文章目录
- [36. Data augmentation](#36. Data augmentation)
-
- [36.1 Training with enhanced data](#36.1 Training with enhanced data)
- [36.2 Enhancement measures](#36.2 Enhancement measures)
- [36.3 Data augmentation summary](#36.3 Data augmentation summary)
- [37. Fine tuning](#37. Fine tuning)
-
- [37.1 Fine tuning Introduce](#37.1 Fine tuning Introduce)
- [37.2 Fine tuning Step](#37.2 Fine tuning Step)
- [37.3 Fine tuning summary](#37.3 Fine tuning summary)
- [38. Object detection](#38. Object detection)
-
- [38.1 Object detection](#38.1 Object detection)
- [38.2 Edge box implementation](#38.2 Edge box implementation)
- [39. Object detection algorithm](#39. Object detection algorithm)
-
- [39.1 Regional Convolutional Neural Network](#39.1 Regional Convolutional Neural Network)
-
- [39.1.1 R-CNN](#39.1.1 R-CNN)
- [39.1.2 Fast RCNN](#39.1.2 Fast RCNN)
- [39.1.3 Faster RCNN](#39.1.3 Faster RCNN)
- [39.1.4 Mask RCNN](#39.1.4 Mask RCNN)
- [39.1.5 summary](#39.1.5 summary)
- [39.2. SSD single shot detection](#39.2. SSD single shot detection)
- [39.3 YOLO(you only look once)](#39.3 YOLO(you only look once))
- [40. Neural style](#40. Neural style)
-
- [40.1 Basic concepts](#40.1 Basic concepts)
- [40.2 Working principle](#40.2 Working principle)
- [40.3 Loss function](#40.3 Loss function)
- [40.4 Advantages and disadvantages](#40.4 Advantages and disadvantages)
- [40.5 Application scenarios](#40.5 Application scenarios)
- [40.6 Implementation method](#40.6 Implementation method)
- [41. Kaggle cifar10 achieve](#41. Kaggle cifar10 achieve)
- [42. Encounter problems and solutions](#42. Encounter problems and solutions)
-
- [42.1 kernel problem](#42.1 kernel problem)
- [42.2 Path problem](#42.2 Path problem)
- [42.3 wandb problem](#42.3 wandb problem)
36. Data augmentation
- 数据增广是深度学习中一项重要的技术,主要用于增加训练数据集的数量和多样性,从而提高模型的泛化能力和鲁棒性。
- 数据增广不仅用于处理图片,也可用于文本和语音
基本概念: 数据增广是指通过对原始数据集进行一系列的变换来增加数据集数量,这些变换可以是几何变换(如旋转、缩放、裁剪等)、颜色变换(如改变亮度、对比度等)或添加噪声等方式。通过数据增广,可以生成新的训练数据,使模型更好地适应各种变化,提高模型的性能。
- 随机裁剪:随机裁剪是一种常用的数据增广技术,它可以从原始图像中随机裁剪出一部分作为新的训练样本。这种技术可以增加图像的多样性,使模型更好地感知图像的不同部分。
- 旋转:通过对原始图像进行旋转操作,可以生成具有不同方向的训练样本。这有助于模型学习不同方向的特征,提高模型的泛化能力。
- 缩放:缩放操作可以改变图像的大小,生成具有不同尺寸的训练样本。这有助于模型学习不同尺度的特征,提高模型对目标大小的适应性。
- 颜色变换:通过改变图像的亮度、对比度、饱和度等颜色属性,可以增加图像的多样性。这种技术有助于模型学习颜色不变性特征,提高模型的鲁棒性。
- 增加噪声:在图像中添加噪声可以模拟真实场景中的噪声干扰,使模型更具抗噪性。常见的噪声类型包括高斯噪声、椒盐噪声等。
- 图像扭曲:通过改变图像的形状,如拉伸或挤压,可以增加数据集的多样性。这种技术有助于模型学习不同形状的物体特征,提高模型的泛化能力。
36.1 Training with enhanced data
-
采集数据得到的训练场景与实际部署场景不同是常见的问题,这种变化有时会显著影响模型表现。在训练集中尽可能模拟部署时可能遇到的场景对模型的泛化性十分重要。
-
数据增强是指在一个已有数据集上操作使其有更多的多样性。对语音来说可以加入不同的背景噪音,对图片而言可以改变其颜色,形状等。
一般来说不会先将数据集做增广后存下来再用于训练;而是直接在线生成,从原始数据中读图片并随机做数据增强,再进入模型训练。通常只在训练时做数据增强而测试时不用。可以将数据增强理解为一个正则项。
36.2 Enhancement measures
翻转
左右翻转,上下翻转
- 要注意不是所有增强策略都总是可行,如建筑图片上下翻转就不太合适,而之前的树叶分类竞赛中的树叶图片就没关系。

切割
- 从图片中切割一块然后变形到固定形状。一般做法是随机取一个高宽比,随机取图片大小(切下部分占原图的百分数),随机取位置。

颜色
- 改变色调,饱和度,明亮度。

其他
- 还可以有很多种不同的方法,如高斯模糊,部分像素变黑,图片变形,锐化等等。理论上讲Photoshop能做到的都可以用作图片数据增强,但效果好坏另当别论。如果测试集中有类似的效果那么相应的数据增广手段会更有效。
36.3 Data augmentation summary
- 数据增广通过变形数据来获取多样性从而使得模型泛化性能更好
- 常见图片增广包括翻转,切割,变色
37. Fine tuning
37.1 Fine tuning Introduce
问题引入:很多时候,例如我们想对家具进行分类,但是往往在努力收集数据得到的数据集也比较小假如我们想识别图片中不同类型的椅子,然后向用户推荐购买链接。
-
一种可能的方法是首先识别100把普通椅子,为每把椅子拍摄1000张不同角度的图像,然后在收集的图像数据集上训练一个分类模型。 尽管这个椅子数据集可能大于Fashion-MNIST数据集,但实例数量仍然不到ImageNet中的十分之一。
-
适合ImageNet的复杂模型可能会在这个椅子数据集上过拟合。 此外,由于训练样本数量有限,训练模型的准确性可能无法满足实际要求。为了避免这种情况,我们可以有两种方法:
-
显然的想法就是收集更多的数据,但是,收集和标记数据可能需要大量的时间和金钱。 例如,为了收集ImageNet数据集,研究人员花费了数百万美元的研究资金。 尽管目前的数据收集成本已大幅降低,但这一成本仍不能忽视。
-
我们可以考虑迁移学习将从源数据集 学到的知识迁移到目标数据集。 例如,尽管ImageNet数据集中的大多数图像与椅子无关,但在此数据集上训练的模型可能会提取更通用的图像特征,这有助于识别边缘、纹理、形状和对象组合。 这些类似的特征也可能有效地识别椅子。
37.2 Fine tuning Step
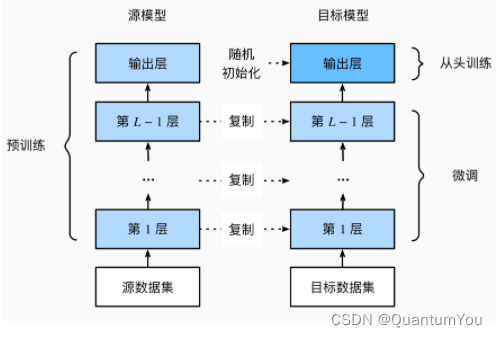
- 如图所示,微调包括以下四个步骤:
-
在源数据集(例如ImageNet数据集)上预训练神经网络模型,即源模型。
-
创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
-
向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
-
在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
-
通常来讲,微调速度更快,并且具有较强的正则性,一般学习率比较小,也不需要很多轮的数据迭代,对于不同的任务往往只需要改变最后输出层,这一层随机初始化即可。
37.3 Fine tuning summary
- 迁移学习将从源数据集中学到的知识"迁移"到目标数据集,微调是迁移学习的常见技巧。
- 除输出层外,目标模型从源模型中复制所有模型设计及其参数,并根据目标数据集对这些参数进行微调。但是,目标模型的输出层需要从头开始训练。
- 通常,微调参数使用较小的学习率,而从头开始训练输出层可以使用更大的学习率。
38. Object detection
38.1 Object detection
- 图片分类和目标检测在任务上的区别:图片分类已知有一个确定目标,任务是识别该目标属于何种分类,而目标检测不仅需要检测出图片中所有感兴趣的目标类别,并确定其位置,所以目标检测要比图片分类更复杂应用场景更广。
- 图片分类和目标检测在数据集上的区别:由于目标检测中每一张图片可能存在多个目标,每个目标我们不仅需要分类,还需要确定边缘框以给出目标位置信息,因此目标检测数据集的标注成本要显著高于图片分类,也就导致了目标检测数据集较小。
- 边缘框:用一个尽量小矩形框将目标物体大体框起来,边框的位置信息就可以表示目标位置在图片中的位置信息,常见的边缘框有两种表示方法:
- (左上x,左上y,右下x,右下y)
- (左上x,左上y,宽,高)
- 目标检测数据集的常见表示:每一行表示一个物体,对于每一个物体而言,用"图片文件名,物体类别,边缘框"表示,由于边缘框用4个数值表示,因此对于每一行的那一个物体而言,需要用6个数值表示。
- 目标检测领域常用数据集:COCO(80类物体,330K图片,所有图片共标注1.5M物体)
38.2 Edge box implementation
- 目标的位置
- 在图像分类任务中,我们假设图像中只有一个主要物体对象,我们只关注如何识别其类别。 然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。 在计算机视觉里,我们将这类任务称为目标检测 (object detection)或*目标识别*(object recognition)。目标检测在多个领域中被广泛使用。 例如,在无人驾驶里,我们需要通过识别拍摄到的视频图像里的车辆、行人、道路和障碍物的位置来规划行进线路。 机器人也常通过该任务来检测感兴趣的目标。安防领域则需要检测异常目标,如歹徒或者炸弹。
- 边界框
-
在目标检测中,我们通常使用边界框 (bounding box)来描述对象的空间位置。 边界框是矩形的,由矩形左上角的以及右下角的x 和y 坐标决定。 另一种常用的边界框表示方法是边界框中心的(x ,y)轴坐标以及框的宽度和高度。
-
在这里,我们定义在这两种表示法之间进行转换的函数:
box_corner_to_center从两角表示法转换为中心宽度表示法,而box_center_to_corner反之亦然。 输入参数boxes可以是长度为4的张量,也可以是形状为(n ,4)的二维张量,其中n是边界框的数量。
python
#@save
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
#@save
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes- 我们将根据坐标信息定义图像中狗和猫的边界框。 图像中坐标的原点是图像的左上角,向右的方向为x 轴的正方向,向下的方向为y轴的正方向。
python
# bbox是边界框的英文缩写
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]- 我们可以将边界框在图中画出,以检查其是否准确。 画之前,我们定义一个辅助函数
bbox_to_rect。 它将边界框表示成matplotlib的边界框格式。
python
#@save
def bbox_to_rect(bbox, color):
# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:
# ((左上x,左上y),宽,高)
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)- 在图像上添加边界框之后,我们可以看到两个物体的主要轮廓基本上在两个框内。
python
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));
- 小结
- 目标检测不仅可以识别图像中所有感兴趣的物体,还能识别它们的位置,该位置通常由矩形边界框表示。
- 我们可以在两种常用的边界框表示(中间,宽度,高度)和(左上,右下)坐标之间进行转换。
39. Object detection algorithm
39.1 Regional Convolutional Neural Network
39.1.1 R-CNN
- 使用启发式搜索算法来选择锚框
- 使用预训练模型来对每个锚框抽取特征(每个锚框当作一个图片,用CNN)
- 训练一个SVM来类别分类(神经网络之前,category prediction)
- 训练一个线性回归模型来预测边缘框偏移(bounding box prediction)
- 兴趣区域(Rol)池化层
- 给定一个锚框,均匀分割(如果没法均匀分割,取整)成 n x m 块,输出每块的最大值(max pooling)
- 不管锚框多大,总是输出nm个值
- 目的:每个锚框都可以变成想要的形状
-
定义与背景:
- R-CNN是第一个成功将深度学习应用到目标检测上的算法。
- 在R-CNN之前,目标检测通常基于手工设计的特征和传统的机器学习算法,如SVM和随机森林,这些方法在复杂场景中往往效果有限。
- R-CNN通过引入深度学习的卷积神经网络(CNN),极大地改进了目标检测的准确性和性能。
-
算法流程:
- 候选区域生成:使用Selective Search等方法从一张图像中生成约2000个候选区域(候选框)。
- 特征提取:对每个候选区域,使用深度网络(如AlexNet)提取固定长度的特征向量。
- 分类:将提取的特征向量送入一个独立的SVM分类器,以判断该区域是否包含目标,并预测所属类别。
- 位置修正:为了提升定位准确性,R-CNN还训练了一个边界框回归模型,对候选框的位置进行精细修正。
-
创新与特点:
- 引入深度学习:R-CNN首次将深度学习引入目标检测领域,显著提升了检测性能。
- 候选区域机制:通过生成候选区域,避免了对整个图像进行密集的滑动窗口搜索,提高了算法效率。
- 特征学习能力强:利用CNN提取的特征具有更强的判别性,有助于准确检测目标。
-
后续发展:
- 自R-CNN之后,研究人员提出了一系列基于R-CNN的改进算法,如Fast R-CNN、Faster R-CNN和Mask R-CNN等,这些算法在保持高精度的同时,进一步提升了检测速度和应用范围。
39.1.2 Fast RCNN
-
RCNN需要对每个锚框进行CNN运算,这些特征抽取计算有重复,并且锚框数量大,特征抽取的计算量也大。Fast RCNN改进了这种计算量大的问题
-
使用CNN对整张图片抽取特征(快的关键)
-
使用Rol池化层对每个锚框(将在原图片中搜索到的锚框,映射到CNN得到的结果上),生成固定长度的特征
Fast R-CNN是目标检测领域的一个重要模型,它在R-CNN的基础上进行了改进,显著提高了检测速度和效率
一、定义与背景
- Fast R-CNN是Ross Girshick在R-CNN之后提出的另一种目标检测模型。与R-CNN相比,Fast R-CNN的主要优势在于其更高的检测速度和更高效的训练过程。它通过使用深度卷积网络(如VGG16)一次性处理整张图像来提取特征,而不是像R-CNN那样对每个候选区域分别进行特征提取,从而大大减少了计算量。
二、算法流程
Fast R-CNN的算法流程主要包括以下几个步骤:
- 候选区域生成:使用Selective Search等方法从输入图像中生成多个候选区域(也称为感兴趣区域,ROI)。
- 特征提取:通过一个深度卷积网络(如VGG16)对整张输入图像进行特征提取,生成特征图。然后,将每个候选区域映射到特征图上,得到对应的特征向量。
- RoI Pooling:由于不同候选区域的大小和形状可能不同,因此需要对它们进行尺寸归一化,以便输入到后续的全连接层中。Fast R-CNN采用了RoI Pooling层来实现这一目的。具体地,它将每个候选区域的特征图划分为固定数量的子区域(如7x7),并对每个子区域进行最大池化操作,从而得到一个固定长度的特征向量。
- 分类与回归:将RoI Pooling层输出的特征向量输入到两个并行的全连接层中,一个用于分类(预测候选区域所属的类别),另一个用于边界框回归(预测候选区域的位置偏移量,以更准确地定位目标)。
三、特点与优势
- 高效性:Fast R-CNN仅对整张图像进行一次卷积操作,而不是像R-CNN那样对每个候选区域分别进行特征提取,因此大大提高了检测速度。同时,其端到端的训练方式也使得模型更为高效。
- 准确性:Fast R-CNN在Pascal VOC数据集上的accuracy从R-CNN的62%提升至66%,表明其在保持高效率的同时,也具有良好的检测准确性。
- 灵活性:Fast R-CNN可以使用不同的深度卷积网络作为特征提取器,如VGG16、ResNet等,以适应不同的应用场景和需求。
39.1.3 Faster RCNN
- 在Fast RCNN基础上变得更快
- 使用一个 区域提议网络来替代启发式搜索获得更好的锚框
- 如下图所示,将CNN结果输入到卷积层,然后用锚框去圈区域,这些锚框很多有好有坏,然后进行预测,binary 预测是预测这个锚框的好坏,即有没有有效的圈住物体,bounding box prediction预测是对锚框进行一些改进,最后用NMS(非极大值抑制)对锚框进行合并。
- 具体来说,区域提议网络的计算步骤如下:
- 使用填充为1的3×3的卷积层变换卷积神经网络的输出,并将输出通道数记为c。这样,卷积神经网络为图像抽取的特征图中的每个单元均得到一个长度为c的新特征。
- 以特征图的每个像素为中心,生成多个不同大小和宽高比的锚框并标注它们。
- 使用锚框中心单元长度为c的特征,分别预测该锚框的二元类别(含目标还是背景)和边界框。
- 使用非极大值抑制,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
39.1.4 Mask RCNN
- 如果有像素级别的标号,使用FCN(fully convolutional network)利用这些信息。可以提升CNN的性能
- Rol align。之前的Rol进行池化的时候,如果没法整除,可以直接取整。但是像素级别的标号预测的时候,会造成偏差的累积,导致边界预测不准确。未来避免这种情况,使用Rol align,也就是当没法整除,对每个像素值进行按比例分配。
- 具体来说,Mask R-CNN将兴趣区域汇聚层替换为了兴趣区域对齐 层,使用双线性插值(bilinear interpolation)来保留特征图上的空间信息,从而更适于像素级预测。 兴趣区域对齐层的输出包含了所有与兴趣区域的形状相同的特征图。 它们不仅被用于预测每个兴趣区域的类别和边界框,还通过额外的全卷积网络预测目标的像素级位置。
39.1.5 summary
- R-CNN是最早也是最有名的一类基于锚框和CNN的目标检测算法
- Fast/Faster RCNN 持续提升性能
- Faster RCNN和Mask RCNN是在要求高精度场景下常用的算法(但是速度是最慢的)
39.2. SSD single shot detection
-
生成锚框
- 对每个像素,生成多个以它为中心的锚框
- 给定 n 个大小 s 1 , . . . , s n s_1,...,s_n s1,...,sn和m个高宽比,生成n+m-1个锚框,其大小和高宽比分别为: ( s 1 , r 1 ) , ( s 2 , r 1 ) . . . , ( s n , r 1 ) , ( s 1 , r 2 ) , . . . , ( s 1 , r m ) (s_1,r_1),(s_2,r_1)...,(s_n,r_1),(s_1,r_2),...,(s_1,r_m) (s1,r1),(s2,r1)...,(sn,r1),(s1,r2),...,(s1,rm)
-
SSD模型
- 对多个分辨率下的卷积特征,生成锚框,预测
- 一个基础网络,抽取特征,然后用多个卷积层来减半高宽
- 在每段都生成锚框
- 底部段拟合小物体
- 顶部段拟合大物体
- 对每个锚框预测类别和边缘框
-
总结
- 速度快,精度很低。这么多年,作者没有持续的提升,但是启发了后面的一系列工作,实现上相对比较简单。
- SSD通过单神经网络来检测模型(single shot)
- 以像素为中心的产生多个锚框
- 在多个段的输出上进行多尺度的检测
39.3 YOLO(you only look once)
- SSD中锚框大量重复,因此浪费了很多计算资源
- YOLO将图片均分为 S X S 个锚框
- 每个锚框预测 B 个边缘框(防止多个物体出现在一个锚框里面)
- 后续版本 v2 v3 v4 有持续改进
- 非锚框算法
YOLO(You Only Look Once)是一种高效的目标检测算法,它通过一次前向传播即可同时预测多个目标的位置和类别,显著提高了目标检测的速度和效率。
YOLOv1
1. 基本原理
- YOLOv1将目标检测任务视为一个回归问题,使用单个神经网络在整幅图像上进行预测。
- 将输入图像划分为SxS的网格(如7x7),每个网格预测B个边界框(bounding box)以及这些边界框的置信度和C个类别概率。
2. 特点
- 速度快:由于仅需要一次前向传播,因此检测速度非常快。
- 端到端训练:直接优化检测性能,不需要额外的分类或定位步骤。
3. 局限性
-
对小目标和密集目标的检测效果可能不佳。
-
由于网格划分,有时会出现边界框定位不准确的情况。
YOLOv2
1. 改进点
- 引入批量归一化(Batch Normalization),提高了模型的收敛速度和稳定性。
- 使用高分辨率的图像进行训练,提高了对小目标的检测效果。
- 引入锚框(anchor boxes),允许模型预测多种尺度和比例的边界框。
- 提出了一个新的网络结构Darknet-19,作为YOLOv2的主干网络。
2. 拓展数据集
-
YOLO9000:除了使用COCO数据集进行训练外,还结合了ImageNet数据集,实现了对9000多种类别的检测。
YOLOv3
1. 改进点
-
使用更深、更复杂的网络结构Darknet-53,提高了特征提取能力。
-
引入了多尺度预测,提高了对不同大小目标的检测效果。
-
使用了逻辑回归损失函数来替代softmax进行分类预测,以处理多标签分类问题。
YOLOv4
1. 改进点
- 采用了CSPDarkNet53作为主干网络,进一步提高了特征提取能力。
- 引入了SPP(空间金字塔池化)模块和PAN(路径聚合网络),增强了特征融合和上下文信息提取能力。
- 使用了CIOU_Loss作为损失函数,提高了边界框的回归精度。
- 采用了多种数据增强和模型优化技巧,如Mosaic数据增强、CmBN(跨小批量标准化)等。
2. 性能
- YOLOv4在保持高速度的同时,进一步提高了目标检测的精度,尤其在复杂场景和小目标检测方面表现出色。
40. Neural style
40.1 Basic concepts
- 样式迁移:将样式图片中的风格(如油画、水彩等)迁移到内容图片上,生成一张新的合成图片。
40.2 Working principle
基于卷积神经网络(CNN)的样式迁移是这一领域的奠基性工作。其工作原理大致如下:
-
初始化合成图片:通常将合成图片初始化为内容图片。
-
选择预训练的卷积神经网络:用于抽取图片的特征。在训练过程中,该网络的权重保持不变。
-
特征抽取:卷积神经网络通过多个层逐级抽取图像的特征。可以选择某些层的输出作为内容特征或样式特征。
- 内容特征:通常选择较深的网络层输出作为内容特征,因为它们能够捕获更高级别的图像信息。
- 样式特征:通过计算不同网络层输出之间的相关性来获取样式特征,这可以捕获图像的纹理和颜色信息。
-
训练过程:
- 通过优化算法(如梯度下降)迭代更新合成图片,使其同时满足内容损失和样式损失的要求。
- 内容损失:使合成图片在内容特征上与内容图片接近。
- 样式损失:使合成图片在样式特征上与样式图片接近。
- 总变差损失:有助于减少合成图片中的噪点。
40.3 Loss function
样式迁移常用的损失函数由三部分组成:
- 内容损失:使合成图像与内容图像在内容特征上接近。
- 样式损失:使合成图像与样式图像在样式特征上接近。
- 总变差损失:有助于减少合成图像中的噪点。
40.4 Advantages and disadvantages
- 优点:能够生成具有特定风格的合成图片,为艺术创作和图像处理提供了新的可能性。
- 缺点:每张图片都需要重新训练,计算成本较高。此外,生成的合成图片可能存在噪声或失真等问题。
40.5 Application scenarios
样式迁移在艺术创作、广告设计、游戏开发等领域具有广泛的应用前景。例如,可以将名画的风格迁移到现代照片上,创造出独特的艺术效果;也可以将不同的艺术风格应用于广告图像,提高广告的吸引力和创新性。
40.6 Implementation method
如下图所示,可以用一个预训练好的神经网络来实现样式迁移:
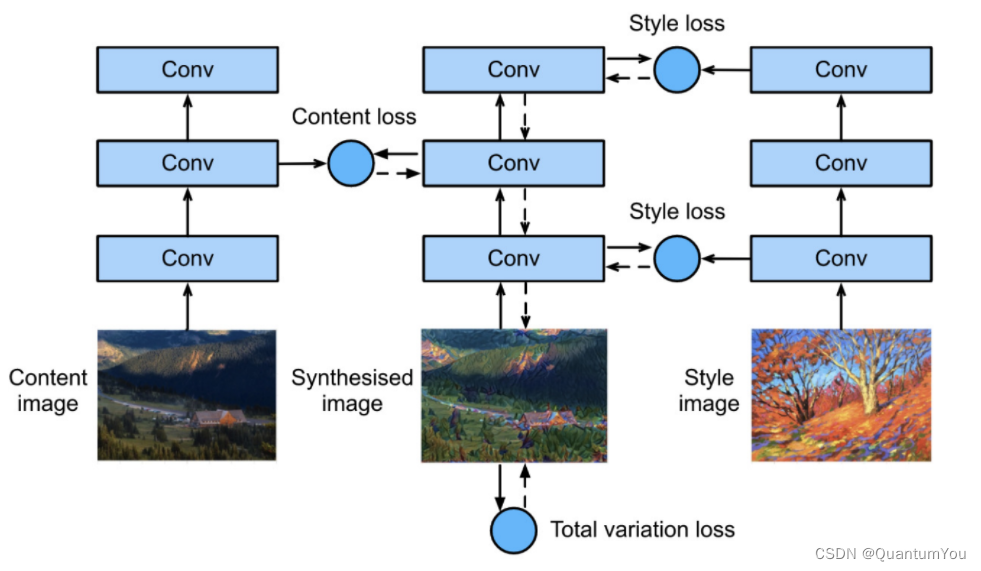
- 1:复制内容图片来初始化一张图片,之后将这张图片中的像素作为参数进行更新,最终得到合成的图片
- 2:将内容图片,当前的合成图片,样式图片分别输入一个相同的预训练好的神经网络
- 3:假设该神经网络的不同层分别提取与内容和风格相关的信息,可以据此得到一个损失:
- 将合成图片与内容 相关的层的输出与内容 图片对应层的输出进行处理,得到内容损失
- 将合成图片与风格 相关的层的输出与风格 图片对应层的输出进行处理,得到风格损失
- 对合成图片本身,统计图片中的高频噪点(即过明或过暗像素点),得到全变分损失
- 将三部分损失加起来得到总的样式迁移的损失函数
- 4:利用3定义的损失函数,以合成图片的每个像素点为参数进行梯度下降,得到最终合成的图片
内容损失
神经网络内容相关层的输出的相似度可以直接反应两张图片在内容上的相似度,因此内容损失可以直接将对应层的输出视为内容直接求平方差损失。
风格损失:格拉姆矩阵
对于内容层,可以直接将对应层的输出求平方差损失,但是对于风格则略有不同
一般认为,风格层对应的输出的多个通道分别对应着不同类型的信息,如果将输出的形状从 b a t c h _ s i z e = 1 , c h a n n e l s , h , w batch\\_size=1,channels,h,w batch_size=1,channels,h,w转化为 c h a n n e l s , h ∗ w channels,h\*w channels,h∗w就能得到通道数个向量,以 x 1 , x 2 . . . x c x_1,x_2...x_c x1,x2...xc表示,代表不同通道所提取出的不同信息,而风格可以视作这些信息之间的关联,即相似度。
定义格拉姆矩阵 X ∗ X T ∈ R c ⋅ c \bold X * \bold X^T \in R^{c \cdot c} X∗XT∈Rc⋅c,矩阵的第i行第j列即向量 x i x_i xi与 x j x_j xj的内积,这个矩阵就代表了一张图片的风格。
对于生成图片和风格图片的格拉姆矩阵求平方差损失就能得到所需的风格损失
此外,为了让风格损失不受格拉姆矩阵及向量的大小影响,实际将格拉姆矩阵除以这些大小 c h a n n n e l s ∗ h ∗ w channnels*h*w channnels∗h∗w。
全变分损失
用于去除高频噪点(过明过暗像素点)
∑ i , j ∣ x i , j − x i + 1 , j ∣ + ∣ x i , j − x i , j + 1 ∣ \sum_{i, j} \left|x_{i, j} - x_{i+1, j}\right| + \left|x_{i, j} - x_{i, j+1}\right| i,j∑∣xi,j−xi+1,j∣+∣xi,j−xi,j+1∣
41. Kaggle cifar10 achieve
42. Encounter problems and solutions
42.1 kernel problem
已解决
- 解决Jupyter Notebook当中有关内核挂掉的问题
- 加入以下代码
python
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"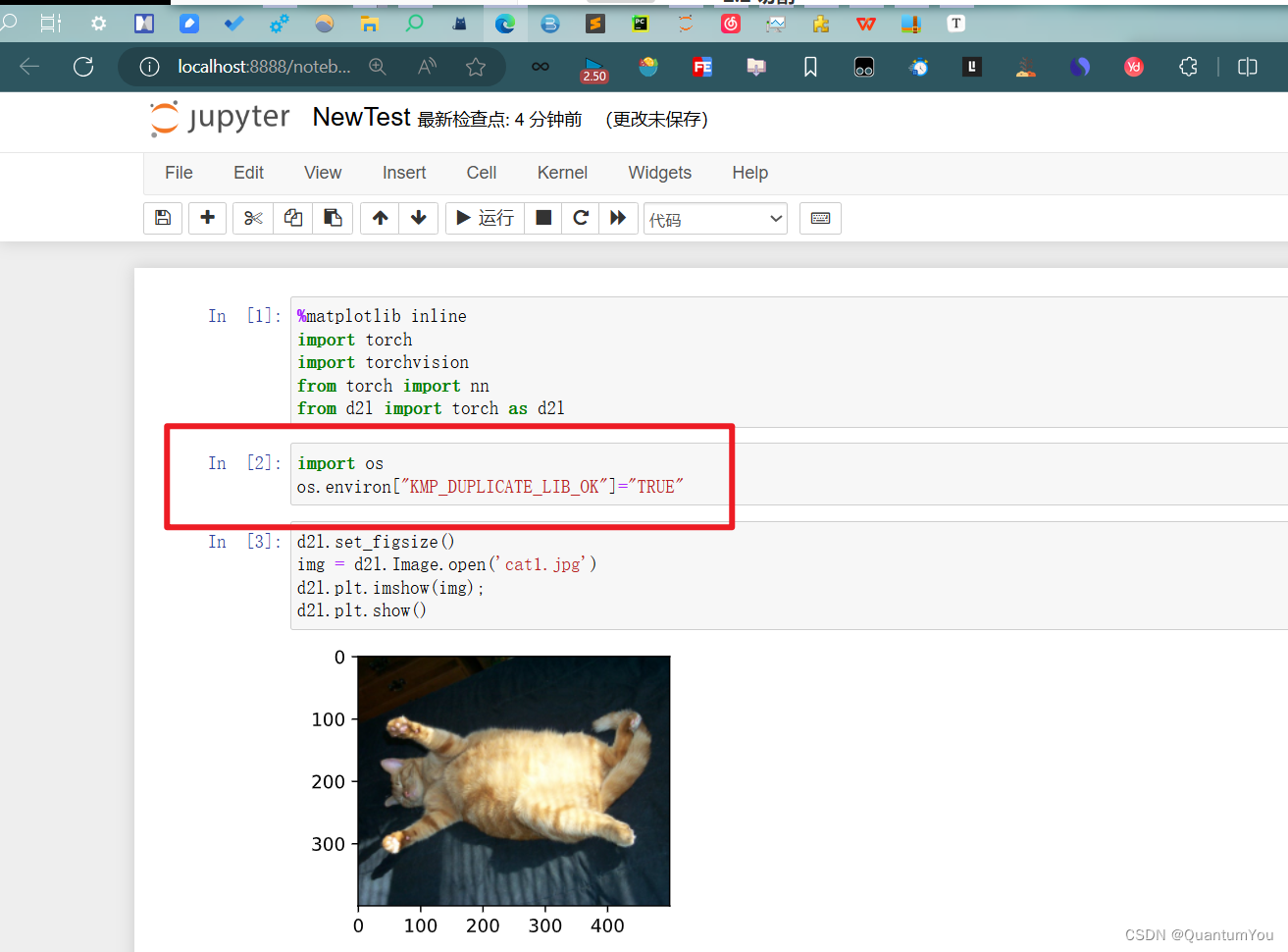
42.2 Path problem
已解决
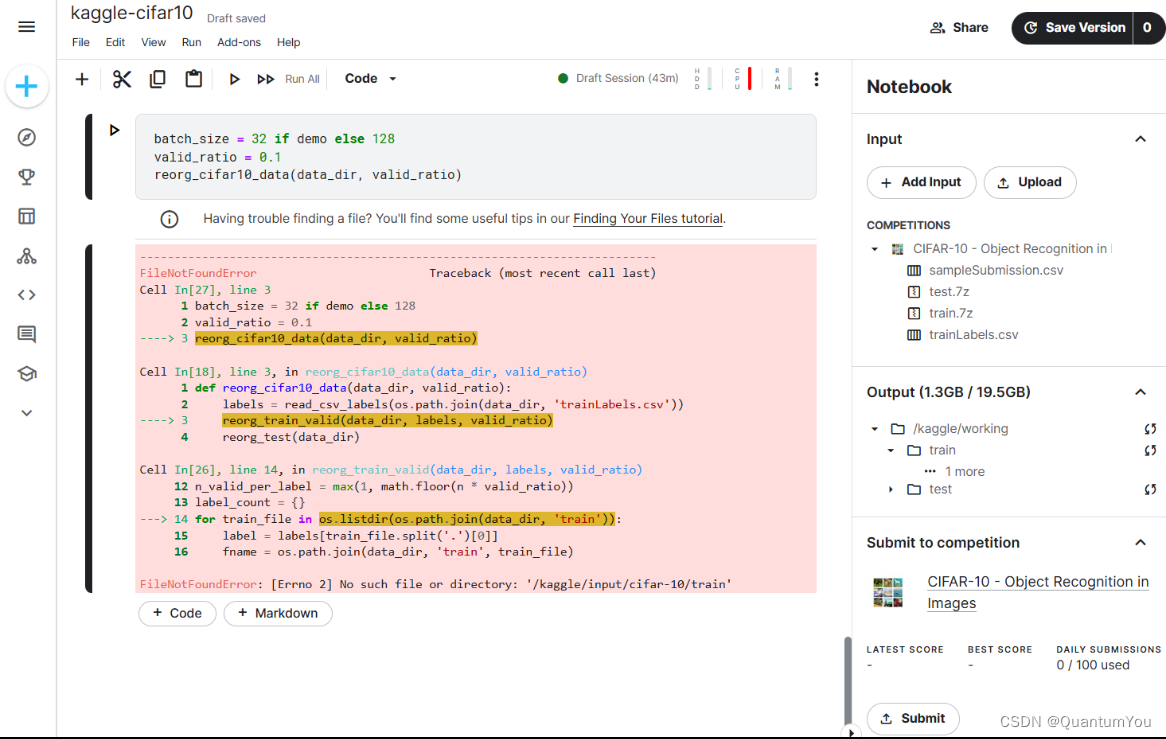
解决方案:使用相对路径 ,进行简化代替
42.3 wandb problem
已解决