一、数据接口分析
主页地址:某花顺
1、抓包
通过抓包可以发现在登陆时,网站首先请求了pwdRangeCalcRegular.json、getGS两个接口,接着请求dologinreturnjson2进行登陆,但是此接口会返回请先完成滑块验证码校验的响应。然后网站就会请求getPreHandle接口获取滑块验证码,在滑动验证码之后,会请求getTicket接口进行校验,校验成功之后,会再次发送登陆请求。
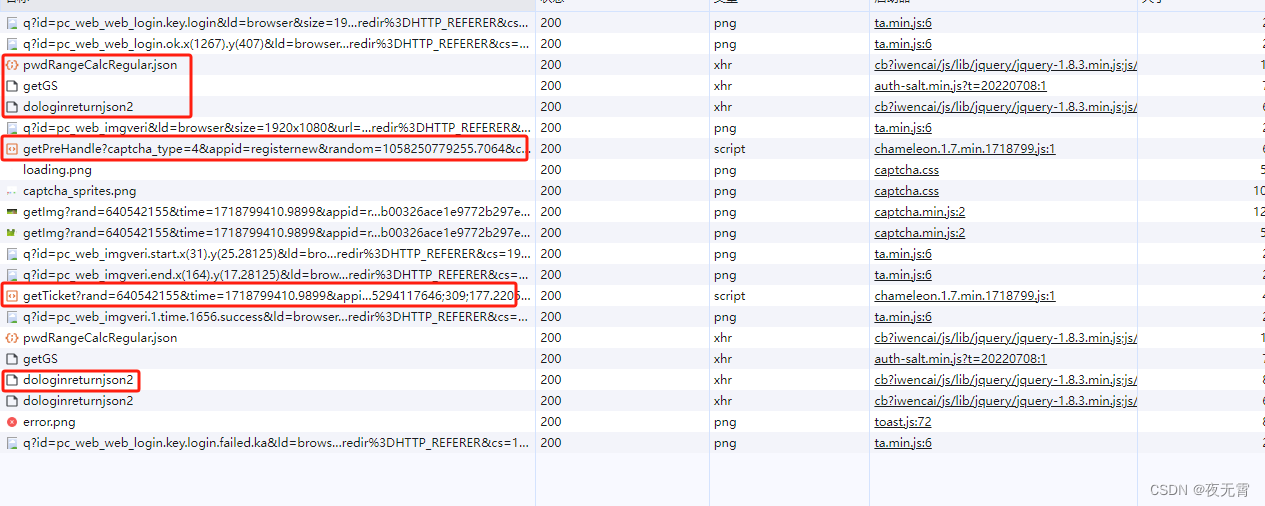
2、判断是否有加密参数
2.1 请求参数是否加密?
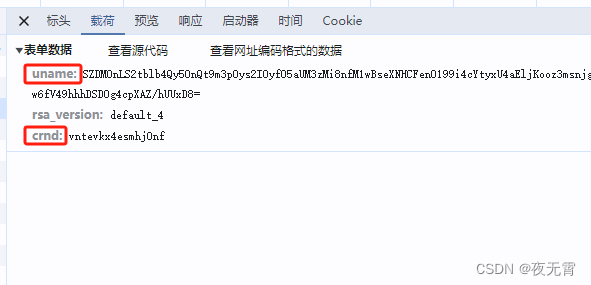
(1) getGS
通过查看"载荷"模块,可以发现有两个加密参数,uname和crnd
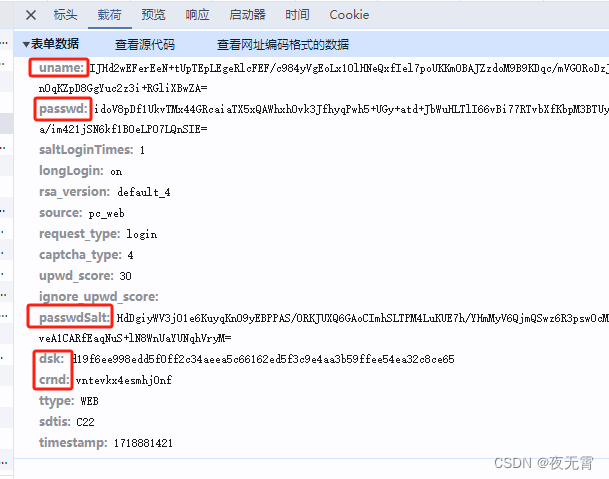
(2)dologinreturnjson2
这个接口的加密参数就比较多了,需要关注的有三个参数uname、passwd、passwdSalt,除了这三个参数以外,还有两个参数。一个是dsk,通过查看接口可以发现这个参数是上面getGS接口返回的,另一个是crnd,这个参数与getGS请求携带的crnd是一样的。
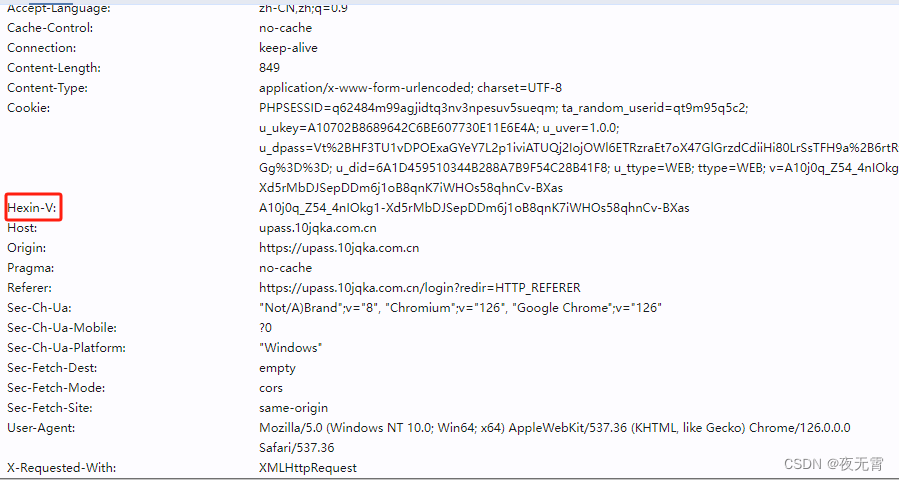
2.2 请求头是否加密?
通过查看"标头"模块可以发现,请求头中有一个Hexin-V,且这个参数的值与cookie中的v值一致,所以可以不需要关心这个请求头的值,把cookie中的v值生成出来,放到请求头中就可以了。
2.3. 响应是否加密?
无
2.4. cookie是否加密?
通过2.3可知有一个v的加密cookie
二、加密位置定位
1、加密参数
通过搜索关键字passwd:可以很轻松的搜索到加密位置,发现此处是大部分加密参数的加密位置,且getGS接口也是从此处请求的,从此处进入到getSaltGS方法内部,就可以定位到getGS接口所需要的参数。
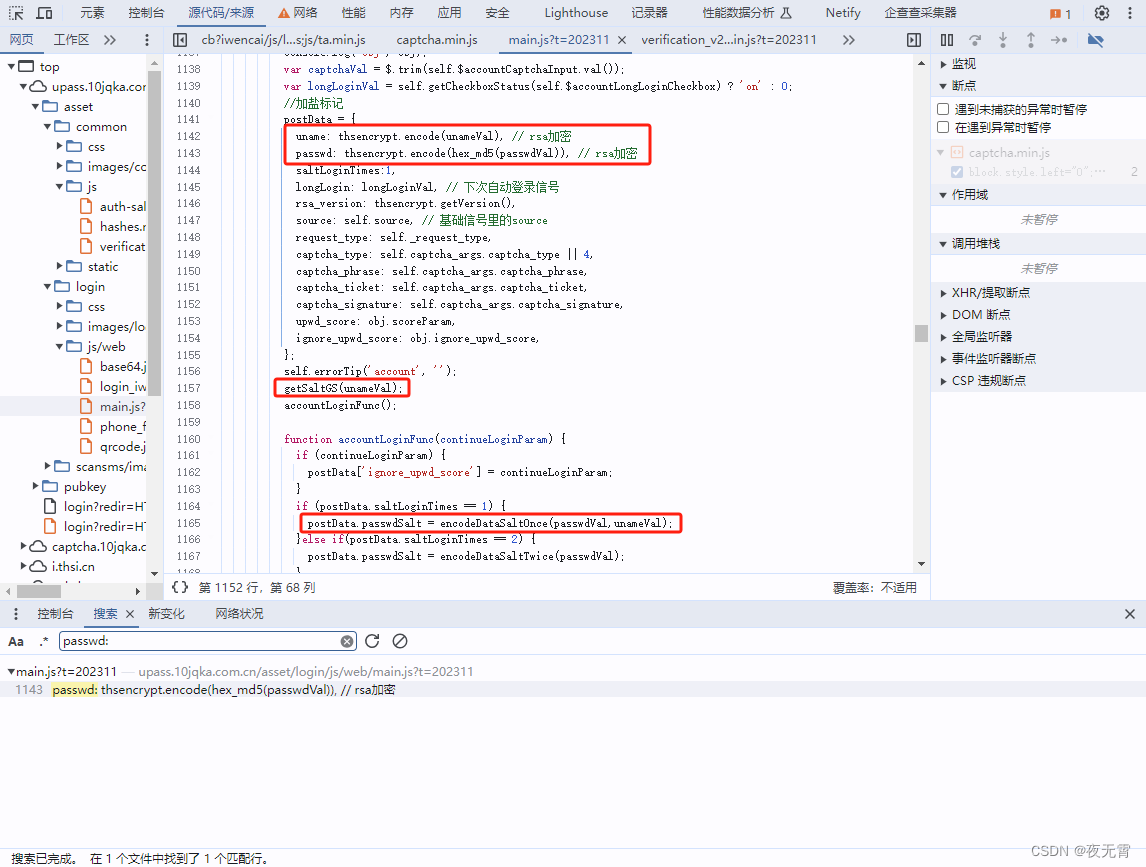
同时我们可以发现,其中有几个参数我们是不知道的,captcha_phrase、captcha_ticket、captcha_signature,这三个参数通过变量名就可以看出是跟滑块验证码有关的,所以可以暂时不处理。除了这三个参数以外,还有两个参数scoreParam和ignore_upwd_score,通过搜索关键字scoreParam =可以发现这个参数的赋值位置。
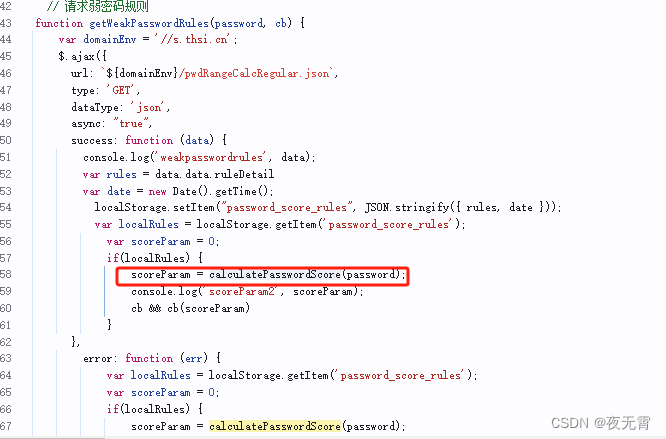
不难看出,此参数就是网站根据请求pwdRangeCalcRegular.json返回的规则,对输入的密码进行评分。
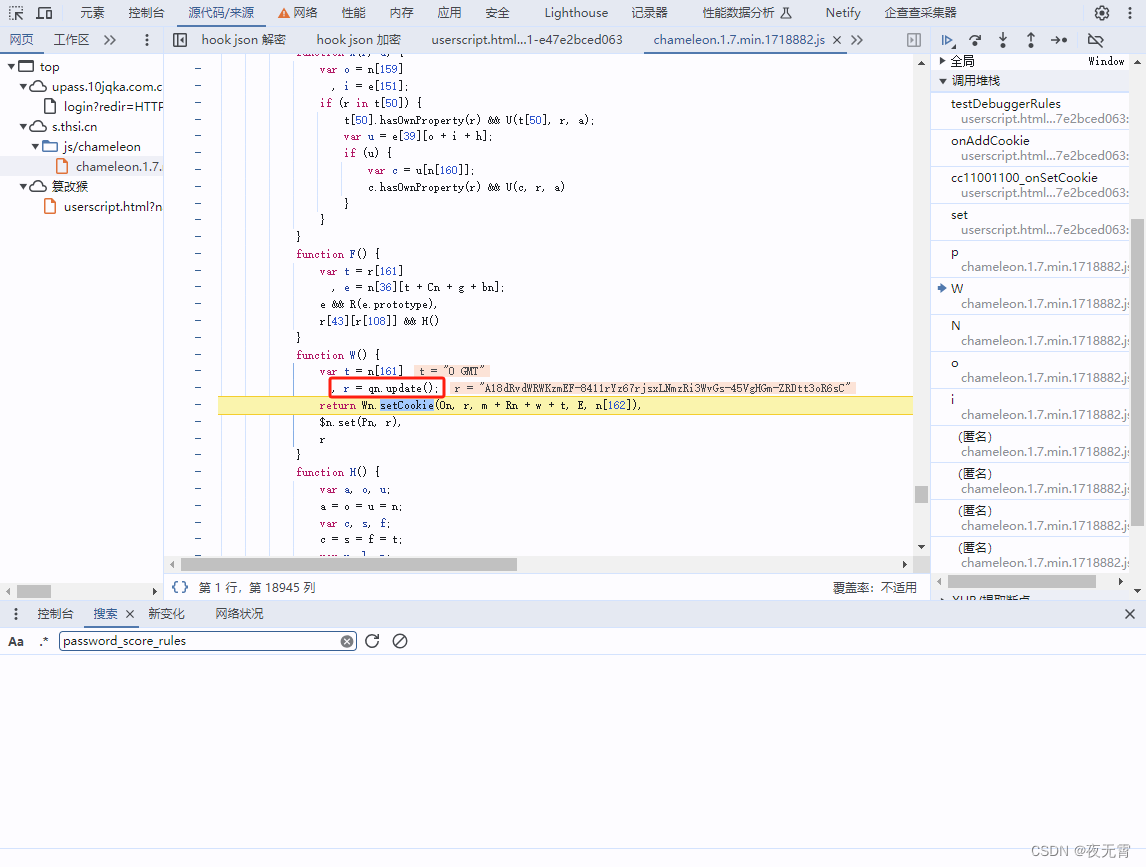
2、Cookie
首先将cookie清除,然后运行hook脚本,刷新页面,接着跟栈,就可以发现cookie的生成位置了。
三、扣代码大致思路
1、第一步
先扣加密参数的代码,加密参数的代码只需要将thsencrypt加密对象所在文件的代码全部copy出来,然后补一下环境就可以了,其他代码缺啥补啥就行了。
2、第二步
扣cookie生成的代码,两种方案。
第一种方案,将cookie生成位置整个文件的代码copy出来,然后补环境,将cookie生成方法导出到全局即可,代码量1300行左右。
第二种方案,进入到cookie生成的方法中,一步一步的把用到的方法扣出来,cookie生成的方法中会有一些浏览器指纹检测,可以写死,也可以弄成随机的。指纹检测写死的话,代码量100行左右。
四、请求大致思路
1、第一步(可省略)
首先需要请求pwdRangeCalcRegular.json接口,获取到密码评分规则,然后通过网站的方法得到密码的分数。因为此接口返回的密码评分规则是不变的,所以可以直接复制下来用,省去这一个请求。
2、第二步
生成cookie,同时将其放入请求头中。
3、第三步
请求getGS接口,将响应结果保存以及请求时携带的crnd参数。
4、第四步(可省略)
从getGS的响应中提取dsk和请求时携带的crnd参数,发送第一次dologinreturnjson2。此次请求肯定返回的是失败的响应,因为还没有进行滑块验证。
5、第五步
请求getPreHandle接口,获取滑块验证码的背景图和滑块图,同时将响应中的sign参数保存。
6、第六步
识别滑块位置(注意:x轴和y轴的距离均需要),然后同时携带getPreHandle响应中的sign参数,发送getTicket请求,此请求验证成功后会返回ticket参数。
7、第七步
至此,dologinreturnjson2接口所需要的所有参数均已拿到,就可以发送请求进行登录了。