With two arguments, the first argument specifies the offset of the first row to return, and the second specifies the maximum number of rows to return. The offset of the initial row is 0 (not 1):
sql复制代码
SELECT * FROM tbl LIMIT 5,10; # Retrieve rows 6-15
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
官方解释
Avoid using from and size to page too deeply or request too many results at once. Search requests usually span multiple shards. Each shard must load its requested hits and the hits for any previous pages into memory. For deep pages or large sets of results, these operations can significantly increase memory and CPU usage, resulting in degraded performance or node failures.
By default, you cannot use from and size to page through more than 10,000 hits. This limit is a safeguard set by the index.max_result_window index setting. If you need to page through more than 10,000 hits, use the search_after parameter instead.
Warning:Elasticsearch uses Lucene's internal doc IDs as tie-breakers. These internal doc IDs can be completely different across replicas of the same data. When paging search hits, you might occasionally see that documents with the same sort values are not ordered consistently.
Elasticsearch 使用 Lucene 的内部文档 ID 作为决定因素。这些内部文档 ID 在相同数据的副本之间可能完全不同。当分页搜索命中时,您有时可能会发现具有相同排序值的文档的排序不一致。
You can use the search_after parameter to retrieve the next page of hits using a set of sort values from the previous page.
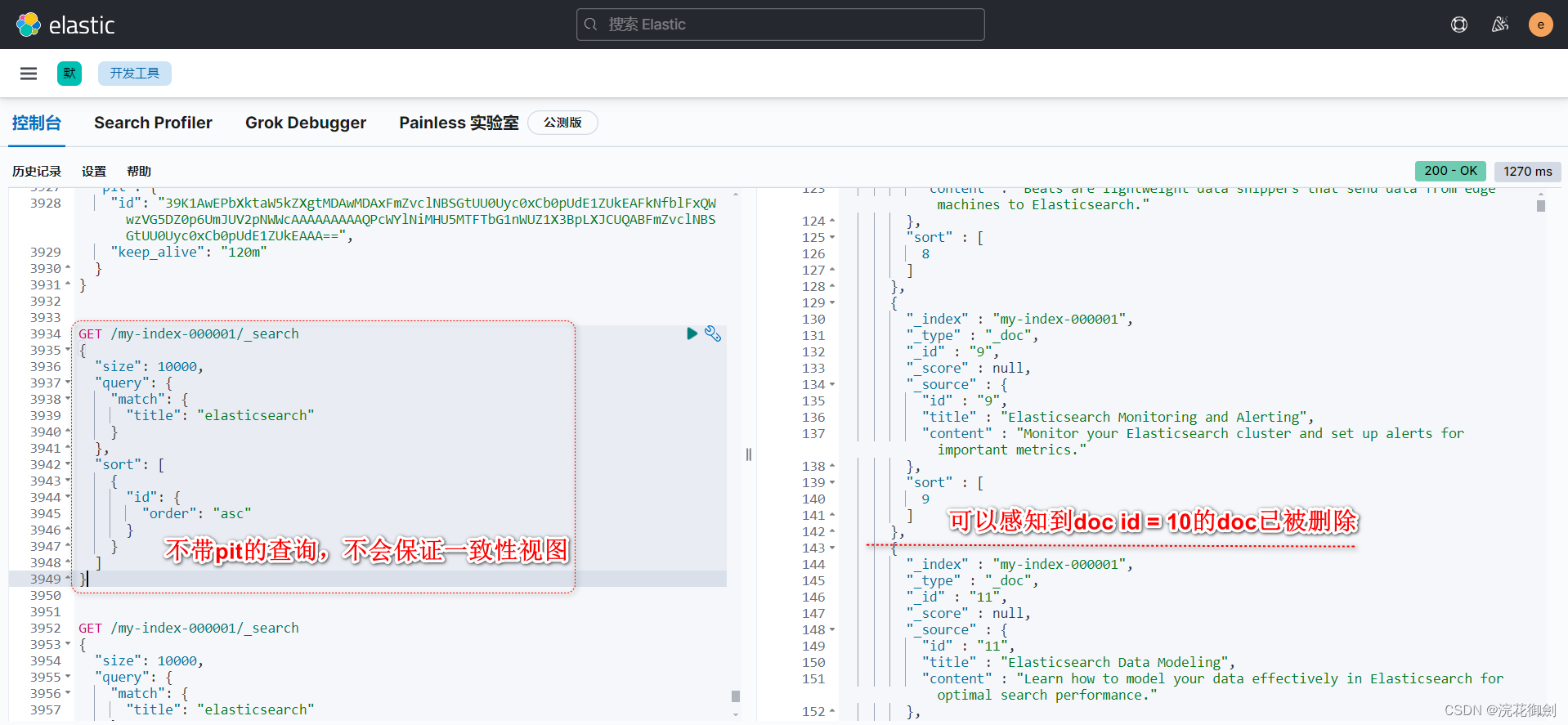
Using search_after requires multiple search requests with the same query and sort values. If a refresh occurs between these requests, the order of your results may change, causing inconsistent results across pages. To prevent this, you can create a point in time (PIT) to preserve the current index state over your searches.
POST /my-index-000001/_pit?keep_alive=10m
//结果如下:得到以一个pit id
{
"id" : "39K1AwEPbXktaW5kZXgtMDAwMDAxFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAFkNfblFxQWwzVG5DZ0p6UmJUV2pNWWcAAAAAAAAATbUWYlNiMHU5MTFTbG1nWUZ1X3BpLXJCUQABFmZvclNBSGtUU0Uyc0xCb0pUdE1ZUkEAAA=="
}
2.首次查询
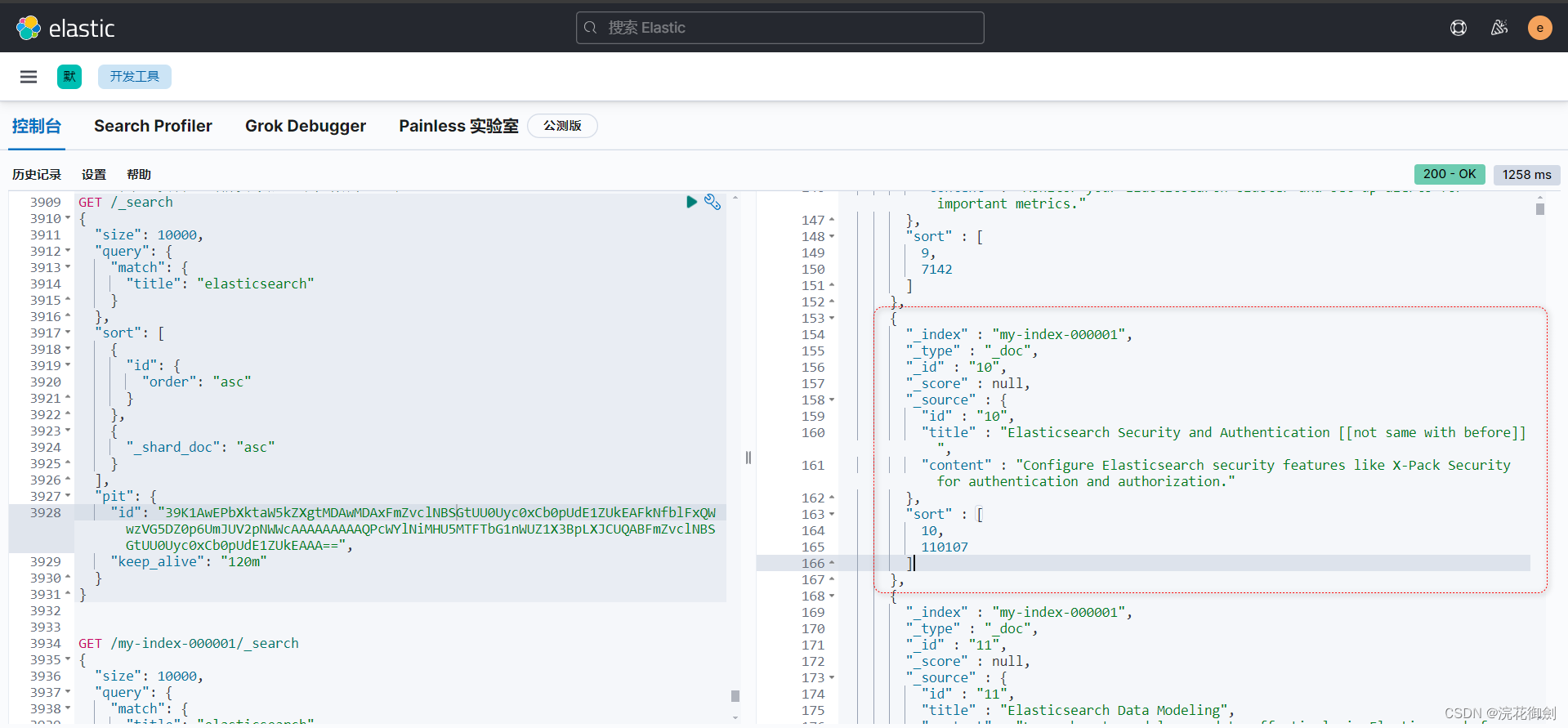
IMPORTANT :All PIT search requests add an implicit sort tiebreaker field called _shard_doc, which can also be provided explicitly. If you cannot use a PIT, we recommend that you include a tiebreaker field in your sort. This tiebreaker field should contain a unique value for each document. If you don't include a tiebreaker field, your paged results could miss or duplicate hits.
NOTE :Search after requests have optimizations that make them faster when the sort order is _shard_doc and total hits are not tracked. If you want to iterate over all documents regardless of the order, this is the most efficient option.
IMPORTANT :If the sort field is a date in some target data streams or indices but a date_nanos field in other targets, use the numeric_type parameter to convert the values to a single resolution and the format parameter to specify a date format for the sort field. Otherwise, Elasticsearch won't interpret the search after parameter correctly in each request.
<2>PIT ID for the search.
The search response includes an array of sort values for each hit. If you used a PIT, a tiebreaker is included as the last sort values for each hit. This tiebreaker called _shard_doc is added automatically on every search requests that use a PIT. The _shard_doc value is the combination of the shard index within the PIT and the Lucene's internal doc ID, it is unique per document and constant within a PIT. You can also add the tiebreaker explicitly in the search request to customize the order
_shard_doc 值是 PIT 中的分片索引和 Lucene 的内部文档 ID 的组合,它对于每个文档都是唯一的 ,并且在 PIT 中是恒定的 。因此,可以在搜索请求中显式添加tiebreaker以自定义顺序。
<3>You can repeat this process to get additional pages of results. If using a PIT, you can extend the PIT's retention period using the keep_alive parameter of each search request.
可以使用每个搜索请求的 keep_alive 参数来延长 PIT 的保留期。
可指定"track_total_hits": false参数, Disable the tracking of total hits,进一步加快分页速度。
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
We no longer recommend using the scroll API for deep pagination. If you need to preserve the index state while paging through more than 10,000 hits, use the search_after parameter with a point in time (PIT).