本文翻译整理自:https://www.selenium.dev/documentation/webdriver/elements/
文章目录
识别和使用DOM中的元素对象。
大多数人的大多数Selenium代码都涉及使用Web元素。
一、文件上传
因为Selenium无法与文件上传对话框交互,所以它提供了一种方法 在不打开对话框的情况下上传文件。
如果元素是file类型的input元素, 您可以使用send key方法将完整路径发送到将要上传的文件。
py
file_input = driver.find_element(By.CSS_SELECTOR, "input[type='file']")
file_input.send_keys(upload_file)
driver.find_element(By.ID, "file-submit").click()二、定位策略
标识DOM中一个或多个特定元素的方法。
定位器是一种识别页面上元素的方法。
它是传递给 查找元素方法。
查看我们的鼓励测试实践以获取有关 定位器,包括何时和何时使用 为什么要将定位器与查找方法分开声明。
1、传统定位器
Selenium在WebDriver中支持以下8种传统定位策略:
| 定位器 | 描述 |
|---|---|
| 类名 | 定位其类名包含搜索值的元素(不允许使用复合类名) |
| css选择器 | 定位与CSS选择器 |
| id | 匹配的元素定位其ID属性与搜索值匹配的元素 |
| name | 定位其NAME属性与搜索值匹配的元素 |
| 链接文本 | 定位可见文本与搜索值匹配的锚元素 |
| 部分链接文本 | 定位可见文本包含搜索值的锚元素。 如果多个元素匹配,则只选择第一个。 |
| 标签名称 | 定位标签名称与搜索值匹配的元素 |
| xpath | 定位与XPath表达式匹配的元素 |
2、创建定位器
要使用Selenium处理Web元素,我们需要首先在网页上定位它。
Selenium为我们提供了上述方法,我们可以使用这些方法在页面上定位元素。
为了理解和创建定位器,我们将使用以下超文本标记语言片段。
html
<html>
<body>
<style>
.information {
background-color: white;
color: black;
padding: 10px;
}
</style>
<h2>Contact Selenium</h2>
<form action="/action_page.php">
<input type="radio" name="gender" value="m" />Male
<input type="radio" name="gender" value="f" />Female <br>
<br>
<label for="fname">First name:</label><br>
<input class="information" type="text" id="fname" name="fname" value="Jane"><br><br>
<label for="lname">Last name:</label><br>
<input class="information" type="text" id="lname" name="lname" value="Doe"><br><br>
<label for="newsletter">Newsletter:</label>
<input type="checkbox" name="newsletter" value="1" /><br><br>
<input type="submit" value="Submit">
</form>
<p>To know more about Selenium, visit the official page
<a href ="www.selenium.dev">Selenium Official Page</a>
</p>
</body>
</html>3、类名
超文本标记语言页面web元素可以有属性类。
我们可以在上面显示的超文本标记语言片段中看到一个示例。
我们可以使用Selenium中可用的类名定位器来识别这些元素。
python
driver = webdriver.Chrome()
driver.find_element(By.CLASS_NAME, "information")4、CSS选择器
CSS是用于设置超文本标记语言页面样式的语言。
我们可以使用css选择器定位器策略来识别页面上的元素。
如果元素有一个id,我们将定位器创建为css=#id。
否则我们遵循的格式是css=属性=值。
让我们看看上面超文本标记语言片段的示例。
我们将使用css为名字文本框创建定位器。
python
driver = webdriver.Chrome()
driver.find_element(By.CSS_SELECTOR, "#fname")5、id
我们可以使用网页中元素的ID属性来定位它。
通常,网页上每个元素的ID属性应该是唯一的。
我们将使用它来识别姓氏字段。
python
driver = webdriver.Chrome()
driver.find_element(By.ID, "lname")6、NAME
我们可以使用网页中元素的NAME属性来定位它。
通常,NAME属性对于网页上的每个元素都应该是唯一的。
我们将使用它来识别时事通讯复选框。
python
driver = webdriver.Chrome()
driver.find_element(By.NAME, "newsletter")7、链接文本
如果我们要定位的元素是一个链接,我们可以使用链接文本定位器在网页上识别它。
链接文本是链接显示的文本。
在共享的超文本标记语言片段中,我们有一个可用的链接,让我们看看我们将如何定位它。
python
driver = webdriver.Chrome()
driver.find_element(By.LINK_TEXT, "Selenium Official Page")8、部分链接文本
如果我们要定位的元素是一个链接,我们可以使用部分链接文本定位器在网页上识别它。
链接文本是链接显示的文本。
我们可以将部分文本作为值传递。
在共享的超文本标记语言片段中,我们有一个可用的链接,让我们看看如何定位它。
python
driver = webdriver.Chrome()
driver.find_element(By.PARTIAL_LINK_TEXT, "Official Page")9、标签名称
我们可以使用超文本标记语言TAG本身作为定位器来识别页面上的web元素。
从上面分享的超文本标记语言片段中,让我们使用其html标记"a"来识别链接。
python
driver = webdriver.Chrome()
driver.find_element(By.TAG_NAME, "a")10、xpath
超文本标记语言文档可以被视为XML文档,然后我们可以使用xpath,它将是到达感兴趣元素的路径来定位元素。
XPath可以是绝对xpath,它是从文档的根目录创建的。
示例- /html/form/input1。
这将返回男性单选按钮。
或者xpath可以是相对的。
示例-//输入@name='fname'。
这将返回第一个名称输入框。
让我们使用xpath为女性单选按钮创建定位器。
python
driver = webdriver.Chrome()
driver.find_element(By.XPATH, "//input[@value='f']")11、相对定位器
Selenium 4引入了相对定位器(以前称为友好定位器)。
当不容易为所需元素构建定位器,但很容易在空间上描述元素与具有易于构建的定位器的元素之间的关系时,这些定位器很有帮助。
它是如何工作的
Selenium使用JavaScript函数 getBoundingClientRect() 确定页面上元素的大小和位置,并可以使用此信息来定位相邻元素。
相对定位器方法可以作为原点的参数,要么是先前定位的元素引用,或者另一个定位器。
在这些示例中,我们将只使用定位器,但是您可以将最终方法中的定位器与元素对象交换,它的工作方式相同。
让我们考虑下面的示例来理解相对定位器。
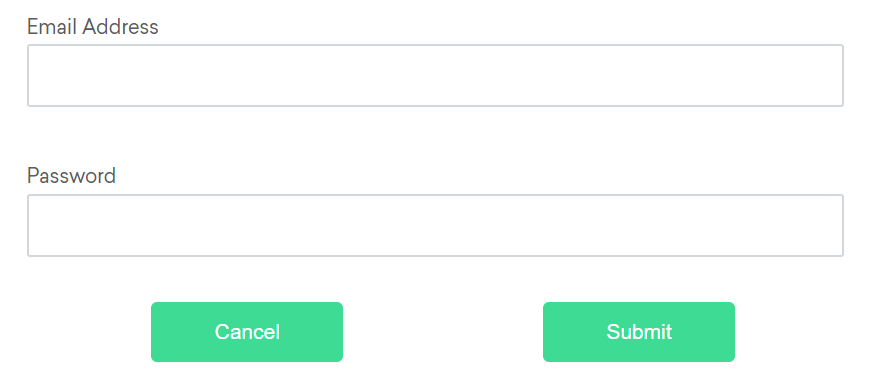
可用相对定位器
以上
如果由于某种原因电子邮件文本字段元素不容易识别,但密码文本字段元素是,我们可以使用它是"密码元素"上方的"输入"元素这一事实来定位文本字段元素。
python
email_locator = locate_with(By.TAG_NAME, "input").above({By.ID: "password"})下面
如果密码文本字段元素由于某种原因不容易识别,但电子邮件文本字段元素是,我们可以使用它是电子邮件元素"下方"的"输入"元素这一事实来定位文本字段元素。
python
password_locator = locate_with(By.TAG_NAME, "input").below({By.ID: "email"})左边的
如果由于某种原因,取消按钮不容易识别,但提交按钮元素是,我们可以使用它是提交元素"左侧"的"按钮"元素这一事实来定位取消按钮元素。
python
cancel_locator = locate_with(By.TAG_NAME, "button").to_left_of({By.ID: "submit"})右边
如果提交按钮由于某种原因不容易识别,但取消按钮元素是,我们可以使用它是取消元素"右侧"的"按钮"元素这一事实来定位提交按钮元素。
python
submit_locator = locate_with(By.TAG_NAME, "button").to_right_of({By.ID: "cancel"})临近
如果相对定位不明显,或者它根据窗口大小而变化,您可以使用近方法 确定距离提供的定位器最多50px的元素。
一个很好的用例是使用没有易于构建的定位器的表单元素, 但其关联的输入标签元素。
python
email_locator = locate_with(By.TAG_NAME, "input").near({By.ID: "lbl-email"})链式相对定位器
如果需要,您还可以使用链式定位器。
有时,元素最容易被识别为既在一个元素的上方/下方,又在另一个元素的右侧/左侧。
python
submit_locator = locate_with(By.TAG_NAME, "button").below({By.ID: "email"}).to_right_of({By.ID: "cancel"})三、查找Web元素
根据提供的定位器值定位元素。
使用Selenium最基本的方面之一是获取要使用的元素引用。
Selenium提供了许多内置定位器策略来唯一标识元素。
有许多方法可以在非常高级的场景中使用定位器。
为了本留档的目的, 让我们考虑这个超文本标记语言片段:
html
<ol id="vegetables">
<li class="potatoes">...
<li class="onions">...
<li class="tomatoes"><span>Tomato is a Vegetable</span>...
</ol>
<ul id="fruits">
<li class="bananas">...
<li class="apples">...
<li class="tomatoes"><span>Tomato is a Fruit</span>...
</ul>1、第一匹配元素
许多定位器将匹配页面上的多个元素。
单数查找元素方法将返回对在给定上下文中找到的第一个元素的引用。
评估整个DOM
当在驱动实例上调用find元素方法时,它会返回对DOM中与提供的定位器匹配的第一个元素的引用。
该值可以存储并用于未来的元素操作。
在我们上面的示例超文本标记语言中,有两个元素的类名为"西红柿",因此此方法将返回"蔬菜"列表中的元素。
python
vegetable = driver.find_element(By.CLASS_NAME, "tomatoes")评估DOM的子集
与其在整个DOM中找到唯一的定位器,不如将搜索范围缩小到另一个已定位元素的范围。
在上面的示例中,有两个元素的类名为"西红柿",获取第二个元素的引用更具挑战性。
一种解决方案是定位具有唯一属性的元素,该属性是所需元素的祖先,而不是不需要元素的祖先,然后在该对象上调用find元素:
python
fruits = driver.find_element(By.ID, "fruits")
fruit = fruits.find_element(By.CLASS_NAME,"tomatoes")WebDriver、WebElement和ShadowRoot类都实现了一个SearchContext接口,即 考虑基于角色的接口 。
基于角色的接口允许您确定特定的 驱动程序实现支持给定的功能。
这些接口定义明确,并尝试 坚持责任单一。
优化定位器
嵌套查找可能不是最有效的定位策略,因为它需要向浏览器发出两个单独的命令。
为了稍微提高性能,我们可以使用CSS或XPath在单个命令中查找此元素。
对于此示例,我们将使用CSS选择器:
python
fruit = driver.find_element(By.CSS_SELECTOR,"#fruits .tomatoes")2、所有匹配元素
有几个用例需要获取与定位器匹配的所有元素的引用,而不仅仅是第一个。
复数查找元素方法返回元素引用的集合。
如果没有匹配项,则返回一个空列表。
在这种情况下,对所有水果和蔬菜列表项的引用将在集合中返回。
python
plants = driver.find_elements(By.TAG_NAME, "li")获取元素
通常,您获得了一个元素集合,但希望使用特定元素,这意味着您需要遍历该集合并确定您想要的元素。
python
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
# Navigate to Url
driver.get("https://www.example.com")
# Get all the elements available with tag name 'p'
elements = driver.find_elements(By.TAG_NAME, 'p')
for e in elements:
print(e.text)3、从元素中查找元素
它用于在父元素的上下文中查找匹配的子WebElements列表。
为此,父WebElement与"findElements"链接以访问子元素
python
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.example.com")
# Get element with tag name 'div'
element = driver.find_element(By.TAG_NAME, 'div')
# Get all the elements available with tag name 'p'
elements = element.find_elements(By.TAG_NAME, 'p')
for e in elements:
print(e.text)4、获取活动元素
它用于跟踪(或)查找在当前浏览上下文中具有焦点的DOM元素。
python
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.google.com")
driver.find_element(By.CSS_SELECTOR, '[name="q"]').send_keys("webElement")
# Get attribute of current active element
attr = driver.switch_to.active_element.get_attribute("title")
print(attr)最后修改2023年9月12日:更新所有需要将代码移动到示例中的地方(b82db1dd56e)
四、与Web元素交互
用于操作表单控件的高级指令集。
一个元素上只有5个基本命令可以执行:
1、附加验证
这些方法旨在密切模仿用户的体验,因此, 与Actions API不同,它尝试执行两件事 在尝试指定的操作之前。
- 如果它确定元素在视口之外,它 将元素滚动到视图中,特别是 它将元素的底部与视口的底部对齐。
- 它确保元素是可交互的 在采取行动之前。
这可能意味着滚动不成功,或者 元素不会以其他方式显示。
确定一个元素是否显示在页面上太难了 直接在webdrive规范中定义, 因此,Selenium发送了一个带有JavaScript原子的执行命令,该命令检查是否会保留 不显示的元素。
如果它确定一个元素不在视口中,则不显示,不 keyboard-interactable,或不 pointer-interactable, 它返回一个元素不可交互错误。
2、点击
如果元素的中心由于某种原因被遮挡, Selenium将返回一个元素点击拦截错误。
python
# Navigate to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")
# Click on the element
driver.find_element(By.NAME, "color_input").click()3、发送钥匙
通常,这意味着元素是具有text类型的表单的输入元素或元素 带有content-editable属性。
如果它不可编辑, 返回一个无效的元素状态错误。
这是 WebDriver支持的可能击键。
python
# Navigate to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")
# Clear field to empty it from any previous data
driver.find_element(By.NAME, "email_input").clear()
# Enter Text
driver.find_element(By.NAME, "email_input").send_keys("admin@localhost.dev" )4、清除
该元素清除命令重置元素的内容。
通常, 这意味着元素是具有text类型的表单的输入元素或元素 带有content-editable属性。
如果不满足这些条件, 返回一个无效的元素状态错误。
python
# Navigate to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")
# Clear field to empty it from any previous data
driver.find_element(By.NAME, "email_input").clear() 5、提交
在Selenium 4中,这不再使用单独的端点和通过执行脚本实现的功能。
因此,建议不要使用此方法,而是单击适用的表单提交按钮。
五、有关网络元素的信息
你可以了解一个元素。
您可以查询有关特定元素的许多详细信息。
1、显示
此方法用于检查连接的元素是否 显示在网页上。
返回一个Boolean, 如果连接的元素显示在当前 浏览上下文else返回false。
此功能在中提到,但未定义 w3c规范由于 不可能涵盖所有潜在条件。
因此,Selenium不能指望驱动程序实施 此功能直接,现在依赖于 直接执行大型JavaScript函数。
这个函数对一个元素进行了许多近似值 树中的性质和关系返回一个值。
python
# Navigate to the url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")
# Get boolean value for is element display
is_email_visible = driver.find_element(By.NAME, "email_input").is_displayed()2、已启用
此方法用于检查网页上连接的元素是启用还是禁用。
返回一个布尔值,如果在当前浏览上下文中启用了连接的元素,则返回True,否则返回false。
python
# Navigate to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")
# Returns true if element is enabled else returns false
value = driver.find_element(By.NAME, 'button_input').is_enabled()3、被选中
此方法确定引用的元素是否被选中。
此方法广泛用于复选框、单选按钮、输入元素和选项元素。
Returns a boolean value, True if referenced element is selected in the current browsing context else returns false.
python
# Navigate to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")
# Returns true if element is checked else returns false
value = driver.find_element(By.NAME, "checkbox_input").is_selected()Copy
4、Tag Name
It is used to fetch the TagName of the referenced Element which has the focus in the current browsing context.
python
# Navigate to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")
# Returns TagName of the element
attr = driver.find_element(By.NAME, "email_input").tag_name
Copy
5、Size and Position
用于获取引用元素的尺寸和坐标。
获取的数据体包含以下详细信息:
- 元素左上角的X轴位置
- 元素左上角的y轴位置
- 元素的高度
- 元素的宽度
python
# Navigate to url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")
# Returns height, width, x and y coordinates referenced element
res = driver.find_element(By.NAME, "range_input").rect
6、获取CSS值
检索当前浏览上下文中元素的指定计算样式属性的值。
python
# Navigate to Url
driver.get('https://www.selenium.dev/selenium/web/colorPage.html')
# Retrieves the computed style property 'color' of linktext
cssValue = driver.find_element(By.ID, "namedColor").value_of_css_property('background-color') 7、文本内容
检索指定元素的呈现文本。
python
# Navigate to url
driver.get("https://www.selenium.dev/selenium/web/linked_image.html")
# Retrieves the text of the element
text = driver.find_element(By.ID, "justanotherlink").text8、获取属性或属性
获取与DOM属性关联的运行时值。
它返回与元素的DOM属性或属性关联的数据。
python
# Navigate to the url
driver.get("https://www.selenium.dev/selenium/web/inputs.html")
# Identify the email text box
email_txt = driver.find_element(By.NAME, "email_input")
# Fetch the value property associated with the textbox
value_info = email_txt.get_attribute("value")2024-06-17(一)