很久前明月就发现百度爬虫只抓取、只收录就是不给流量了,加上百度搜索体验越来越差,反正明月已经很久没有用过百度搜索,目前使用的浏览器几乎默认搜索都已经修改成其他搜索引擎了,真要搜索什么,一般都是必应+谷歌结合着使用。所以就一直在纠结要不好屏蔽百度爬虫,上周借助 CloudFlare 的【随机加密】先技术性的屏蔽百度爬虫了。
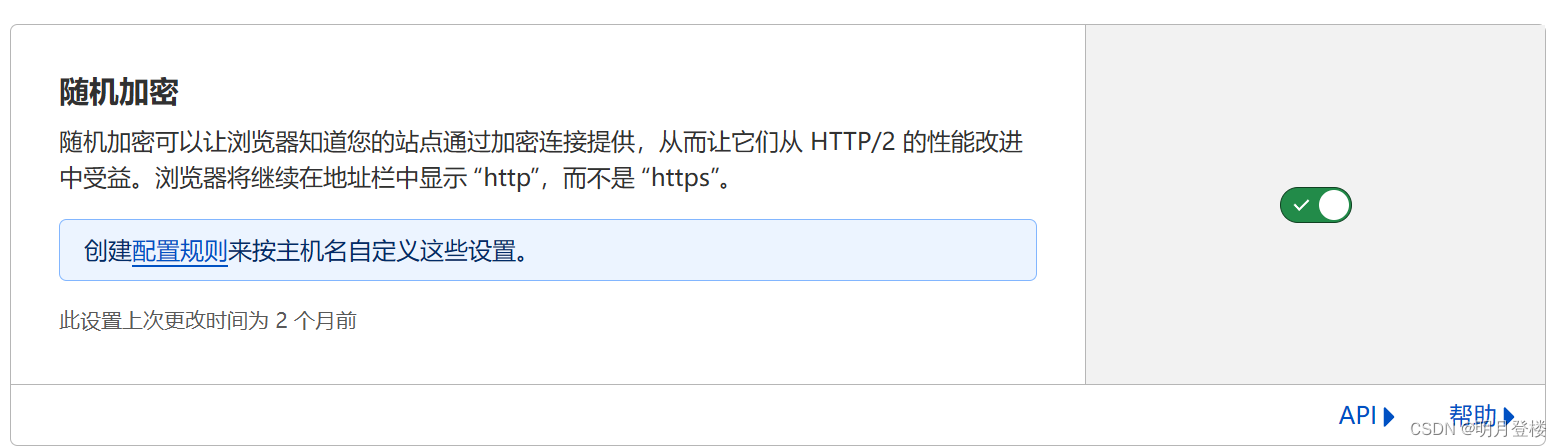
说起来比较好笑都 2024 年了,早就号称支持 HTTPS 的百度爬虫竟然不支持【随机加密 】(可参考【使用 CloudFlare 后百度抓取诊断抓取失败的解决办法】一文),就是这么神奇!

所以我这个所谓的技术性屏蔽百度爬虫说白了就是开启【随机加密】,让百度的爬虫抓取出现报错,今天又继续在 robots.txt 里屏蔽百度爬虫:
User-agent: Baiduspider
Disallow: /
User-agent: Baiduspider-image
Disallow: /说实话,百度爬虫真的很 low,既然你都不给我流量,我也就没有"供养"你的必要了,反正我现在的感觉就是百度爬虫一直在利用网站养他的 AI,这是我不能接受的,所以必须屏蔽拦截掉。