- chatGPT概述
ChatGPT 是一个基于 GPT-3 构建的对话生成模型,它由 OpenAI 开发并提供。ChatGPT 的原理基于大规模的预训练模型 GPT-3,该模型在庞大的文本数据集上进行了训练,从而具有强大的自然语言理解和生成能力。
ChatGPT 的工作原理可以简单概括如下:
- 预训练:ChatGPT 使用了 GPT-3 的架构,通过在海量文本数据上进行自监督学习,学习了丰富的语言知识和语境。
- 微调:OpenAI 对预训练的模型进行微调,以适应对话生成的任务。这意味着模型会在对话数据集上进行进一步的训练,以提高在生成对话方面的表现。
- 推理生成:一旦模型经过微调,它就可以接收用户输入并生成相应的回复。ChatGPT 会根据输入文本的上下文和语境生成连贯的回复。
ChatGPT 的成功之处在于其强大的文本生成能力和对话连贯性。它能够理解语境、保持话题连贯,并生成具有逻辑性和合理性的回复。这使得 ChatGPT 能够广泛应用于聊天机器人、客服系统、智能助手等领域,为用户提供自然流畅的对话体验。
需要注意的是,ChatGPT 仍然存在一些局限性,例如可能会出现语义不准确、回复不连贯等问题。不过,随着模型的不断优化和更新,这些问题会逐渐得到改善,使得 ChatGPT 在对话生成领域的表现越来越出色。
- GPT-3的特点与架构
GPT-3(Generative Pre-trained Transformer 3)是由 OpenAI 开发的一种基于 Transformer 架构的预训练语言模型,是目前公认的规模最大的通用预训练模型之一。GPT-3 在大规模文本数据集上进行了训练,具有强大的自然语言理解和生成能力。以下是关于 GPT-3 的详细介绍以及其架构:
GPT-3 的特点:
- 规模大:GPT-3 是迄今为止规模最大的预训练语言模型,拥有数万亿个参数。
- 零样本学习:GPT-3 具有零样本学习的能力,即可以在未见过的任务上进行推理和生成。
- 通用性:GPT-3 是一种通用的预训练模型,可以适用于各种自然语言处理任务。
GPT-3 的架构:
GPT-3 的架构基于 Transformer 模型,主要包括以下组件:
- 输入嵌入(Input Embedding):将输入文本转换为密集向量表示。
- Transformer 编码器(Transformer Encoder):由多个 Transformer 编码层组成,用于对输入序列进行编码。
- 位置编码(Positional Encoding):用于为输入序列中的每个单词位置分配唯一的编码。
- 自注意力机制(Self-Attention Mechanism):用于模型在处理输入序列时关注不同单词之间的交互。
- 前馈神经网络(Feed-Forward Neural Network):用于在每个 Transformer 编码层中对自注意力表示进行非线性转换。
- 残差连接(Residual Connections)和层归一化(Layer Normalization):用于加速训练和提高模型性能。
- 输出层(Output Layer):对编码后的表示进行解码,生成最终的输出序列。
GPT-3 的工作流程:
- 输入编码:将输入文本经过嵌入层和位置编码层转换为向量表示。
- Transformer 编码:通过多个 Transformer 编码层对输入序列进行编码,提取上下文信息。
- 解码和生成:使用输出层对编码后的表示进行解码,生成模型的输出序列。
- 反向传播:通过反向传播算法优化模型参数,以减小生成序列与目标序列之间的差距。
GPT-3 的强大之处在于其巨大的规模、通用的预训练能力和出色的生成效果,使其成为自然语言处理领域的重要里程碑之一。其架构的灵活性和效率使得 GPT-3 能够适用于多种自然语言处理任务,并取得令人瞩目的成果。
- transformer模型
Transformer 模型是由 Vaswani 等人在论文"Attention is All You Need"中提出的一种基于自注意力机制的深度学习模型,用于处理序列到序列(sequence-to-sequence)的任务,如机器翻译、文本摘要等。Transformer 模型的创新之处在于完全抛弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),而是仅使用注意力机制来捕捉输入序列中的依赖关系。
Transformer 模型的主要组成部分包括:
- 编码器(Encoder):用于将输入序列进行编码,捕捉输入序列中的信息。
- 解码器(Decoder):用于生成输出序列,同时结合编码器的输出和自身的状态进行上下文理解和生成。
- 自注意力机制(Self-Attention):用于计算序列中不同位置之间的依赖关系。
- 位置编码(Positional Encoding):用于为输入序列中的每个位置分配一个位置信息,使得模型能够学习序列的顺序信息。
下面是一个简化的 Transformer 模型的实现示例,使用 Python 和 PyTorch:
python
import torch
import torch.nn as nn
class Transformer(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers, num_heads, dropout):
super(Transformer, self).__init__()
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(
d_model=input_dim,
nhead=num_heads,
dim_feedforward=hidden_dim,
dropout=dropout,
),
num_layers=num_layers,
)
self.decoder = nn.TransformerDecoder(
nn.TransformerDecoderLayer(
d_model=input_dim,
nhead=num_heads,
dim_feedforward=hidden_dim,
dropout=dropout,
),
num_layers=num_layers,
)
def forward(self, src, tgt):
src_mask = None
tgt_mask = self.generate_square_subsequent_mask(tgt.size(0))
encoder_output = self.encoder(src, src_mask)
decoder_output = self.decoder(tgt, encoder_output, tgt_mask)
return decoder_output
def generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask在这个示例中,我们定义了一个简单的 Transformer 类,其中包含一个编码器和一个解码器。模型的前向传播方法实现了编码器和解码器的运算流程,同时生成了解码器需要的掩码(mask)来防止未来信息泄露。这里使用了 PyTorch 的内置 TransformerEncoder 和 TransformerDecoder 模块来构建模型。
这只是一个简单的示例,实际的 Transformer 模型可能会更加复杂,并可能包含更多的组件和特性。希望这个示例能帮助您更好地理解 Transformer 模型的实现机制。
- 自注意力机制
自注意力机制(Self-Attention Mechanism)是 Transformer 模型的核心组件之一,被广泛应用于自然语言处理任务中,如文本生成、翻译和问答等。自注意力机制能够在输入序列内部进行注意力计算,从而捕捉序列中不同位置之间的关联性,提高模型对长距离依赖的建模能力。以下是自注意力机制的详细介绍:
1. 基本概念:
- Query(查询) 、Key(键) 和 Value(值) 是自注意力机制的三个要素。
- 给定一个输入序列,通过查询、键和值的线性变换,得到对应的查询向量、键向量和值向量。
- 通过计算查询向量和键向量之间的相似度得到注意力分数,再将注意力分数与值向量加权求和,得到最终的输出。
2. 自注意力计算:
- 注意力分数计算:通过查询向量和键向量的点积,再经过缩放和 Softmax 操作,得到注意力分数。
- 加权求和:将注意力分数作为权重,对值向量进行加权求和,得到自注意力机制的输出。
3. 多头注意力(Multi-Head Attention):
- 为了增强模型的表达能力,Transformer 中引入了多头注意力机制。
- 将输入进行多次线性变换,得到多组查询、键和值,分别进行注意力计算,最后将多组输出拼接并线性变换,得到最终的多头注意力输出。
4. 自注意力在 Transformer 中的应用:
- 在 Transformer 的编码器和解码器中都使用了自注意力机制。
- 编码器中的自注意力用于捕捉输入序列内部的关系,提取上下文信息。
- 解码器中的自注意力用于捕捉输出序列内部的关系,同时结合编码器的输出进行上下文理解和生成。
自注意力机制作为 Transformer 模型的核心之一,在自然语言处理任务中展现了良好的表现,能够有效地处理长距离依赖关系,提高模型的性能和泛化能力。通过合理应用自注意力机制,可以实现更加强大和灵活的模型,帮助解决各种复杂的自然语言处理问题。
- PyTorch的编码解码器
PyTorch 提供了内置的 TransformerEncoder 和 TransformerDecoder 模块,用于构建 Transformer 模型中的编码器和解码器部分。这两个模块是构建 Transformer 模型的重要组件,它们封装了自注意力层、前馈神经网络等操作,简化了 Transformer 模型的实现过程。下面我们将详细介绍 PyTorch 中的这两个模块:
TransformerEncoder:
torch.nn.TransformerEncoder类用于构建 Transformer 模型中的编码器部分。- 构造函数参数包括
encoder_layer、num_layers和norm。 encoder_layer参数指定了编码器每层的结构,通常使用nn.TransformerEncoderLayer。num_layers参数指定了编码器中的层数。norm参数指定了归一化方法,通常使用nn.LayerNorm。
TransformerDecoder:
torch.nn.TransformerDecoder类用于构建 Transformer 模型中的解码器部分。- 构造函数参数包括
decoder_layer、num_layers和norm。 decoder_layer参数指定了解码器每层的结构,通常使用nn.TransformerDecoderLayer。num_layers参数指定了解码器中的层数。norm参数指定了归一化方法,通常使用nn.LayerNorm。
TransformerEncoderLayer:
torch.nn.TransformerEncoderLayer类定义了 Transformer 编码器中的一个层。- 构造函数参数包括
d_model、nhead、dim_feedforward、dropout等。 d_model指定了模型的输入和输出维度。nhead指定了注意力头的数量。dim_feedforward指定了前馈神经网络的隐藏层维度。dropout指定了 Dropout 概率。
TransformerDecoderLayer:
torch.nn.TransformerDecoderLayer类定义了 Transformer 解码器中的一个层。- 构造函数参数与
TransformerEncoderLayer类似,包括d_model、nhead、dim_feedforward、dropout等。
这些 PyTorch 内置的模块使得构建 Transformer 模型变得更加简单和高效,开发者可以方便地使用这些模块来构建自己的 Transformer 模型,而不必从头实现所有细节。通过灵活地调整参数和层数,可以构建不同规模和性能的 Transformer 模型,适用于各种自然语言处理任务。
- 应用与结构图示
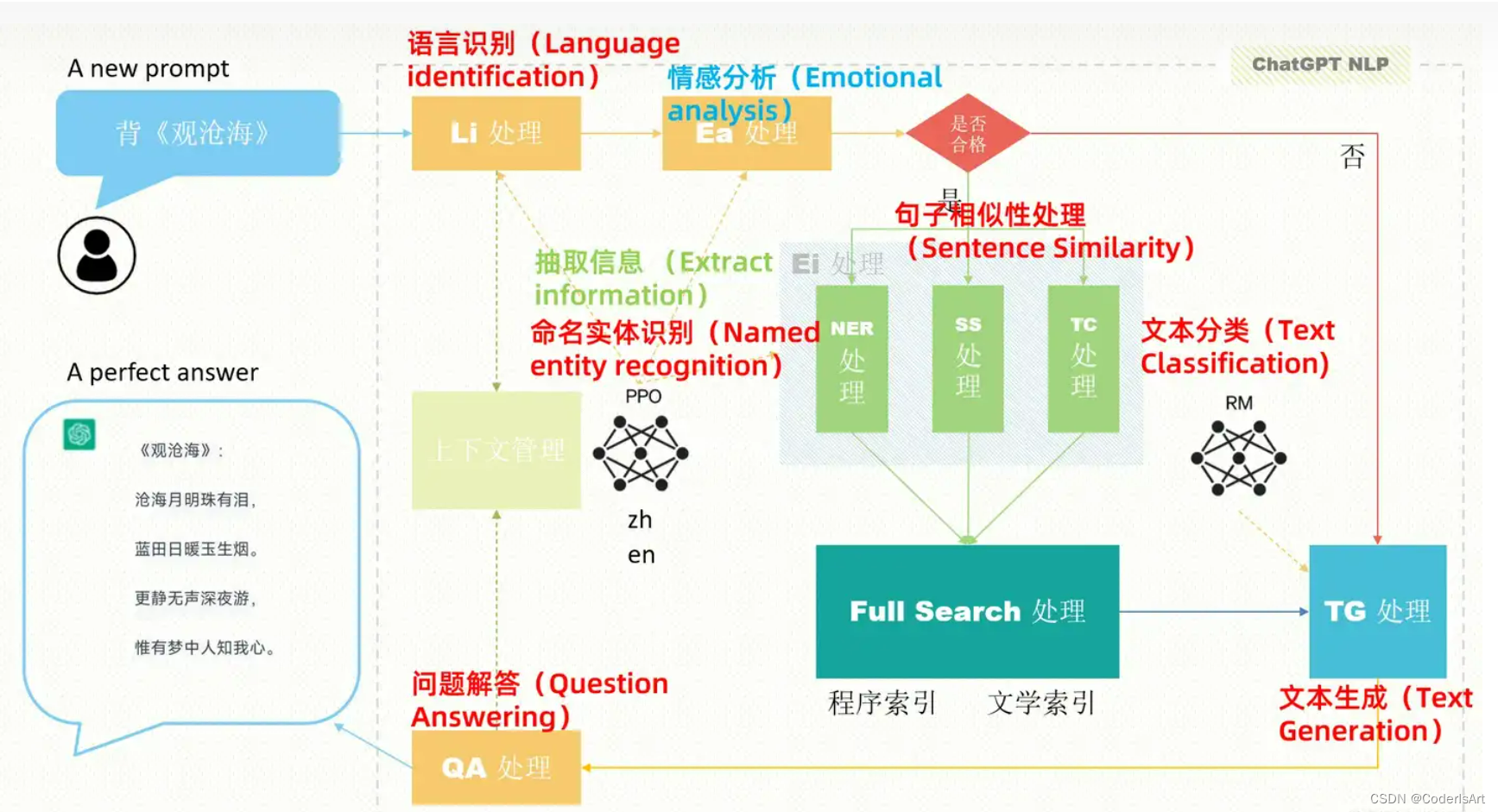
- 参考链接:
一张图说明chatGPT工作原理 - 知乎 (zhihu.com)