HBase快速入门系列
HBase的概述
什么是HBase?
HBase 是一个开源的、分布式的、面向列的 NoSQL 数据库,它构建在 Apache Hadoop 之上,提供了高可靠性、高性能和可伸缩性的数据存储解决方案。HBase 的设计灵感来自于 Google 的 Bigtable。
主要特点和功能包括
-
面向列的存储: HBase 采用面向列的存储模型,数据按行键(Row Key)和列族(Column Family)存储,可以支持动态列。
-
分布式存储: HBase 是基于 Hadoop 的分布式文件系统(如 HDFS)构建的,可以水平扩展以处理大规模数据集。
-
高可靠性和高可用性: HBase 提供数据的自动复制和容错机制,确保数据的可靠性和可用性。
-
快速读写: HBase 提供了高性能的读写操作,支持随机读写访问,并能够处理大量并发请求。
-
强一致性: HBase 提供强一致性的数据访问模型,确保数据的一致性性。
-
支持自动分区和负载均衡: HBase 可以自动管理数据的分区和负载均衡,使得数据在集群中分布均匀。
-
支持多种操作接口: HBase 提供了多种操作接口,包括 Java API、REST API、Thrift API 等,方便用户进行数据访问和操作。
使用场景
-
实时数据存储和分析: HBase 适用于需要实时存储和分析大量数据的场景,如日志数据、传感器数据等。
-
在线交易处理(OLTP): HBase 支持高并发的随机读写操作,适用于在线交易处理系统。
-
实时推荐系统: HBase 可以作为实时推荐系统的数据存储引擎,支持快速的数据检索和更新。
-
时序数据存储: HBase 适用于存储时序数据,如传感器数据、日志数据等,支持按时间范围的快速查询。
HBase的架构
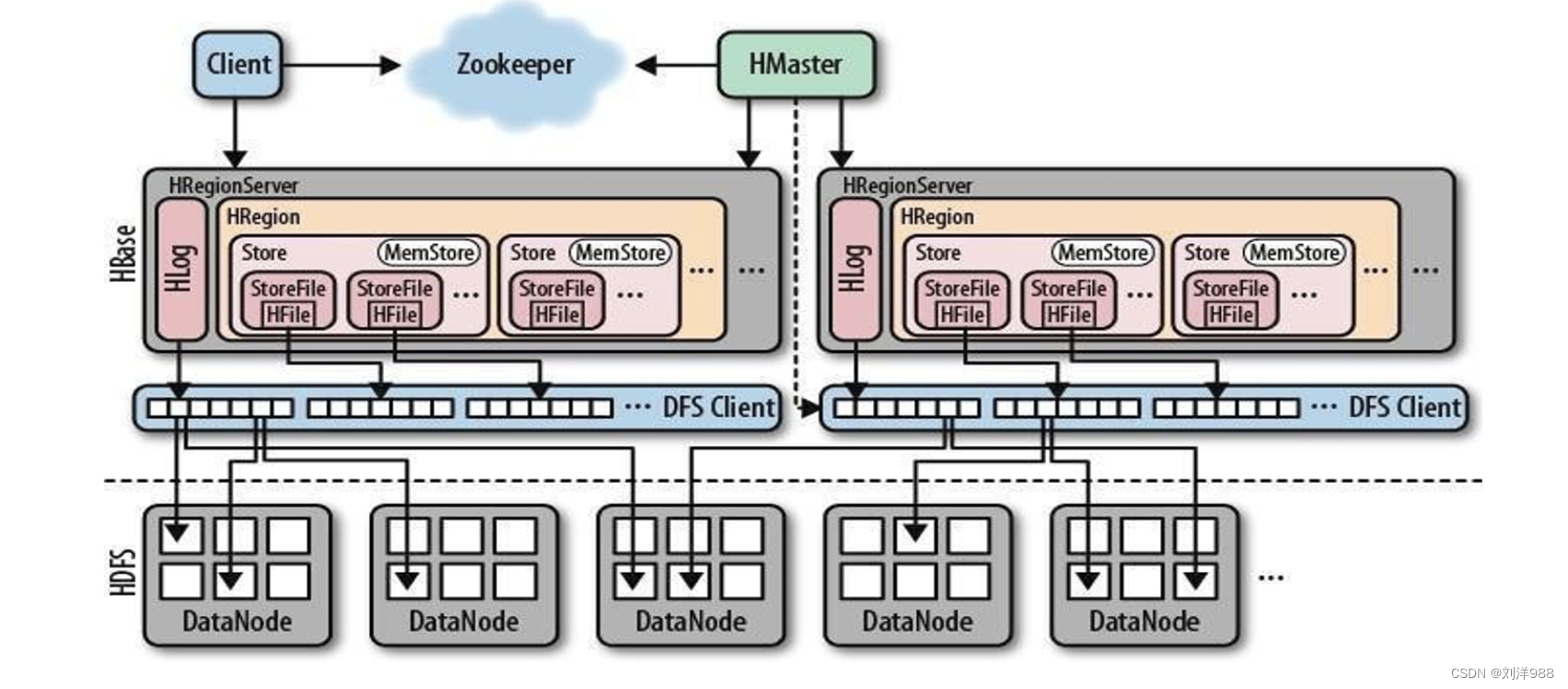
-
HMaster:
HMaster 是 HBase 的主节点,负责管理整个集群的元数据、负载均衡、Region 的分配和调度、故障恢复等工作。HMaster 通过 ZooKeeper 进行协调和通信。
-
RegionServer:
RegionServer 是 HBase 的工作节点,负责管理存储数据的 Region。
每个RegionServer 可以管理多个 Region,负责处理读写请求、数据的存储和 检索等操作。
-
Region:
Region 是 HBase 中数据存储和管理的基本单元,数据按照 Row Key 范围划分为多个 Region,每个 Region 存储一定范围的数据。RegionServer 负责管理和处理特定的 Region。
-
HLog(Write-ahead Log):
HLog 是 HBase 中的写前日志,用于记录数据的变更操作,确保数据的持久性和一致性。HLog 会先将数据写入日志,然后再写入内存和磁盘中。
-
MemStore:
MemStore 是位于 RegionServer 中的内存缓存,用于暂时存储写入的数据,当数据量达到一定阈值时,会将数据刷写到磁盘中的 HFile 中。
-
HFile:
HFile 是 HBase 中数据存储的文件格式,数据按列族存储在 HFile 中,提供快速的数据检索和访问。
-
ZooKeeper:
ZooKeeper 是 HBase 集群中的协调服务,用于管理集群的状态信息、选举 Master、协调 RegionServer 等。HBase 使用 ZooKeeper 来确保集群的一致性和可靠性。
-
HBase Client:
HBase Client 是用户与 HBase 集群交互的接口,用户可以通过 HBase Client 发送读写请求、管理数据等操作。
HBase部署与启动
下载、解压缩,在/etc/profile全局配置文件中添加
export HBASE_HOME=/export/servers/hbase-2.4.5
export PATH= PATH:HBASE_HOME/bin
下载、解压缩,在/etc/profile全局配置文件中添加
export HBASE_HOME=/export/servers/hbase-2.4.5
export PATH= PATH:HBASE_HOME/bin
下载、解压缩,在/etc/profile全局配置文件中添加
xml
<configuration>
<!-- hbase数据存放的目录-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://my2308-host:9000/hbase</value>
</property>
<!-- zk的位置 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
<description>my2308-host:2181</description>
</property>
<!--hbase.cluster.distributed表示是否分布式部署,指定为true-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- hbase主节点的位置 -->
<property>
<name>hbase.master</name>
<value>my2308-host:60000</value>
</property>
</configuration>拷贝zookeeper的conf/zoo.cfg到hbase的conf/下
启动HBase,执行start-hbase.sh脚本
注意:为了方便启动,可在/etc/profile中添加环境变量
export HBASE_HOME=/export/servers/hbase-2.4.5
export PATH= PATH: HBASE_HOME/bin
HBase基本操作
前提条件
- 启动Hadoop集群:sbin/start-all.sh
- 启动ZooKeeper服务:zkServer.sh start
- 启动HBase服务:start-hbase.sh
数据库操作
进入 hbase 客户端
hbase shell
查看所有库(命名空间)
list_namespace
创建一个名称为'mydb'的库
create_namespace 'mydb'
删除'mydb'库
drop_namespace 'mydb'
进入 hbase 客户端
hbase shell
表操作
查看 'mydb'库下的表
list_namespace_tables 'mydb'
查看所有自己创建的表
list
在'mydb'库下创建名为test的表,并创建'f1'、'f2'两个列族
create 'mydb:test','f1','f2'
注意:创建表时若不指定库名,默认在default库下创建表,创建表要至少指定一个列族
查看表详细信息
describe 'mydb:test' 或 desc 'mydb:test'
增加列族
alter 'mydb:test','f3'
删除列族
alter 'mydb:test','delete'=>'f2'
删除表
disable 'mydb:test'
drop 'mydb:test'
注意:删除表需要先进行disable,再进行drop
数据的CRUD操作
先在 default 库下创建一个名为stu的表,列族名称是 info
create 'stu','info'
插入数据
put 'stu','1001','info:name','linghc'
put 'stu','1001','info:sex','man'
put 'stu','1001','info:age','26'
put 'stu','1002','info:name','renyy'
put 'stu','1002','info:sex','female'
put 'stu','1002','info:age','24'
put 'stu','1003','info:name','yilin'
put 'stu','1003','info:sex','female'
put 'stu','1003','info:age','18'
某一行的列的个数可以不一样
put 'stu','1004','info:name','dongfangb'
put 'stu','1004','info:sex','female'
put 'stu','1004','info:age','28'
put 'stu','1004','info:party','rysj'
根据row key(行键)查询
get 'stu','1004'
根据行键、列名查询
get 'stu','1004','info:name','info:age'
扫描表数据
scan 'stu'
按rowkey范围扫描 {STARTROW => '1001' ,STOPROW => '1003'} :左闭右开,此时只查询到 1002
scan 'stu',{STARTROW => '1001' ,STOPROW => '1003'}
指定STOPROW 后加!,可以实现左闭右闭
scan 'stu',{STARTROW => '1001' ,STOPROW => '1003!'}
修改数据:直接put进行覆盖
put 'stu','1001','info:name','linghc1'
注意:修改数据后,其实只是在原来的基础上增加了一条数据,查询的时候返回了时间戳最新的一个版本,旧版本的数据还在
查寻每个单元格的2个版本数据
scan 'stu',{RAW=>true,VERSIONS=>2}
注意RAW参数必须和VERSIONS一起使用,旧版本的数据在适当的时候会被释放;如果想要保留最新两个版本的数据,可以将某个表的 VERSIONS设置为2
更改表的VERSIONS
alter 'stu',{NAME=>'info',VERSIONS=>2}
注意:创建表时若不指定库名,默认在default库下创建表,创建表要至少指定一个列族
删除数据
delete 'stu','1001','info:sex'
此时查询会发现无数据
get 'stu','1001','info:sex'
再通过版本号查询
scan 'stu',{RAW=>true,VERSIONS=>2}
会发现删除的数据有Delete标注
- 根据行键和列名删除列
deleteall 'stu','1001','info:sex'
标注为:DeleteColumn
- 根据行键删除列族
deleteall 'stu','1004'
标注为:DeleteFamily
- 删除表中所有数据
truncate 'stu'
truncate命令将删除表中的所有数据行,但是保留表的结构和配置信息。
HBase的不足
当涉及到某些特定的应用场景时,HBase并不总是首选解决方案。举例来说,HBase本身并不支持复杂的聚合运算,如Join和GroupBy操作。在这种情况下,可以考虑在HBase之上集成Phoenix或Spark组件。Phoenix适用于小规模聚合的OLTP场景,而Spark则适用于大规模聚合的OLAP场景。
此外,HBase原生不支持二级索引功能,这意味着无法直接进行二级索引查找。不过,有许多第三方解决方案可以为HBase提供二级索引支持,比如Phoenix提供的二级索引功能。
另一个限制是HBase没有实现全局跨行事务,只支持单行事务模型。针对这一点,Phoenix提供了全局事务模型组件,可以弥补HBase在这方面的不足。
尽管如此,HBase作为一个高可靠性、高性能和可伸缩性的分布式NoSQL数据库,在Hadoop生态系统的支持下,通过集成Phoenix、Spark或其他第三方组件,仍然能够满足广泛的大数据存储和处理需求。