一、概念
1.概述
(1)Hive是一个构建于Hadoop顶层的数据仓库工具。
(2)某种程度上可以看作是用户编程接口,本身不存储和处理数据。
(3)依赖分布式文件系统HDFS存储数据。
(4)依赖分布式并行计算模型MapReduce处理数据。
(5)定义了简单的类SQL 查询语言------HiveQL。
(6)用户可以通过编写的HiveQL语句运行MapReduce任务。
(7)Hive需要把HiveQL语句转换成MapReduce任务进行运行。
(8)Hive具有的特点非常适用于数据仓库。
(9)是一个可以提供有效、合理、直观组织和使用数据的模型。
2.联系:
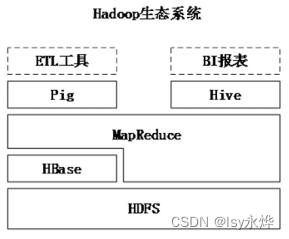
(1)Hive依赖于HDFS 存储数据。
(2)Hive依赖于MapReduce 处理数据。
(3)Pig可以作为Hive的替代工具
pig是一种数据流语言和运行环境,适合用于查询半结构化数据集。常用于ETL过程的一部分,即将外部数据装载到Hadoop集群中,然后转换为用户期待的数据格式。
(4)HBase 提供数据的实时访问,而Hive只能处理静态数据,主要是BI报表数据,所以HBase与Hive的功能是互补的。
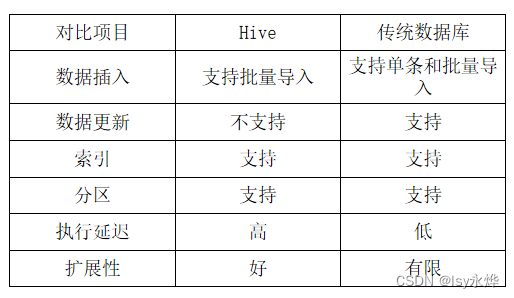
3.Hive与传统数据库的对比
4.Hive组成模块
(1)用户接口模块
(2)驱动模块:包括编译器、优化器、执行器等。
(3)元数据存储模块(Metastore):是一个独立的关系型数据库,通常是与MySQL数据库连接后创建的一个MySQL实例,也可以是Hive自带的derby数据库实例。
二、习题
1.判断题 (1分)
Hive中的元数据存储模块是一个独立的关系型数据库。( )
正确答案: 正确
2.判断题 (1分)
Hive需要把HiveQL语句转换成MapReduce任务进行运行。( )
正确答案: 正确
3.判断题 (1分)
传统的数据库提供分区功能来改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率。Hive不支持分区功能,不使用分区使用索引可以加快数据的查询速度。( )
正确答案: 错误
Hive支持分区功能
4.判断题 (1分)
Hive同时支持导入单条数据和批量数据。( )
正确答案: 错误
5.判断题 (1分)
Hive是一个构建于Hadoop顶层的数据仓库工具,本身不存储和处理数据。( )
正确答案: 正确