目录
1、kafka简介
kafka是基于scala语言开发的分布式消息队列,具备高吞吐,高性能,高可靠的特点,同时可持久化,可水平扩展、支持流数据处理;同时kafka在系统架构层面能够将业务消息生产系统与业务消息消费系统进行解耦合处理,降低消息消费系统对上游系统的数据读取影响。
2、kafka使用场景
- 消息传输
- 网站行为日志追踪
- 审计数据收集
- 日志收集
- event sourcing
- 流式处理
3、kafka基础概念
3.1、消息
3.1.1、消息构成详解
kafka的消息是kafka存储数据的具体载体,kafka的消息格式由很多字段构成,其中很多字段用于管理消息的元数据字段,对用户是完全透明的。kakfa消息格式经过3次变迁,分别被称为V0、V1、V2版本,目前大部分用户使用的应该还是V1版本的消息格式。V1版本的消息格式如下图所示:

消息 = 消息头部 + key + value
【消息头部】:包含消息的CRC码、消息版本号、消息属性、消息时间戳、键长度、消息体长度
【CRC码】:循环冗余校验码,是一种错误检测编码,用于检测数据传输或存储过程是否发生错误
【消息版本号】:V0、V1、V2,代表不同的消息体组织形式
【属性】:占位1字节,使用低3位保存消息的压缩类型,其余5位尚未使用。当前只支持4种压缩类型:0(无压缩)、1(GZIP)、2(Snappy)、3(LZ4)
【时间戳】:保存消息的发送时间戳,用于流式处理以及其他依赖时间的处理语音,如果不指定则取当前时间
【key】:消息键,对消息做partition使用,即决定消息被保存在某topic下的哪个partition
【value】:消息体,保存实际的消息数据
3.1.2、消息存储设计
kafka采用紧凑的二进制字节数组来保存上面这些字段,也就是说没有任何多于的byte位浪费。kafka做所以没有使用java对象保存上面的消息格式是因为:
java内存模型(java memory model,即JMM)中,对象保存开销相当巨大,对于小对象而言,通常要花费2倍的空间来保存数据(甚至更糟)。另外随着堆上的数据量越来越大,GC的性能会下降很多,从而整体上拖慢系统的吞吐量。尽管JMM会对java类进行优化,比如重排各个字段的内存布局以及减少内存使用量,但是对于kafka的消息实例依然需要消耗40个字节左右,而且其中有7个字节只是为了补齐。同时由于java的操作系统通常默认开启了页缓存机制,也就是说堆上保存的对象很有可能在页缓存中还保留有一份,造成了极大的资源浪费。所以kakfa在消息设计的时候避开了繁重的java堆上内存分配,直接使用紧凑二进制字节数组bytebuffer而不是独立对象。因此至少能够访问多一倍的可用内存。同时大量使用页缓存而非堆内存还有一个好处:当出现kafka broker崩溃时,堆内存上的数据也一并小时,但页缓存的数据依然存在。broker重启后可以继续提供服务,不需要再单独热缓存。
3.2、topic
topic是kafka中的主题,是一个逻辑概念,代表了某一类消息,也有人把topic理解为某类文本形式存储的业务数据表。
3.3、partition
kafka中的topic通常会被多个消费者订阅,因此出于性能的考量,kafka并不是topic-message的两级结构,而是采用了topic-partition-message的三级结构来分散负载,从本质上说每一个topic都有若干个partition构成。即topic由parition构成,partition由不能被修改的有序消息序列构成,所以parition可以说是有序的消息日志。
kafka的partition没有实际业务含义,partition的引入纯粹是为了提升系统的吞吐量,因此在创建topic时可以根据集群实际配置设置具体的partition数,实现整体性能的最大化。

3.4、offset
topic partition中的每一条消息记录都被分配一个位移值,该位移值是从0开始顺序递增的整数,位移信息可以唯一定位到paritition下的一条消息。 通过<topic,partiton,offset>可以唯一的定位一条消息

3.5、replication
3.5.1、replication简介
为了保证高可靠性,kafka采用了副本备份存储消息机制,副本存在的唯一目的就是放置数据丢失。副本面向的对象是partition,而不是面向具体的消息。在kafka中,replication分为两类:leader replication和follower replication。
3.5.2、副本角色
副本角色可以分为:leader和follower
leader副本面向客户端请求,为客户端提供消息读取以及消息写入服务;
follower副本不对客户端开放,仅被动的从leader副本中获取数据,follower的唯一价值就是充当leader的候补。一旦leader副本宕机,kafka便会从剩余副本中选举新的leader提供服务。kafka保证同一个partition的多个replication一定不会分布在同一个broker上,保证某个broker节点宕机,一定可以从其他broker中获取服务。
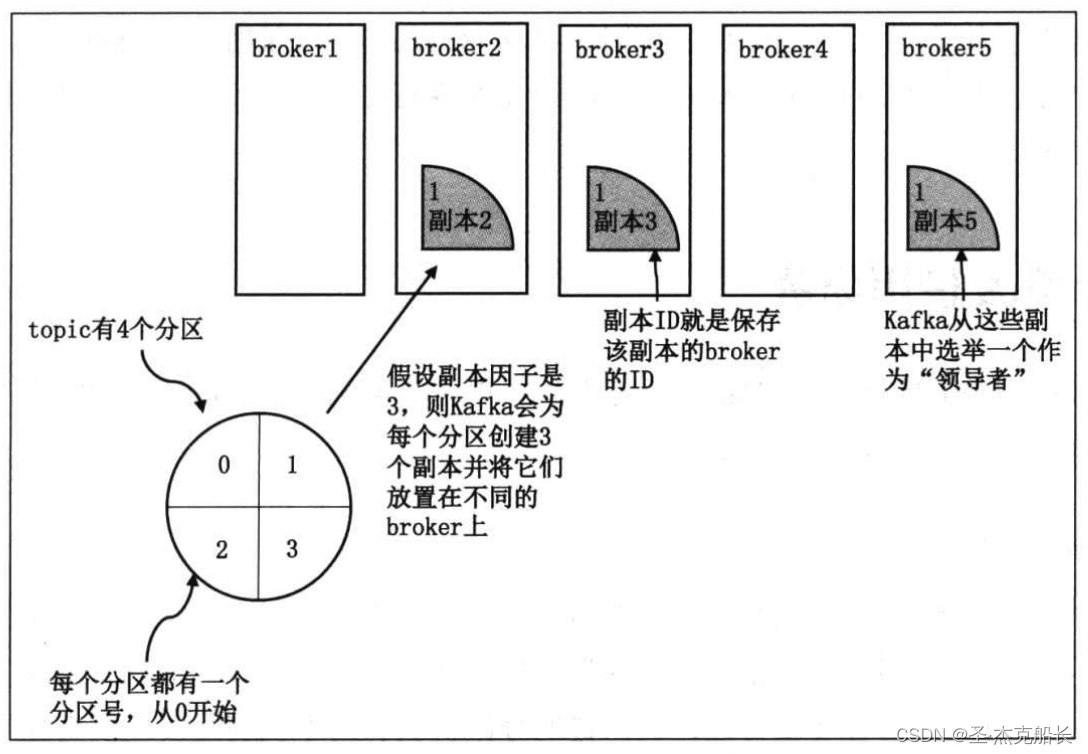
3.5.3、副本类型
3.5.3.1、副本类型简介
根据follower与leader副本的消息同步状态可以将副本分为:ISR与OSR
【AR】:所有副本
【ISR】:副本同步队列
【OSR]:副本掉队队列
AR = ISR + OSR
3.5.3.2、ISR简介
ISR的全称是in-sync replication,即与leader replication保持同步的replication集合,kafka为partition动态维护一个replication集合。该集合中的所有replication保存的消息日志都与leader replication保持同步状态,只有这个集合中的replcaition才能被选举为leader,也只有该集合中的所有replication都接收到同一条消息,kafka才会将该消息置为已提交状态,即认为消息发送成功。kafka承诺只要这个集合中至少存在一个replication,那些"已提交"状态的消息就不会丢失。
3.5.3.3、ISR伸缩维护机制
正常情况下,partition的所有replication都应该与leader replication保持同步,即所有replication都在ISR中,因为各种各样的原因,一小部分replication开始落后于leader replication的进度。当滞后到一定程度,kafka会将这些replication剔出ISR列表,被踢出的副本会被放入OSR队列中,当被踢出的replication重新追上leader replication进度时,kafka会将他们从OSR中加回到ISR中。这一切都是自动维护的,不需要用户进行人工干预。
3.5.3.4、ISR伸缩判定条件
kafka采用replica.lag.time.max.ms和replica.lag.max.messages两项配置监控时延;时延大于配置即会把broker剔除ISR列表,放入OSR列表中;时延小于配置即会把broker加入ISR列表