介绍
在数据处理领域,数据分析师在数据湖上运行其即席查询。数据湖充当分析和生产环境之间的接口,可防止下游查询影响上游数据引入管道。为了确保数据湖中的数据处理效率,选择合适的存储格式至关重要。
Vanilla数据湖解决方案构建在具有 Hive 元存储的云对象存储之上,其中数据文件以 Parquet 格式编写。尽管此设置针对可缩放的分析查询模式进行了优化,但由于两个原因,它难以处理对数据的频繁更新:
- Hive 表格式要求我们使用最新数据重写 Parquet 文件。例如,要更新 Hive 未分区表中的一条记录,我们需要读取所有数据、更新记录并写回整个数据集。
- 由于将数据组织为压缩的列格式(比行格式更复杂)的开销,因此编写 Parquet 文件的成本很高。
计划中的下游转换进一步加剧了这个问题。这些必要的步骤用于清理和处理数据以供使用,但会增加延迟,因为总延迟现在包括这些处理作业的组合计划间隔。
幸运的是,Hudi 格式的引入允许 Avro 和 Parquet 文件在读取时合并 (MOR) 表上共存,从而支持快速写入,这为拥有数据延迟最小的数据湖提供了可能性。提交时间线的概念进一步允许为数据提供原子性、一致性、隔离性和持久性 (ACID) 保证。
我们针对输入源的不同特性采用不同的配置集:
- 高吞吐量或低吞吐量。高吞吐源是指具有高活性源的源。例如,我们从每笔客户交易中生成的预订事件流。另一方面,低吞吐源是活性水平相对较低的源。例如,每晚发生的对账生成的事务事件。
- Kafka(无界)或关系数据库源(有界)。写出来源可以大致分为无界和有界。无界源通常与具体化为 Kafka 主题的交易事件相关,代表用户在与 Grab 超级应用交互时生成的事件。边界源通常是指关系数据库 (RDS) 源,其大小与预配的存储绑定。
以下部分将深入探讨每个源之间的差异以及我们针对它们优化的相应配置。
高吞吐源
对于具有高吞吐量的数据源,我们选择以 MOR 格式写入文件,因为以 Avro 格式写入文件允许快速写入以满足我们的延迟要求。
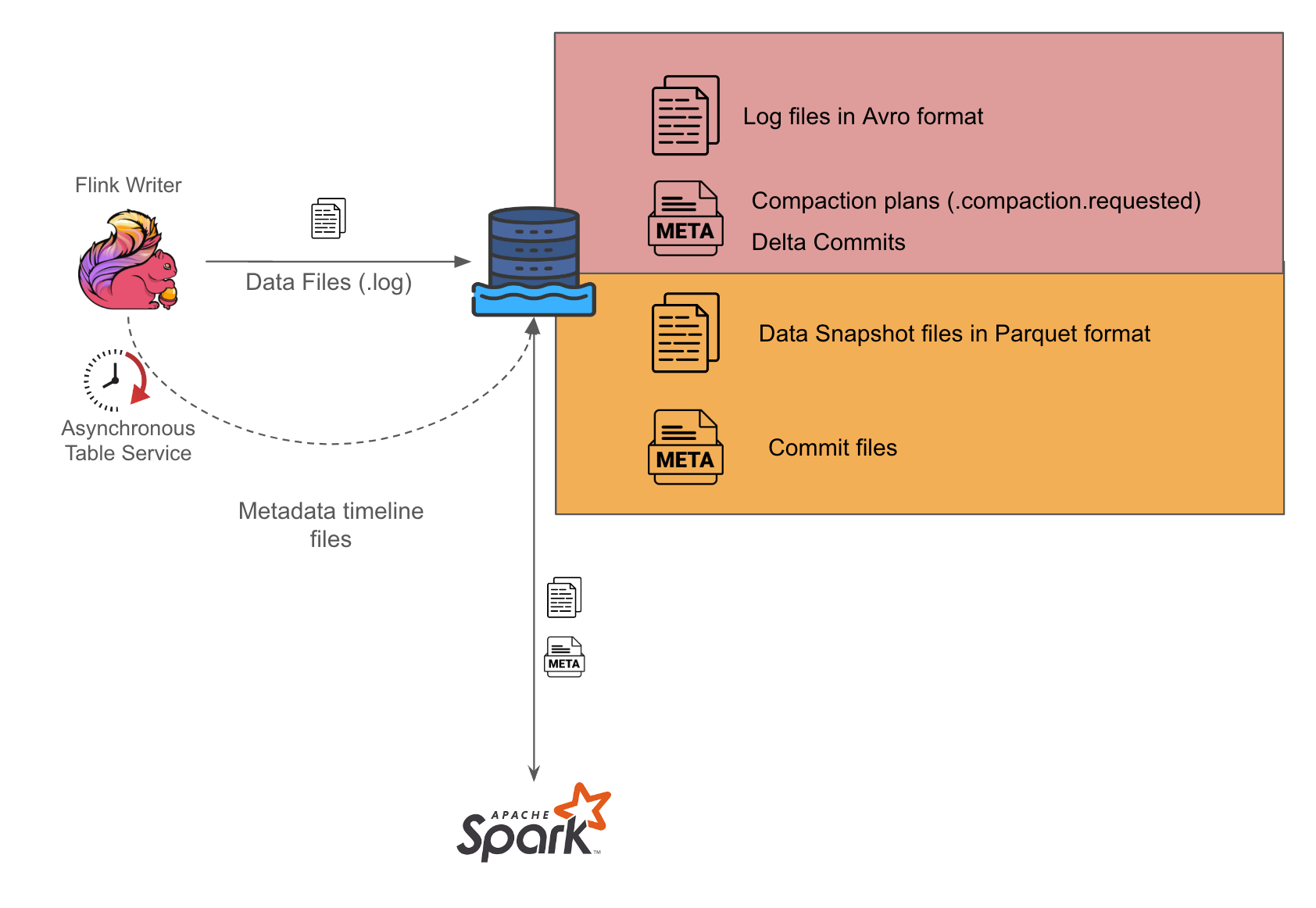
如图 1 所示,我们使用 Flink 执行流处理,并在设置中以 Avro 格式写出日志文件。然后,我们设置了一个单独的 Spark 写入端,该写入端在 Hudi 压缩过程中定期将 Avro 文件转换为 Parquet 格式。
我们通过在 Flink 写入端上启用异步服务,进一步简化了 Flink 写入端和 Spark 写入端之间的协调,以便它可以生成 Spark 写入端执行的压缩计划。在 Spark 作业运行期间,它会检查可用的压缩计划并对其执行操作,从而将编排写入的负担完全放在 Flink 写入端上。这种方法有助于最大程度地减少可能出现的潜在并发问题,因为将有一个参与者来编排关联的 Hudi 表服务。
低吞吐源
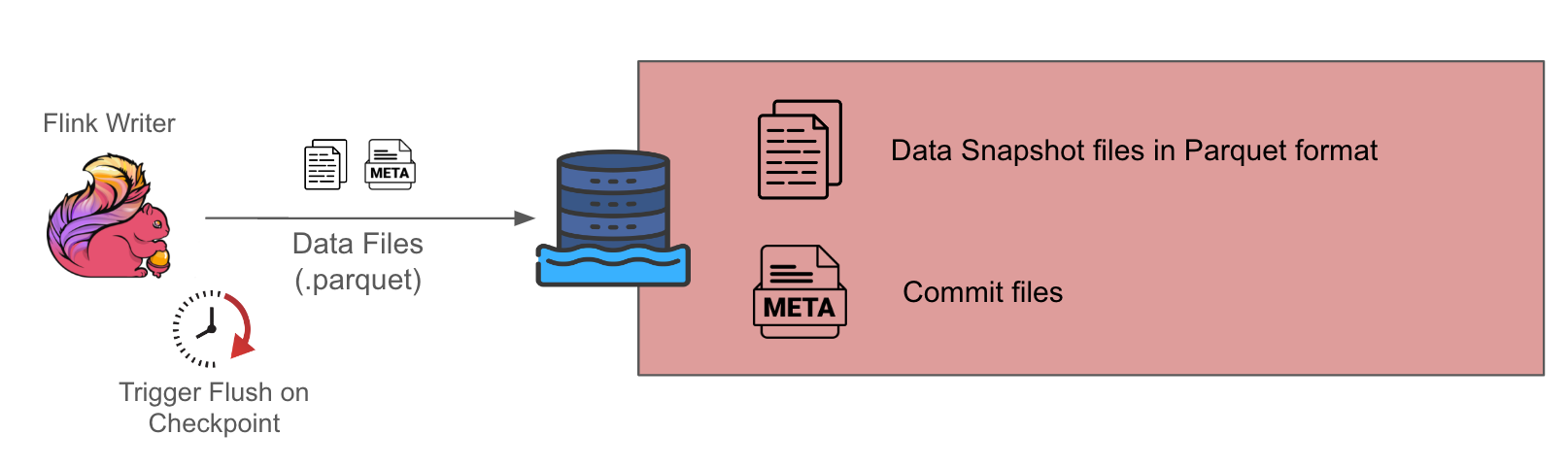
对于低吞吐量的源,我们倾向于选择写入时复制 (COW) 表,因为它的设计简单,因为它只涉及一个组件,即 Flink 写入端。缺点是它具有更高的数据延迟,因为此设置仅在每个检查点间隔(通常约为 10-15 分钟)生成 Parquet 格式的数据快照。
连接到 Kafka(无界)数据源
Grab 使用 Protobuf 作为 Kafka 中的中心数据格式,确保模式演进兼容性。但是,这些主题的模式的推导仍然需要一些转换,以使其与 Hudi 接受的模式兼容。其中一些转换包括确保 Avro 记录字段不仅包含单个数组字段,以及处理逻辑十进制架构以将其转换为固定字节架构以实现 Spark 兼容性。
鉴于源的无界性质,我们决定按 Kafka 事件时间将其划分为小时级别。这确保了我们的Hudi业务将更快。Parquet 文件写入速度会更快,因为它们只会影响同一分区中的文件,并且考虑到 Kafka 事件时间的单调递增性质,同一事件时间分区中的每个 Parquet 文件将具有有限大小。
通过按 Kafka 事件时间对表进行分区,我们可以进一步优化压缩计划操作,因为现在使用 BoundedPartitionAwareCompactionStrategy 可以减少所需的文件查找量。只有最近分区中的日志文件才会被选中进行压缩,作业管理器不再需要列出每个分区来确定在规划阶段选择哪些日志文件进行压缩。
连接到 RDS(有界)数据源
对于 RDS,我们决定使用 Veverica 的 Flink Change Data Capture (CDC) 连接器来获取二进制日志流。然后 RDS 会将 Flink 写入端视为复制服务器,并开始在每次 MySQL 更改时将其二进制日志数据流式传输到它。Flink CDC 连接器将数据显示为 Kafka Connect (KC) 源记录,因为它在后台使用 Debezium 连接器。然后将这些记录反序列化并将它们转换为 Hudi 记录是一项简单的任务,因为 Avro 架构和关联的数据更改已在 KC 源记录中捕获。
获取的二进制日志时间戳也会在消费期间作为指标发出,以便我们在摄取时监控观察到的数据延迟。
针对这些来源进行优化涉及两个阶段:
- 首先,为冷启动增量快照过程分配更多资源,其中 Flink 在 RDS 中拍摄当前数据状态的快照,并将该快照加载到 Hudi 表中。此阶段通常占用大量资源,因为在此过程中会引入大量文件写入和数据。
- 快照完成后,Flink 将开始处理二进制日志流,观察到的吞吐量将下降到类似于数据库写入吞吐量的水平。Flink 写入端在这个阶段所需的资源将比快照阶段低得多。
Hudi 表的索引
当写入引擎执行更新时,索引对于更新插入 Hudi 表非常重要,它允许它有效地定位要更新的数据的文件组。
从 0.14 版本开始,Flink 引擎仅支持 Bucket Index 或 Flink 状态索引。Bucket Index 通过对记录键进行哈希处理并将其与写入数据文件的命名约定所指示的特定文件存储桶进行匹配来执行文件记录的索引。另一方面,Flink 状态索引将记录键的索引映射存储到内存中的文件。
鉴于我们的表包含无界的 Kafka 源,我们的状态索引可能会无限增长。此外,Flink 状态索引在版本部署和配置更新中保持状态的要求增加了整体解决方案的复杂性。
因此,我们选择了简单的 Bucket Index,因为它简单易用,而且每个分区的 Hudi 表大小在一周内不会发生剧烈变化。然而,这带来了一个限制,即存储桶的数量无法轻松更新,并施加了我们的 Flink 管道可以扩展的并行度限制。因此,随着流量的有机增长,我们会发现自己处于一种情况,即我们的配置变得过时并且无法处理增加的负载。
为了解决这个问题,对存储桶索引使用一致的哈希将是需要探索的,以优化我们的 Parquet 文件大小,并允许存储桶的数量随着流量的增长而无缝增长。
效果
新鲜业务指标
在创建我们的 Hudi 数据摄取解决方案后,我们使各种用户(例如我们的数据分析师)能够更轻松地对延迟较低的数据执行临时查询。此外,Hudi 表可以与 Trino 中的 Hive 表无缝连接,以获得额外的上下文。这样一来,我们就可以构建运营仪表板,为我们的各个运营商反映新的业务指标,使他们能够快速响应任何异常情况(例如F1或季节性假期等高需求事件)。
更快速的欺诈检测
我们解决方案的另一个重要用户是我们的欺诈检测分析师。这使他们能够快速访问新的交易事件并分析其欺诈模式,尤其是在出现新的攻击模式时,而这种攻击模式尚未被他们的规则引擎检测到。我们的解决方案还允许他们执行多个临时查询,这些查询涉及对不同天数据的回溯,而不会影响我们的生产 RDS 和 Kafka 集群,方法是使用数据湖作为数据接口,将数据延迟降低到分钟级,从而使他们能够更快地响应攻击。
下一步计划?
随着数据存储解决方案的快速发展,我们渴望测试和集成新功能,例如记录级索引和预联接表的创建。这种演变超越了 Hudi 社区,扩展到了其他表格格式,例如 Iceberg 和 DeltaLake。我们随时准备适应这些变化,并将每种格式的优势整合到 Grab 的数据湖中。