一、场景描述
以统计号码的流量案例为基础,进行开发。
流量统计结果
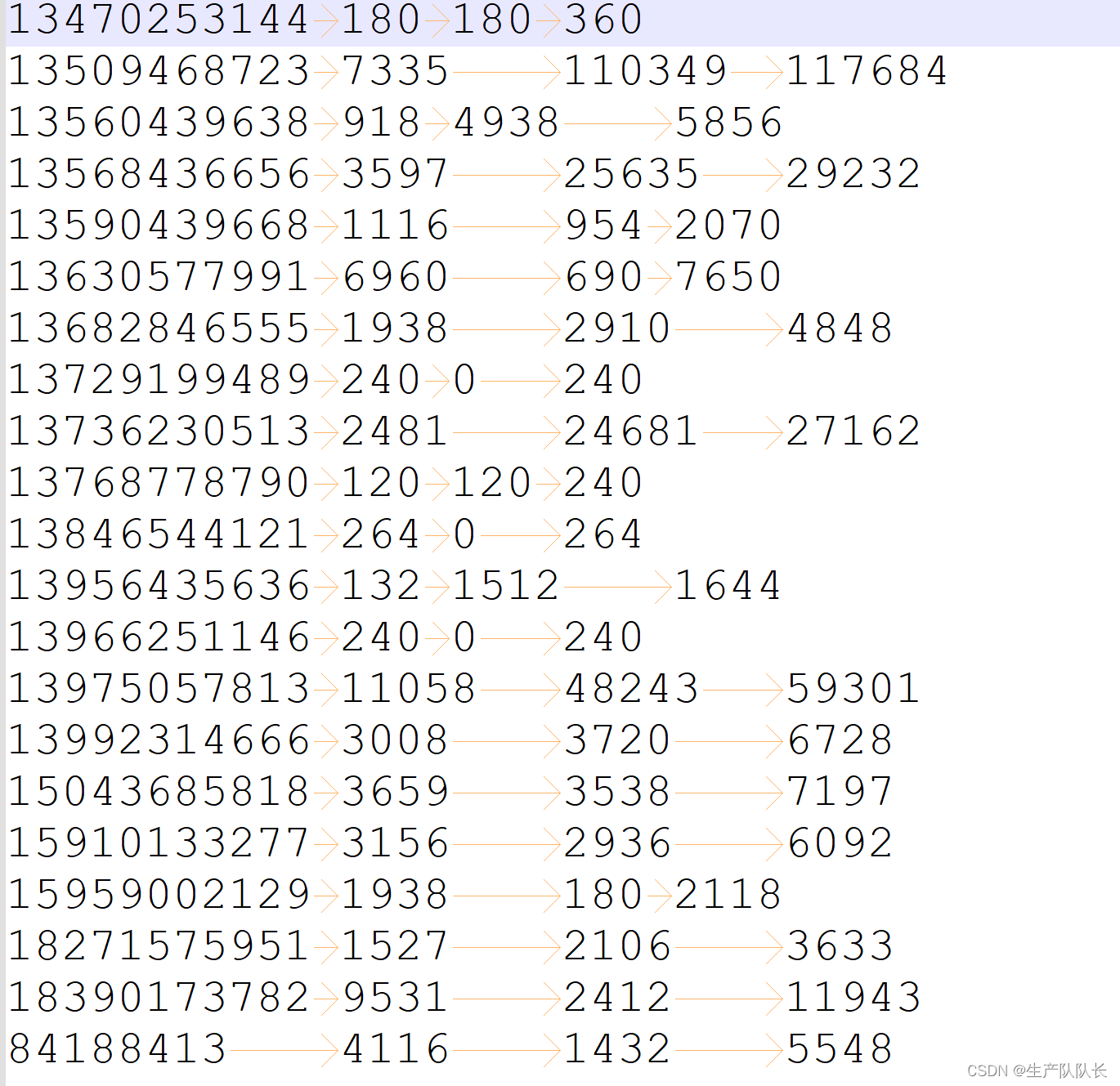
我们现在要对这个数据的总流量进行自定义排序。
二、代码实现
我们要对总流量进行排序,就是对FlowBean中的sumFlow字段进行排序。
所以,我们需要让FlowBean实现WritableComparable接口,并重写compareTo方法。
另外,我们知道,排序是在Shuffle过程进行的,且是在环形缓冲区进行的排序
此处的排序,采用快速排序算法,针对key的索引进行排序,按照字典顺序进行排序。
所以,我们需要在mapper程序中,把FlowBean设置成key,这样,Shuffle阶段,会调用FlowBean的compareTo方法,进行排序。
FlowBean.java
java
package com.atguigu.mapreduce.writableComparable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 1、定义类实现writable接口
* 2、重写序列化和反序列化方法
* 3、重写空参构造
* 4、toString方法
*/
public class FlowBean implements WritableComparable<FlowBean> {
private long upFlow; // 上行流量
private long downFlow; // 下行流量
private long sumFlow; // 总流量
// 空参构造
public FlowBean() {
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
@Override
public int compareTo(FlowBean o) {
// 总流量的倒序排序
if (this.sumFlow > o.sumFlow) {
return -1;
} else if (this.sumFlow < o.sumFlow) {
return 1;
} else {
// 按照上行流量的正序排
if (this.upFlow > o.upFlow) {
return 1;
} else if (this.upFlow < o.upFlow) {
return -1;
} else {
return 0;
}
}
}
}FlowMapper.java
java
package com.atguigu.mapreduce.writableComparable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
private FlowBean outK = new FlowBean();
private Text outV = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取一行
String line = value.toString();
// 切割
String[] split = line.split("\t");
// 封装
outV.set(split[0]);
outK.setUpFlow(Long.parseLong(split[1]));
outK.setDownFlow(Long.parseLong(split[2]));
outK.setSumFlow();
// 写出
context.write(outK, outV);
}
}三、测试
可以看出,实现了排序效果。

同时,我们可以在这个基础上,实现分区
这样,就实现了分区排序。