sql
UPDATE grid_metric_group_schema t1
JOIN temp_grid_metric_schema_0123 t2 ON t1.api_id = t2.api_id
SET t1.name_for_model = t2.name_for_model, t1.parameters = t2.parameters, t1.examples = t2.examples, t1.filter_examples = t2.filter_examples, t1.description_for_model = t2.description_for_model, t1.keyphrases = t2.keyphrases, t1.name_for_human = t2.name_for_human , t1.id = REPLACE(UUID(), '-', '')在执行这样一段代码时,发现grid_metric_group_schema表中的id字段生成的值都是一样的,如下图所示,然后迅速定位到UUID()函数上,在想是不是UUID()函数只调用了一次把所有记录行赋成一个值了,但仔细一看其实可以发现每个id都是不一样的,只不过相似度很高。
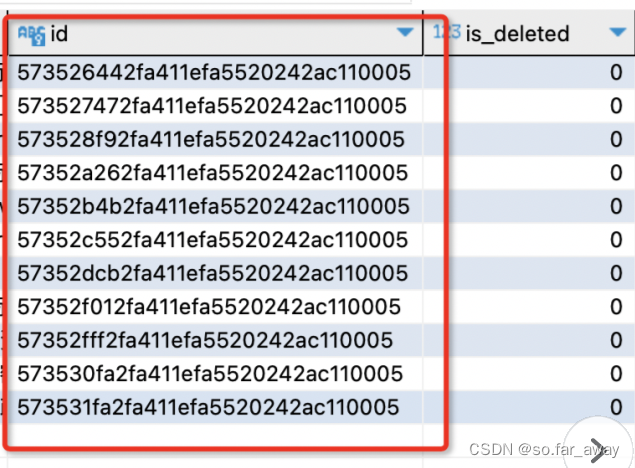
趁机了解了一下MySQL中的UUID()函数,首先可以确定的是,UUID()生成的uuid值是字符串类型的,固定长度为36个字符(包含4个"-"字符),并且是唯一的,同一个SQL语句中多处调用UUID()函数得到的随机值不同,不会存在重复问题,一般来说,MySQL中使用uuid的方式是这样的REPLACE(UUID(), '-', ''),把"-"字符给去掉构成固定长度为32的字符串。
从构成上讲,UUID()生成的随机值由5个部分组成(8-4-4-4-12),分隔符为中划线,前三部分是由时间戳换算过来的,第四部分是暂时性保持时间戳的一致性,每次重新启动MySQL服务时发生变化,第五部分用于保证空间唯一性,可以简单理解为"只要是同一台机器,就不会发生变化"。
一了解uuid的构成,就可以明白为什么在进行批量插入或者更新操作的时候,UUID()生成的字符串相似度很高,后两部分不用说了就是一致的,前三部分只有很细微的差别,这是因为批量操作在同一时间段进行,时间戳差异很小,所以最终呈现的效果就是生成的uuid相似度很高。
虽然生成的uuid都是唯一的,但是如何保证它们看起来差异也很大呢?
可以考虑使用MD5()函数,可以简单地将它理解为一种哈希函数,它的生成结果是长度固定位32的字符串,刚好和去掉中划线的uuid的字符长度一致,具体用法就是:MD5(UUID())。
但既然是哈希函数,就一定会有哈希冲突,不过这只会在数据量很大的时候才会发生,我这里维护的数据库表数据量都很小,所以就无需过多关注这个问题。
说到底,其实uuid已经可以保证唯一了,MD5()在某种程度上甚至破坏了uuid原有的序列含义,保证了低相似性的同时也破坏了唯一性,MD5()也很难保证安全性。