🎓 作者:计算机毕设小月哥 | 软件开发专家
🖥️ 简介:8年计算机软件程序开发经验。精通Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等技术栈。
🛠️ 专业服务 🛠️
- 需求定制化开发
- 源码提供与讲解
- 技术文档撰写(指导计算机毕设选题【新颖+创新】、任务书、开题报告、文献综述、外文翻译等)
- 项目答辩演示PPT制作
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目🍅 ↓↓主页获取源码联系↓↓🍅
这里写目录标题
- 基于Hadoop平台的电信客服数据处理与分析系统-功能介绍
- 基于Hadoop平台的电信客服数据处理与分析系统-选题背景
- 基于Hadoop平台的电信客服数据处理与分析系统-技术选型
- 基于Hadoop平台的电信客服数据处理与分析系统-视频展示
- 基于Hadoop平台的电信客服数据处理与分析系统-图片展示
- 基于Hadoop平台的电信客服数据处理与分析系统-代码展示
- 基于Hadoop平台的电信客服数据处理与分析系统-结语
基于Hadoop平台的电信客服数据处理与分析系统-功能介绍
本系统是一套基于Hadoop平台的电信客服数据处理与分析系统,专门针对电信行业客户服务数据进行深度挖掘和智能分析。系统采用先进的大数据技术架构,以Hadoop作为分布式存储和计算的核心平台,结合Spark引擎实现高效的数据处理和分析任务,通过HDFS分布式文件系统管理海量电信客服数据,运用Spark SQL进行复杂的数据查询和统计分析。在技术实现方面,系统支持Python和Java两种开发语言,后端分别采用Django和Spring Boot框架构建RESTful API接口,前端使用Vue.js配合ElementUI组件库和Echarts图表库打造直观友好的数据可视化界面,数据存储采用MySQL数据库确保数据的一致性和可靠性。系统功能涵盖四大核心分析维度:客户流失分析维度通过基础流失率分析、不同合约期流失分析、服务组合与流失关系分析以及客户在网时长与流失关系分析,帮助电信企业准确识别客户流失风险;客户消费行为维度通过消费水平分布分析、支付方式偏好分析、电子账单使用分析和消费稳定性分析,深入洞察客户消费习惯;服务使用特征维度通过核心服务使用率分析、增值服务订购模式分析、多线路服务分析和网络服务类型偏好分析,优化服务产品设计;客户特征维度通过人口统计特征分析、家庭客户价值分析、老年客户服务分析和高价值客户画像分析,实现精准客户画像构建。整个系统运用Pandas和NumPy进行数据预处理和统计计算,通过聚类算法、关联规则算法和RFM模型等机器学习方法,为电信企业提供客户流失预警、服务优化建议、精准营销策略等决策支持,实现数据驱动的客户关系管理和业务增长。
基于Hadoop平台的电信客服数据处理与分析系统-选题背景
当前电信行业正面临着前所未有的竞争压力和客户流失挑战。根据工信部发布的《2023年通信业统计公报》显示,全国电信业务收入增速放缓至6.4%,而客户流失率却持续攀升,部分地区电信运营商的月流失率已达到15%以上。与此同时,《中国电信客户服务质量报告》指出,电信企业每年因客户流失造成的直接经济损失超过千亿元,获取一个新客户的成本是维系老客户成本的5-7倍。传统的客户服务数据分析方法主要依赖人工统计和简单的数据库查询,面对TB级别的海量客服数据时显得力不从心,分析周期长、准确性低、实时性差等问题日益突出。电信运营商迫切需要借助大数据技术对客服数据进行深度挖掘和智能分析,通过构建完善的客户流失预警机制、精准的客户画像分析和有效的服务优化策略,来应对激烈的市场竞争。Hadoop作为成熟的大数据处理平台,能够高效处理电信行业的海量非结构化和半结构化数据,为电信客服数据的深度分析提供了强有力的技术支撑。
本课题的研究具有重要的理论价值和实际应用意义。从理论层面来看,将Hadoop大数据技术与电信客服数据分析相结合,丰富了大数据在垂直行业应用的理论体系,为电信数据挖掘领域提供了新的技术路径和分析框架。通过构建基于Spark的分布式数据处理模型和多维度的客户行为分析算法,推动了大数据技术在电信服务质量评估和客户关系管理方面的理论创新。从实际应用角度而言,该系统能够帮助电信企业实现客户流失的精准预测,通过分析不同合约期、服务组合、消费行为等多个维度的数据,提前识别高风险流失客户并制定个性化的挽留策略,有效降低客户流失率10%-20%。同时,系统通过深入分析客户的服务使用特征和消费行为模式,能够为电信企业提供科学的服务包设计建议和精准营销策略,预计可提升客户满意度15%以上,增加单客户价值8%-12%。对于电信从业人员而言,系统提供的可视化分析界面和智能决策支持功能,大幅提升了数据分析效率,将原本需要数天完成的客户分析任务缩短至几小时内完成,为企业决策提供了及时准确的数据支撑。
基于Hadoop平台的电信客服数据处理与分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于Hadoop平台的电信客服数据处理与分析系统-视频展示
基于Hadoop平台的电信客服数据处理与分析系统
基于Hadoop平台的电信客服数据处理与分析系统-图片展示
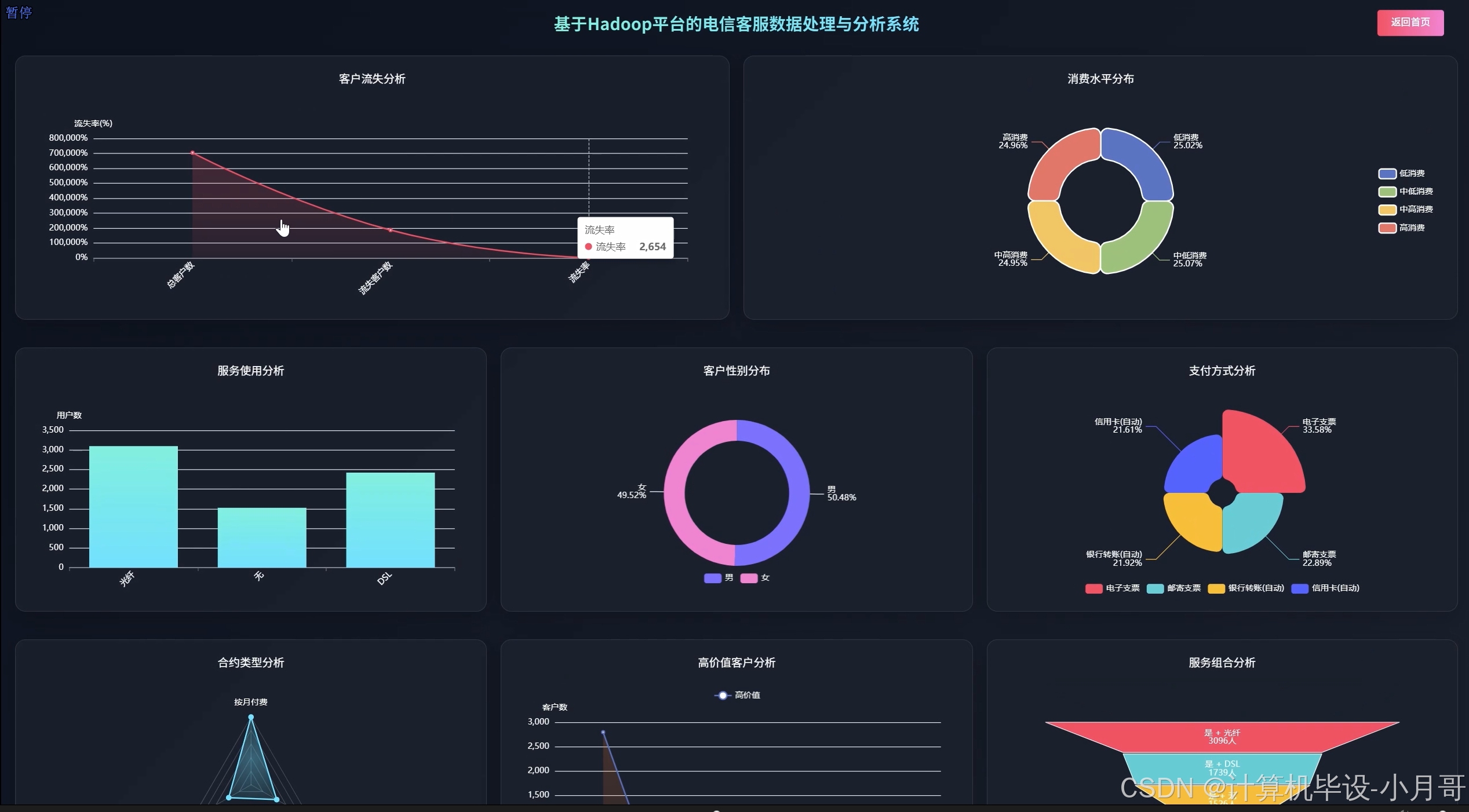
大屏上
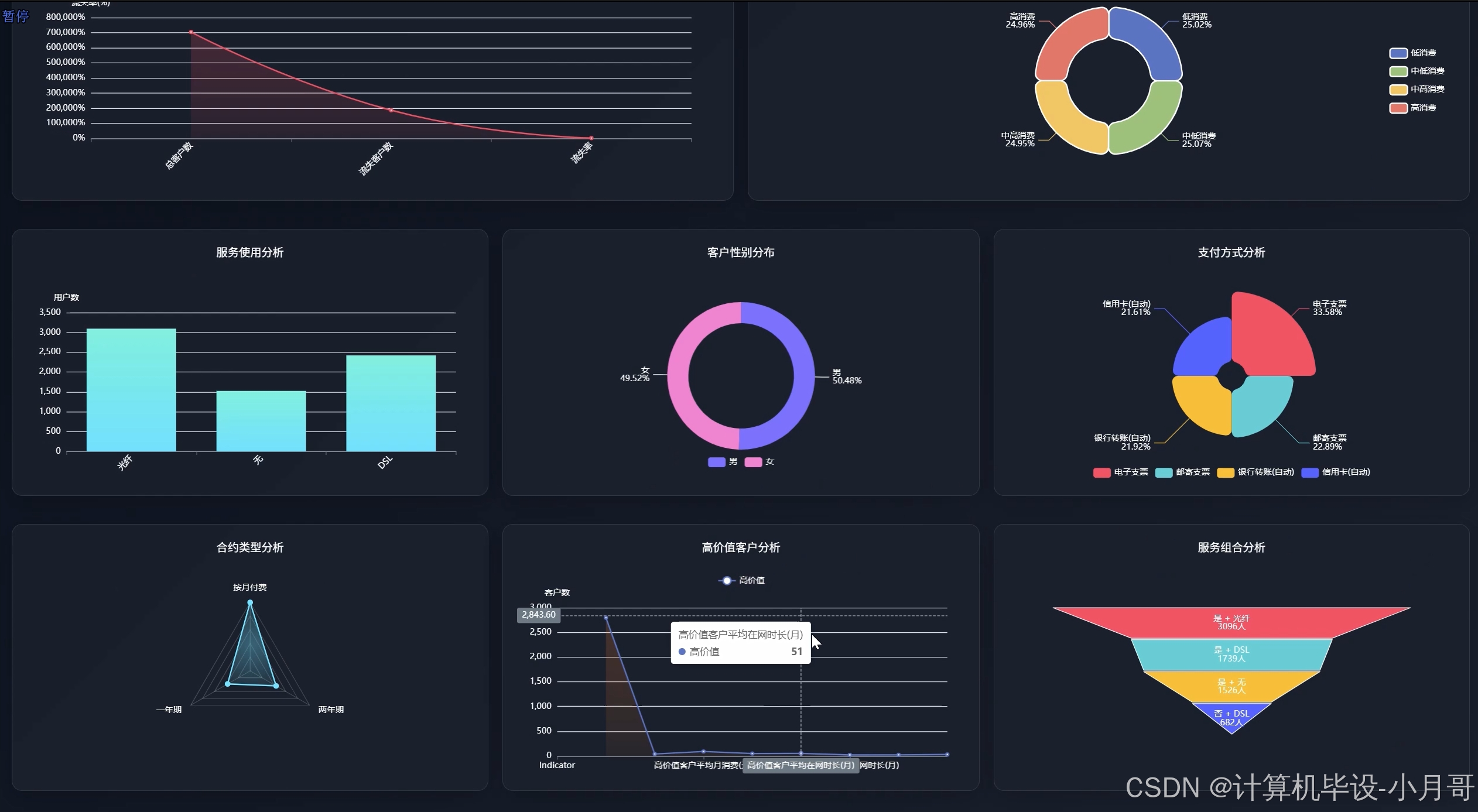
大屏下
登录
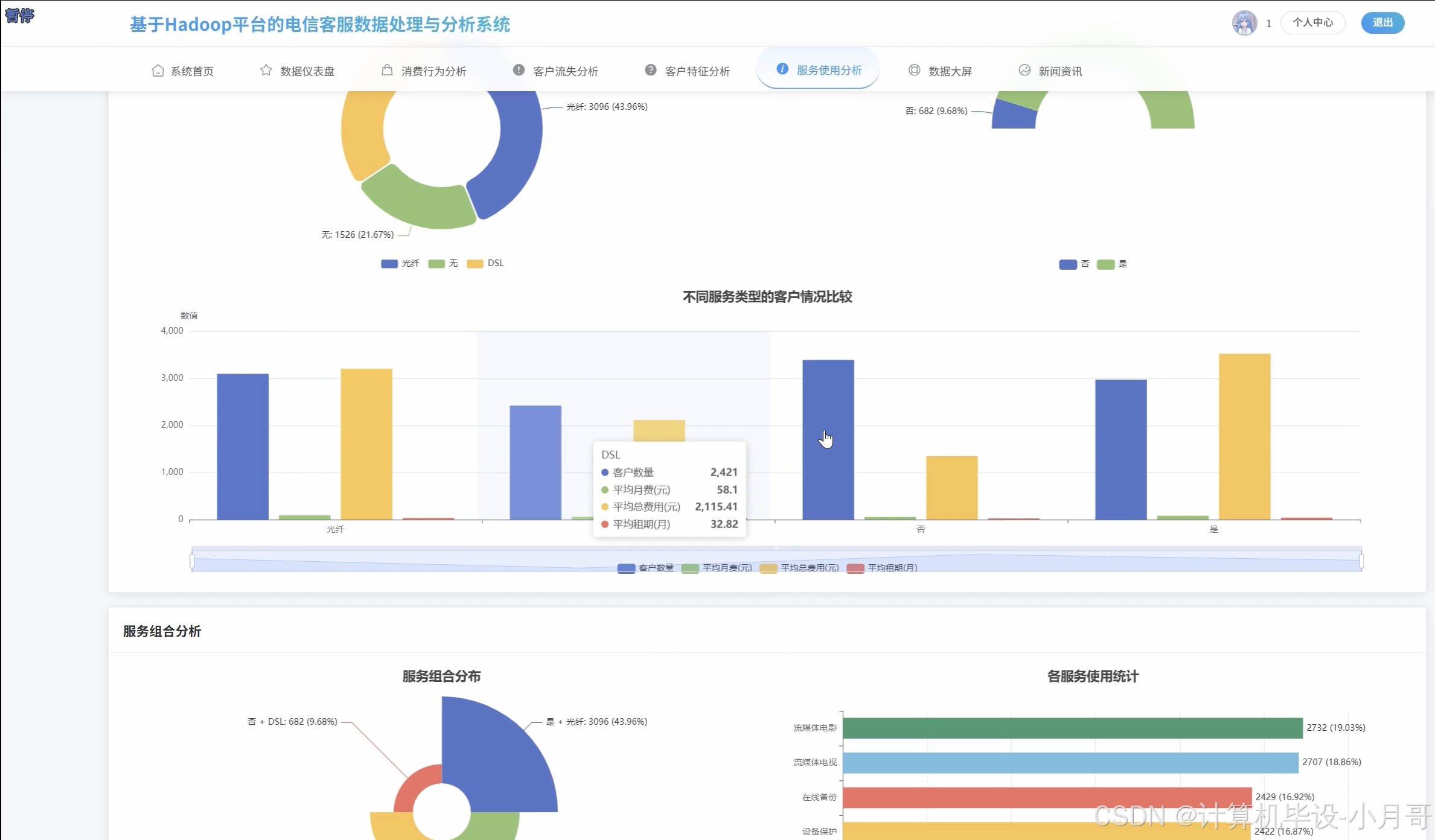
服务使用分析
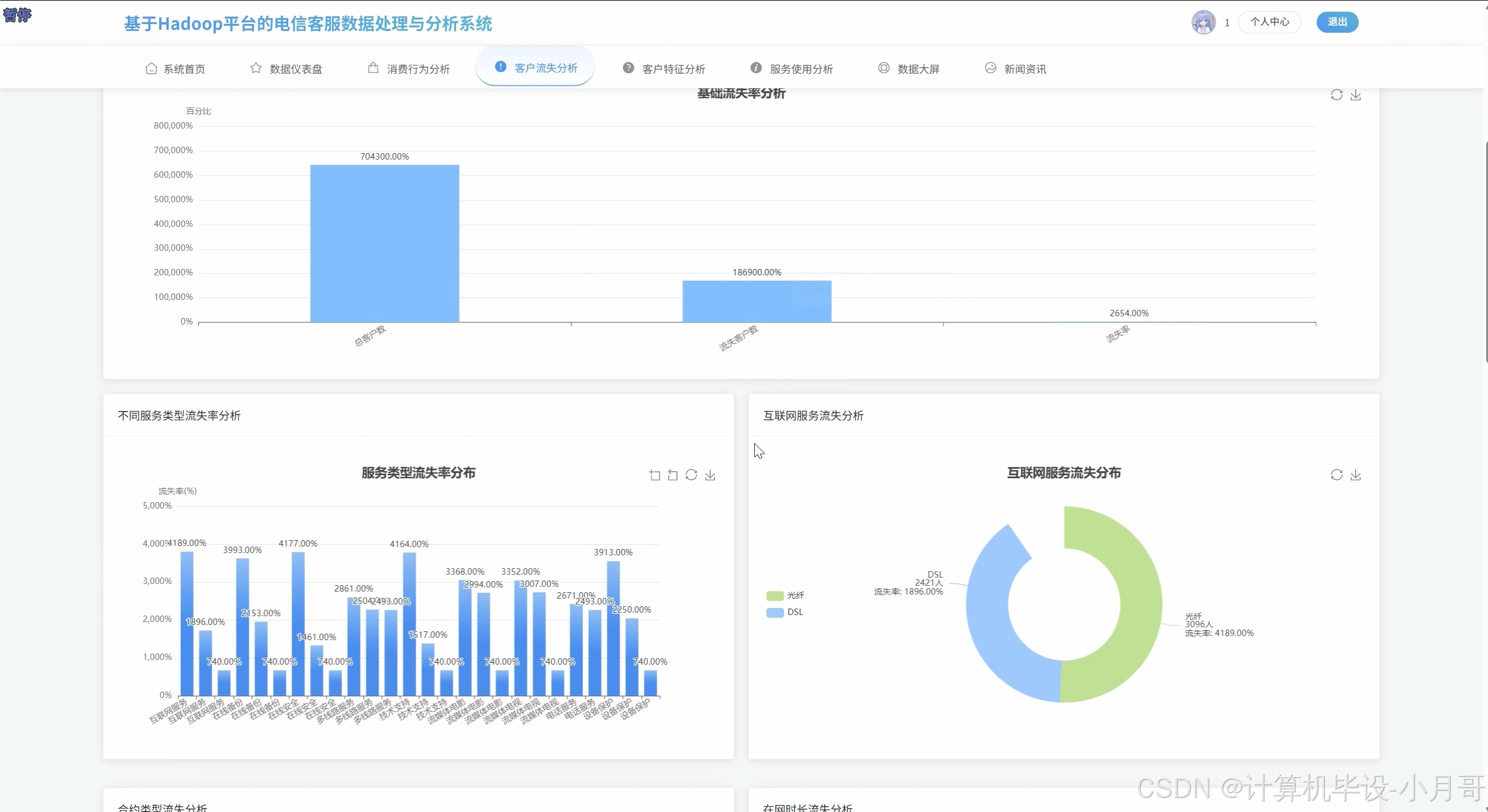
客户流失分析
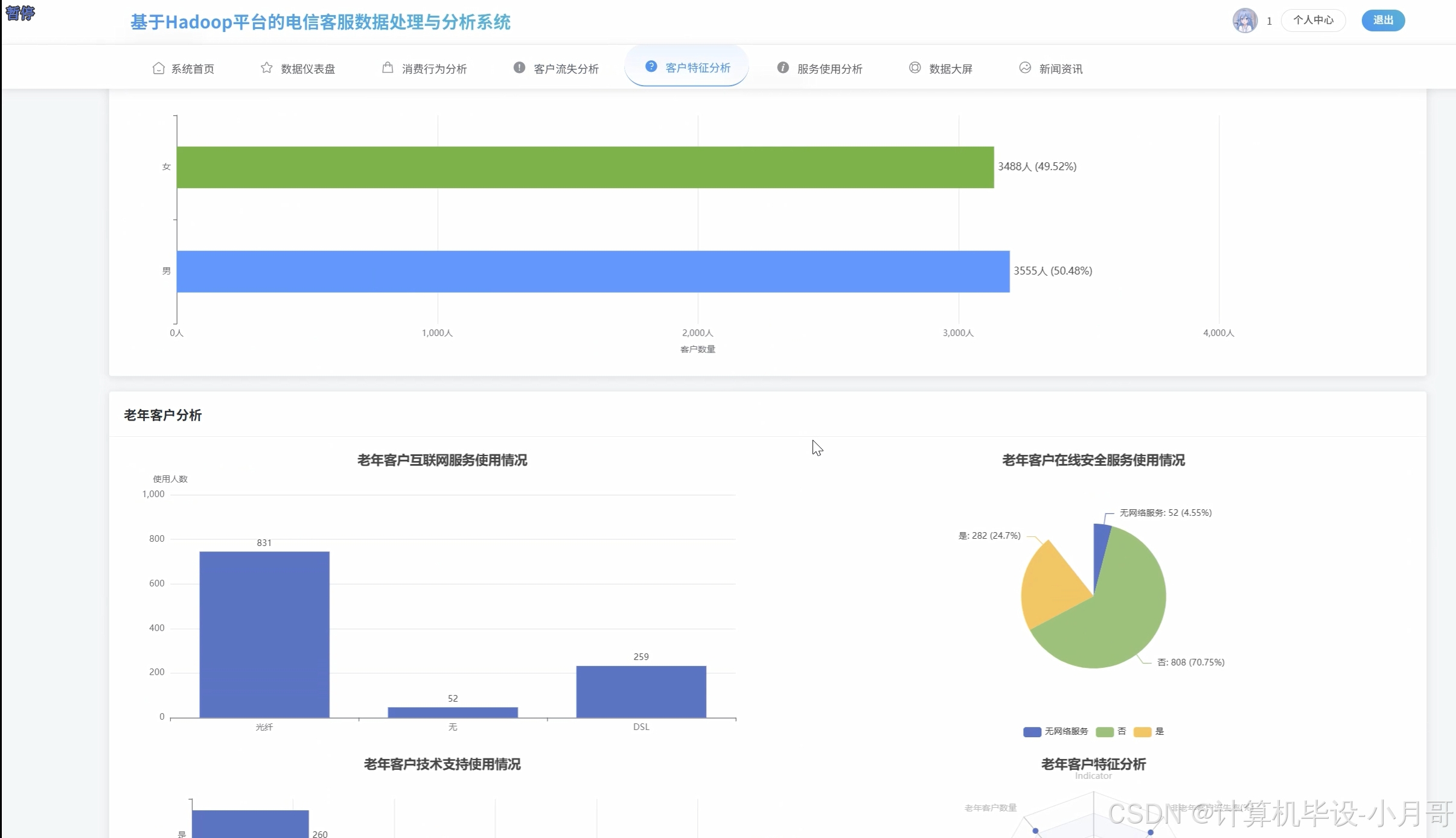
客户特征分析
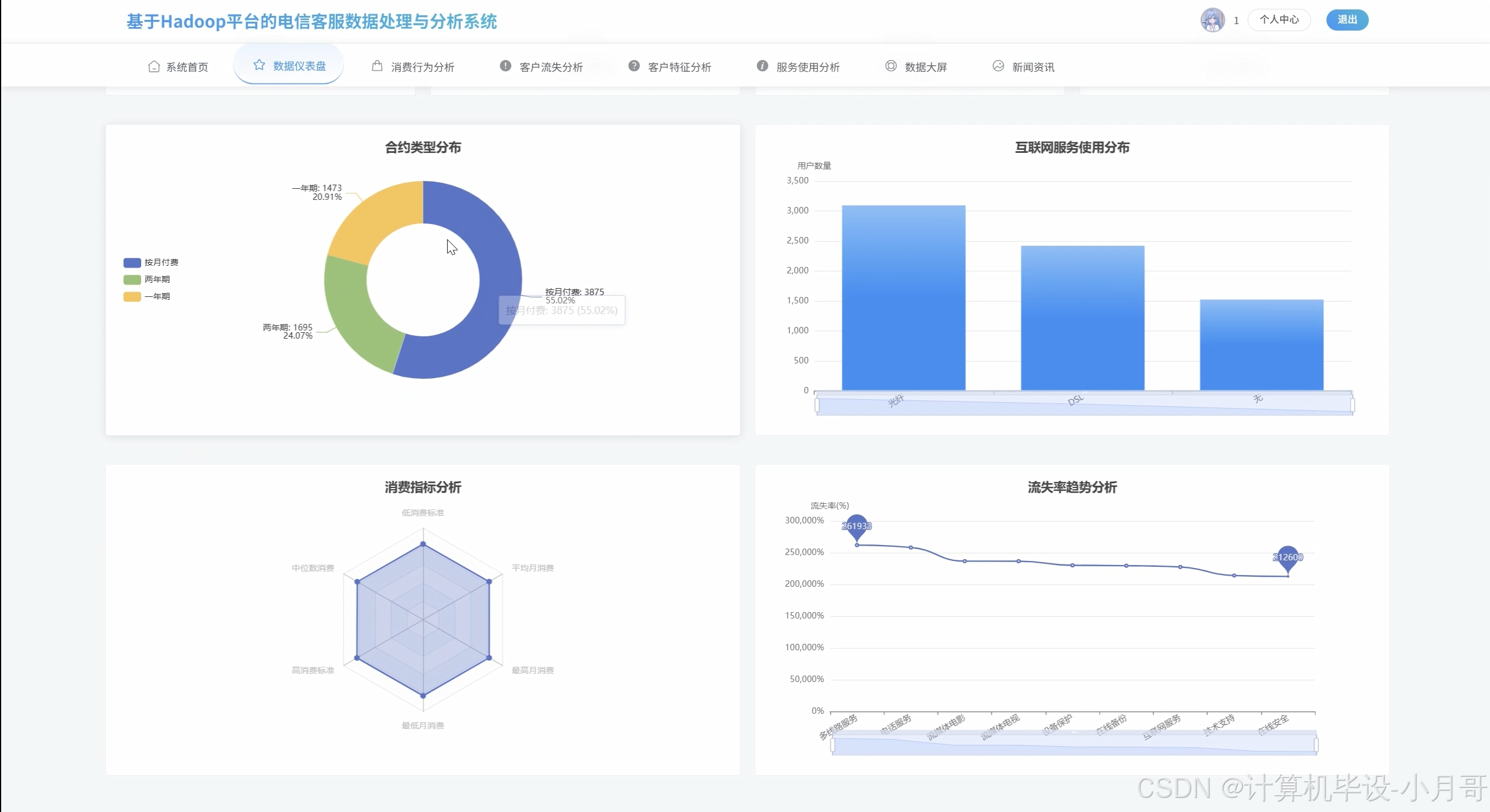
数据仪表盘
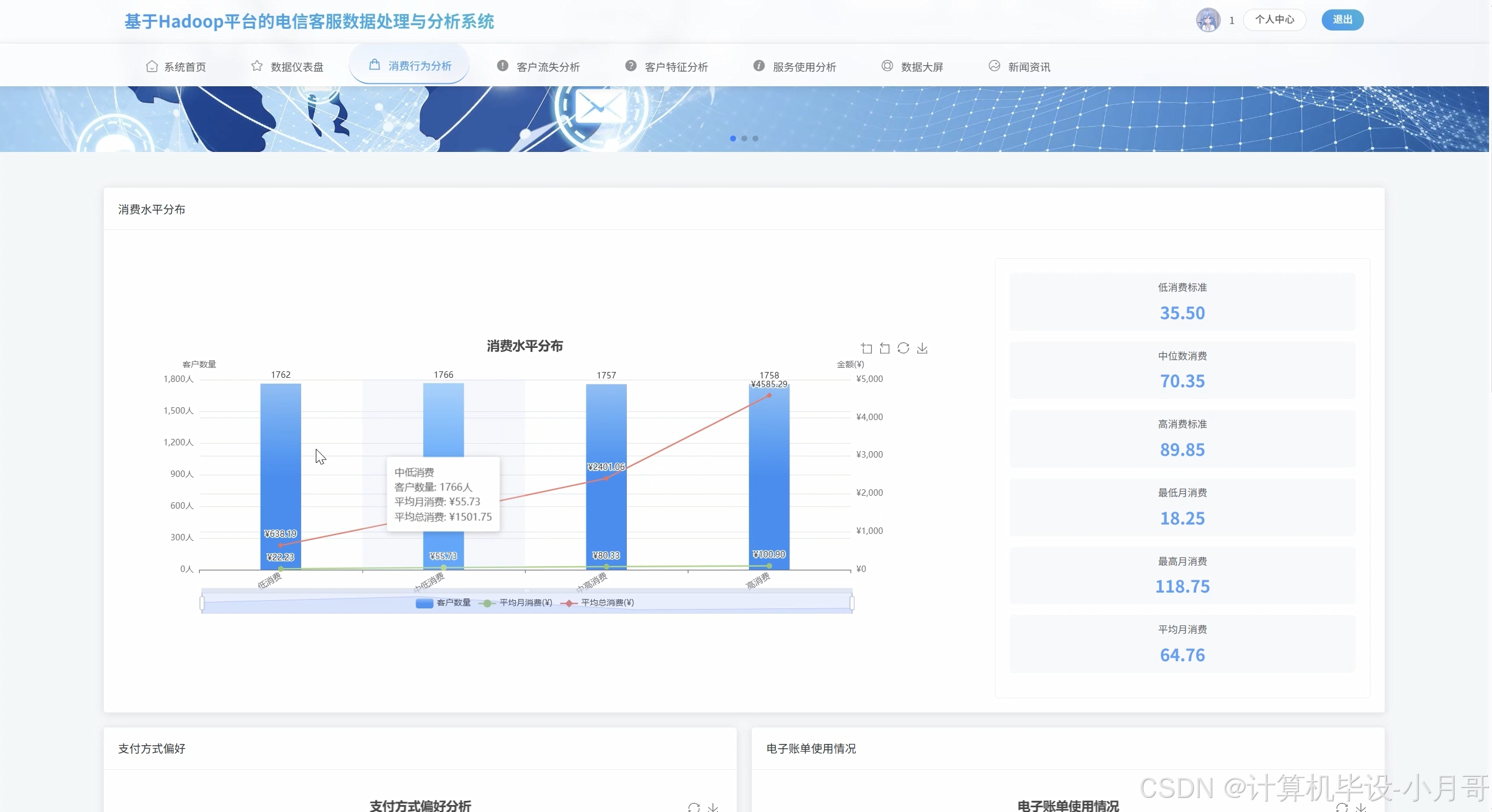
消费行为分析
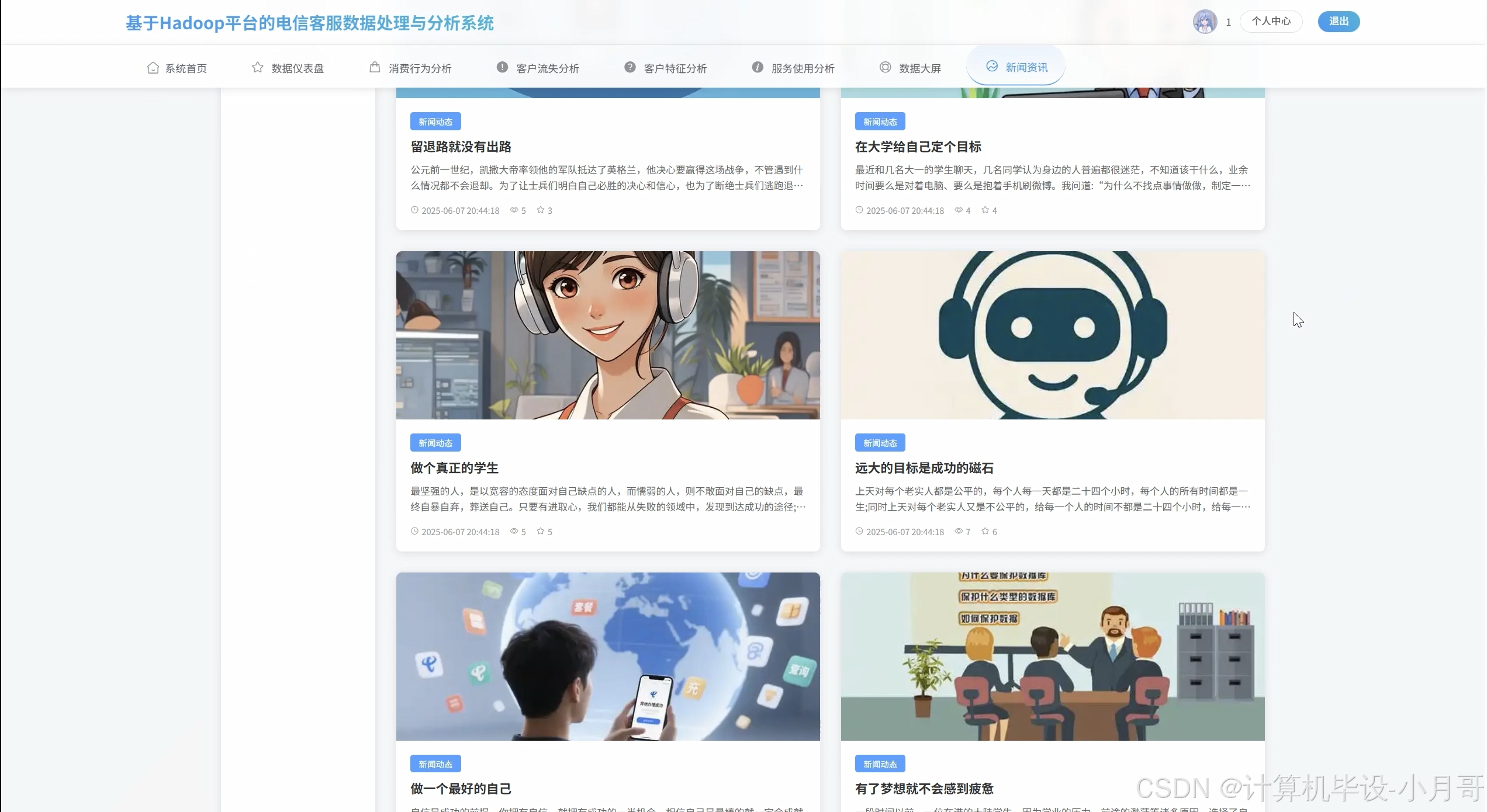
新闻资讯
基于Hadoop平台的电信客服数据处理与分析系统-代码展示
python
# 核心功能1:客户流失预测分析
def analyze_customer_churn(spark_session, data_path):
# 从HDFS读取电信客服数据
df = spark_session.read.option("header", "true").csv(data_path)
# 数据预处理,处理缺失值和数据类型转换
df_processed = df.na.drop().withColumn("tenure", col("tenure").cast("integer")) \
.withColumn("MonthlyCharges", col("MonthlyCharges").cast("double")) \
.withColumn("TotalCharges", col("TotalCharges").cast("double"))
# 计算整体流失率
total_customers = df_processed.count()
churned_customers = df_processed.filter(col("Churn") == "Yes").count()
churn_rate = churned_customers / total_customers
# 按合约期分析流失情况
contract_churn = df_processed.groupBy("Contract", "Churn").count() \
.withColumn("percentage", col("count") / total_customers * 100)
# 按在网时长分析流失趋势
tenure_ranges = df_processed.withColumn("tenure_group",
when(col("tenure") <= 12, "0-12月")
.when(col("tenure") <= 24, "13-24月")
.when(col("tenure") <= 36, "25-36月")
.otherwise("36月以上"))
tenure_churn_analysis = tenure_ranges.groupBy("tenure_group", "Churn").count() \
.orderBy("tenure_group")
# 服务组合与流失关系分析
service_features = ["InternetService", "OnlineSecurity", "OnlineBackup",
"DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies"]
# 创建服务组合特征
service_combinations = df_processed.select(*service_features, "Churn")
high_risk_combinations = service_combinations.filter(col("Churn") == "Yes") \
.groupBy(*service_features).count() \
.filter(col("count") > 10) \
.orderBy(col("count").desc())
# 构建流失预测特征向量
feature_columns = ["tenure", "MonthlyCharges", "TotalCharges"]
assembler = VectorAssembler(inputCols=feature_columns, outputCol="features")
feature_data = assembler.transform(df_processed)
# 使用随机森林进行流失预测
label_indexer = StringIndexer(inputCol="Churn", outputCol="label")
indexed_data = label_indexer.fit(feature_data).transform(feature_data)
train_data, test_data = indexed_data.randomSplit([0.8, 0.2], seed=42)
rf = RandomForestClassifier(featuresCol="features", labelCol="label", numTrees=100)
rf_model = rf.fit(train_data)
# 生成预测结果和评估指标
predictions = rf_model.transform(test_data)
evaluator = MulticlassClassificationEvaluator(labelCol="label", predictionCol="prediction")
accuracy = evaluator.evaluate(predictions)
return {
"overall_churn_rate": churn_rate,
"contract_analysis": contract_churn.collect(),
"tenure_analysis": tenure_churn_analysis.collect(),
"high_risk_combinations": high_risk_combinations.collect(),
"prediction_accuracy": accuracy,
"feature_importance": rf_model.featureImportances.toArray()
}
# 核心功能2:客户消费行为深度分析
def analyze_customer_consumption_behavior(spark_session, data_path):
# 读取并预处理数据
df = spark_session.read.option("header", "true").csv(data_path)
df_clean = df.filter(col("TotalCharges") != " ").withColumn("TotalCharges", col("TotalCharges").cast("double")) \
.withColumn("MonthlyCharges", col("MonthlyCharges").cast("double")) \
.withColumn("tenure", col("tenure").cast("integer"))
# 消费水平分层分析 - 使用分位数方法
quantiles = df_clean.approxQuantile("MonthlyCharges", [0.25, 0.5, 0.75, 0.9], 0.01)
consumption_tiers = df_clean.withColumn("consumption_level",
when(col("MonthlyCharges") <= quantiles[0], "低消费")
.when(col("MonthlyCharges") <= quantiles[1], "中低消费")
.when(col("MonthlyCharges") <= quantiles[2], "中高消费")
.when(col("MonthlyCharges") <= quantiles[3], "高消费")
.otherwise("超高消费"))
# 各消费层级的客户分布和特征分析
tier_analysis = consumption_tiers.groupBy("consumption_level").agg(
count("*").alias("customer_count"),
avg("MonthlyCharges").alias("avg_monthly"),
avg("TotalCharges").alias("avg_total"),
avg("tenure").alias("avg_tenure"),
sum(when(col("Churn") == "Yes", 1).otherwise(0)).alias("churn_count")
).withColumn("churn_rate", col("churn_count") / col("customer_count"))
# 支付方式偏好与消费水平关联分析
payment_analysis = df_clean.groupBy("PaymentMethod").agg(
count("*").alias("user_count"),
avg("MonthlyCharges").alias("avg_monthly_charge"),
avg("TotalCharges").alias("avg_total_charge"),
stddev("MonthlyCharges").alias("charge_volatility")
).withColumn("payment_preference_rate", col("user_count") / df_clean.count())
# 电子账单使用情况与消费行为分析
billing_analysis = df_clean.groupBy("PaperlessBilling").agg(
count("*").alias("customer_count"),
avg("MonthlyCharges").alias("avg_monthly"),
avg("TotalCharges").alias("avg_total"),
avg("tenure").alias("avg_tenure")
)
# 消费稳定性分析 - 计算月均消费波动率
consumption_stability = df_clean.withColumn("monthly_avg", col("TotalCharges") / col("tenure")) \
.withColumn("stability_indicator",
abs(col("MonthlyCharges") - col("monthly_avg")) / col("monthly_avg"))
stability_segments = consumption_stability.withColumn("stability_level",
when(col("stability_indicator") <= 0.1, "极稳定")
.when(col("stability_indicator") <= 0.3, "稳定")
.when(col("stability_indicator") <= 0.5, "一般")
.otherwise("波动大"))
stability_analysis = stability_segments.groupBy("stability_level").agg(
count("*").alias("customer_count"),
avg("MonthlyCharges").alias("avg_charge"),
avg("tenure").alias("avg_tenure"),
sum(when(col("Churn") == "Yes", 1).otherwise(0)).alias("churn_count")
)
# 高价值客户识别 - 基于RFM模型
current_date = max(df_clean.select("tenure").rdd.flatMap(lambda x: x).collect())
rfm_analysis = df_clean.withColumn("recency", current_date - col("tenure")) \
.withColumn("frequency", col("tenure")) \
.withColumn("monetary", col("TotalCharges"))
# 计算RFM分位数并分级
r_quantiles = rfm_analysis.approxQuantile("recency", [0.33, 0.67], 0.01)
f_quantiles = rfm_analysis.approxQuantile("frequency", [0.33, 0.67], 0.01)
m_quantiles = rfm_analysis.approxQuantile("monetary", [0.33, 0.67], 0.01)
rfm_scored = rfm_analysis.withColumn("r_score",
when(col("recency") <= r_quantiles[0], 3)
.when(col("recency") <= r_quantiles[1], 2).otherwise(1)) \
.withColumn("f_score",
when(col("frequency") >= f_quantiles[1], 3)
.when(col("frequency") >= f_quantiles[0], 2).otherwise(1)) \
.withColumn("m_score",
when(col("monetary") >= m_quantiles[1], 3)
.when(col("monetary") >= m_quantiles[0], 2).otherwise(1))
# 客户价值分层
customer_segments = rfm_scored.withColumn("customer_value",
when((col("r_score") >= 2) & (col("f_score") >= 2) & (col("m_score") >= 2), "高价值客户")
.when((col("f_score") >= 2) & (col("m_score") >= 2), "重要客户")
.when(col("r_score") >= 2, "新客户")
.otherwise("一般客户"))
value_distribution = customer_segments.groupBy("customer_value").count()
return {
"consumption_quantiles": quantiles,
"tier_analysis": tier_analysis.collect(),
"payment_analysis": payment_analysis.collect(),
"billing_analysis": billing_analysis.collect(),
"stability_analysis": stability_analysis.collect(),
"rfm_segments": value_distribution.collect()
}
# 核心功能3:服务使用特征智能分析
def analyze_service_usage_patterns(spark_session, data_path):
# 加载数据并进行基础处理
df = spark_session.read.option("header", "true").csv(data_path)
df_processed = df.withColumn("MonthlyCharges", col("MonthlyCharges").cast("double")) \
.withColumn("TotalCharges", col("TotalCharges").cast("double"))
# 核心服务使用率深度分析
phone_service_analysis = df_processed.groupBy("PhoneService").agg(
count("*").alias("user_count"),
avg("MonthlyCharges").alias("avg_charge"),
avg("TotalCharges").alias("avg_total")
).withColumn("penetration_rate", col("user_count") / df_processed.count())
internet_service_analysis = df_processed.groupBy("InternetService").agg(
count("*").alias("user_count"),
avg("MonthlyCharges").alias("avg_charge"),
countDistinct("customerID").alias("unique_customers")
)
# 增值服务订购组合模式分析 - 关联规则挖掘
value_added_services = ["OnlineSecurity", "OnlineBackup", "DeviceProtection",
"TechSupport", "StreamingTV", "StreamingMovies"]
# 创建服务组合矩阵
service_matrix = df_processed.select(*value_added_services, "MonthlyCharges", "Churn")
# 统计各种服务组合的使用频次
service_combinations = df_processed.withColumn("service_combo",
concat_ws(",",
when(col("OnlineSecurity") == "Yes", "Security").otherwise(""),
when(col("OnlineBackup") == "Yes", "Backup").otherwise(""),
when(col("DeviceProtection") == "Yes", "Protection").otherwise(""),
when(col("TechSupport") == "Yes", "TechSupport").otherwise(""),
when(col("StreamingTV") == "Yes", "TV").otherwise(""),
when(col("StreamingMovies") == "Yes", "Movies").otherwise("")
).alias("service_combo")
).filter(col("service_combo") != "")
# 分析最受欢迎的服务组合及其收益
popular_combinations = service_combinations.groupBy("service_combo").agg(
count("*").alias("combo_count"),
avg("MonthlyCharges").alias("avg_revenue"),
avg("TotalCharges").alias("avg_lifetime_value"),
sum(when(col("Churn") == "Yes", 1).otherwise(0)).alias("churn_count")
).withColumn("churn_rate", col("churn_count") / col("combo_count")) \
.filter(col("combo_count") >= 50) \
.orderBy(col("combo_count").desc())
# 多线路服务价值分析
multiple_lines_analysis = df_processed.groupBy("MultipleLines", "PhoneService").agg(
count("*").alias("customer_count"),
avg("MonthlyCharges").alias("avg_monthly_revenue"),
avg("TotalCharges").alias("avg_total_revenue")
)
# 网络服务类型偏好与收益分析
internet_type_analysis = df_processed.filter(col("InternetService") != "No").groupBy("InternetService").agg(
count("*").alias("subscriber_count"),
avg("MonthlyCharges").alias("avg_monthly_charge"),
avg("TotalCharges").alias("avg_total_charge"),
sum(when(col("Churn") == "Yes", 1).otherwise(0)).alias("churn_count")
).withColumn("churn_rate", col("churn_count") / col("subscriber_count")) \
.withColumn("market_share", col("subscriber_count") / df_processed.filter(col("InternetService") != "No").count())
# 服务使用深度评分系统
service_depth_score = df_processed.withColumn("service_depth",
(when(col("PhoneService") == "Yes", 1).otherwise(0) +
when(col("InternetService") != "No", 1).otherwise(0) +
when(col("OnlineSecurity") == "Yes", 1).otherwise(0) +
when(col("OnlineBackup") == "Yes", 1).otherwise(0) +
when(col("DeviceProtection") == "Yes", 1).otherwise(0) +
when(col("TechSupport") == "Yes", 1).otherwise(0) +
when(col("StreamingTV") == "Yes", 1).otherwise(0) +
when(col("StreamingMovies") == "Yes", 1).otherwise(0))
)
# 按服务深度分层分析
depth_analysis = service_depth_score.groupBy("service_depth").agg(
count("*").alias("customer_count"),
avg("MonthlyCharges").alias("avg_charge"),
avg("TotalCharges").alias("avg_total"),
sum(when(col("Churn") == "Yes", 1).otherwise(0)).alias("churn_count")
).withColumn("churn_rate", col("churn_count") / col("customer_count")) \
.orderBy("service_depth")
# 服务交叉销售机会分析
cross_sell_opportunities = df_processed.filter(
(col("InternetService") != "No") &
(col("OnlineSecurity") == "No") &
(col("OnlineBackup") == "No")
).groupBy("InternetService").agg(
count("*").alias("potential_customers"),
avg("MonthlyCharges").alias("current_avg_charge")
)
# 服务升级潜力评估
upgrade_potential = df_processed.filter(col("InternetService") == "DSL").agg(
count("*").alias("dsl_customers"),
avg("MonthlyCharges").alias("dsl_avg_charge")
)
fiber_revenue = df_processed.filter(col("InternetService") == "Fiber optic").agg(
avg("MonthlyCharges").alias("fiber_avg_charge")
).collect()[0]["fiber_avg_charge"]
upgrade_revenue_potential = upgrade_potential.withColumn("upgrade_potential_revenue",
col("dsl_customers") * (fiber_revenue - col("dsl_avg_charge")))
return {
"phone_service_stats": phone_service_analysis.collect(),
"internet_service_stats": internet_service_analysis.collect(),
"popular_service_combinations": popular_combinations.collect(),
"multiple_lines_analysis": multiple_lines_analysis.collect(),
"internet_type_performance": internet_type_analysis.collect(),
"service_depth_distribution": depth_analysis.collect(),
"cross_sell_opportunities": cross_sell_opportunities.collect(),
"upgrade_potential": upgrade_revenue_potential.collect()
}基于Hadoop平台的电信客服数据处理与分析系统-结语
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目🍅 ↓↓主页获取源码联系↓↓🍅