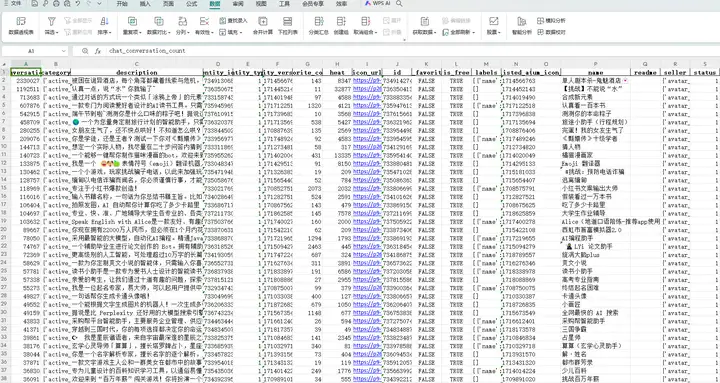
动态加载页面,返回json数据:
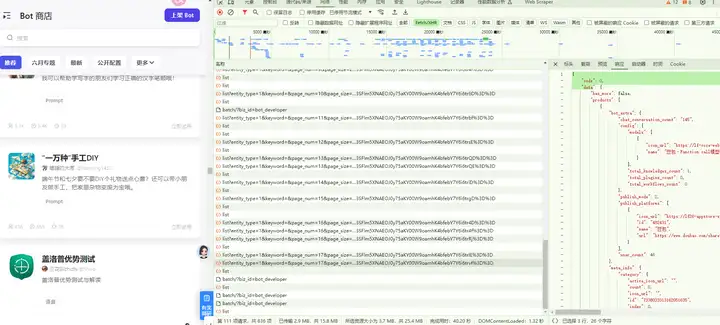
翻页规律:
这两个URL在多个方面有所不同,主要差异如下:
- **查询参数(Query Parameters)**:
- 第一个URL的查询参数包括:
- `entity_type=1`
- `keyword=`(空值)
- `page_num=16`
- `page_size=24`
- `sort_type=1`
- `source=1`
- `msToken=8_renFdIfix-XVFJAqAj8F_gSPv1V5A8NX_iL2teO45SBxvZye4AXZv4JiFygZVTPs2LVqZg0CowxYQ9sdwwkxHC3lR41AkwQGefhQr32f7YVvrrl1PS9L1SC_ftRvg%3D`
- `a_bogus=x7Rh%2FQgXmDIpvfLh55KLfY3qV4a3Y0Iy0SVkMDheeV3Rdg39HMO19exYKsJvjk6jNs%2FDIeEjy4hbYpcQrQcnM1wf7Wsx%2F2CZmyh0t-P2so0j53intL6mE0hN-Jj3SFlm5XNAEOJ0y75aKY00W9oamhK4bfebY7Y6i6trRj%3D%3D`
- 第二个URL的查询参数包括:
- `entity_type=1`
- `keyword=`(空值)
- `page_num=1`
- `page_size=24`
- `sort_type=1`
- `source=1`
- `msToken=8_renFdIfix-XVFJAqAj8F_gSPv1V5A8NX_iL2teO45SBxvZye4AXZv4JiFygZVTPs2LVqZg0CowxYQ9sdwwkxHC3lR41AkwQGefhQr32f7YVvrrl1PS9L1SC_ftRvg%3D`
- `a_bogus=x7Rh%2FQgXmDIpvfLh55KLfY3qV4a3Y0Iy0SVkMDheeV3Rdg39HMO19exYKsJvjk6jNs%2FDIeEjy4hbYpcQrQcnM1wf7Wsx%2F2CZmyh0t-P2so0j53intL6mE0hN-Jj3SFlm5XNAEOJ0y75aKY00W9oamhK4bfebY7Y6i6trRj%3D%3D`
主要区别在于`page_num`参数,第一个URL中`page_num=16`,而第二个URL中`page_num=1`。这意味着第一个URL请求的是第16页的数据,而第二个URL请求的是第1页的数据。
- **URL编码**:
- 两个URL中的查询参数值都是经过URL编码的,以确保特殊字符(如空格、%、&等)能够正确传输。
总结来说,这两个URL的主要区别在于请求的数据页数不同,第一个URL请求第16页的数据,而第二个URL请求第1页的数据。其他参数如`entity_type`, `keyword`, `page_size`, `sort_type`, `source`, `msToken`, 和 `a_bogus` 在两个URL中都是相同的。
返回的json数据如下:
{
"code": 0,
"data": {
"has_more": false,
"products": [
{
"bot_extra": {
"chat_conversation_count": "145",
"config": {
"models": [
{
"icon_url": "https://lf-coze-web-cdn.coze.cn/obj/coze-web-cn/MODEL_ICON/doubao.png",
"name": "豆包·Function call模型"
}
],
"total_knowledges_count": 1,
"total_plugins_count": 0,
"total_workflows_count": 0
},
"publish_mode": 2,
"publish_platforms": [
{
"icon_url": "https://lf26-appstore-sign.oceancloudapi.com/ocean-cloud-tos/FileBizType.BIZ_BOT_ICON/4383119973291048_1700223103089819298.jpeg?lk3s=60aae199\u0026x-expires=1718792155\u0026x-signature=FlRwUZl%2FOoBKUwJHWskM5skN4xs%3D",
"id": "482431",
"name": "豆包",
"url": "https://www.doubao.com/share?botId=7356440225838841908"
}
],
"user_count": 46
},
"meta_info": {
"category": {
"active_icon_url": "",
"count": 0,
"icon_url": "",
"id": "7338033313162051635",
"index": 0,
"name": "角色"
},
"description": "非遗小贴士是一名资深的非物质文化遗产研究学者,能够为用户提供目录查询、详细信息查询以及相关的文化历史背景介绍。通过使用工具搜索相关信息,去除冗余信息并以通俗易懂的方式回答用户问题,让用户更好地了解中国各地的非物质文化遗产。",
"entity_id": "7356440225838841908",
"entity_type": 1,
"entity_version": "1712825279218",
"favorite_count": 7,
"heat": 0,
"icon_url": "https://p26-flow-product-sign.byteimg.com/tos-cn-i-13w3uml6bg/9a23cfb384944811aafa4bee236071c3~tplv-13w3uml6bg-resize:128:128.image?rk3s=2e2596fd\u0026x-expires=1721380555\u0026x-signature=Rpy50nvNyEe2WZIN6NY2Apen5XQ%3D",
"id": "7356526186891149324",
"is_favorited": false,
"is_free": true,
"labels": \[\],
"listed_at": "1712825280",
"medium_icon_url": "",
"name": "非遗小贴士",
"readme": "",
"seller": {
"avatar_url": "https://p9-passport.byteacctimg.com/img/mosaic-legacy/3796/2975850990~300x300.image",
"id": "0",
"name": "dingansich"
},
"status": 1,
"user_info": {
"avatar_url": "https://p9-passport.byteacctimg.com/img/mosaic-legacy/3796/2975850990~300x300.image",
"name": "用户514055857025",
"user_id": "0",
"user_name": "dingansich"
}
}
},
在deepseek中输入提示词:
你是一个Python编程专家,完成一个Python脚本编写的任务,具体步骤如下:
在F盘新建一个Excel文件:cozeaiagent20240619.xlsx
请求网址:
https://www.coze.cn/api/marketplace/product/list?entity_type=1&keyword=&page_num={pagennumber}&page_size=24&sort_type=1&source=1&msToken=8_renFdIfix-XVFJAqAj8F_gSPv1V5A8NX_iL2teO45SBxvZye4AXZv4JiFygZVTPs2LVqZg0CowxYQ9sdwwkxHC3lR41AkwQGefhQr32f7YVvrrl1PS9L1SC_ftRvg%3D&a_bogus=Oym0QfzDdidpDfL655KLfY3qVVa3Y0Ia0SVkMDhe5n3Rt639HMY79exYKs0vM-WjNs%2FDIeEjy4hbYpcQrQcnM1wf7Wsx%2F2CZmyh0t-P2so0j53intL6mE0hN-Jj3SFlm5XNAEOJ0y75aKY00W9oamhK4bfebY7Y6i6trvf%3D%3D
请求方法:
GET
状态代码:
200 OK
{pagenumber}的值从1开始,以1递增,到17结束;
获取网页的响应,这是一个嵌套的json数据;
获取json数据中"data"键的值,然后获取其中"products"键的值,这是一个json数据;
提取这个json数据中 "bot_extra"键的值,然后获取其中"chat_conversation_count"键的值,作为chat_conversation_coun,写入Excel文件的第1列;
提取这个json数据中"meta_info"键的值,这是一个json数据,提取这个json数据中所有的键写入Excel文件的标头(从第2列开始),提取这个json数据中所有键对应的值写入Excel文件的列(从第2列开始);
保存Excel文件;
注意:每一步都输出信息到屏幕;
每爬取1页数据后暂停5-9秒;
需要对 JSON 数据进行预处理,将嵌套的字典和列表转换成适合写入 Excel 的格式,比如将嵌套的字典转换为字符串;
在较新的Pandas版本中,append方法已被弃用。我们应该使用pd.concat来代替。
要设置请求标头:
请求标头:
Accept:
application/json, text/plain, */*
Accept-Encoding:
gzip, deflate, br, zstd
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8
Agw-Js-Conv:
str
Priority:
u=1, i
Referer:
Sec-Ch-Ua:
"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"
Sec-Ch-Ua-Mobile:
?0
Sec-Ch-Ua-Platform:
"Windows"
Sec-Fetch-Dest:
empty
Sec-Fetch-Mode:
cors
Sec-Fetch-Site:
same-origin
Traceparent:
03-8de266a364bfbd7d249c9595eec2c7ac-007656cd2d801cbd-01
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36
X-Requested-With:
XMLHttpRequest
程序运行,数据爬取下来了,但是有些问题,没有正确写入Excel列,让deepseek修正:
程序把"meta_info"这个json数据中所有的内容写入Excel第2行的,我希望的是把"meta_info"这个json数据中所有的键写入第2行、第3行等的表头,所有键的值写入第2行、第3行。。。
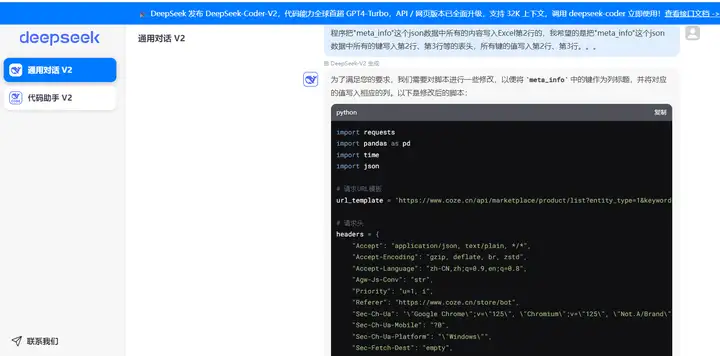
import requests
import pandas as pd
import time
import json
请求URL模板
url_template = "https://www.coze.cn/api/marketplace/product/list?entity_type=1&keyword=&page_num={}&page_size=24&sort_type=1&source=1&msToken=8_renFdIfix-XVFJAqAj8F_gSPv1V5A8NX_iL2teO45SBxvZye4AXZv4JiFygZVTPs2LVqZg0CowxYQ9sdwwkxHC3lR41AkwQGefhQr32f7YVvrrl1PS9L1SC_ftRvg%3D&a_bogus=Oym0QfzDdidpDfL655KLfY3qVVa3Y0Ia0SVkMDhe5n3Rt639HMY79exYKs0vM-WjNs%2FDIeEjy4hbYpcQrQcnM1wf7Wsx%2F2CZmyh0t-P2so0j53intL6mE0hN-Jj3SFlm5XNAEOJ0y75aKY00W9oamhK4bfebY7Y6i6trvf%3D%3D"
请求头
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Agw-Js-Conv": "str",
"Priority": "u=1, i",
"Referer": "https://www.coze.cn/store/bot",
"Sec-Ch-Ua": "\"Google Chrome\";v=\"125\", \"Chromium\";v=\"125\", \"Not.A/Brand\";v=\"24\"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "\"Windows\"",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"Traceparent": "03-8de266a364bfbd7d249c9595eec2c7ac-007656cd2d801cbd-01",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
创建Excel文件
file_path = "F:/cozeaiagent20240619.xlsx"
df = pd.DataFrame(columns="chat_conversation_count")
遍历页码
for page_number in range(1, 18):
url = url_template.format(page_number)
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
products = data'data''products'
for product in products:
chat_conversation_count = product'bot_extra''chat_conversation_count'
meta_info = product'meta_info'
meta_info_keys = list(meta_info.keys())
meta_info_values = list(meta_info.values())
new_data = pd.DataFrame({
"chat_conversation_count": chat_conversation_count,
})
for key, value in zip(meta_info_keys, meta_info_values):
new_datakey = value
df = pd.concat(df, new_data, ignore_index=True)
print(f"Page {page_number} processed.")
else:
print(f"Failed to retrieve data from page {page_number}. Status code: {response.status_code}")
暂停5-9秒
time.sleep(5 + (page_number % 5))
保存Excel文件
df.to_excel(file_path, index=False)
print(f"Data saved to {file_path}")