开发环境搭建
克隆
git clone https://github.com/cmu-db/bustub.git
cd bustub/
切换分支
git checkout -b branchname v20221128-2022fall
创建docker镜像
docker build . -t bustub_img
创建容器
docker create -it --name bustub_container -v "E:/cmu/bustub":"/bustub" bustub_img bash
启动容器
docker start -ia bustub_container
查看有哪些已经启动的容器
docker ps
进入指定容器
docker exec -it 30eb49a811aa /bin/bash
Project0
编译
在/bustub/build生成makefile:cmake ...
报错:CMake Warning at CMakeLists.txt:47 (message):!! We recommend that you use clang-12 for developing BusTub. You're using
GNU 11.4.0, which is not clang.
解决:在主目录的CMakeLists下增加2行 set(CMAKE_C_COMPILER "/usr/bin/clang-12")set(CMAKE_CXX_COMPILER "/usr/bin/clang+±12")
或者:加编译选项:-DCMAKE_C_COMPILER=usr/bin/clang-12和-DCMAKE_CXX_COMPILER=/usr/bin/clang+±12
设置失效:ctrl+ship+p cmake配置 选择clang-12,然后重新打开一个终端
编译:make starter_trie_test
调试
launch.json
cpp
{
"version": "0.2.0",
"configurations": [
{
"type": "lldb",
"request": "launch",
"name": "Debug",
"program": "${workspaceFolder}/build/test/starter_trie_test",
"args": [],
"cwd": "${workspaceFolder}",
"preLaunchTask": "make starter_trie_test"
},
]
}make starter_trie_test任务:这里使用-C指定makefile文件的路径在当前目录的build目录下
cpp
{
"version": "2.0.0",
"tasks": [
{
"type": "shell",
"label": "make starter_trie_test",
"command": "make",
"args": [
"-C",
"build",
"starter_trie_test"
]
}
]
}Project1:缓冲池管理器
task1:可扩展哈希
目录大小:2^全局深度
全局深度: 取元素的低多少位 进行分类,放入不同的桶中
桶的局部深度:当有其它桶进行分裂使得目录扩张(全局深度增加),会导致未分裂的桶局部深度低于全局深度。这种情况下,如果该桶发生溢出,那么只进行桶分裂,全局深度不增加。
全局深度>局部深度 发生桶溢出时:只分裂不扩张 全局深度=局部深度 发生桶溢出时:既分裂又扩张
关键:扩张是把所有桶全部尾插到目录中,桶分裂时使用局部深度形成的掩码来找到指向当前桶的所有idx,将它们重新指向新的桶
,最后重新分配当前桶中的所有元素。
task2: LRU-K替换策略
-
力扣146.LRU缓存
std::list<std::pair<int,int>> ls;//k,v
std::unordered_map<int, decltype(ls.begin())> lru_map;//k,list
get:要将查看的这个key再次put
put:先判断put的key是否已经存在,如果已经有了,就将当前旧的key删除,重新插入到头部。
-
LRU-K
cppstd::list<std::pair<frame_id_t, Frameinfo>> ls1;//frame_id 访问次数 std::list<std::pair<frame_id_t, Frameinfo>> ls2;//frame_id 访问次数 //使用map,可以O(1)时间复杂度 根据frame_id直接访问到list上各页面的访问次数 //同时,可以直接操作list节点进行移动 std::unordered_map<frame_id_t, decltype(ls1.begin())> m;//frame_id list1/list2的迭代器使用map保存{frame_id:list迭代器},就可以通过frame_id直接找到链表上的该页面对应信息,使用如下Frameinfo结构体保存每个页的信息。
struct Frameinfo { size_t visits = 0;//访问次数 bool evictable_{false};//是否可驱逐 };
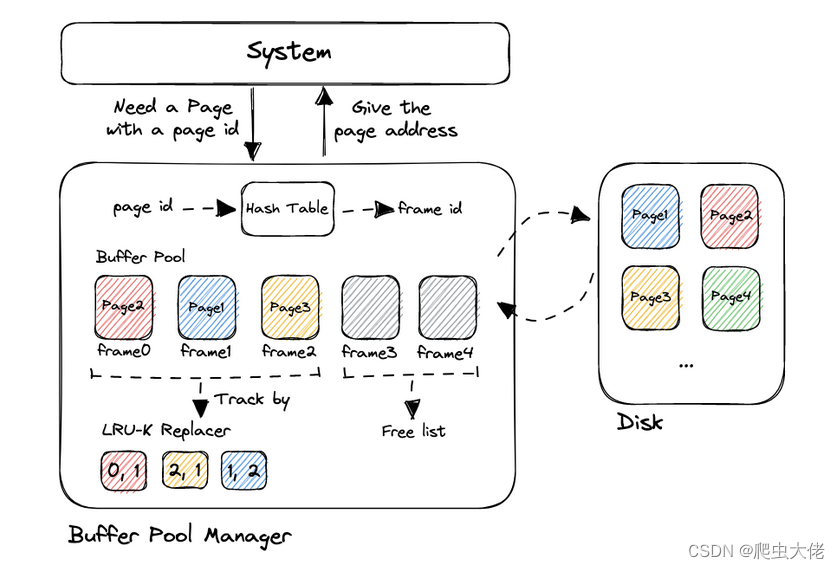
task3:缓冲池管理器
功能:系统向缓冲池管理器请求某指定page_id的页面,缓冲池管理器经过一系列操作,返回页面在内存中的地址。
具体操作:先在可拓展哈希中找该页面,可拓展哈希的list中存储的是(page_id,frame_id),根据得到的frame id即可在pages_数组中找到该页。如果可拓展哈希中没有该页面,就先看free_list还有没有空位,如果有,直接调用WritePage把Disk上的页面读取到内存,否则先调用LRU-K驱逐一个内存块。
原子变量的使用:
- 由于不允许拷贝,只能使用值初始化
头文件#include
atomic_int m(0);
size_t转int:
static_cast<int>(i)
| 变量 | 意义 |
|---|---|
| page_table_ | 可拓展哈希,保存(page_id,frame_id) |
| replacer_ | LRU-K,主要是在需要驱逐页面时使用,传出frame_id |
| pages_ | 以frame_id为下标,保存所有页面的数组 |
| free_list_ | 保存pages_中空闲页面的frame_id,一开始就被初始化为从0开始的int |
| page | 页面,保存有该页面的page_id,实际数据是一个char数组 |
NewPgImp
在缓冲池中新增一个空白页面,并指定好页面的id。如果free_list已满,就尝试驱逐页面(如果页面是脏,需要写回磁盘),如果都无法驱逐,就返回nullptr
frame_id的获取 :首先检查空闲链表free_list_,如果有空闲frame_id就直接取出一个使用,然后添加新页面信息。如果没有空闲,就驱逐页面得到一个frame_id,然后添加新页面信息。
怎么驱逐页面 :调用Evict得到驱逐页面的frame_id后,需要检查该页是否为脏页,如果是,则需要写回磁盘。此外,还需要把该页信息从可拓展哈希中删除。
怎么添加新页面信息:AllocatePage函数会在定义的next_page_id上依次+1.每次只需要调用它获取新的page_id。由于所有页面都保存在pages_数组中,因此设置pagesframe_id的信息即可。此外,还需要把页面信息写入可拓展哈希和LRU-K
FetchPgImp
读一个页面,先看是不是在缓冲池中,如果不在,需要从磁盘上读入
Project2:B+树
数据库支持多种索引方式:
哈希索引 全文索引 B+树索引
mysql数据库为什么使用B+树作为索引的数据结构
为了加快记录的查找,必须使用索引来避免对全表进行顺序查找。
二叉树:如果数据关键字恰好有顺序,会导致形成特别深的二叉树
平衡二叉树:避免了二叉树中形成线性链表的情况,但一个节点所保存的信息太少,无法有效利用到磁盘预读机制
多路平衡查找树(B树):很好利用了磁盘预读机制,但每个非叶子节点记录自己存储的数据,不利于区间查找,且导致可存储的节点数目大大减少。
B+树:所有数据存储在叶子节点中,且叶子节点被串成有序的双向链表,便于区间查找。关键设计在于,让一个节点的大小恰好等于一个块的大小(4K),这样减少了磁盘IO。内部节点只存储key和维持树形结构的指针,叶子节点只存储key和对应数据。
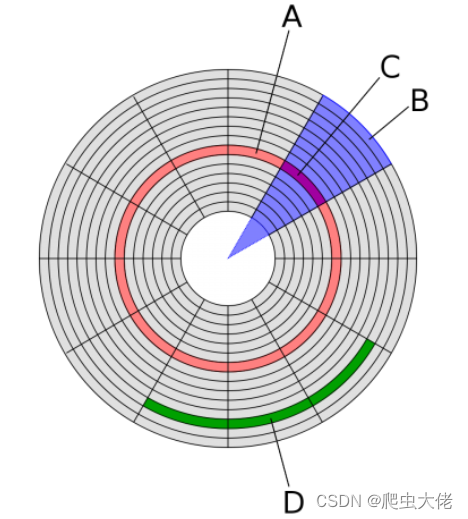
A是磁道,C是扇区,D是磁盘块(簇)由多个扇区组成
区分磁盘预读与cpu预取机制
磁盘预读:由于内存比磁盘的读写速度快,需要尽量减少磁盘IO次数。现在常见磁盘扇区大小为4K个字节,因此每次磁盘读取都至少将1页数据加载进内存。
cpu预取:内存的读写速度太慢,为了减小其与cpu的差距,在cpu内部引入了3级缓存,从内存读取数据时,cpu会试图预取64字节数据到缓存。
对于频繁写而不是频繁读的场景,使用LSM树比B+树更适合:例如日志系统
因为B+树的数据都存储在叶子节点中,叶子节点一般存储在磁盘中。每次写入数据都是要随机写入磁盘。
LSM树简介:至少由2棵树组成,1棵较小,存储在内存中,1棵较大,存储在磁盘中。内存中的树变大到某阈值,就批量写入到磁盘的树中(相当于有序链表的归并)
数据库存储引擎
mysql有2种常用的存储引擎:MyISAM、InnoDB
存储引擎的作用:数据先传输到存储引擎,再按照其规定存储格式保存到数据文件中。
| MyISAM | InnoDB |
|---|---|
| 不支持事务 | 支持事务 |
| 存储速度快 | 存储速度慢些 |
| 不支持外键 | 支持外键 |
InnoDB默认定义的块大小是16KB,即每次磁盘IO,读取数据都是16KB的倍数
柔性数组成员
结构体的最后一个元素可以是大小未定的数组,被称作柔性数组
cpp
#include <iostream>
using namespace std;
struct A
{
int x;//4
int str[];//大小未定
};
int main()
{
cout<<sizeof(A)<<endl;//4
A* p = new A;
for (size_t i = 0; i < 10; i++)
{
p->str[i] = 1;
}
return 0;
}std::lower_bound()和std::upper_bound()
cpp
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main(){
vector<int> num = {1,2,4,7,15,34};
sort(num.begin(), num.end());//从小到大排序
int pos1=lower_bound(num.begin(), num.end(),7)-num.begin(); //返回数组中第一个大于或等于被查数的值
int pos2=upper_bound(num.begin(), num.end(),7)-num.begin(); //返回数组中第一个大于被查数的值
cout<<pos1<<" "<<num[pos1]<<endl;//3 7
cout<<pos2<<" "<<num[pos2]<<endl;//4 15
return 0;
}叶子的查找与非叶子的查找
叶子:0开始找,只有等于和不等于两种情况
非叶子:1开始找(0处没保存值),使用lower_bound查找的最终位置t,如果结果大于当前数,则返回array_t-1,如果等于当前数,则返回array_t+1,如果小于,那么返回array_最后一个元素。
B+树
内部节点的key是其下叶子节点的最小值,
find
对于非叶子节点,