ELFK 日志收集与可视化平台
一、前言
1、为什么要收集日志
(1)问题诊断与故障排除
- 错误和异常跟踪:日志记录系统运行过程中的错误和异常信息,有助于快速定位问题根源。
- 性能问题排查:通过分析日志,可以识别系统性能瓶颈,发现资源消耗过高的操作或请求。
(2)系统监控与运维
- 实时监控:日志数据可以用于实时监控系统状态,及时发现和响应潜在问题。
- 资源使用情况:日志记录系统资源(如 CPU、内存、磁盘)的使用情况,有助于优化资源配置和管理。
(3)安全性和合规性
- 安全事件检测:日志可以记录系统中的安全事件(如未授权访问、异常登录等),帮助及时发现和应对安全威胁。
- 审计和合规:许多行业法规要求对系统活动进行详细记录,以满足审计和合规要求。日志提供了必要的审计轨迹。
(4)分析和优化
- 使用模式分析:通过分析日志,可以了解用户行为和系统使用模式,优化系统设计和用户体验。
- 问题趋势分析:日志数据可以用于分析问题发生的趋势,帮助预测和预防未来的故障。
(5)自动化和可视化
- 自动化运维:结合日志数据和自动化工具,可以实现自动化运维任务,如故障自动恢复、资源自动扩展等。
- 可视化:使用工具(如 Kibana、Grafana 等)将日志数据可视化,提供直观的系统状态和趋势展示,便于管理和决策。
(6)审计与报告
- 详细记录:日志记录了系统的详细活动情况,为后续的审计和报告提供了依据。
- 报告生成:通过对日志数据的分析,可以生成各种报告,帮助管理层了解系统运行状况和问题。
2、什么是ELFK
- ELFK 指的是Elasticsearch、Logstash、Kibana(通常被称为ELK Stack),以及Filebeat的组合。ELK Stack是一套开源工具,用于搜索、分析和可视化日志数据,而Filebeat是一个轻量级的日志数据传输器,可以将日志从服务器发送到Logstash或Elasticsearch。
(1) Elasticsearch
Elasticsearch是一个基于Apache Lucene的开源搜索和分析引擎。它能够实时地存储、搜索和分析海量数据,具有高扩展性和高性能。主要特点包括:
- 分布式设计:支持分布式存储和搜索,能够处理大规模数据集。
- 实时搜索:可以实时地索引和搜索数据,适用于需要快速响应的应用场景。
- RESTful API:提供简单易用的RESTful API接口,便于与其他系统集成。
(2)Logstash
Logstash是一个开源的数据收集引擎,能够从多种来源采集数据,并将数据进行转换和传输到不同的存储系统(如Elasticsearch)。主要功能包括:
- 多输入源支持:支持从日志文件、数据库、消息队列等多种数据源采集数据。
- 数据过滤和转换:使用丰富的插件和过滤器对数据进行处理,如解析、格式化、聚合等。
- 灵活的输出配置:可以将处理后的数据发送到多个目标,包括Elasticsearch、文件、邮件等。
(3) Kibana
Kibana是一个开源的数据可视化和探索工具,专门用于Elasticsearch数据的展示。它提供了强大的图表和仪表盘功能,使用户可以轻松地创建、共享和浏览数据可视化。主要特点包括:
- 实时分析:通过交互式的仪表盘和图表,对数据进行实时分析和展示。
- 强大的搜索功能:基于Elasticsearch的搜索能力,支持复杂的查询和过滤。
- 丰富的可视化选项:支持多种类型的图表和可视化工具,如折线图、柱状图、饼图、地图等。
(4) Filebeat
Filebeat是一个轻量级的日志收集器,专门设计用于将日志文件从服务器发送到Logstash或Elasticsearch。主要功能包括:
- 轻量级和高效:占用资源少,适合在各类服务器上运行。
- 模块化设计:支持多种日志类型(如系统日志、Apache日志、Nginx日志等),并预配置了相应的解析模块。
- 可靠的数据传输:确保日志数据的完整传输,并在网络故障时支持数据重传。
(5)ELFK Stack的使用场景
- 日志管理和分析:用于收集、存储和分析应用和系统日志,帮助运维团队快速定位和解决问题。
- 安全信息和事件管理(SIEM):收集和分析安全事件数据,帮助识别潜在的安全威胁和入侵行为。
- 应用性能监控(APM):监控应用程序性能,识别性能瓶颈和优化应用性能。
- 业务数据分析:分析业务数据,帮助企业做出数据驱动的决策。
二、Elasticsearch
1、简介
- Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,基于 Apache Lucene 构建。它被设计用于实时的全文搜索、结构化搜索、分析以及组合这两者。Elasticsearch 通常被用作搜索引擎、日志和事件数据分析平台,支持大规模数据处理和实时响应需求。
(1)什么是RESTful 风格
- RESTful 风格(Representational State Transfer,REST)是一种用于构建 Web 服务的架构风格。它通过一组明确的约束和原则来定义系统中组件之间的交互。RESTful 风格利用 HTTP 协议的特性,使 Web 服务更加简单、可扩展和易于维护。
(2)REST 的基本原则
资源(Resource)
- 定义:资源是系统中可被唯一标识的数据实体,可以是对象、文件、服务等。
- 标识 :每个资源通过 URI(统一资源标识符)唯一标识。例如,
http://example.com/users/123表示一个用户资源。
表现层(Representation)
- 定义:表现层是资源的具体形式,可以是 JSON、XML、HTML 等格式。
- 传输:客户端与服务器之间交换资源时,传输的是资源的表现层,而不是资源本身。
状态转换(State Transfer)
- 操作:通过标准的 HTTP 动词(GET、POST、PUT、DELETE 等)操作资源,进行状态转换。
- 无状态性:每个请求都是独立的,不依赖于之前的请求,服务器不会在请求之间保存客户端的状态。
(3)REST 的关键特性
无状态性(Stateless)
- 定义:每个请求从客户端到服务器都必须包含理解请求所需的所有信息,服务器不会在请求之间存储任何客户端上下文。
- 优点:简化了服务器设计,增强了可扩展性和容错性。
可缓存性(Cacheable)
- 定义:响应应明确指示是否可以缓存,以提高性能和减少负载。
- 实现 :通过 HTTP 头部(如
Cache-Control)指示缓存策略。
统一接口(Uniform Interface)
- 定义:统一接口简化和分离了客户端和服务器的架构,使得它们可以独立演化。
- 组成:
- 资源标识:使用 URI 唯一标识资源。
- 资源操作:使用标准的 HTTP 动词操作资源(GET、POST、PUT、DELETE 等)。
- 自描述消息:请求和响应包含足够的信息(如媒体类型、状态码)以使客户端理解。
- 超媒体作为应用状态引擎(HATEOAS):客户端通过超链接在资源之间导航。
分层系统(Layered System)
- 定义:客户端不需要知道它直接连接的是最终服务器还是中间服务器,通过增加中间层,可以实现负载均衡、安全策略等。
- 优点:提高了系统的可扩展性和安全性。
按需代码(Code on Demand)
- 定义:服务器可以通过下载和执行代码(如 JavaScript)来扩展客户端功能。
- 可选性:这是 REST 架构的一个可选特性,不是所有 RESTful 服务都必须实现。
(4)RESTful API 的设计
URI 设计
- 资源命名 :URI 应清晰地反映资源层次结构。例如,
/users/123/orders表示用户 123 的订单。 - 规范:使用名词表示资源,不使用动词。保持简单、一致和直观。
HTTP 动词
- GET :检索资源。例如,
GET /users/123获取用户 123 的信息。 - POST :创建资源。例如,
POST /users创建一个新用户。 - PUT :更新资源。例如,
PUT /users/123更新用户 123 的信息。 - DELETE :删除资源。例如,
DELETE /users/123删除用户 123。
2、核心概念
1. 索引(Index)
- 索引 是 Elasticsearch 存储数据的基本单位。你可以把索引想象成数据库中的一张表。
- 每个索引有一个名字,用来标识和访问它。
2. 文档(Document)
- 文档 是存储在索引中的数据单元,相当于数据库中的一行记录。
- 每个文档是一个 JSON 格式的对象,包含了具体的数据。
3. 字段(Field)
- 字段 是文档的属性,相当于数据库表中的列。
- 例如,一个用户文档可能有
name、age和email等字段。
4. 分片(Shard)
-
分片 是索引的一个子集,可以把它想象成索引的一个小部分。
-
分片允许 Elasticsearch 处理非常大的数据集,并且提高搜索性能。
-
为什么需要分片?- 提高性能 :
- 数据量大:当数据量非常大时,把所有数据放在一个索引中会导致性能问题。单个索引可能会变得过于庞大,导致搜索和索引操作的速度减慢。
- 并行处理:分片将数据分成更小的部分,允许并行处理,从而提高性能。多个分片可以同时处理搜索请求,提升查询速度。
- 扩展存储和处理能力 :
- 分布式存储:分片使得数据可以分布在多个节点上,从而扩展存储和处理能力。这种分布式架构允许在集群中添加更多节点来存储和处理更多数据。
分片如何工作?-
指定分片数量:
-
当你创建一个索引时,你可以指定分片的数量。例如,创建一个包含 5 个分片的索引:
curl -X PUT "localhost:9200/my_index" -H 'Content-Type: application/json' -d' { "settings": { "index": { "number_of_shards": 5, "number_of_replicas": 1 } } }'
-
-
分片存储:
- 每个分片包含一部分索引数据,这些分片可以存储在不同的节点上。分片在节点之间均匀分布,以实现负载均衡。
-
并行查询:
- 当你搜索数据时,Elasticsearch 会并行查询所有相关的分片,并将结果合并返回给客户端。这样可以显著加快搜索速度。例如,当你查询一个包含 5 个分片的索引时,查询会并行地在这 5 个分片上执行,最终将各分片的结果汇总。
- 提高性能 :
5. 副本(Replica)
- 副本 是分片的拷贝,用来提高数据的可用性和搜索性能。
- 副本确保即使一个节点失败,数据也不会丢失。
3、工作原理
- 数据存储:当你把数据发送给 Elasticsearch 时,它会将数据存储为文档,并将文档放入指定的索引中。
- 分片和副本:Elasticsearch 会将索引分成多个分片,并在多个节点上保存这些分片的副本,以确保数据安全和快速访问。
- 搜索:当你搜索数据时,Elasticsearch 会查找所有相关的分片并汇总结果,以提供快速和准确的搜索响应。
4、主要功能
(1) 全文搜索
- Elasticsearch 可以对大量文本进行快速、精确的全文搜索。
- 使用倒排索引技术,可以快速找到包含特定词语的文档。
(2) 实时数据处理
- 新数据可以实时添加到 Elasticsearch 中,并立即变得可搜索。
(3) 聚合(Aggregation)
- Elasticsearch 支持复杂的数据分析,可以执行各种统计、计数、求和、平均值等操作。
- 聚合功能使其不仅是一个搜索引擎,也是一个数据分析工具。
(4) 分布式系统
- 可以在多个服务器(节点)上运行,并自动管理数据分布和负载均衡。
- 即使某些节点失败,系统仍然可以正常运行。
5、使用场景
- 网站搜索:为网站提供快速和相关的搜索结果。
- 日志分析:分析大量日志数据,找到错误或异常情况。
- 电子商务:搜索和推荐产品,提高用户体验。
- 商业智能:实时分析和可视化数据,帮助企业做出数据驱动的决策。
6、倒排索引
- 倒排索引(Inverted Index)是一种高效的数据结构,用于快速查找包含特定词项的文档。在全文搜索引擎中(如 Elasticsearch、Apache Lucene),倒排索引是核心技术,用于加速搜索操作。它由两部分组成:一个词项词典和一个文档列表。
(1)倒排索引的基本概念
-
词项词典(Term Dictionary):
- 这是一个包含所有索引词项(即,文档中出现的每个唯一词)的列表。
- 每个词项对应一个或多个文档 ID,这些文档包含该词项。
-
文档列表(Posting List):
- 对于每个词项,文档列表存储所有包含该词项的文档 ID。
- 文档列表可能还包含其他信息,如词项在文档中的位置、词频等。
(2)倒排索引的工作原理
1. 建立倒排索引
假设我们有三个文档:
- Doc1: "The cat sat on the mat"
- Doc2: "The dog sat on the mat"
- Doc3: "The cat chased the dog"
建立倒排索引的过程:
- 步骤1:解析每个文档,将其分解成单词(词项)。
- 步骤2:为每个词项创建词典条目,并记录包含该词项的文档 ID。
最终的倒排索引如下:
| 词项 (Term) | 文档 ID 列表 (Posting List) |
|---|---|
| cat | Doc1, Doc3 |
| sat | Doc1, Doc2 |
| on | Doc1, Doc2 |
| the | Doc1, Doc2, Doc3 |
| mat | Doc1, Doc2 |
| dog | Doc2, Doc3 |
| chased | Doc3 |
2. 查询倒排索引
当用户搜索一个词项或短语时,搜索引擎会使用倒排索引快速找到包含这些词项的文档。例如,搜索 "cat" 时,搜索引擎会查看词典,并找到对应的文档 ID 列表,即 Doc1 和 Doc3。
3. 组合查询
对于复杂的查询(如多词查询),搜索引擎可以结合多个词项的文档列表。例如,搜索 "cat and dog" 时,搜索引擎会分别找到 "cat" 和 "dog" 的文档列表,并取交集,以找到同时包含这两个词项的文档,即 Doc3。
(3)倒排索引的优点
高效检索:
- 倒排索引允许搜索引擎快速查找包含特定词项的文档,而不需要逐一扫描所有文档。
- 对于单个词项,查找是非常快速的,时间复杂度为 O(1)。
支持复杂查询:
- 倒排索引不仅支持简单的词项查询,还支持布尔查询、短语查询、范围查询等复杂查询。
节省空间:
- 相比直接存储文档内容,倒排索引只存储词项和文档 ID 列表,节省了大量空间。
(4)倒排索引在 Elasticsearch 中的实现
在 Elasticsearch 中,每个索引(Index)包含一个或多个分片(Shard),每个分片包含一个或多个段(Segment)。每个段维护一个倒排索引,用于存储该段中的所有文档数据。倒排索引的构建和查询由 Apache Lucene 库实现。
示例:
假设我们有一个包含文本数据的 Elasticsearch 索引,文档结构如下:
json
{
"title": "The quick brown fox",
"content": "The fox jumps over the lazy dog"
}当将文档添加到索引时,Elasticsearch 会解析文本内容,并为每个词项创建倒排索引条目。例如:
| 词项 (Term) | 文档 ID 列表 (Posting List) |
|---|---|
| quick | Doc1 |
| brown | Doc1 |
| fox | Doc1 |
| jumps | Doc1 |
| over | Doc1 |
| lazy | Doc1 |
| dog | Doc1 |
当用户搜索 "fox" 时,Elasticsearch 会快速查找倒排索引,找到包含 "fox" 的文档(即 Doc1)。
7、正排索引
正排索引(Forward Index)是一种与倒排索引相对的索引结构,用于存储文档中词项的原始顺序信息。它主要用于快速获取文档的内容,尤其是在需要频繁读取文档内容的场景下。正排索引在一些特定应用中非常有用,比如文本检索中的原始文档提取和自然语言处理中的语料分析。
(1)正排索引的基本概念
-
文档至词项的映射:正排索引存储的是文档到其包含的词项列表的映射关系。每个文档都有一个独立的词项列表,记录了文档中出现的所有词项及其出现的位置。
-
数据存储:正排索引中,每个文档对应一条记录,这条记录包含文档的所有内容。具体来说,正排索引会为每个文档存储其所有词项的列表及其位置信息。
(2)正排索引的工作原理
1. 建立正排索引
假设我们有三个文档:
- Doc1: "The cat sat on the mat"
- Doc2: "The dog sat on the mat"
- Doc3: "The cat chased the dog"
建立正排索引的过程:
- 步骤1:解析每个文档,将其分解成单词(词项)。
- 步骤2:为每个文档创建一个记录,记录文档中的词项及其位置信息。
最终的正排索引如下:
| 文档 ID | 词项列表 |
|---|---|
| Doc1 | "The", "cat", "sat", "on", "the", "mat" |
| Doc2 | "The", "dog", "sat", "on", "the", "mat" |
| Doc3 | "The", "cat", "chased", "the", "dog" |
2. 查询正排索引
当需要获取某个文档的内容时,可以直接通过文档 ID 从正排索引中读取完整的词项列表。例如,要获取 Doc1 的内容,只需读取正排索引中 Doc1 对应的词项列表。
(3)正排索引的优点
-
快速文档检索:通过文档 ID 可以快速检索到文档的完整内容,适用于需要频繁读取文档内容的场景。
-
原始顺序保留:正排索引保留了文档中词项的原始顺序,对于需要分析文本序列的应用(如自然语言处理)非常有用。
(4)正排索引的缺点
-
空间开销大:因为正排索引存储了每个文档的完整内容,相对于倒排索引,它的空间开销更大。
-
查询效率低:正排索引不适合高效的全文检索,因为它需要逐个文档扫描来找到包含特定词项的文档。
8、正排索引 vs. 倒排索引
- 正排索引:适用于快速获取文档内容、保留词项顺序、适合原始文档提取。
- 倒排索引:适用于高效的全文检索、快速查找包含特定词项的文档、适合大规模数据处理。
实际应用
在实际应用中,正排索引和倒排索引常常结合使用。倒排索引用于快速搜索和定位文档,而正排索引用于检索文档的完整内容。例如,在搜索引擎中,使用倒排索引找到包含搜索词的文档后,使用正排索引获取文档内容并进行展示。
三、logstash
1、简介
Logstash 是一个开源的数据收集引擎,常用于日志和事件数据的收集、处理和传输。它是由 Elastic 开发并与 Elasticsearch 和 Kibana 一起构成 ELK 堆栈(Elasticsearch、Logstash、Kibana)的重要部分。以下是对 Logstash 的详细介绍:
2、主要功能
-
数据收集:
- Logstash 支持从各种来源收集数据,包括文件、数据库、消息队列(如 Kafka)、日志服务等。
- 通过输入插件(Input Plugins)来支持这些不同的数据源。
-
数据处理:
- Logstash 提供了强大的数据处理功能,可以对收集到的数据进行过滤、解析、转换等操作。
- 使用过滤插件(Filter Plugins)进行数据的清洗和标准化,例如删除不需要的字段、解析复杂的日志格式、添加地理位置信息等。
-
数据输出:
- 处理后的数据可以通过输出插件(Output Plugins)发送到各种目标,包括 Elasticsearch、文件、数据库、消息队列等。
- 常见的输出目的地是 Elasticsearch,这样处理后的数据可以被索引和搜索。
3、架构
Logstash 的架构通常分为三个主要部分:
- 输入(Inputs) :定义数据的来源。例如,
file输入插件可以从文件中读取数据,beats输入插件可以接收来自 Beats 数据收集器的数据。 - 过滤(Filters) :定义数据处理的规则。例如,
grok过滤插件可以解析和结构化文本数据,mutate过滤插件可以修改字段的值。 - 输出(Outputs) :定义数据的目的地。例如,
elasticsearch输出插件可以将数据发送到 Elasticsearch,stdout输出插件可以将数据打印到控制台。
4、典型使用场景
-
日志收集与分析:
- 将应用程序、系统和网络设备的日志数据集中收集起来,统一处理和分析。
- 结合 Elasticsearch 和 Kibana,可以实现实时的日志搜索、分析和可视化。
-
事件数据处理:
- 收集和处理各种事件数据,如用户活动日志、传感器数据等,进行实时处理和分析。
-
数据转换和转发:
- 在数据流动过程中,使用 Logstash 进行数据的格式转换、清洗和转发。
5、示例配置
以下是一个简单的 Logstash 配置文件示例,用于从文件中读取日志数据,解析并发送到 Elasticsearch:
plaintext
input {
file {
path => "/var/log/myapp.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:loglevel} %{GREEDYDATA:message}" }
}
date {
match => [ "timestamp", "ISO8601" ]
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "myapp-logs-%{+YYYY.MM.dd}"
}
}四、什么是Beats
Beats 是一个开源的数据收集器家族,用于将数据从各种来源发送到 Logstash 和 Elasticsearch。它由 Elastic 开发,旨在提供轻量级、高效的数据收集解决方案。以下是对 Beats 的详细介绍:
Beats 家族成员
-
Filebeat:
- 主要用于转发和集中日志文件。
- 支持监控文件系统中的日志文件,将新增的日志条目实时发送到 Logstash 或 Elasticsearch。
- 常用于收集应用程序日志、服务器日志、容器日志等。
-
Metricbeat:
- 用于收集和转发系统和服务的指标数据。
- 支持从操作系统、容器、数据库、网络服务等收集性能数据,如 CPU、内存、磁盘使用情况等。
- 提供预构建的模块,可以轻松地收集和解析常见服务的指标。
-
Packetbeat:
- 网络数据包分析器,主要用于网络流量的监控和分析。
- 能够捕获网络流量并解析常见协议,如 HTTP、DNS、MySQL、Redis 等。
- 用于监控网络性能、检测异常流量等。
-
Heartbeat:
- 用于监控服务的可用性。
- 可以定期 ping 网络服务,检查其是否可用,并将结果发送到 Logstash 或 Elasticsearch。
- 支持 ICMP、TCP、HTTP 等协议的健康检查。
-
Auditbeat:
- 用于收集和发送审计数据,主要用于安全和合规性目的。
- 可以监控文件完整性、用户登录活动、进程活动等。
- 提供深入的系统审计数据。
-
Winlogbeat:
- 专为 Windows 事件日志设计的 Beats 组件。
- 收集 Windows 事件日志并将其发送到 Logstash 或 Elasticsearch。
- 适用于监控 Windows 系统和应用程序的活动。
工作原理
Beats 以轻量级代理的形式运行在目标机器上,收集数据并将其发送到 Logstash 或 Elasticsearch。每个 Beats 都有自己的输入模块,用于从特定的数据源中收集数据,然后通过输出模块将数据发送到指定的目标。以下是一个 Beats 的工作流程示例:
-
数据收集:
- 例如,Filebeat 监控指定的日志文件目录,检测到新的日志条目时会读取并收集这些日志数据。
-
数据处理:
- 数据在发送之前可以进行简单的处理和增强,例如添加标签、重命名字段等。
-
数据输出:
- 处理后的数据通过输出模块发送到 Logstash、Elasticsearch 或其他支持的目标。
示例配置
以下是一个简单的 Filebeat 配置示例,用于从指定的日志文件中收集数据并发送到 Elasticsearch:
yaml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/myapp/*.log
output.elasticsearch:
hosts: ["http://localhost:9200"]
index: "myapp-logs-%{+yyyy.MM.dd}"优点
- 轻量级:Beats 设计为轻量级代理,不会对系统资源造成过多的消耗。
- 模块化:不同的 Beats 组件针对不同的数据源,功能明确,易于部署和管理。
- 扩展性:通过 Logstash 进行进一步的数据处理,或者直接发送到 Elasticsearch 进行索引和搜索。
五、在 ELK 架构中使用 Filebeat 的原因
Filebeat在ELK架构中的作用主要体现在以下几个方面:
- 轻量高效:作为轻量级数据收集器,Filebeat能够有效地从服务器的文件系统中收集日志数据,减少系统资源消耗。
- 直接集成:它能直接将收集到的日志数据发送到Elasticsearch或通过Logstash进行处理,简化了架构并提高了数据处理的效率和实时性。
- 内置模块和简单配置:Filebeat提供了丰富的内置模块,支持常见应用程序和系统日志的监控和收集,配置简单且易于使用。
- 可靠性和实时性:具备实时日志收集能力,能够及时捕获和发送新生成的日志条目,保证日志数据的完整性和可靠性。
- 适用广泛:适用于应用程序、系统、容器和云服务日志的收集,为ELK生态系统提供了重要的数据源,支持实时监控、故障排查和性能优化。
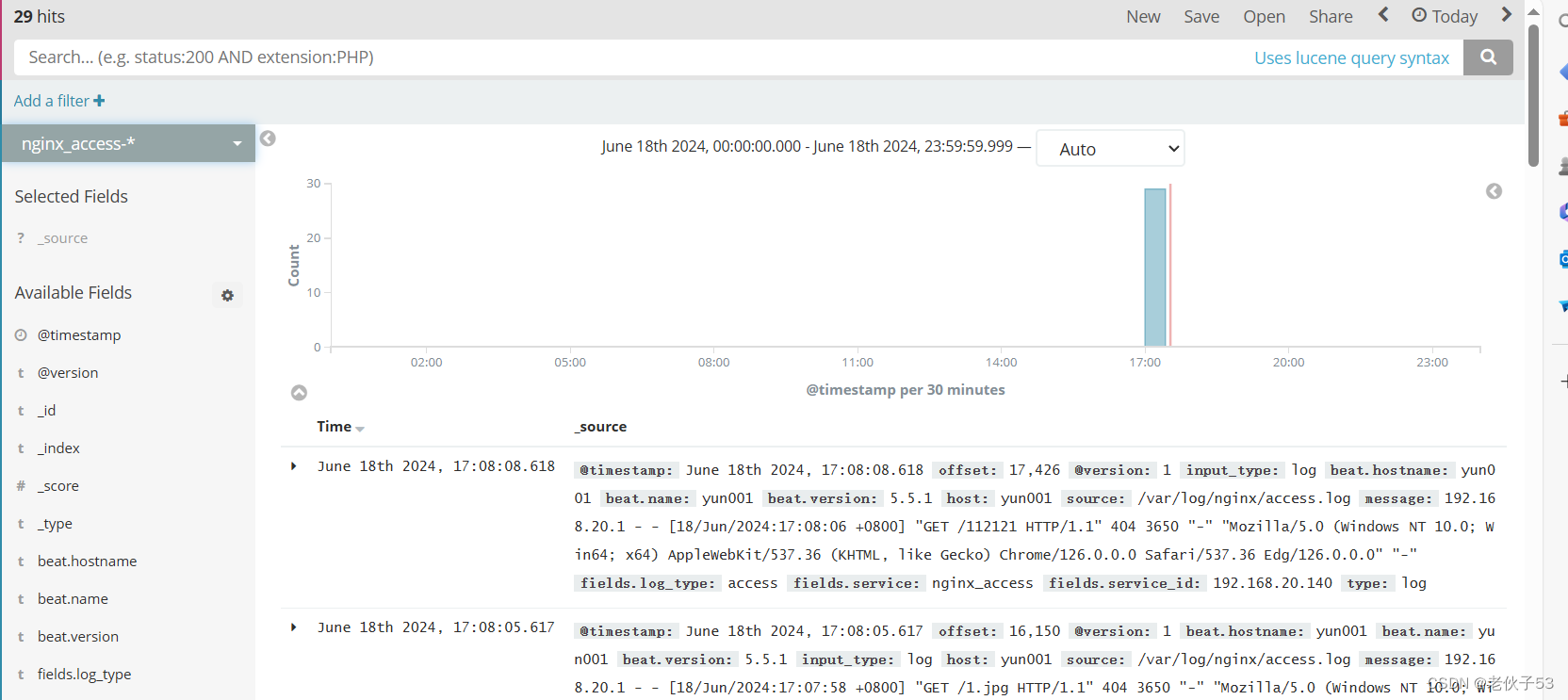
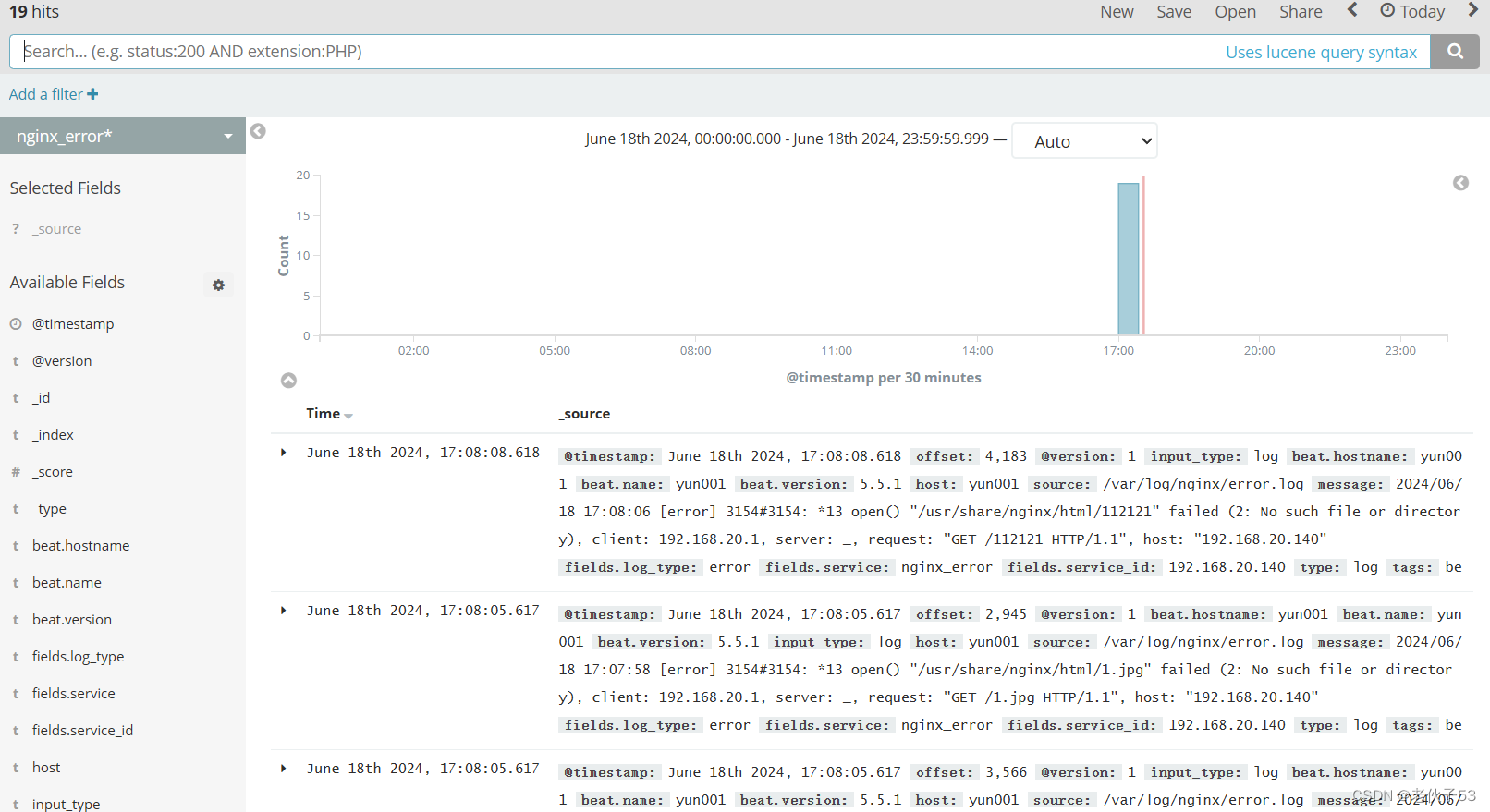
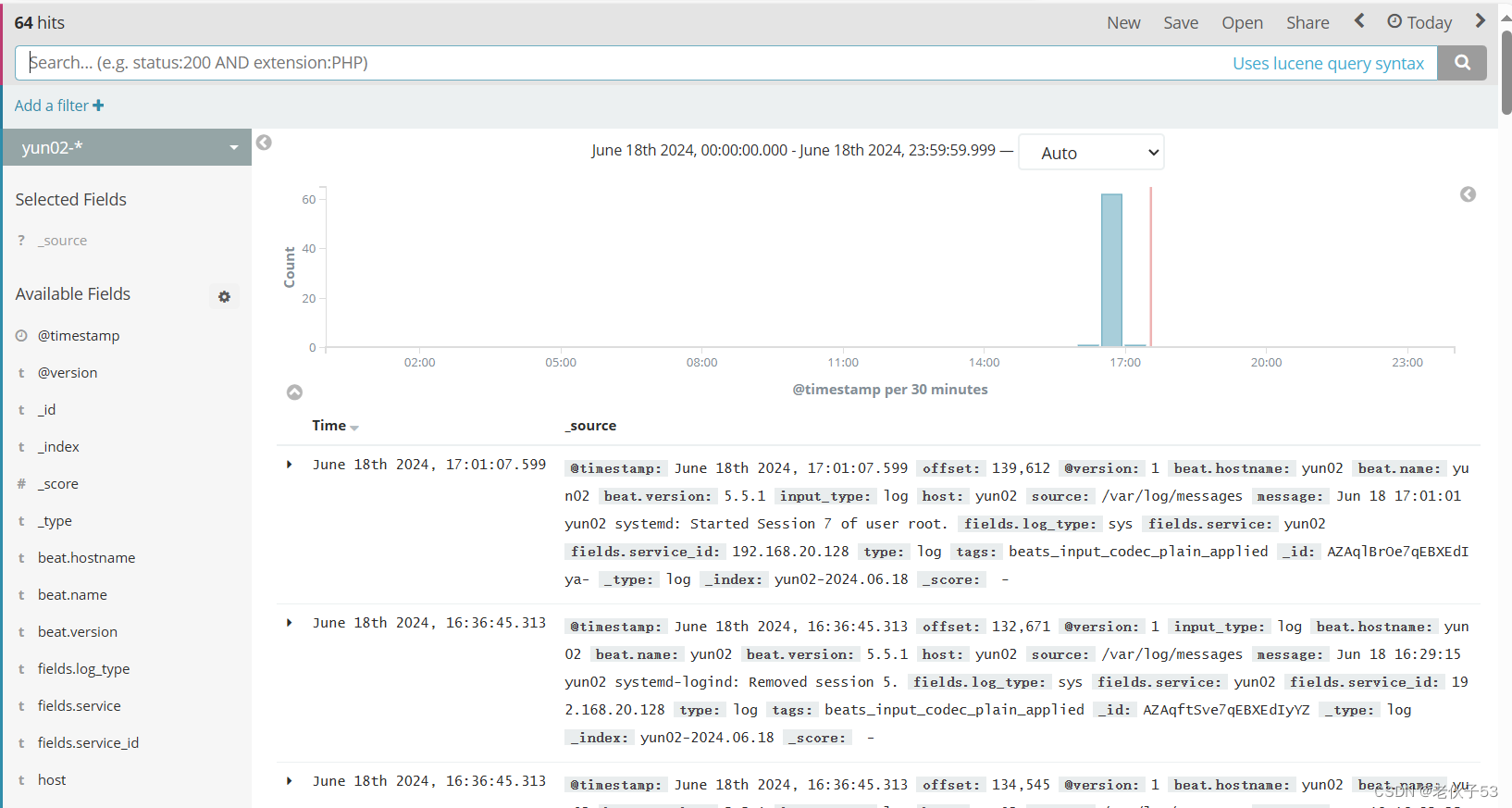
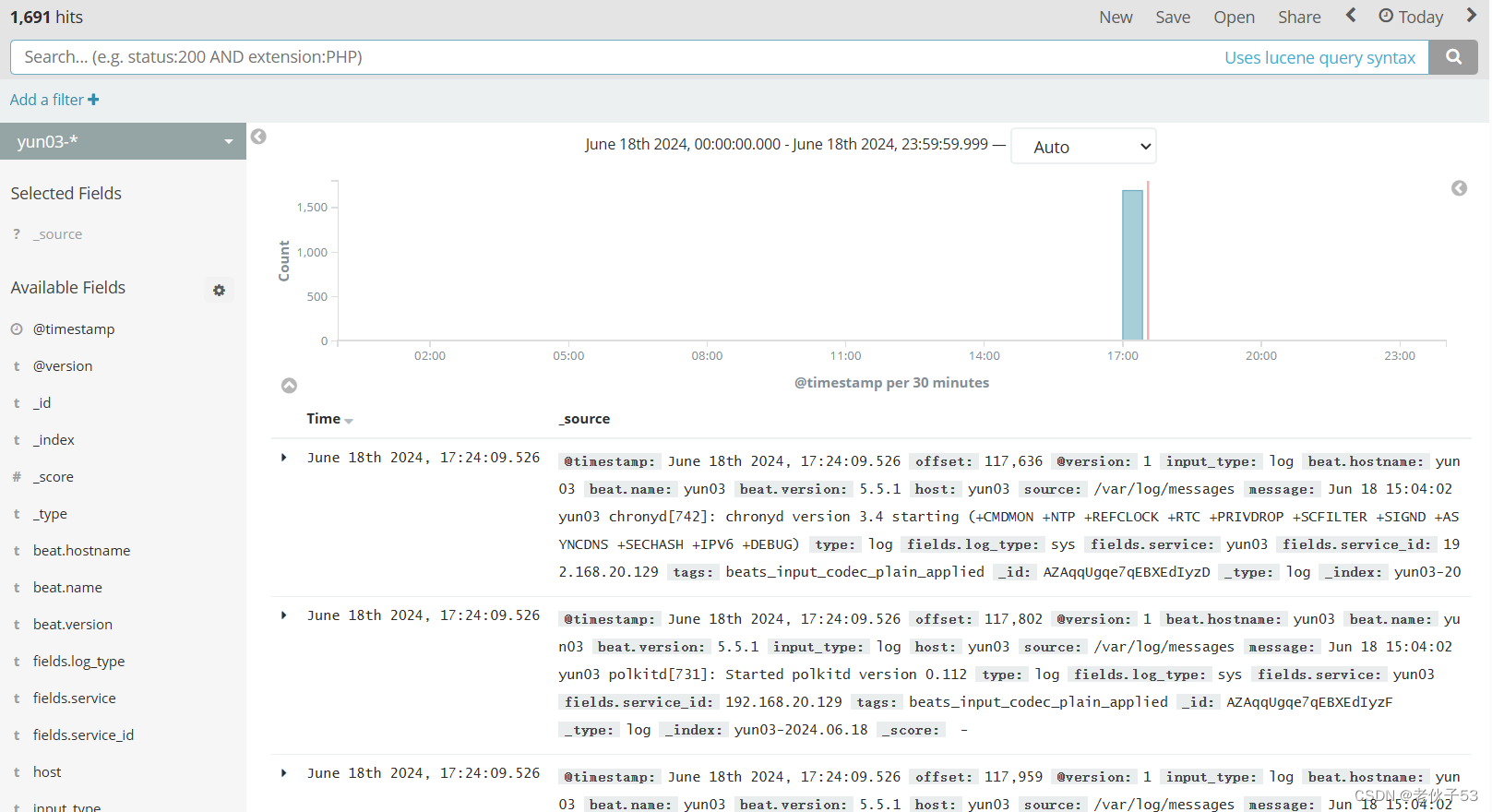
六、ELFK 日志收集与可视化平台搭建实战
1、项目需求
现需要一个ELFK架构的日志收集服务集群来收集正在运行的应用服务器集群的日志信息。具体的架构规划如下。
| 序号 | 服务器 | IP | 类型 | 收集日志类型 |
|---|---|---|---|---|
| 1 | Nginx、Tomcat、Filebeat | 192.168.20.140 | 应用服务器 | 应用错误日志、系统日志 |
| 2 | Apache、MySQL、Filebeat | 192.168.20.141 | 应用服务器 | 应用错误日志、系统日志 |
| 3 | Elasticsearch、Filebeat | 192.168.20.128 | 日志存储 | 系统日志 |
| 4 | Elasticsearch、Filebeat | 192.168.20.129 | 日志存储 | 系统日志 |
| 5 | Logstash、Filebeat | 192.168.20.133 | 日志处理 | 系统日志 |
| 6 | Kibana、Filebeat | 192.168.20.130 | 日志展示 | 系统日志 |
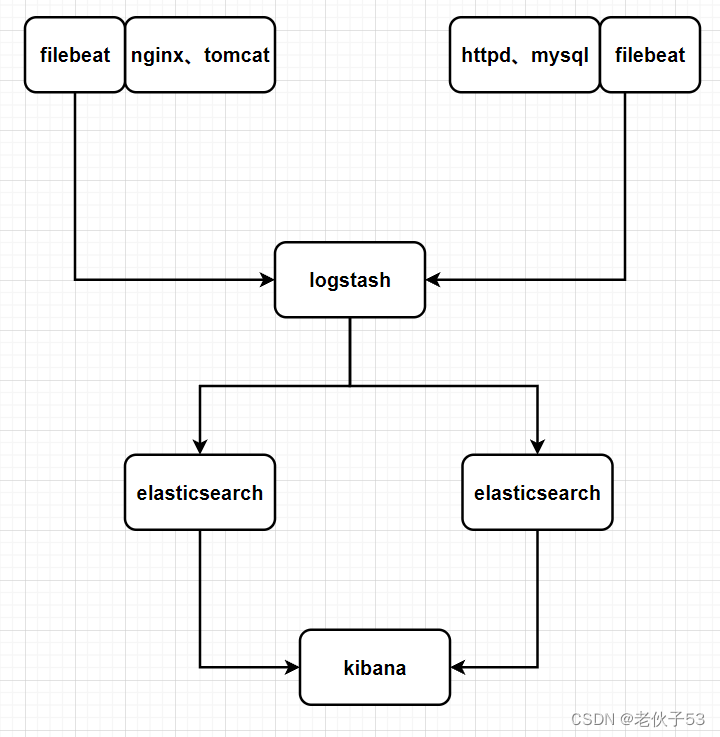
2、项目搭建
(1)应用服务器搭建
-
Nginx服务
-
命令
shellyum install -y epel-release #安装扩展源 yum install -y nginx systemctl start nginx # 开启服务
-
-
Tomcat服务
-
将tomcat、JDK包拖入/opt目录下
-

-

-
-
Apach服务
shellyum install -y httpd systemctl start httpd -
MySQL服务
-
脚本安装
shell#! /bin/bash cd /opt mkdir mysql_tar cd mysql_tar wget https://downloads.mysql.com/archives/get/p/23/file/mysql-community-server-5.7.33-1.el7.x86_64.rpm --no-check-certificate wget https://downloads.mysql.com/archives/get/p/23/file/mysql-community-client-5.7.33-1.el7.x86_64.rpm --no-check-certificate wget https://downloads.mysql.com/archives/get/p/23/file/mysql-community-common-5.7.33-1.el7.x86_64.rpm --no-check-certificate wget https://downloads.mysql.com/archives/get/p/23/file/mysql-community-libs-5.7.33-1.el7.x86_64.rpm --no-check-certificate # 删除centos7系统自带的数据库 rpm -qa | grep mariadb | xargs rpm -e --nodeps # 删除已有的MySQL rpm -qa | grep mysql | xargs rpm -e --nodeps rpm -ivh mysql-community-common-5.7.33-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-5.7.33-1.el7.x86_64.rpm rpm -ivh mysql-community-client-5.7.33-1.el7.x86_64.rpm rpm -ivh mysql-community-server-5.7.33-1.el7.x86_64.rpm # 安装后查询安装的MySQL版本 mysqladmin --version # 启动数据库 systemctl start mysqld echo '安装完毕!!!' -


3、Elasticsearch搭建
(1)拷贝文件
(2)rpm安装
shell
rpm -ivh jdk-8u371-linux-x64.rpm
rpm -ivh elasticsearch-8.14.1-x86_64.rpm-
启动elasticsearch
-
(3)修改配置文件,设置参数
shell
# node1 配置
cluster.name: test-yun
node.name: node1
path.data: /opt/data
path.logs: /opt/logs
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
# node2配置
cluster.name: test-yun
node.name: node2
path.data: /opt/data
path.logs: /opt/logs
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2"](4)重启elasticsearch
shell
# 授权
[root@yun02 opt]# chown elasticsearch:elasticsearch logs
[root@yun02 opt]# chown elasticsearch:elasticsearch data
[root@yun03 opt]# chown elasticsearch:elasticsearch logs
[root@yun03 opt]# chown elasticsearch:elasticsearch data
systemctl restart elasticsearch(5)网页测试

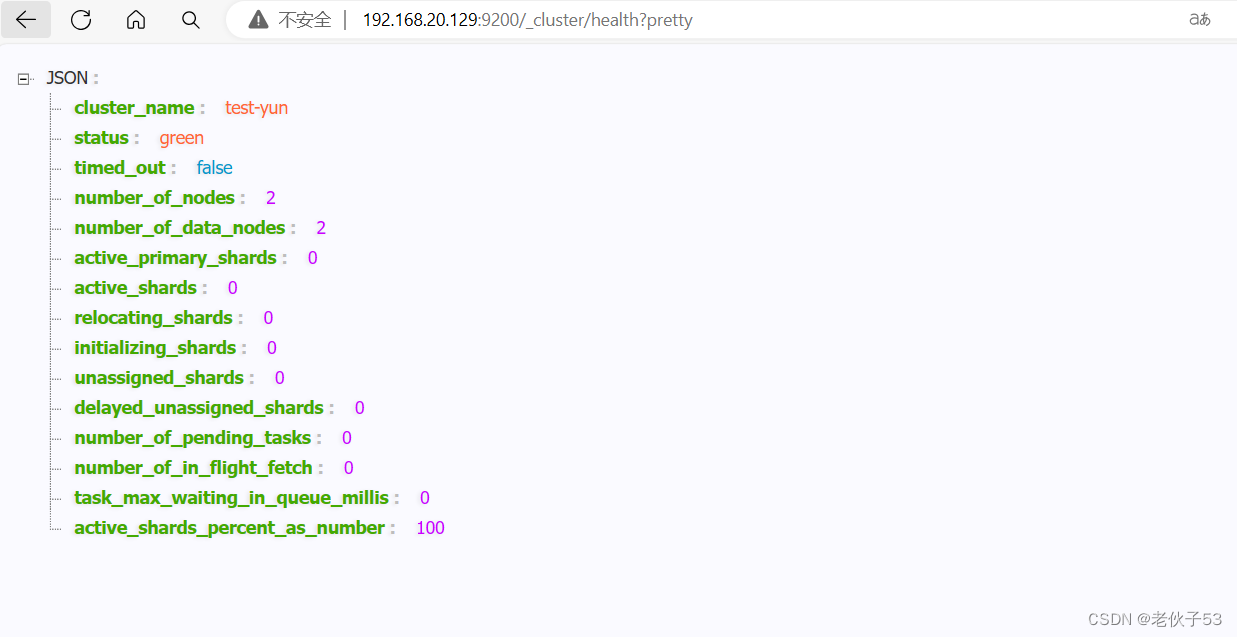
4、Logstash 搭建
(1)rpm安装
shell
rpm -ivh jdk-8u371-linux-x64.rpm
rpm -ivh logstash-5.5.1.rpm
(2)将logstsah加入环境变量
shell
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/(3)在 Logstash 组件所在节点上新建一个 Logstash 配置文件
shell
cd /etc/logstash/conf.d
shell
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.20.128:9200"]
index => "%{[fields][service]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}(4)加载配置文件
shell
logstash -f input.conf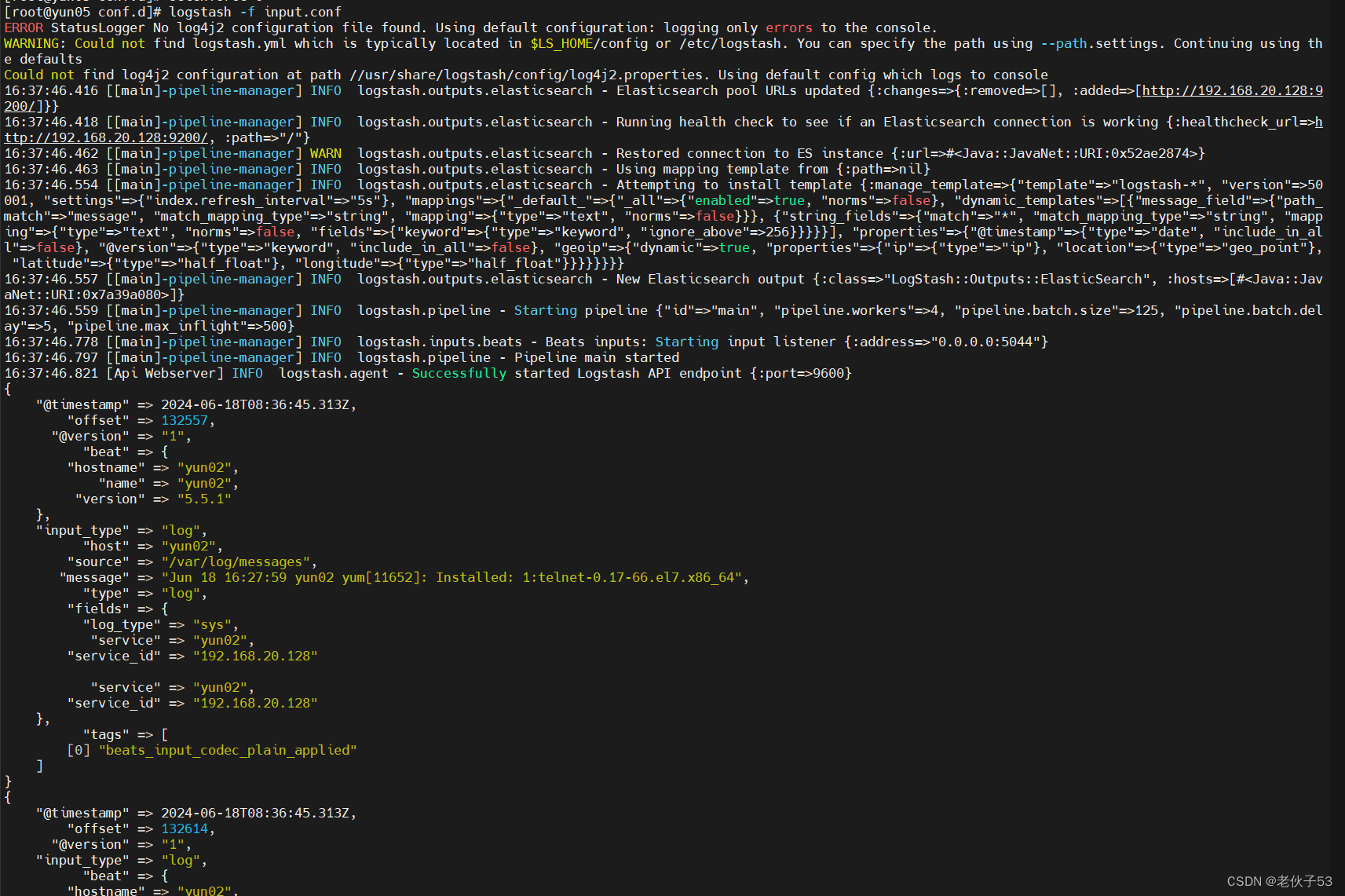
5、部署kibana
(1)安装
shell
[root@yun04 opt]# tar -xf filebeat-5.5.1-linux-x86_64.tar.gz
[root@yun04 opt]# mv filebeat-5.5.1-linux-x86_64 filebeat
(2)访问kibana页面
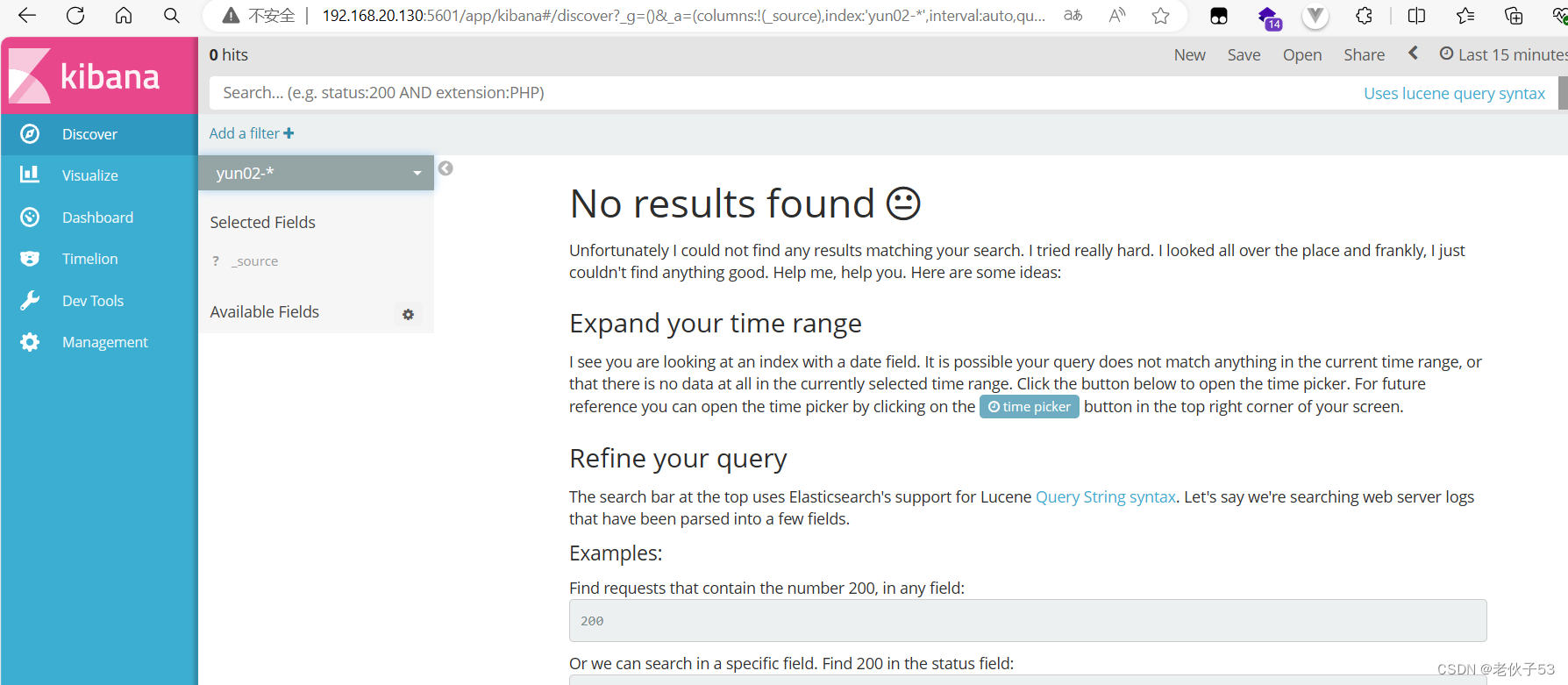
(3)添加索引,测试