- 这是篇LLM论文,用decoder-like的LLM去提取embedding
- 文章认为,decoder-like的LLM在text embedding task表现不优的一大原因就是其casual attention mechanism,其实就是mask的问题。所以只要对现有的decoder-only LLM进行如下三步改进,就将pre-trained decoder-only LLM into a universal text encoder:
- 双向注意力,就是取消掉MSA的mask,用全1的mask 矩阵
- masked next token prediction (MNTP),就是用类似BERT的预训练方式,给一个序列,挖掉中间某几个单词,让模型根据剩下的单词去预测这几个单词,但是些许不同的是,我要预测第i个单词并非使用第i个token的输出来算loss,而是用它前一个token的输出来算loss,也就是i-1.这就是next token。但是我感到奇怪的是,这样不是把模型变成encoder-like 了吗,那模型还能保持原来的性能吗。。
- unsupervised contrastive learning。即使用了上述两部,模型离embedding模型还差一点,因为模型还是在学word-level的特征,相比encoding模型在next sentence prediction任务上学sentence-level的特征,decoder模型缺乏这样的训练。用的是这样的训练方式,就是在random drop out掉一个句子的一些单词,同一个句子,drop out 两次,forward 两次,得到两个embedding,然后这两个embedding 作为positive sample算相似度,不同句子之间的作为negative sample算相似度。
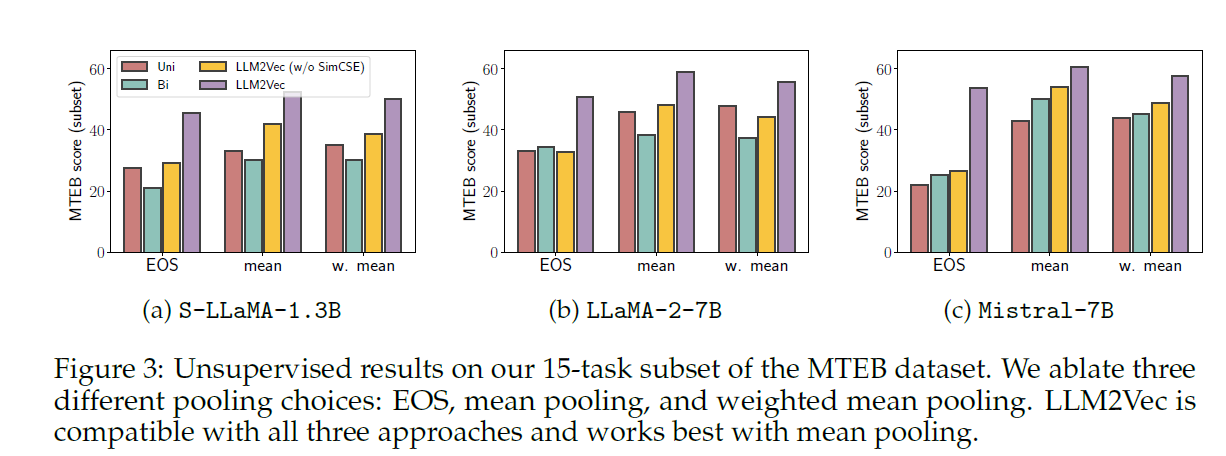
- sentence embedding 的获得方式文章做了消融试验,一种是EOS pooling,一种是mean pooling,一种是weighted mean pooling,mean pooling效果比较好。weighted mean pooling用的是GPT sentence embeddings for semantic search这篇文章中的方法,EOS pooling就是直接用最后一个token作为从这个句子提取的embedding。也就是说,如果不特别设计提取embedding的方法,naive的使用EOS的token和对token进行average pooling这两种方法中,average pooling效果更好