一、流程图
Shuffle是Map方法之后,Reduce方法之前的数据处理过程称。

二、图解说明
1、数据流向
map方法中context.write(outK, outV);开始,写入环形缓冲区,再进行分区排序,写到磁盘
reduce方法拉取磁盘上的数据,归并成最终的结果文件。
一般,设置几个分区(Partition),则生成几个文件。
2、缓冲区
此处的排序,采用快速排序算法,针对key的索引进行排序,按照字典顺序进行排序。
如果环形缓冲区设置的是100m,那么,实际存储数据的空间只有50m
以此,来计算环形缓冲区的IO输出次数
3、Combiner过程
缓冲区溢出的文件有两类,spill.index和spill.out,每个分区都会生成一组。
此处主要做了两件事,对每次溢出的文件,按分区进行合并,和并算法时的算法是归并算法
归并好之后,分别进行压缩处理,并写入磁盘。
而,该过程是一个优化流程,所以,是可选流程。并不是必须的。
4、Reduce处理流程
设置几个分区,就要对应设置几个reduce对应处理
这里的分组也是非必须的
reduce按分区(Partition)主动去读取map的结果文件到内存中,如果内存不够,会溢出到磁盘。
这里主要是进行文件的合并,使用的是归并算法。
三、整体说明
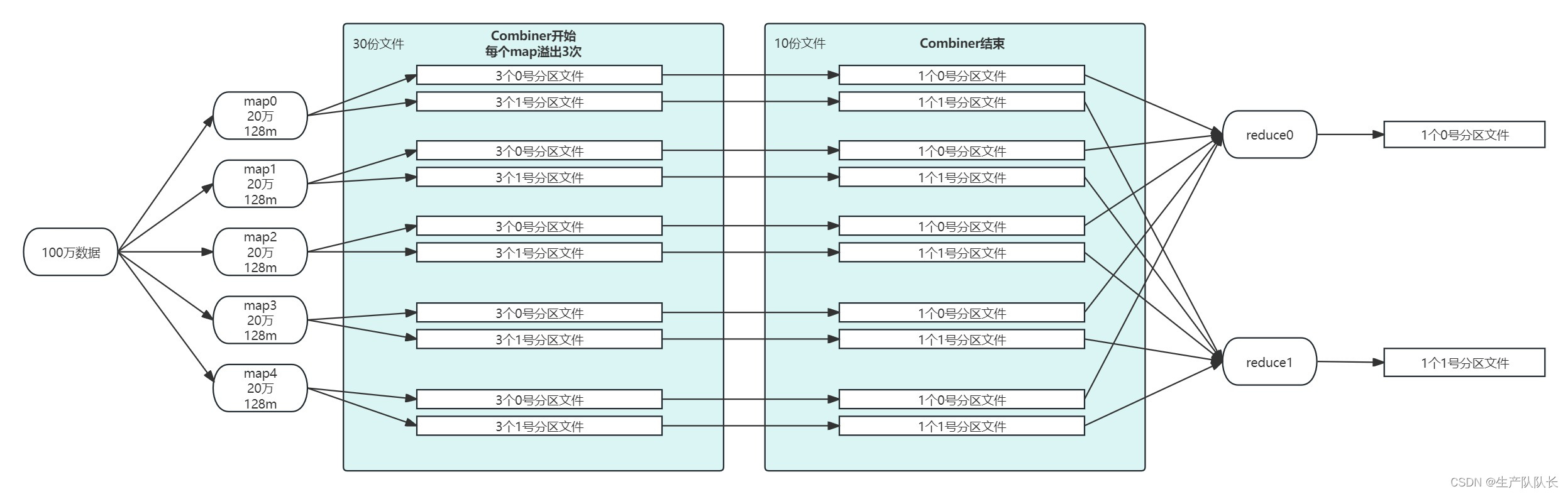
例如,有100万数据,我设计用5个mapTask去处理。那么,每个mapTask会处理20万条数据。
分区,设置为2个,那么,reduce个数就是2个。
文件数量的变化,如下图所示。