文章目录
- [Mybatis 笔记(3.5.16)](#Mybatis 笔记(3.5.16))
- A、试试SqlSessionFactory
- B、建立连接的三种方式
- [C、"复杂"的 Configuration 模式实现](#C、“复杂”的 Configuration 模式实现)
-
- 1、直接构建Configuration
- [2、补充environment 要素](#2、补充environment 要素)
-
- 2.1、填充id
- 2.2、填充TransactionFactory
- [2.3、填充 DataSource](#2.3、填充 DataSource)
- 2.4、整合填充
- 2.5、不存在映射语句集合
- 3、补充映射语句
- D、整理信息
-
- 1、如何构建sqlSeesion?
- [2、如何构建Environment 呢?](#2、如何构建Environment 呢?)
- 3、如何执行sql?
- 4、怎么构建的sql
-
- 4.1、打开会话执行
- 4.2、构建SqlSession
-
- 4.2.1、偏移量处理
- 4.2.2、结果处理器
- [4.2.3、获取 MappedStatement](#4.2.3、获取 MappedStatement)
- 4.3、补充下构建MappedStatement
- 5、交给执行器处理
- 6、执行器开始查数据
- 7、整理结果
- 8、回到开始查询的位置
Mybatis 笔记(3.5.16)
1、基础数据
sql
-- 创建用户表
CREATE TABLE users
(
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL UNIQUE,
email VARCHAR(100) NOT NULL UNIQUE,
password VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 插入示例数据
INSERT INTO users (username, email, password)
VALUES ('john_doe', 'john.doe@example.com', 'password123'),
('jane_smith', 'jane.smith@example.com', 'securepassword'),
('alice_jones', 'alice.jones@example.com', 'mypassword'),
('bob_brown', 'bob.brown@example.com', 'password456'),
('charlie_black', 'charlie.black@example.com', 'pass789');2、基础依赖
测试数据库: mysql 8.0.26
xml
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>3、魔改点标记
1、事务管理器
我们可以自定义事务管理器来实现自己的额外需求。
2、切换环境
根据 Environment 的id选择
A、试试SqlSessionFactory
对应 :
task one这里主要试试如何创建
SqlSessionFactory来创建连接以查询对话
基本流程描绘
SqlSessionFactoryBuilder
| done
↓ ↑
XMLConfigBuilder (读取配置内容) parseConfiguration(核心解析方法)
| ↑
↓ |
XPathParser (直接javax的解析) |
| ↑
↓ |
configuration.xml ----> 1、利用dtd 约束基础数据库 和 mapper 映射文件所在.
2、利用XML解析数据,构建 SqlSessionFactory 来完成整个会话的创建和处理。
如果自己魔改,建议无论如何数据库都留用
pooled数据库,避免习惯性测试纰漏。
3、这里虽然实现很多,但是最终是三种模式,如图(图A-b-1)

(图A-1-1)
B、建立连接的三种方式
根据
A-3可知,原来可以三种模式实现。1、Reader model
2、InputSteam model
3、Configuration model
1、执行方法
java
SqlSession session = sqlMapper.openSession();
try {
User user = (User) session.selectOne("mapper.UserMapper.getUser", 1);
System.out.println(user.getId() + "," + user.getUsername());
} finally {
session.close();
}2、实现方式
除了第三种,前两种除了读取方式不一致,都相当轻松模拟了。
java
public static SqlSessionFactory ReaderModel(String resource){
try (Reader reader = Resources.getResourceAsReader(resource)) {
return new SqlSessionFactoryBuilder().build(reader);
} catch (IOException e) {
System.err.println("Error reading file: " + e.getMessage());
return null;
}
}
public static SqlSessionFactory inputSteamModel(String resource){
try (InputStream inputStream = MybatisHelloWorld.class.getClassLoader().getResourceAsStream(resource)) {
return new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
System.err.println("Error reading file: " + e.getMessage());
return null;
}
}C、"复杂"的 Configuration 模式实现
比起前两种实现,第三种相当于自己来折腾了,走起。
1、直接构建Configuration
直接构建尝试
则会在图 (C-1-1) 处触发空指针异常
java
Configuration configuration = new Configuration();
sqlMapper = new SqlSessionFactoryBuilder().build(configuration);
(图 C-1-1)
2、补充environment 要素
由于直接构建出现空指针异常,因此需要补充
Environment及其内部的datasourcceTips: 这里相当于配置文件中配置数据库的地方了。
构建Environment需要三个参数
①
String id: 这里是环境的唯一id②
TransactionFactory transactionFactory:事务工厂③
DataSource dataSource: 数据源
2.1、填充id
这里其实就是用来填充环境,选择环境的。
这里,我们目前就用
dedevelopment
2.2、填充TransactionFactory
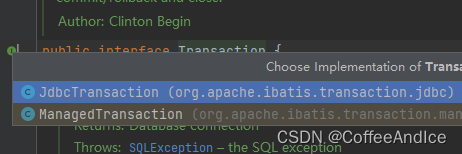
这里主要分为两个,如图 (C-2-2-1)
1、JdbcTransaction:使用JDBC的事务管理机制
2、ManagedTransaction: 什么都不做的事务管理
为了严谨后续测试,使用
JdbcTransaction。如果留空通常会默认选择后者,但直接构建是必选的。
(图 C-2-2-1)
(图 C-2-2-2)

2.3、填充 DataSource
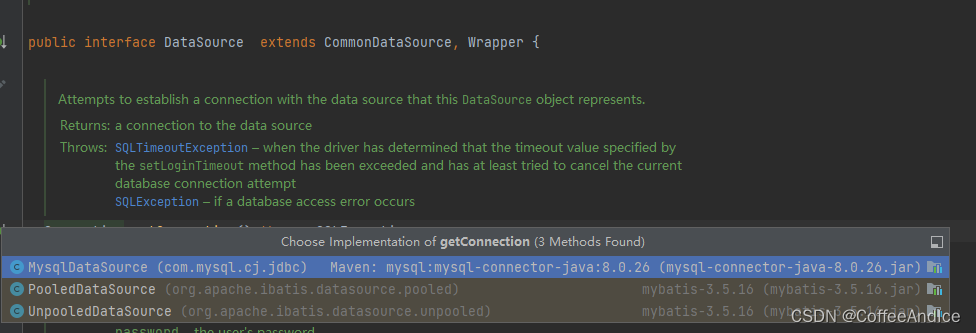
这里主要提供了两种实现方式,如图(C-2-3-1)
1、 PooledDataSource: 线程安全的连接池的数据源
2、UnpooledDataSource: 用完就关的数据源(测试用)
(图 C-2-3-1)
2.4、整合填充
java
Environment development = new Environment
.Builder("development")
.transactionFactory(new JdbcTransactionFactory())
.dataSource(new PooledDataSource("com.mysql.jdbc.Driver"
, "jdbc:mysql://localhost:3306/sys?useUnicode=true"
, "root"
, "root"))
.build();
Configuration configuration = new Configuration(development);
sqlMapper = new SqlSessionFactoryBuilder().build(configuration);
SqlSession session = sqlMapper.openSession();
try {
User user = (User) session.selectOne("mapper.UserMapper.getUser", 1);
System.out.println(user.getId() + "," + user.getUsername());
} finally {
session.close();
} 2.5、不存在映射语句集合
执行后会发现
Mapped Statements collection does not contain value for mapper.UserMapper.getUser
3、补充映射语句
正常的配置,也是需要配置sql、对象映射才能用,也是正常的。
根据报错得知,我们可以从
DefaultSqlSession#selectList下发现这个问题。余下只需要补充即可。

(图3-1)
3.1、补充 MappedStatement
根据
C.2.5线索,需要补充MappedStatement执行后,会发现
A query was run and no Result Maps were found for the Mapped Statement 'mapper.UserMapper.getUser'. 'resultType' or 'resultMap' must be specified when there is no corresponding method.
查询语句补充
通过构造器,可以知道。
这里对应的id应该与调用的id一致。
故id继续设置:
mapper.UserMapper.getUser
Builder的参数
1、
Configuration无需多解释2、对应MappedStatement的id
3、SqlSource 类型,构建sql用
4、SqlCommandType类型,对应的sql命令类型
java
StaticSqlSource staticSqlSource = new StaticSqlSource(configuration, "select id,username from users where id = 1");
configuration.addMappedStatement(new MappedStatement
.Builder(configuration, "mapper.UserMapper.getUser", staticSqlSource, SqlCommandType.SELECT)
.build());3.2、补充结果集
构造器中可以发现设置
resultMaps数组这里跟随同一个id :
mapper.UserMapper.getUser由于设置值未知,先尝试建设一个空数据尝试
java
List<ResultMapping> resultMappings = new ArrayList<>();
ResultMap resultMap = new ResultMap.Builder(configuration, "mapper.UserMapper.getUser", User.class, resultMappings).build();3.3、整合运行
正常出结果
1,john_doe
D、整理信息
这里由 简单的查询语句开始引入记录
mysqlselect id,username from users where id = ?
1、如何构建sqlSeesion?
1、需要利用配置的
Environment来生成数据库连接。2、需要执行特定的sql,故需要构造语句,则这里需要配置
MappedStatement3、配置了
MappedStatement,要执行,执行要返回结果,故ResultMap就要补齐了。4、如果需要动态参数,那么可以往
MappedStatement里面加ParameterMap
2、如何构建Environment 呢?
参考A、C两点,主要是通过这三种方式来构建基础内容
3、如何执行sql?
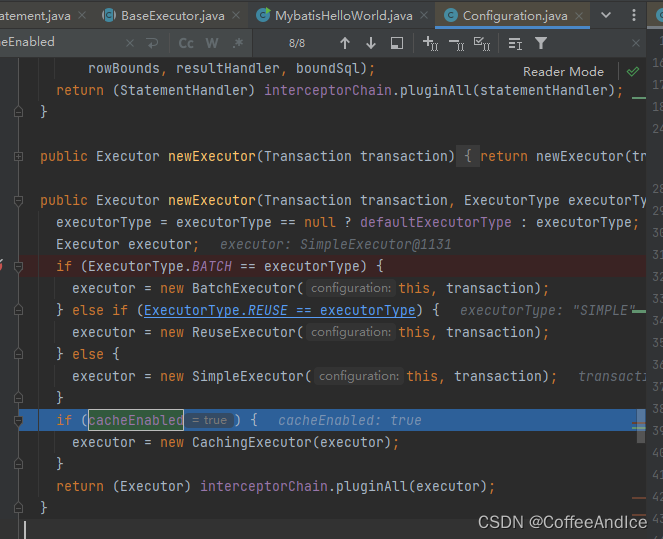
通过上述构建
sqlSession的基础构建成SqlSource, 交由SimpleExecutor执行处理。这里补充一句,其实默认是 CachingExecutor,除非设置了
cacheEnabled为false。可以从
Configuration#newExecutor看到
(图D-3-1)
4、怎么构建的sql
4.1、打开会话执行
如果开启会话时不加参数
默认会是
SimpleExecutor,最终调用的是DefaultSqlSession
SqlSession session = sqlMapper.openSession()
session.selectOne("mapper.UserMapper.getUser", 1)4.2、构建SqlSession
根据
4.1可知其实是由DefaultSqlSession去执行的其实无论是
one还是list其实最终都是list,只不过会给你加一波异常弹出.

(图D-4-4.2-1)
4.2.1、偏移量处理
这里默认是会给你拉爆的,所以还得是处理好。
!
(图D-4-4.2-2)

(图D-4-4.2-3)
4.2.2、结果处理器
这里是可以针对结果处理的地方,这里用了默认值,其实就是null。
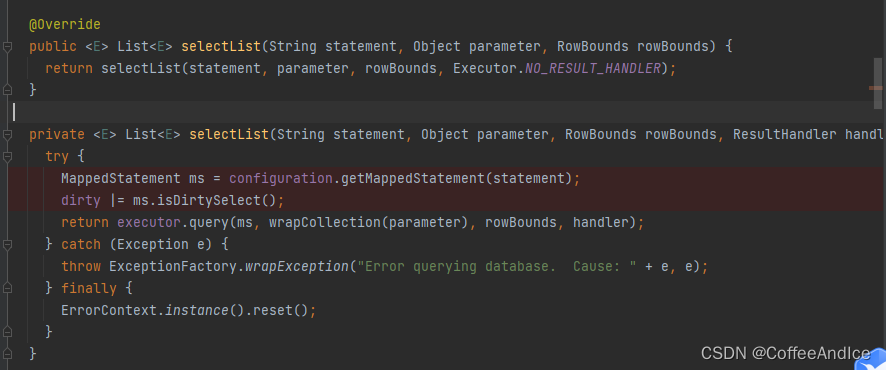
(图D-4-4.2-4)
4.2.3、获取 MappedStatement
这里结合图 (D-4-4.2-4)和图 (D-4-4.2-5)
实际上这里获取的时候是可以检验或比较严的
校验其实就是就是尝试去构建所有的语句避免get不到
Tips:这里的id其实就是全局通用的一个id,用来绑定上下文中设定的语句
这里补充下:图 (D-4-4.2-7) 主要图例是查询语句。构建完后,交回给
executor

(图D-4-4.2-5)
(图D-4-4.2-6)
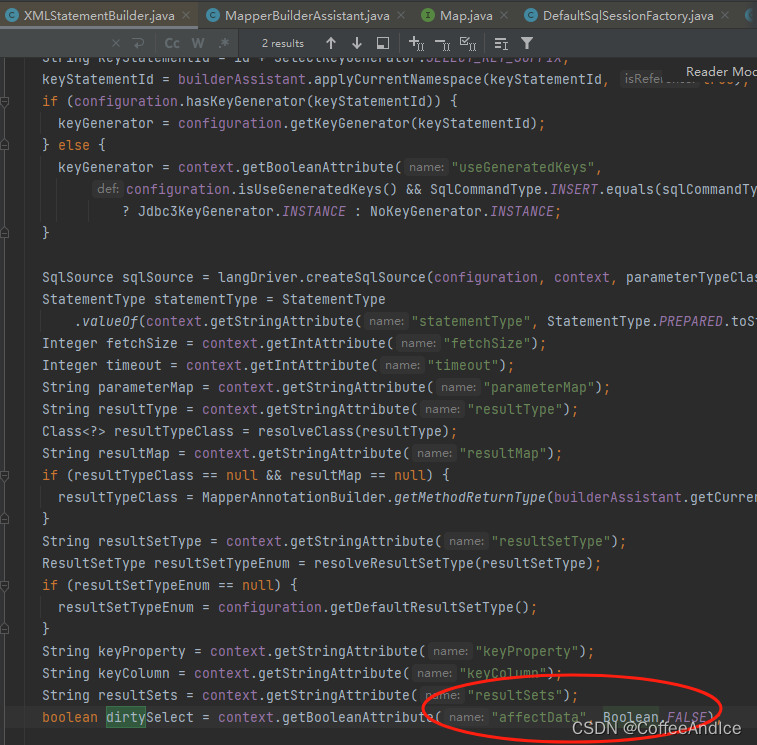
(图D-4-4.2-7)
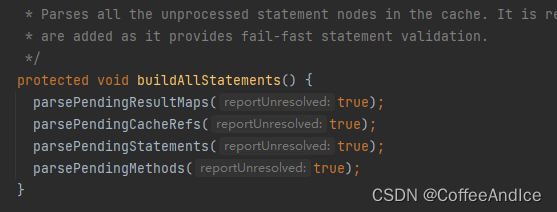
4.3、补充下构建MappedStatement
下述的方法,都能以全局
id维系一起。也就是
getMappedStatement内buildAllStatements内容
| 参数 | 解析 |
|---|---|
| parsePendingResultMaps(true) | 解析结果映射(Result Maps) |
| parsePendingCacheRefs(true) | 解析缓存应用(Cache Refs) |
| parsePendingStatements(true) | 解析SQL 语句 |
| parsePendingMethods(true) | 解析对应的方法 |
5、交给执行器处理
入口参考:图(D-4-4.2-4)
由D-3 可知,交由
CachingExecutor去实现,除非于配置时
configuration.setCacheEnabled(false);则继续进入图(D-5-1)描述
CachingExecutor
5.1、CachingExecutor
这里通常也是所描绘的二级缓存,专门用一个执行器处理。
但是是需要开启的,在
MappedStatment内
markdown
# 由上至下
1、判断 `MappedStatement` 内是否存在缓存。
2、判断是否需要刷新缓存,默认是false的。
3、校验 `MappedStatement` 缓存标记且确保单纯的缓存不存在后续的结果处理,保证一定的幂等性。
4、校验是否存在调用函数的一些问题,如果有就会出异常,也是保护的一种方式
参考图图(D-5-2)
3、校验 `TransactionalCacheManager` 内是否存在缓存若有返回,无则继续委托查询,而委托通常就是 `D-3`中的`SimpleExecutor`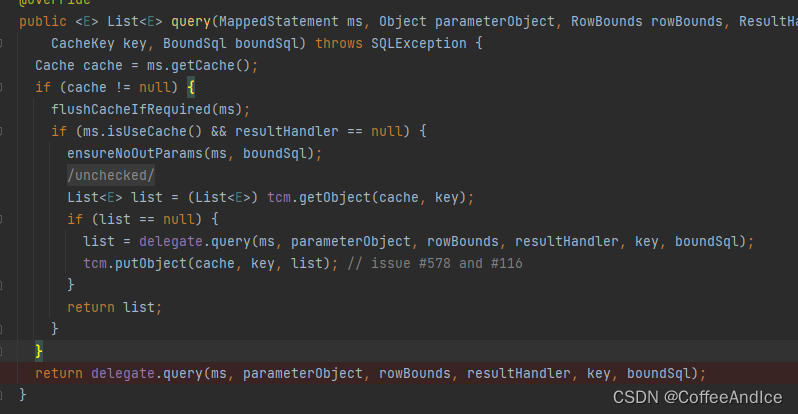
(图D-5-5.1-1)
ensureNoOutParams
这里主要是防止一些调用函数出现在缓存中,避免执行到一些
超乎意料的内容发生,通常是函数和存储语句
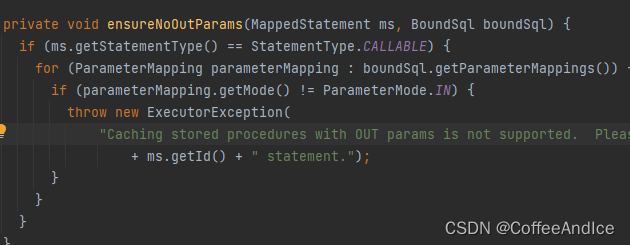
(图D-5-5.1-2)
5.2、SimpleExecutor
这里通常是满足如下其一
1、非缓存开启
2、缓存无法满足后继续委托
Tips:1、值得注意的是,这里由于
SimpleExecutor并未实现query方法,还是回归到BaseExecutor2、通常执行器内都是依赖于sqlsession,也称之为
一级缓存
markdown
# 由上至下
##
1、检测执行器是否被关闭
2、校验是否为顶层查询 并且配置了刷新缓存要求。(这里默认回是false)
3、校验是否存在结果处理器
3.1、如果存在,则继续调用数据库。
3.2、否则校验是否存在调用函数`handleLocallyCachedOutputParameters`
尝试将参数防止到 执行器缓存内
4、然后尝试从数据库获取内容`queryFromDatabase`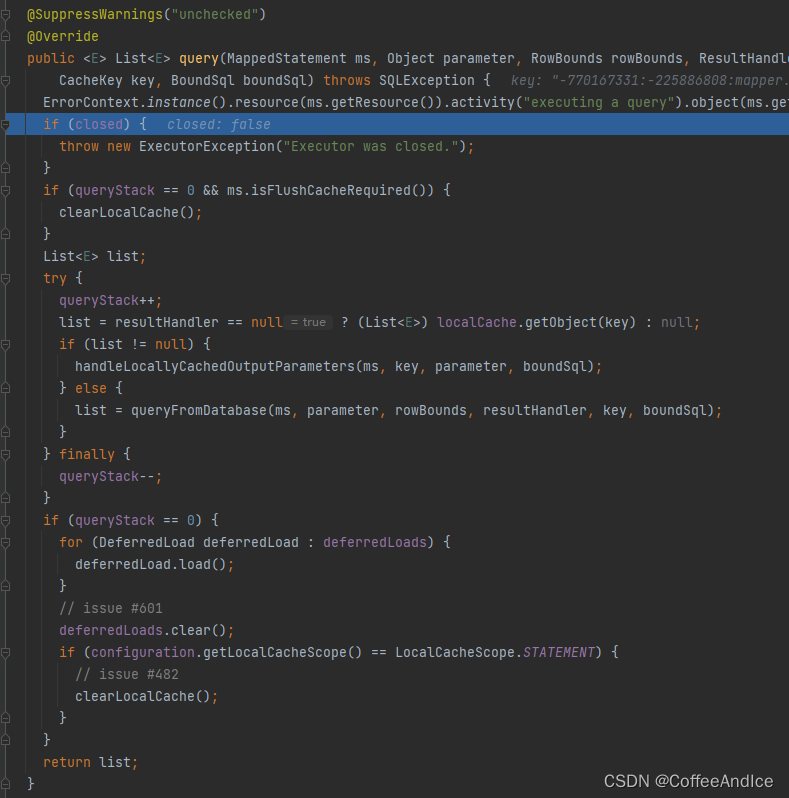
(图D-5-5.2-1)

(图D-5-5.2-2)
6、执行器开始查数据
这里很简洁。
为缓存设置一个设定的
key作为执行标识。1、针对本地缓存。
若执行完美,则为结果值;否则为空
2、针对回调出参类型,则会相应填入回调出参的缓存内。

(图D-6-1)
6.1、doQuery(可插入处理器的地方)
这里开始构建statement处理器。
Tips:通常这个部分就是我们可以对statement魔改的位置

(图D-6-6.1-1)
6.1.1、RoutingStatementHandler
虽然有诸多实现类,但是最后也是通过
RoutingStatementHandler来继续构建。如图(D-6-6.1-3) 这里没有设置的话,其实就是
StatementType.PREPARED,可以参考MappedStatement#Builder
(图D-6-6.1-2)

(图D-6-6.1-3)
6.1.2、PreparedStatementHandler
1、通过驱动器获取连接内容
2、构建
Statement
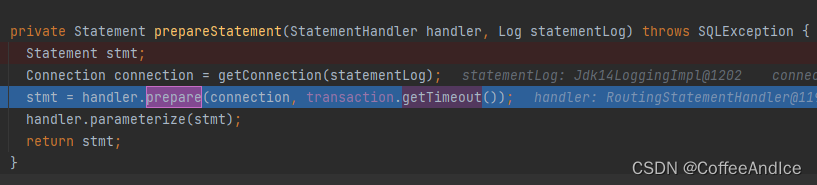
(图D-6-6.2-1)
prepare
1、构建连接实例
这里由于设置是
JdbcTransactionFactory且设置了PooledDataSource因此这里会最终由
JdbcTransaction -> PooledDataSource -> 反射代理构建链接
2、这里承接
6.1.1会是PreparedStatementHandler处理,由于并未实现,所以依旧是BaseStatementHandler处理 跟随图(D-6-6.1-4)2.1、为保错误能被记录的上下文设置。
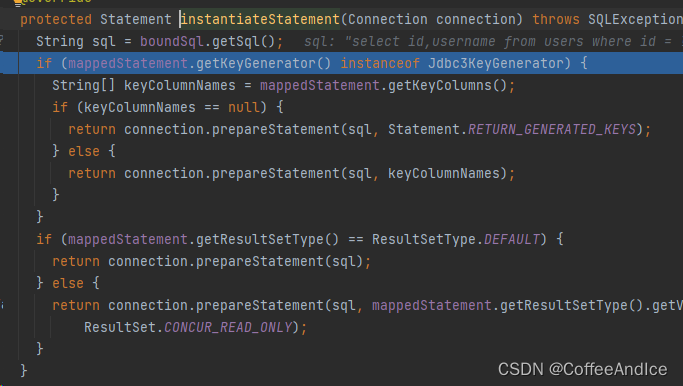
2.2、instantiateStatement
- 移步
(图D-6-6.1-5)
2.2.1、这里就是首先判断是否设置了自增长主键,如果设置了就进入。
(1)设置了keycolumn则返回对应的主键
(2)没有设置则会返回主键的值(如果非自增,这里会返回影响的行数)
这里主要三个实现类:
-1、NoKeyGenerator 没有主键,非插入语句& useGeneratedKeys 默认配置
-2、Jdbc3KeyGenerator 可自增长的主键配置
-3、SelectKeyGenerator 需要协助处理的并非db能自增长的配置2.2.2、这里默认其实都是第一个,传入默认的语句即可。
具体是关于
ResultSetType结果集类型2.3、设置 setStatementTimeout
设置超时时间
2.4、设置setFetchSize
设置获取的行数。

(图D-6-6.1-4)
(图D-6-6.1-5)
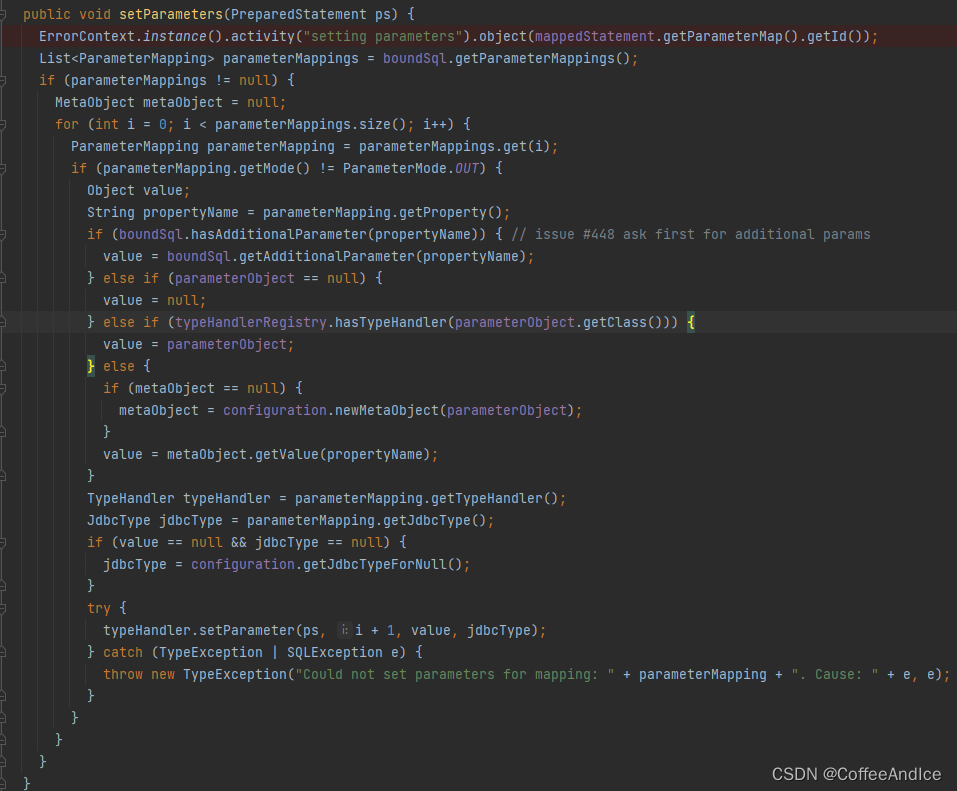
parameterize
对 Statement 进行参数化配置
由于
PreparedStatementHandler并未自己来处理,所以都由BaseStatementHandler实现1、获取全局的配置参数映射
这里可以看到开始配置的
parameterMappings2、这里排除非入参的参数,获取 此次sql所需的参数
这里取参数优先级
从上到下2.1、 如果本来就有参数就直接采用 ,这里是提前赋值的参数
这里可以为类比为
@param注解对应的参数2.2、对比是否为存在的
typeHandlerRegistry处理赋值。2.3、如果是其他类型,则用其类型来获取值
3、设置值到类型sql对应的参数上。
Tips: 这里值得注意的是,若是没有?,最终会再交付到mysql 时触发异常
mysqlParameter index out of range (1 > number of parameters, which is 0).
(图D-6-6.1-6)
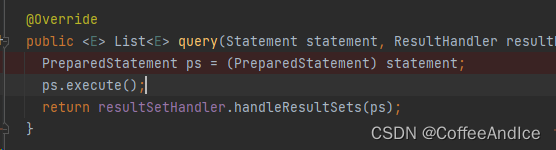
7、整理结果
回归到 图 (D-6-6.1-1),这里实际上还是继续调用
PreparedStatementHandler1、
ps.execute();其实已经交由mysql去执行,直接下一步2、结果处理器,这里默认构建的时候都会创建一个
DefaultResultSetHandler,参考BaseStatementHandler构造器,是调用Configuration#newResultSetHandler,对应图(D7-2)
(图D-7-1)

(图D-7-2)
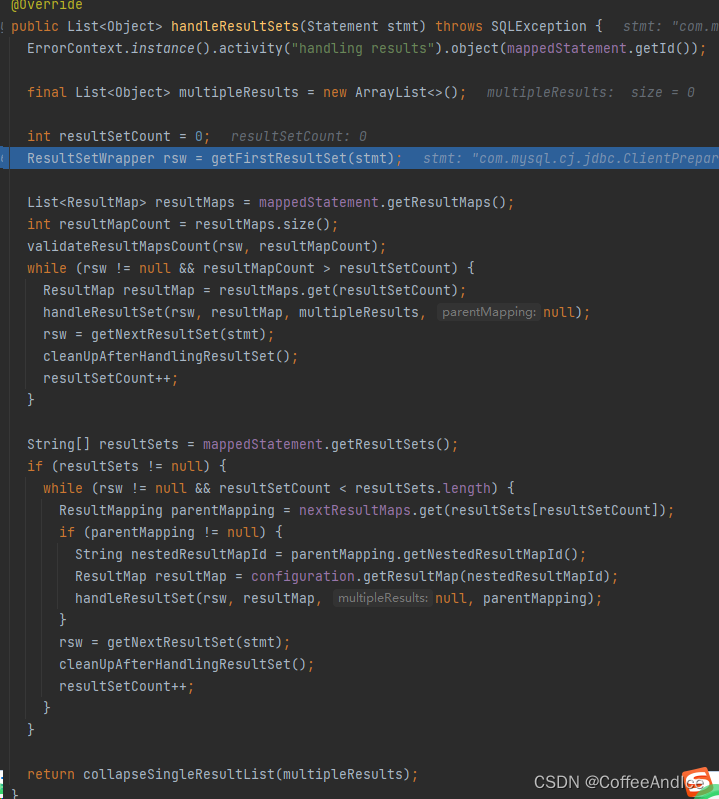
DefaultResultSetHandler
这里其实主要是两个方面
1、
mappedStatement.getResultMaps()部分主要是对结果集直接解析到对象中
2、
mappedStatement.getResultSets();部分主要是处理嵌套结果集的,比如我们mybatis中,的结果套结果的部分
(图D-7-3)
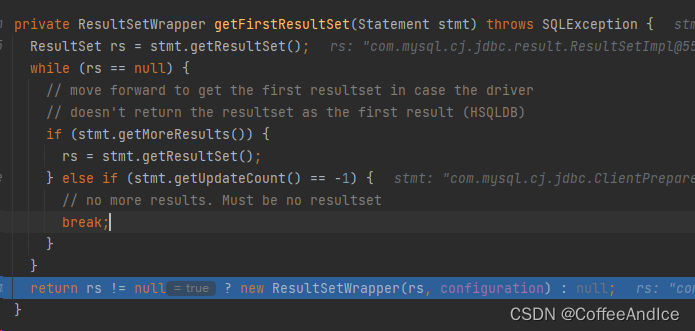
7.1、getFirstResultSet
1、尝试获取结果集
getResultSet这里也提示了the current result as a ResultSet object or null if the result is an update count or there are no more results可能存在没有结果集的情况2、如果为空则尝试获取全部可能的结果集
尝试继续获取结果集
3、获取到结果集后对其赋值解析
参考图 (图D-7.1-2)
根据
columnNames、jdbcTypes、classNames,按照数据的模式填入
ResultSetWrapper中暂存
(图D-7.1-1)

(图D-7.1-2)
7.2、validateResultMapsCount
继续从
mappedStatement.getResultMaps()中获取之前设置的结果映射会从 数据库的结果 和 结果集映射中简单判断下是否设定了内容。

(图D-7.2-1)
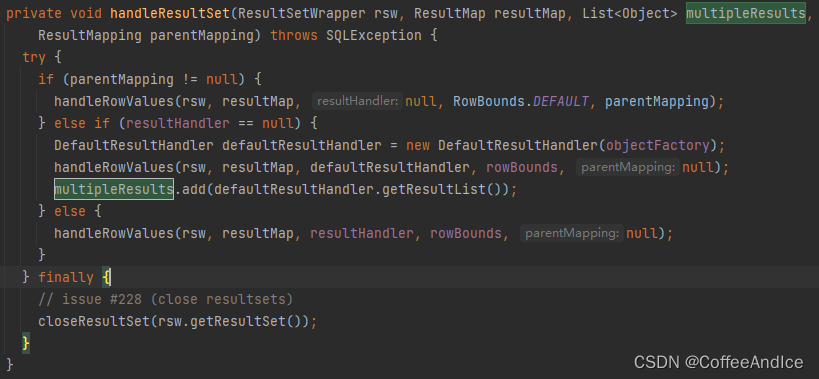
7.3、handleResultSet
这里通常没有设置的情况下,会构建一个默认的
DefaultResultHandler,里面的参数正是构建configuration的默认DefaultObjectFactory这里主要是构建一个
List对象,将对象解析放入。最后释放资源
(图D-7.3-1)
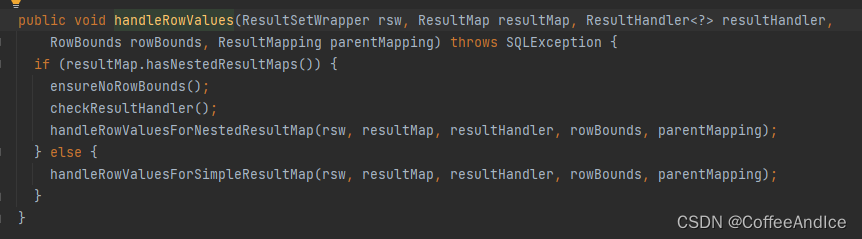
handleRowValues
简单直白,如果有嵌套结果的话继续判断下面
ensureNoRowBounds确保没有行越界,也有有值,方便后续处理
checkResultHandler确保有正确的结果处理器否则直接
handleRowValuesForSimpleResultMap数据库查询返回的行数据映射到一个简单的结果映射对象上,也就是构建的
User对象中最后存储到处理器的
multipleResults中存放起来
(图D-7.3-2)
7.4、cleanUpAfterHandlingResultSet
清空一些嵌套的结果集,主要是不影响后续的内容处理。
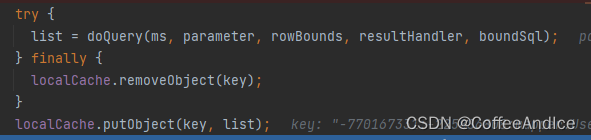
8、回到开始查询的位置
回到 图 (图D-6-1)
首先删除缓存内容,再将结果存放到 一级缓存。
最终递归返回到执行的开始。
(图D-8-1)