使用Python进行音频处理和机器学习的简介

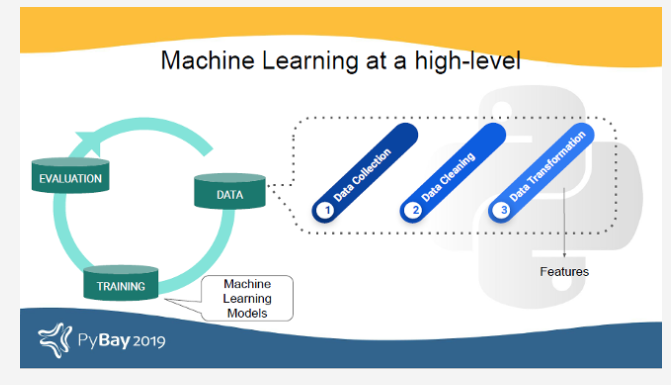
从高层次上讲,任何机器学习问题都可以分为三种任务:数据任务(数据收集,数据清理和特征形成),培训(使用数据特征构建机器学习模型)和评估(评估模型) 。功能,定义为"个人可测量PROPERT IES 或现象特性s的被观察到的,"是非常有用的,因为它们可帮助机器识别数据,并将其分类到类别或预测的值。
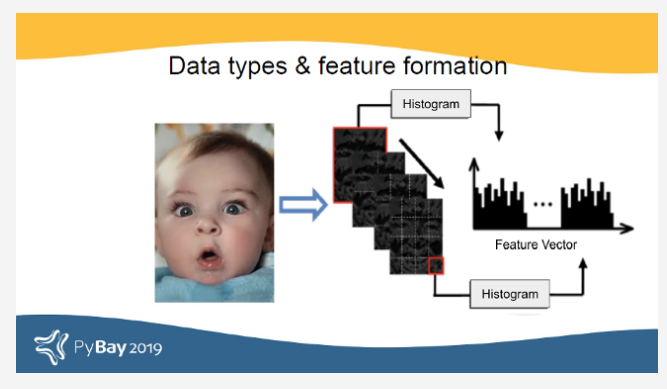
不同的数据类型使用非常不同的处理技术。以图像作为数据类型的示例为例:人眼看起来就像一件事,但是在使用不同的滤镜(取决于应用程序)将其转换为从图像的像素值派生的数值特征后,机器对它的看法有所不同。
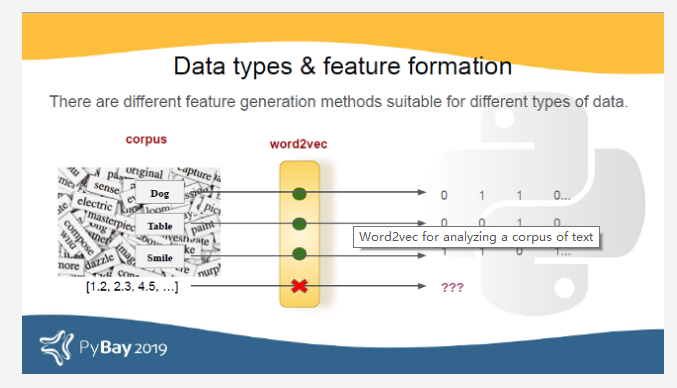
Word2vec非常适合处理文本正文。它将单词表示为数字向量,两个单词向量之间的距离决定了单词的相似程度。如果我们尝试将Word2vec应用于数值数据,则结果可能没有意义。
因此,有一些特定于音频数据类型的处理技术可以很好地与音频配合使用。
什么是音频信号?
音频信号是在可听频率范围内振动的信号。当有人讲话时,它会产生气压信号。耳朵吸收了这些气压差并与大脑沟通。这就是大脑如何帮助一个人识别信号是语音并理解别人在说什么的方式。
有很多执行音频处理的MATLAB工具,但Python中没有那么多工具。在介绍一些可用于处理Python中音频信号的工具之前,让我们研究适用于音频处理和机器学习的一些音频功能。
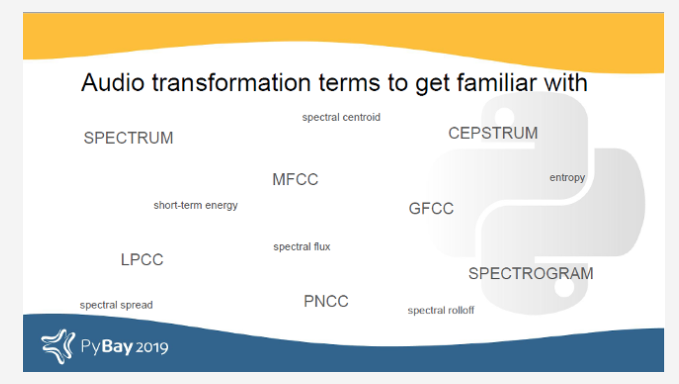
在语音和音频处理中重要的一些数据特征和转换包括梅尔频率倒谱系数(MFCC),伽马通频率倒谱系数(GFCC),线性预测倒谱系数(LFCC),树皮频率倒谱系数(BFCC),功率归一化倒谱系数(PNCC),频谱,倒谱,频谱图等。
我们可以直接使用其中一些功能,并从其他一些功能(例如频谱)中提取功能,以训练机器学习模型。
什么是频谱和倒频谱?
频谱和倒频谱是音频处理中的两个特别重要的功能。

从数学上讲,频谱是信号的傅立叶变换。傅立叶变换将时域信号转换为频域。换句话说,频谱是输入音频的时域信号的频域表示。
倒谱是通过取频谱,随后逆傅立叶变换的对数幅度形成。这导致信号既不在频域中(因为我们进行了傅立叶逆变换),也不在时域中(因为我们在进行傅立叶逆变换之前采用了对数幅度)。结果信号的域称为频率。
这与听力有什么关系?
我们在频域中关心信号的原因与耳朵的生物学有关。在处理和解释声音之前,必须发生许多事情。一种情况发生在耳蜗中,耳蜗充满了流体,其中有成千上万的与神经相连的细毛。有些头发很短,有些则比较长。较短的头发与较高的声音频率发生共振,而较长的头发与较低的声音频率发生共振。因此,耳朵就像天然的傅立叶变换分析仪!

关于人类听力的另一个事实是,当声音频率增加到1kHz以上时,我们的耳朵开始对频率的选择性降低。这与称为Mel滤波器组的东西很好地对应。
使频谱通过梅尔滤波器组,然后取对数幅度和离散余弦变换(DCT)产生梅尔倒谱。DCT提取信号的主要信息和峰值。它还广泛用于JPEG和MPEG压缩中。峰值是音频信息的要点。通常,从梅尔倒谱中提取的前13个系数称为MFCC。它们保存了关于音频的非常有用的信息,并经常用于训练机器学习模型。
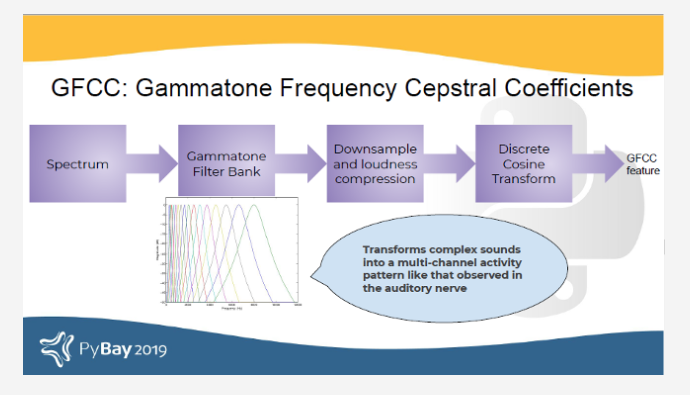
受人耳启发的另一个滤波器是Gammatone滤波器组。该滤波器组用作耳蜗的前端模拟。因此,它在语音处理中有许多应用,因为它旨在复制我们的听觉。

GFCC是通过使光谱通过Gammatone滤波器组,然后进行响度压缩和DCT形成的。第一个(大约)22个功能部件称为GFCC。GFCC在语音处理中有许多应用,例如说话人识别。
在音频处理任务(尤其是语音)中有用的其他功能包括LPCC,BFCC,PNCC,以及频谱特征,例如频谱通量,熵,滚降,质心,扩展和能量熵。
建立分类器
作为一项快速实验,让我们尝试使用一个名为pyAudioProcessing的基于Python的开源库,构建一个具有频谱特征和MFCC,GFCC以及MFCC和GFCC组合的分类器。
首先,我们希望pyAudioProcessing将音频分为三类:语音,音乐或鸟类。
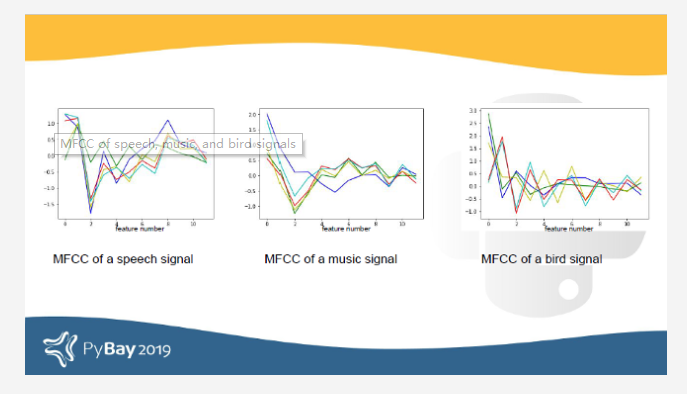
使用一个小的数据集(每个班级有50个样本用于训练)并且没有任何微调,我们可以评估这种分类模型识别音频类别的潜力。
接下来,让我们尝试pyAudioProcessing使用的音乐流派分类问题GZTAN音频数据集和音频功能:MFCC和光谱特征。

有些类型的作品表现不错,而另一些则有改进的空间。可以从该数据中探索的一些事物包括:
- 数据质量检查:是否需要更多数据?
- 音乐节拍和其他方面的功能
- 除音频外的其他功能,例如转录和文本
- 不同的分类器会更好吗?已经有关于使用神经网络对音乐流派进行分类的研究。
无论此快速测试的结果如何,很明显,这些功能都可以从信号中获取有用的信息,机器可以使用它们,并且它们构成了可以使用的良好基准。