一. CDC与Flink CDC区别:
CDC(Change Data Capture):这是一种技术,用于捕获数据库中的数据变更(例如插入、更新、删除操作),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。CDC通常是通过轮询数据库事务日志或使用数据库特定的触发器来实现的。
Flink CDC(Apache Flink Change Data Capture):Flink是一个流处理引擎,Flink CDC是指利用Apache Flink框架来实现数据变更捕获的技术(即用Apache Flink这个流处理框架来实现CDC的技术)。FlinkCDC是一个开源的数据库变更日志捕获和处理框架,它可以实时地从各种数据库(如MySQL、PostgreSQL、Oracle、MongoDB等)中捕获数据变更并将其转换为流式数据,FlinkCDC 可以帮助实时应用程序实时地处理和分析这些流数据,从而实现数据同步、数据管道、实时分析和实时应用等功能。它可以实时地捕获数据源中的变更,并将这些变更推送到目标系统或进行实时分析处理。Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQl等数据库直接读取全量数据和增量变更数据的source 组件。开源地址:https://github.com/ververica/flink-cdc-connectors
主要区别:在于实现的方式和技术栈。CDC是一种通用的数据管理技术,而Flink CDC是特定利用Apache Flink框架实现的数据变更捕获技术。 Flink CDC提供了更高级的功能,如实时处理和流式数据分析,适用于需要处理大规模实时数据的场景。
二.CDC实现方式:
- 基于触发器的CDC:在表上创建触发器,当数据发生更改时,触发器会将更改的数据记录到其他系统或表中。
- 基于事务日志的CDC:通过读取数据库事务日志,将日志中的更改记录解析为可操作的数据。这种方法通常用于增量备份和恢复。
- 基于游标的CDC:在数据库中使用游标,逐行处理数据更改,并将这些更改应用于其他系统或表。
- 基于时间戳的CDC:为表中的每个数据行分配一个时间戳,当数据发生更改时,更新相应的时间戳。然后,可以使用时间戳来识别和处理数据更改。
- 基于消息队列的CDC:将数据更改作为事件发送到消息队列,以便其他系统或应用程序可以订阅和处理这些事件。
CDC主要分为基于查询 和基于Binlog 两种方式:

三.CDC原理与机制:
Debezium 和 Canal 是目前最流行使用的 CDC 工具,这些 CDC 工具的核心原理是抽取数据库日志获取变更。目前 Debezium (支持全量、增量同步,同时支持 MySQL、PostgreSQL、Oracle 等数据库),使用较为广泛。Flink SQL CDC 内置了 Debezium 引擎,利用其抽取日志获取变更的能力,将changelog 转换为 Flink SQL 认识的 RowData 数据。Debezium的数据格式如下:
通过 Debezium 采集的数据,包含了旧数据(before)和新数据行(after)以及原数据信息(source),op 的 u 表示是update 更新操作标识符(op 字段的值 c,u,d,r 分别对应 create,update,delete,reade),ts_ms 表示同步的时间戳。
四. Flink CDC 主要特点:
- 支持多种数据库类型:Flink CDC 支持多种数据库,如 MySQL、PostgreSQL、Oracle、MongoDB 等。
- 实时数据捕获:Flink CDC 能够实时捕获数据库中的数据变更,并将其转换为流式数据。
- 高性能:Flink CDC 基于 Flink 引擎,具有高性能的数据处理能力。
- 低延迟:Flink CDC 可以在毫秒级的延迟下处理大量的数据变更。
- 易集成:Flink CDC 与 Flink 生态系统紧密集成,可以方便地与其他 Flink 应用程序一起使用。
- 高可用性:Flink CDC 支持实时备份和恢复,确保数据的高可用性。
其他常见的开源CDC方案:
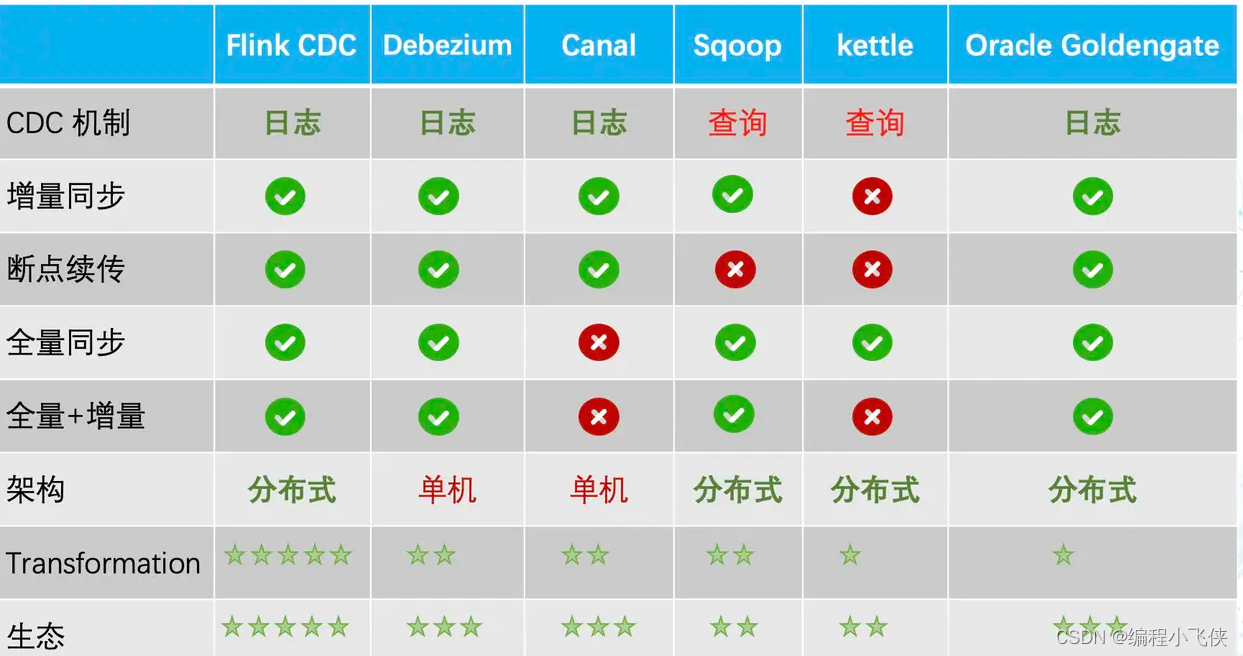
开源地址:https://github.com/ververica/flink-cdc-connectors