一、引言
在数字时代的浪潮中,我们被由语言和视觉等多种模态构成的信息海洋所包围。人类大脑以其卓越的多模态上下文理解能力,在日常任务中游刃有余。然而,在人工智能领域,如何将这种能力赋予机器,尤其是如何在语言模型的成功基础上扩展到视觉领域,成为了当前研究的热点和难点。

二、多模态上下文理解的局限性
在语言模型领域,GPT系列的崛起无疑为我们带来了诸多启示。这些模型通过大量的文本数据训练,不仅能够在上下文中解决各种语言任务,更能在推理阶段,通过提供几个例子,就完成未见过的任务。这种能力让我们不禁思考:如果图像也能"说话",如果机器能够理解图像的"语言",那么视觉领域的未来将如何被改写?
自然而然就有了"图像说图像的语言"的观点,将图像作为接口,统一了各种视觉任务。通过给定几个例子,模型能够较好地完成其他视觉任务,如图像分割等。然而,正如王鑫龙所指出的,当前基于纯图像的上下文学习仍存在着局限性。首先,现有的数据集无法完全涵盖视觉任务的多样性 。在真实世界中,视觉信息千变万化,而数据集往往只能涵盖其中的一部分。这使得模型在面对未知任务时,难以做出准确的判断。其次,与语言相比,图像中的上下文关系较为模糊 。语言中的词语和句子有着明确的语法和语义结构,而图像中的元素则往往缺乏这种明确的关联。这使得模型在理解图像时,需要付出更多的努力。

三、多模态训练的探索
为了克服这些局限性,尝试自回归地在多模态序列中预测"下一个"Token,无论是图像中的下一个Patch,视频中的下一帧,还是文本中的下一个词例token。这种统一的生成式多模态训练方式,不仅提高了模型的泛化能力,还使得模型能够更好地理解多模态上下文之间的关系。
然而,生成式多模态模型研究目前仍面临着三个最关键的问题:数据、编码器以及预训练。
- 在数据方面,我们需要探讨什么样的数据能够满足下一代多模态任务的需求。这不仅要关注数据的形式,还要关注数据的内容。
- 在编码器方面,我们需要了解哪些编码方式能够满足生成、理解以及统一多模态任务的需求。这包括分词器和语义编码器在内的各种编码方式。
- 在预训练方面,我们需要找到一种能够同时利用多模态数据的方法,使得模型能够在训练过程中学习到更多的知识和信息。
试想一下人类观看视频时,我们接受的是交错的视觉和文本数据,这些数据之间具有优秀的上下文相关性。受此启发,智源团队使用交错的文本-视频数据(interleaved data)。通过将描述性视频中的文字与视觉图片对应起来,并在时间戳上对齐二者 。这种方法不仅提高了模型对多模态数据的理解能力,还使得模型能够更好地学习到多模态数据之间的关联关系。

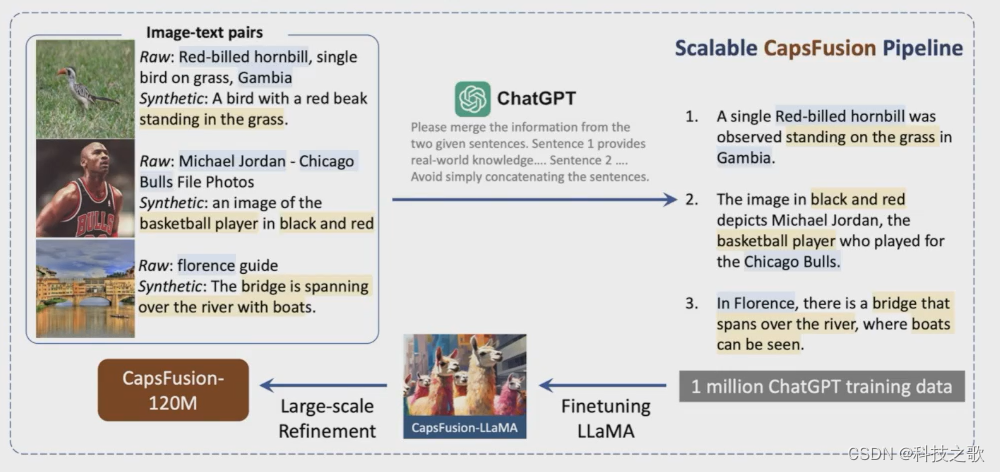
为了保证数据质量,智源团队使用了CapsFusion技术。这项技术利用大模型按照指令有机地整合原始描述和合成描述,从结构有缺陷的原始描述中提取世界知识,同时与结构化但句法简化的合成字幕合并 。通过这种方式,智源团队创建了一个全面而精细的「图像-文本」数据集CapsFusion-120M。这个数据集不仅包含了大量的图像和文本数据,还通过精细的对齐和标注,使得模型能够更好地学习到多模态数据之间的关联关系。
在编码器方面,要考虑编码器能达到什么规模、是否可以不使用编码器以及编码器是否可以是稀疏的等问题。受到Segment Anything项目的启发,智源团队尝试稀疏且支持提示(prompting)的分词器。分词器可以根据需要对图像进行分词,实现按需输出。此外,还用patch作为视觉单元的可行性,并发现去掉编码器在某些情况下可能带来新的思路。然而,这种方法也存在训练不稳定、性能较差等问题。
四、多模态模型的挑战
在构建统一多模态模型时,我们仍然会遇到"不可能三角"的挑战:紧凑-无损-离散,三者无法同时满足。
- 紧凑性意味着用较少的token来表达图像或视频;
- 无损性意味着能够完美重建图像或视频;
- 离散性则意味着使用离散的token表示。
目前我们只能同时满足其中的两个,实现所有三个目标仍然有技术瓶颈。这需要我们在未来的研究中继续探索和创新。总的来说,多模态上下文理解是一个充满挑战和机遇的研究方向。