什么是 bigkey?
简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
-
String 类型的 value 超过 1MB
-
复合类型(List、Hash、Set、Sorted Set 等)的 value 包含的元素超过 5000 个(不过,对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。

bigkey 判定标准
bigkey 是怎么产生的?有什么危害?
bigkey 通常是由于下面这些原因产生的:
-
程序设计不当,比如直接使用 String 类型存储较大的文件对应的二进制数据。
-
对于业务的数据规模考虑不周到,比如使用集合类型的时候没有考虑到数据量的快速增长。
-
未及时清理垃圾数据,比如哈希中冗余了大量的无用键值对。
bigkey 除了会消耗更多的内存空间和带宽,还会对性能造成比较大的影响。
在 Redis 常见阻塞原因总结1这篇文章中我们提到:大 key 还会造成阻塞问题。具体来说,主要体现在下面三个方面:
-
客户端超时阻塞:由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
-
网络阻塞:每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
-
工作线程阻塞:如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
大 key 造成的阻塞问题还会进一步影响到主从同步和集群扩容。
综上,大 key 带来的潜在问题是非常多的,我们应该尽量避免 Redis 中存在 bigkey。
如何发现 bigkey?
1、使用 Redis 自带的 --bigkeys 参数来查找。
# redis-cli -p 6379 --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' with 4437 bytes
[00.00%] Biggest list found so far '"my-list"' with 17 items
-------- summary -------
Sampled 5 keys in the keyspace!
Total key length in bytes is 264 (avg len 52.80)
Biggest list found '"my-list"' has 17 items
Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' has 4437 bytes
1 lists with 17 items (20.00% of keys, avg size 17.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
4 strings with 4831 bytes (80.00% of keys, avg size 1207.75)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00从这个命令的运行结果,我们可以看出:这个命令会扫描(Scan) Redis 中的所有 key ,会对 Redis 的性能有一点影响。并且,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 String 数据类型,包含元素最多的复合数据类型)。然而,一个 key 的元素多并不代表占用内存也多,需要我们根据具体的业务情况来进一步判断。
在线上执行该命令时,为了降低对 Redis 的影响,需要指定 -i 参数控制扫描的频率。redis-cli -p 6379 --bigkeys -i 3 表示扫描过程中每次扫描后休息的时间间隔为 3 秒。
2、使用 Redis 自带的 SCAN 命令
SCAN 命令可以按照一定的模式和数量返回匹配的 key。获取了 key 之后,可以利用 STRLEN、HLEN、LLEN等命令返回其长度或成员数量。
| 数据结构 | 命令 | 复杂度 | 结果(对应 key) |
|---|---|---|---|
| String | STRLEN | O(1) | 字符串值的长度 |
| Hash | HLEN | O(1) | 哈希表中字段的数量 |
| List | LLEN | O(1) | 列表元素数量 |
| Set | SCARD | O(1) | 集合元素数量 |
| Sorted Set | ZCARD | O(1) | 有序集合的元素数量 |
对于集合类型还可以使用 MEMORY USAGE 命令(Redis 4.0+),这个命令会返回键值对占用的内存空间。
3、借助开源工具分析 RDB 文件。
通过分析 RDB 文件来找出 big key。这种方案的前提是你的 Redis 采用的是 RDB 持久化。
网上有现成的代码/工具可以直接拿来使用:
-
redis-rdb-tools2:Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
-
rdb_bigkeys3 : Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
4、借助公有云的 Redis 分析服务。
如果你用的是公有云的 Redis 服务的话,可以看看其是否提供了 key 分析功能(一般都提供了)。
这里以阿里云 Redis 为例说明,它支持 bigkey 实时分析、发现,文档地址:https://www.alibabacloud.com/help/zh/apsaradb-for-redis/latest/use-the-real-time-key-statistics-feature 。
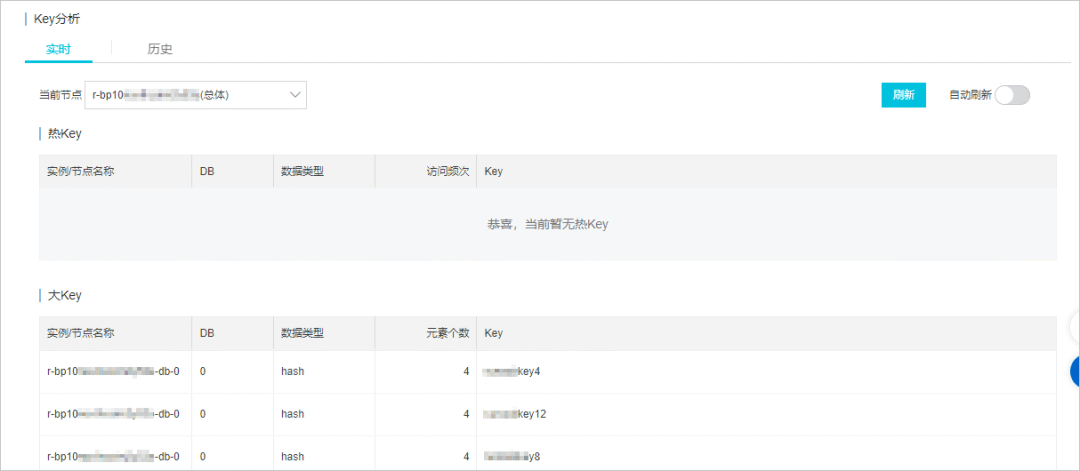
阿里云Key分析
如何处理 bigkey?
bigkey 的常见处理以及优化办法如下(这些方法可以配合起来使用):
-
分割 bigkey:将一个 bigkey 分割为多个小 key。例如,将一个含有上万字段数量的 Hash 按照一定策略(比如二次哈希)拆分为多个 Hash。
-
手动清理 :Redis 4.0+ 可以使用
UNLINK命令来异步删除一个或多个指定的 key。Redis 4.0 以下可以考虑使用SCAN命令结合DEL命令来分批次删除。 -
采用合适的数据结构:例如,文件二进制数据不使用 String 保存、使用 HyperLogLog 统计页面 UV、Bitmap 保存状态信息(0/1)。
-
开启 lazy-free(惰性删除/延迟释放) :lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
JavaGuide 开源版 :javaguide.cn(已经维护五年,138k+ star,Java 面试指南)
JavaGuide 面试专版 :《Java 面试指北 》 (质量很高,专为面试打造,配合 JavaGuide 食用)