> name VARCHAR(25),
-> deptId INT(11),
-> salary FLOAT,
-> CONSTRAINT fk_emp_dept1
-> FOREIGN KEY(deptId) REFERENCES tb_dept1(id)
-> );
Query OK, 0 rows affected (0.37 sec)
mysql> DESC tb_emp6;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(25) | YES | | NULL | |
| deptId | int(11) | YES | MUL | NULL | |
| salary | float | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
4 rows in set (1.33 sec)以上语句执行成功之后,在表 tb_emp6 上添加了名称为 fk_emp_dept1 的外键约束,外键名称为 deptId,其依赖于表 tb_dept1 的主键 id。
1.3、MySQL唯一约束(UNIQUE KEY)
MySQL唯一约束(Unique Key)要求该列唯一,允许为空,但只能出现一个空值。唯一约束可以确保一列或者几列不出现重复值。
提示:UNIQUE 和 PRIMARY KEY 的区别:一个表可以有多个字段声明为 UNIQUE,但只能有一个 PRIMARY KEY 声明;声明为 PRIMAY KEY 的列不允许有空值,但是声明为 UNIQUE 的字段允许空值的存在。
【实例 1】创建数据表 tb_dept2,指定部门的名称唯一,输入的 SQL 语句和运行结果如下所示。
mysql> CREATE TABLE tb_dept2
-> (
-> id INT(11) PRIMARY KEY,
-> name VARCHAR(22) UNIQUE,
-> location VARCHAR(50)
-> );
Query OK, 0 rows affected (0.37 sec)
mysql> DESC tb_dept2;
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(40) | YES | UNI | NULL | |
| location | varchar(50) | YES | | NULL | |
+----------+-------------+------+-----+---------+-------+
3 rows in set (0.08 sec)2、MySQL索引简介
索引是 MySQL 中一种十分重要的数据库对象。它是数据库性能调优技术的基础,常用于实现数据的快速检索。
索引就是根据表中的一列或若干列按照一定顺序建立的列值与记录行之间的对应关系表,实质上是一张描述索引列的列值与原表中记录行之间一一对应关系的有序表。
在 MySQL 中,通常有以下两种方式访问数据库表的行数据:
1) 顺序访问
顺序访问是在表中实行全表扫描,从头到尾逐行遍历,直到在无序的行数据中找到符合条件的目标数据。这种方式实现比较简单,但是当表中有大量数据的时候,效率非常低下。例如,在几千万条数据中查找少量的数据时,使用顺序访问方式将会遍历所有的数据,花费大量的时间,显然会影响数据库的处理性能。
2) 索引访问
索引访问是通过遍历索引来直接访问表中记录行的方式。使用这种方式的前提是对表建立一个索引,在列上创建了索引之后,查找数据时可以直接根据该列上的索引找到对应记录行的位置,从而快捷地查找到数据。索引存储了指定列数据值的指针,根据指定的排序顺序对这些指针排序。
例如,在学生基本信息表 students 中,如果基于 student_id 建立了索引,系统就建立了一张索引列到实际记录的映射表,当用户需要查找 student_id 为 12022 的数据的时候,系统先在 student_id 索引上找到该记录,然后通过映射表直接找到数据行,并且返回该行数据。因为扫描索引的速度一般远远大于扫描实际数据行的速度,所以采用索引的方式可以大大提高数据库的工作效率。
索引的使用原则和注意事项
虽然索引可以加快查询速度,提高 MySQL 的处理性能,但是过多地使用索引也会造成以下弊端:
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。
注意:索引可以在一些情况下加速查询,但是在某些情况下,会降低效率。
索引只是提高效率的一个因素,因此在建立索引的时候应该遵循以下原则:
在经常需要搜索的列上建立索引,可以加快搜索的速度。
在作为主键的列上创建索引,强制该列的唯一性,并组织表中数据的排列结构。
在经常使用表连接的列上创建索引,这些列主要是一些外键,可以加快表连接的速度。
在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,所以其指定的范围是连续的。
在经常需要排序的列上创建索引,因为索引已经排序,所以查询时可以利用索引的排序,加快排序查询。
在经常使用 WHERE 子句的列上创建索引,加快条件的判断速度。
与此对应,在某些应用场合下建立索引不能提高 MySQL 的工作效率,甚至在一定程度上还带来负面效应,降低了数据库的工作效率,一般来说不适合创建索引的环境如下:
对于那些在查询中很少使用或参考的列不应该创建索引。因为这些列很少使用到,所以有索引或者无索引并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度,并增大了空间要求。
对于那些只有很少数据值的列也不应该创建索引。因为这些列的取值很少,例如人事表的性别列。查询结果集的数据行占了表中数据行的很大比例,增加索引并不能明显加快检索速度。
对于那些定义为 TEXT、IMAGE 和 BIT 数据类型的列不应该创建索引。因为这些列的数据量要么相当大,要么取值很少。
当修改性能远远大于检索性能时,不应该创建索引。因为修改性能和检索性能是互相矛盾的。当创建索引时,会提高检索性能,降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
2.1、创建索引
-
一般索引
mysql> CREATE TABLE tb_stu_info
-> (
-> id INT NOT NULL,
-> name CHAR(45) DEFAULT NULL,
-> dept_id INT DEFAULT NULL,
-> age INT DEFAULT NULL,
-> height INT DEFAULT NULL,
-> INDEX(height)
-> );
Query OK,0 rows affected (0.40 sec) -
唯一索引
mysql> CREATE TABLE tb_stu_info2
-> (
-> id INT NOT NULL,
-> name CHAR(45) DEFAULT NULL,
-> dept_id INT DEFAULT NULL,
-> age INT DEFAULT NULL,
-> height INT DEFAULT NULL,
-> UNIQUE INDEX(height)
-> );
Query OK,0 rows affected (0.40 sec) -
查看索引
mysql> SHOW INDEX FROM tb_stu_info2\G
*************************** 1. row ***************************
Table: tb_stu_info2
Non_unique: 0
Key_name: height
Seq_in_index: 1
Column_name: height
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
1 row in set (0.03 sec) -
删除索引
删除表 tb_stu_info 中的索引,输入的 SQL 语句和执行结果如下所示。mysql> DROP INDEX height
-> ON tb_stu_info;
Query OK, 0 rows affected (0.27 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW CREATE TABLE tb_stu_info\G
*************************** 1. row ***************************
Table: tb_stu_info
Create Table: CREATE TABLEtb_stu_info(
idint(11) NOT NULL,
namechar(45) DEFAULT NULL,
dept_idint(11) DEFAULT NULL,
ageint(11) DEFAULT NULL,
heightint(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=gb2312
1 row in set (0.00 sec)
2、数据表的基本操作
2.1、MySQL SELECT 基本语法
MySQL 表单查询是指从一张表的数据中查询所需的数据,主要有查询所有字段、查询指定字段、查询指定记录、查询空值、多条件的查询、对查询结果进行排序等。
-
在 SELECT 语句中使用星号"*"通配符查询所有字段。
mysql> SELECT * FROM tb_students_info;
-
查询表中指定的字段
mysql> SELECT name FROM tb_students_info;
2.2、MySQL DISTINCT:去重(过滤重复数据)
DISTINCT 关键字指示 MySQL 消除重复的记录值
mysql> SELECT DISTINCT age
-> FROM tb_students_info;2.2、MySQL AS:设置别名
注意:在为表取别名时,要保证不能与数据库中的其他表的名称冲突。
mysql> SELECT stu.name,stu.height
-> FROM tb_students_info AS stu;2.3、MySQL LIMIT:限制查询结果的记录条数
LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
第一个参数"位置偏移量"指示 MySQL 从哪一行开始显示,是一个可选参数,如果不指定"位置偏移量",将会从表中的第一条记录开始(第一条记录的位置偏移量是 0,第二条记录的位置偏移量是 1,以此类推);第二个参数"行数"指示返回的记录条数。
在 tb_students_info 表中,使用 LIMIT 子句返回从第 4 条记录开始的行数为 5 的记录,输入的 SQL 语句和执行结果如下所示。
mysql> SELECT * FROM tb_students_info LIMIT 3,5;
+----+-------+---------+------+------+--------+------------+
| id | name | dept_id | age | sex | height | login_date |
+----+-------+---------+------+------+--------+------------+
| 4 | Jane | 1 | 22 | F | 162 | 2016-12-20 |
| 5 | Jim | 1 | 24 | M | 175 | 2016-01-15 |
| 6 | John | 2 | 21 | M | 172 | 2015-11-11 |
| 7 | Lily | 6 | 22 | F | 165 | 2016-02-26 |
| 8 | Susan | 4 | 23 | F | 170 | 2015-10-01 |
+----+-------+---------+------+------+--------+------------+
5 rows in set (0.00 sec)2、MySQL常用运算符详解
MySQL 支持 4 种运算符,分别是:
-
- 算术运算符
执行算术运算,例如:加、减、乘、除等。
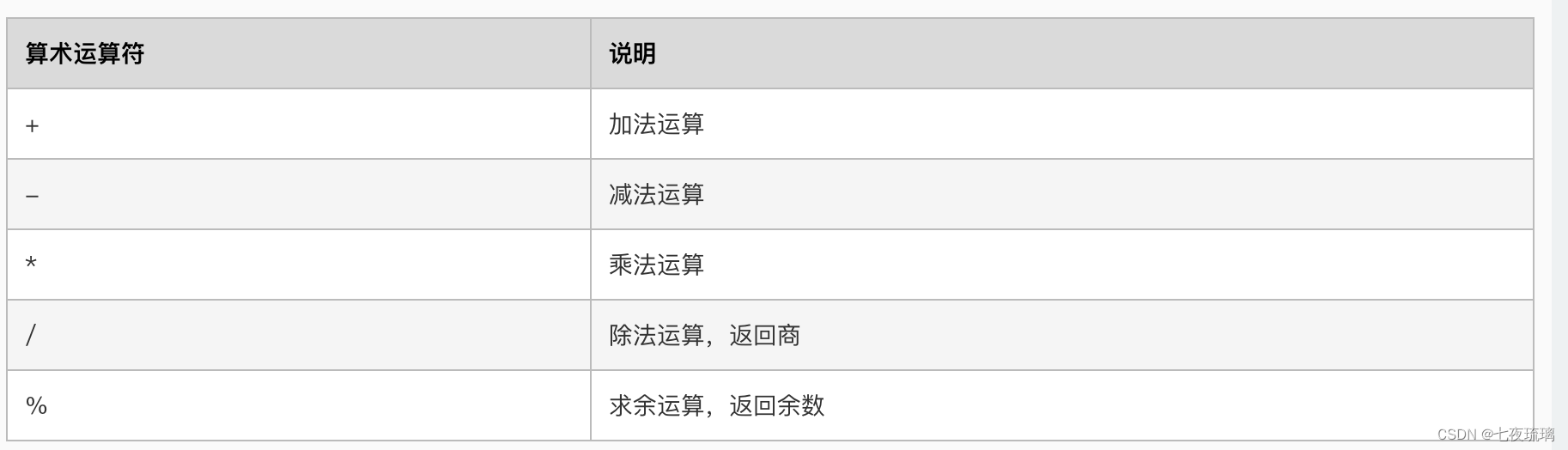
- 算术运算符
-
- 比较运算符
包括大于、小于、等于或者不等于,等等。主要用于数值的比较、字符串的匹配等方面。例如:LIKE、IN、BETWEEN AND 和 IS NULL 等都是比较运算符,还包括正则表达式的 REGEXP 也是比较运算符。

- 比较运算符
-
- 逻辑运算符
包括与、或、非和异或等逻辑运算符。其返回值为布尔型,真值(1 或 true)和假值(0 或 false)。
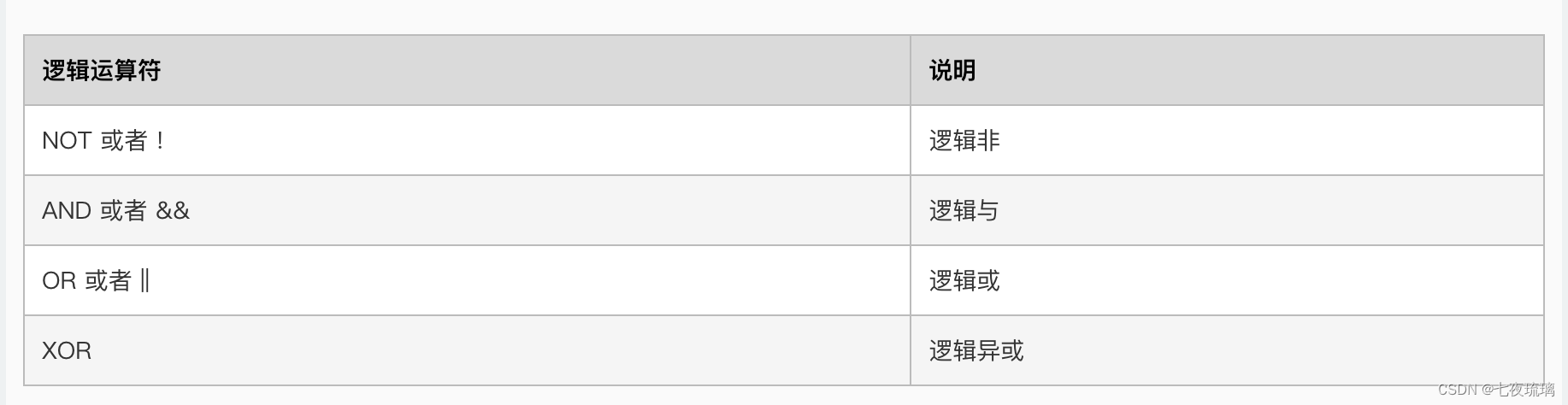
- 逻辑运算符
-
- 位运算符
包括按位与、按位或、按位取反、按位异或、按位左移和按位右移等位运算符。位运算必须先将数据转换为二进制,然后在二进制格式下进行操作,运算完成后,将二进制的值转换为原来的类型,返回给用户。
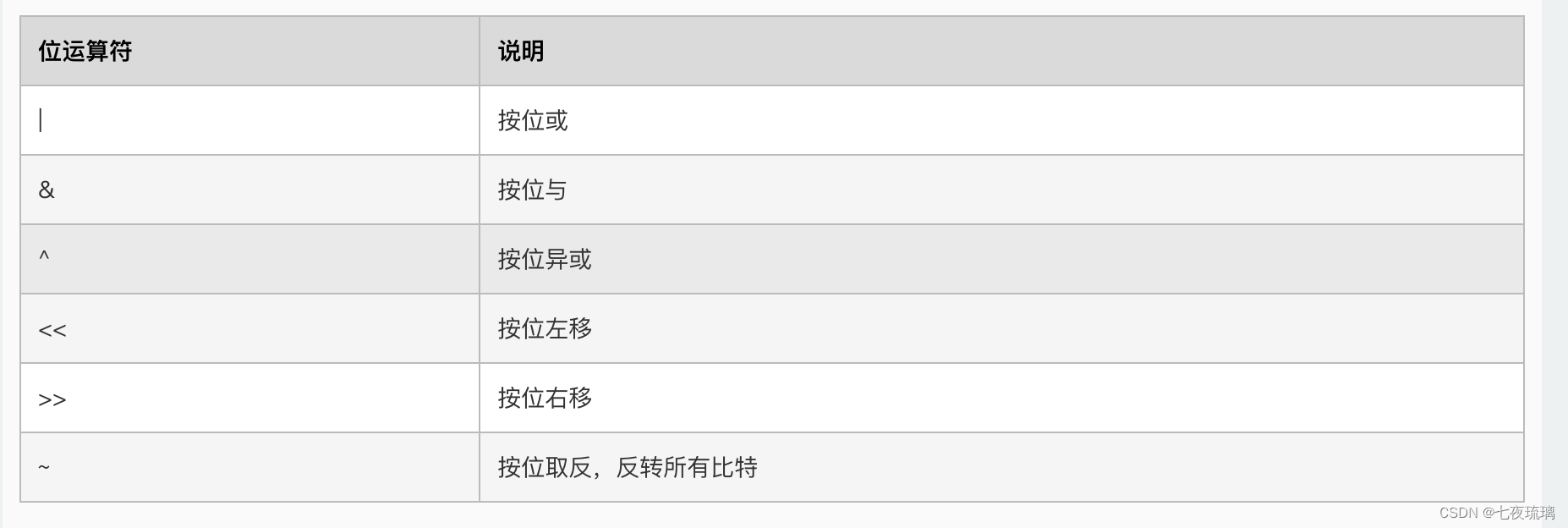
运算符的优先级决定了不同的运算符在表达式中计算的先后顺序,下表列出了 MySQL 中的各类运算符及其优先级。

可以看出,不同运算符的优先级是不同的。一般情况下,级别高的运算符优先进行计算,如果级别相同,MySQL 按表达式的顺序从左到右依次计算。
- 位运算符
另外,在无法确定优先级的情况下,可以使用圆括号"()"来改变优先级,并且这样会使计算过程更加清晰。