文章目录
- 1.正则化线性回归
-
- [1.1 可视化数据集](#1.1 可视化数据集)
- [1.2 正则化线性回归成本函数](#1.2 正则化线性回归成本函数)
- [1.3 正则化线性回归梯度](#1.3 正则化线性回归梯度)
- [1.4 拟合线性回归](#1.4 拟合线性回归)
- [2 偏差-方差](#2 偏差-方差)
-
- [2.1 学习曲线](#2.1 学习曲线)
- 3.多项式回归
-
- [3.1 学习多项式回归](#3.1 学习多项式回归)
- [3.2 正则化参数的调整](#3.2 正则化参数的调整)
- [3.3 使用交叉验证集选择 λ](#3.3 使用交叉验证集选择 λ)
- [3.4 计算测试集误差](#3.4 计算测试集误差)
1.正则化线性回归
在练习的前半部分,您将实施正则化线性回归,利用水库水位的变化预测流出大坝的水量。在下半部分,您将进行一些调试学习算法的诊断,并检查偏差与方差的影响。所提供的脚本 ex5.m 将帮助您逐步完成本练习。
1.1 可视化数据集
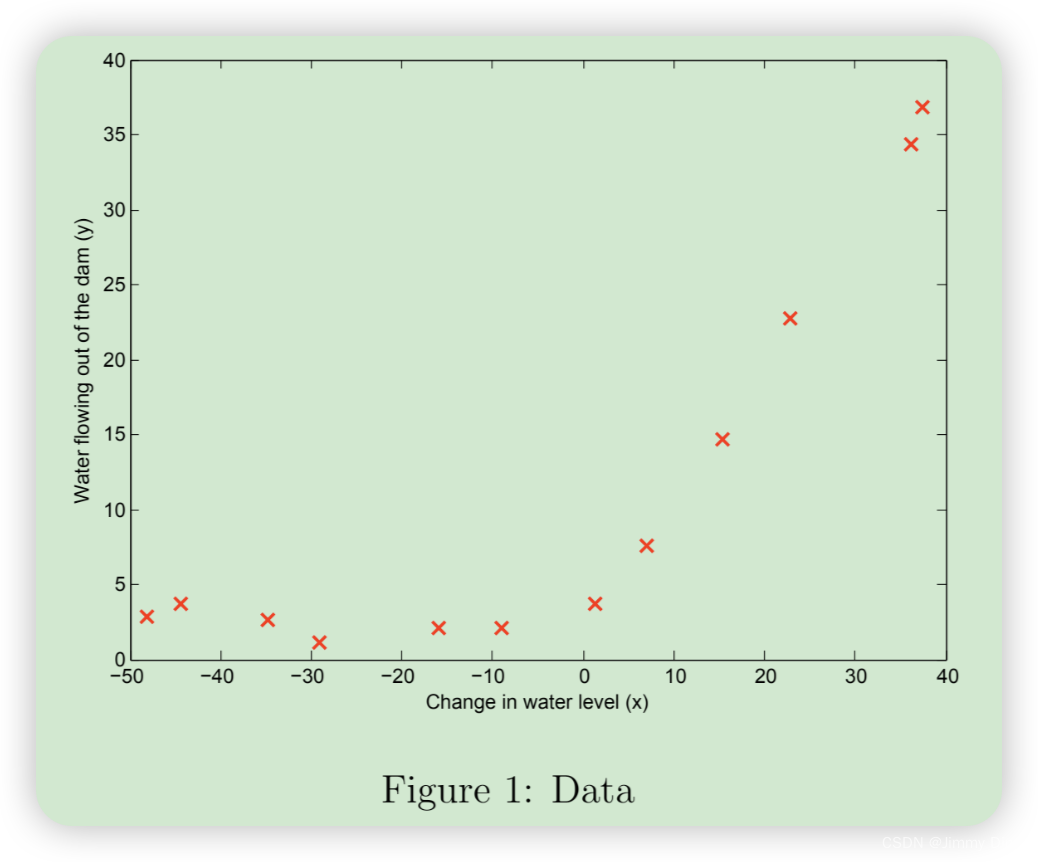
首先,我们将对包含水位变化历史记录 x 和流出大坝的水量 y 的数据集进行可视化处理。
该数据集分为三个部分:
- 训练集,您的模型将在训练集上学习: X、y
- 交叉验证集,用于确定正则化参数:Xval、yval
- 用于评估性能的测试集。这些是模型在训练过程中没有看到的 "未见 "示例: Xtest, ytest
ex5.m 的下一步将绘制训练数据(图 1)。在接下来的部分中,您将实现线性回归,用它来拟合数据的直线并绘制学习曲线。之后,您将实施多项式回归,以找到更好的拟合数据。
python
%matplotlib inline # 使 matplotlib 图像在 Jupyter Notebook 中内嵌显示
import numpy as np # 导入 NumPy 库,用于数组和矩阵操作
import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于数据可视化
from scipy.io import loadmat # 从 SciPy 库中导入 loadmat 函数,用于加载 MATLAB 文件
import scipy.optimize as opt # 导入 SciPy 库中的优化模块,用于优化算法
path = 'ex5data1.mat' # 指定要加载的数据文件路径
data = loadmat(path) # 加载 MATLAB 文件中的数据,返回一个字典,其中包含了文件中的所有变量
# 提取训练集的特征矩阵 X 和标签 y
X, y = data['X'], data['y']
# 提取交叉验证集的特征矩阵 Xval 和标签 yval
Xval, yval = data['Xval'], data['yval']
# 提取测试集的特征矩阵 Xtest 和标签 ytest
Xtest, ytest = data['Xtest'], data['ytest']
# 在特征矩阵 X 的第 0 列插入一列全为 1 的列向量,作为偏置项
X = np.insert(X, 0, 1, axis=1)
# 在交叉验证集的特征矩阵 Xval 中插入一列全为 1 的列向量,作为偏置项
Xval = np.insert(Xval, 0, 1, axis=1)
# 在测试集的特征矩阵 Xtest 中插入一列全为 1 的列向量,作为偏置项
Xtest = np.insert(Xtest, 0, 1, axis=1)
# 打印训练集特征矩阵 X 和标签 y 的形状
print('X={}, y={}'.format(X.shape, y.shape))
# 打印交叉验证集特征矩阵 Xval 和标签 yval 的形状
print('Xval={}, yval={}'.format(Xval.shape, yval.shape))
# 打印测试集特征矩阵 Xtest 和标签 ytest 的形状
print('Xtest={}, ytest={}'.format(Xtest.shape, ytest.shape)) 
python
def plotData():
"""瞧一瞧数据长啥样"""
plt.figure(figsize=(8, 5)) # 创建一个宽为8英寸、高为5英寸的图形窗口
plt.scatter(X[:, 1:], y, c='r', marker='x') # 绘制散点图,X的第一列是偏置项,跳过,c='r'表示红色,marker='x'表示用 'x' 形标记点
plt.xlabel('Change in water level (x)') # 设置x轴标签
plt.ylabel('Water flowing out of the dam (y)') # 设置y轴标签
plt.grid(True) # 显示网格线
plotData() # 调用函数,绘制图形
1.2 正则化线性回归成本函数
回想一下,正则化线性回归的成本函数如下
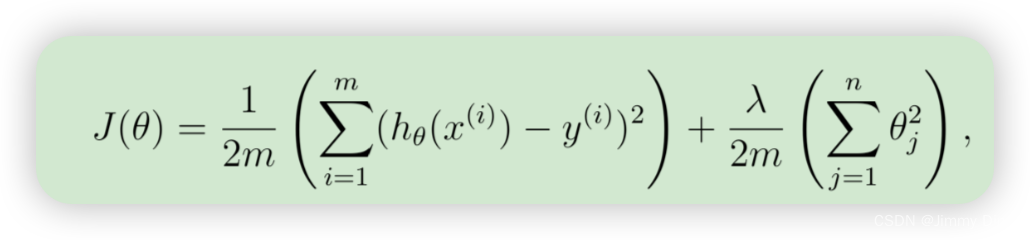
其中,λ 是正则化参数,用于控制正则化程度(从而有助于防止过度拟合)。随着模型参数 θj 的增大,惩罚也随之增大。请注意,不应对 θ0 项进行正则化。(在 Octave/MATLAB中,θ0 项表示为 theta(1),因为在 Octave/MATLAB 中索引从 1 开始)。您现在应该完成文件 linearRegCostFunction.m 中的代码。完成后,ex5.m 的下一部分将使用初始化为 1; 1 的 theta 运行成本函数。您应该能看到 303.993 的输出结果。
python
def costReg(theta, X, y, l):
'''不对 theta0 进行正则化
theta 是形状为 (n+1,) 的一维数组
X 是形状为 (m, n+1) 的矩阵
y 是形状为 (m, 1) 的矩阵
'''
cost = ((X @ theta - y.flatten()) ** 2).sum() # 计算平方误差的总和
regterm = l * (theta[1:] @ theta[1:]) # 计算正则化项(不包括 theta0)
return (cost + regterm) / (2 * len(X)) # 返回正则化后的成本函数值
theta = np.ones(X.shape[1]) # 初始化 theta 为全 1 的数组,长度为 X 的列数
print(costReg(theta, X, y, 1)) # 计算并打印正则化后的成本函数值,期望输出 303.99319222026431.3 正则化线性回归梯度
相应地,正则化线性回归成本对 θj 的偏导数定义为

在 linearRegCostFunction.m 中,添加计算梯度的代码,并将其重新输入变量 grad。完成后,ex5.m 的下一部分将使用初始化为 1; 1 的 theta 运行梯度函数。
python
def gradientReg(theta, X, y, l):
"""
theta: 1维数组,形状为 (2,)
X: 2维数组,形状为 (12, 2)
y: 2维数组,形状为 (12, 1)
l: 正则化参数 lambda
grad: 与 theta 形状相同的梯度 (2,)
"""
grad = (X @ theta - y.flatten()) @ X # 计算梯度的非正则化部分
regterm = l * theta # 计算正则化项
regterm[0] = 0 # 不对偏置项进行正则化
return (grad + regterm) / len(X) # 返回正则化后的梯度
# 使用初始值为 [1, 1] 的 theta,期望得到梯度 [-15.303016, 598.250744] (lambda=1)
theta = np.ones(X.shape[1]) # 初始化 theta 为 [1, 1]
print(gradientReg(theta, X, y, 1)) # 打印计算得到的梯度1.4 拟合线性回归
一旦成本函数和梯度函数正常工作,ex5.m 的下一部分将运行 trainLinearReg.m 中的代码来计算最佳值
该训练函数使用 fmincg 来优化成本函数。
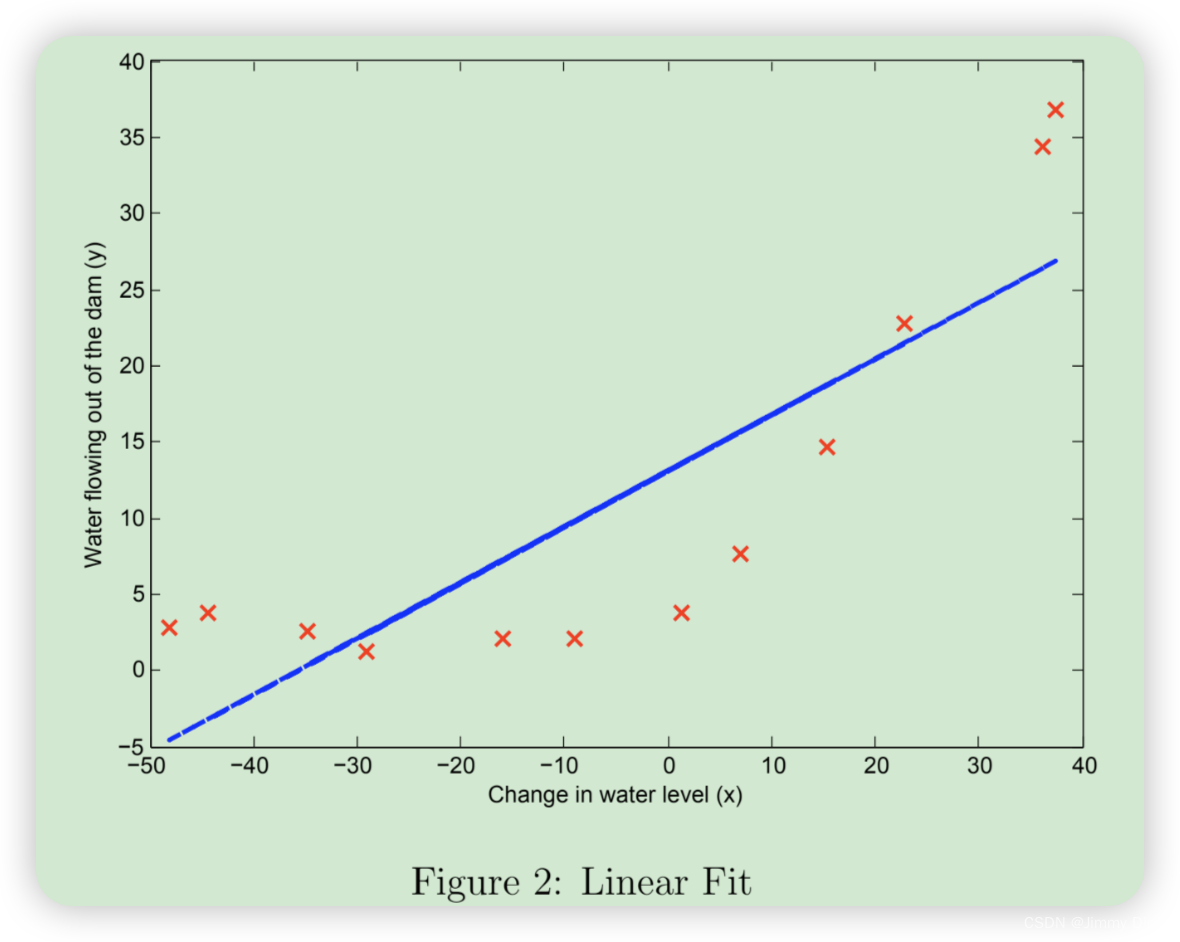
在这一部分,我们将正则化参数 λ 设为零。因为我们目前的线性回归实现试图拟合一个 2 维的θ、正则化对于如此低维度的 θ 并没有太大帮助。最后,ex5.m 脚本还应该绘制出最佳拟合线,得到类似图 2 的图像。最佳拟合线告诉我们,由于数据具有非线性模式,因此模型并不能很好地拟合数据。虽然如图所示将最佳拟合可视化是调试学习算法的一种可行方法,但要将数据和模型可视化并非易事。在下一节中,您将实现一个生成学习曲线的函数,即使不容易将数据可视化,它也能帮助您调试学习算法。
python
def trainLinearReg(X, y, l):
# 初始化参数 theta 为零向量,长度为 X 的列数
theta = np.zeros(X.shape[1])
# 使用 scipy.optimize.minimize 进行优化
res = opt.minimize(fun=costReg, # 优化目标函数为 costReg
x0=theta, # 初始参数 theta
args=(X, y, l),# 目标函数的额外参数:训练数据 X, y 和正则化参数 l
method='TNC', # 使用 TNC(Truncated Newton Conjugate-Gradient)方法进行优化
jac=gradientReg) # 梯度函数为 gradientReg
# 返回优化后的参数
return res.x
# 使用训练数据和正则化参数 l=0 训练模型,得到优化后的参数
fit_theta = trainLinearReg(X, y, 0)
# 绘制数据点
plotData()
# 绘制拟合直线
plt.plot(X[:,1], X @ fit_theta)
plt.show()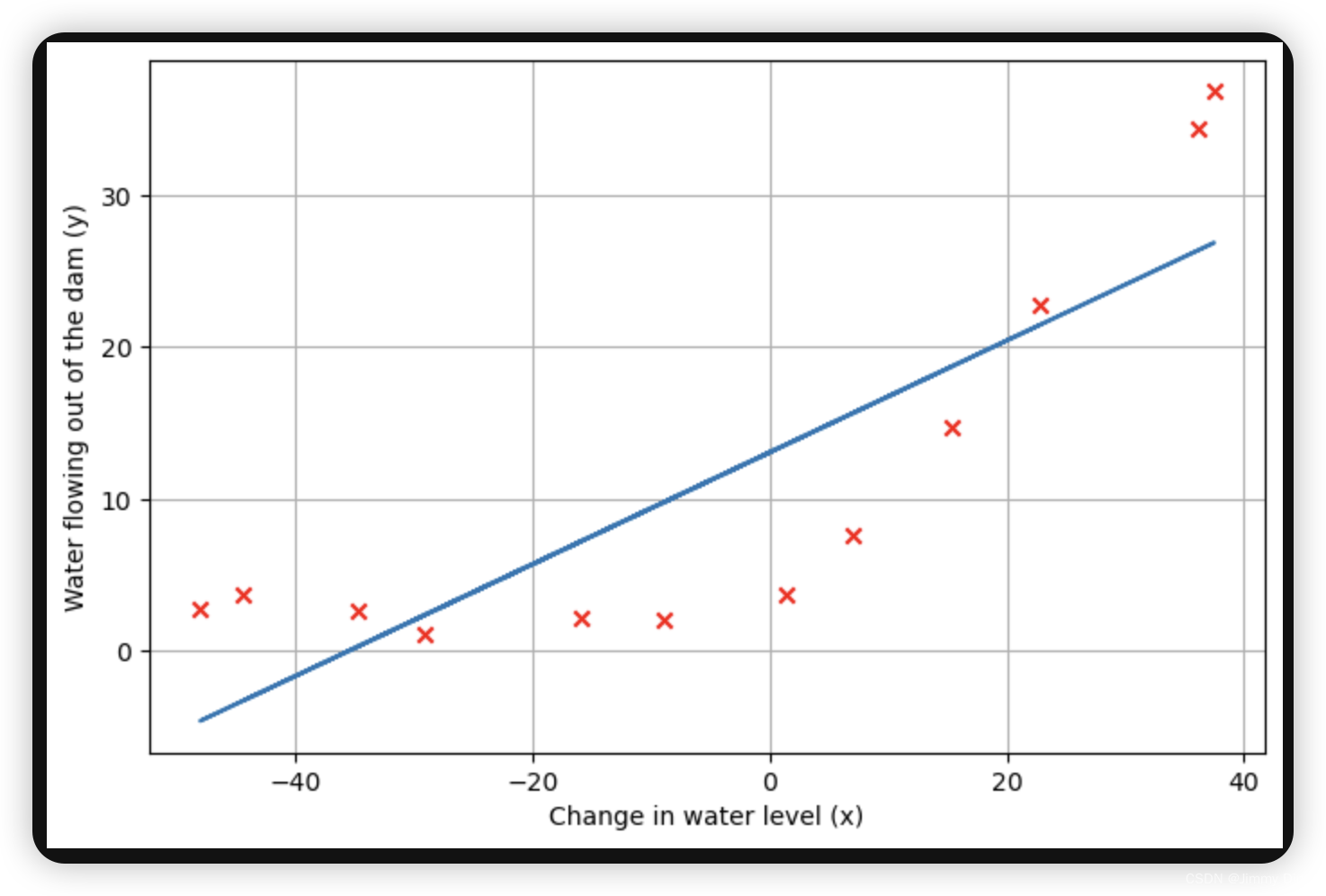
2 偏差-方差
机器学习中的一个重要概念是偏差-方差权衡。偏差大的模型对数据来说不够复杂,往往拟合不足,而方差大的模型则对训练数据拟合过度。
在这部分练习中,您将在学习曲线上绘制训练和测试误差图,以诊断偏差-方差问题。
2.1 学习曲线
现在,您将执行代码来生成学习曲线,这将有助于调试学习算法。回想一下,学习曲线是训练集和交叉验证误差与训练集大小的函数关系图。要绘制学习曲线,我们需要不同训练集大小的训练集和交叉验证集误差。要获得不同的训练集大小,应该使用原始训练集 X 的不同子集。具体来说,训练集大小为 i 时,应该使用前 i 个示例(即 X(1:i,:) 和 y(1:i))。请注意,lambda 会作为参数传递给 learningCurve 函数。学习完 θ 参数后,应计算训练集和交叉验证集上的误差。回想一下,数据集的训练误差定义为
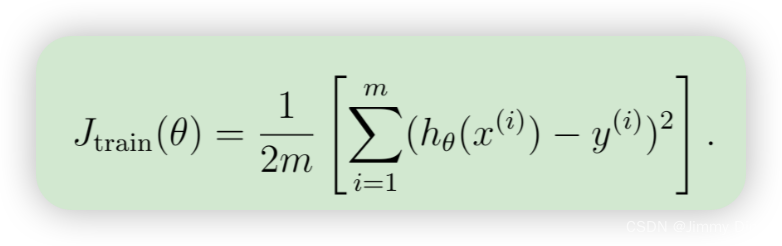
特别要注意的是,训练误差不包括正则化项。计算训练误差的一种方法是使用现有的代价函数,只有在计算训练误差和交叉验证误差时才将λ 设为 0。计算训练集误差时,请确保在训练子集(即 X(1:n,:) 和 y(1:n))上计算(而不是整个训练集)。但是,对于交叉验证误差,应该在整个交叉验证集上计算。完成计算后,ex5.m 将打印学习曲线,并生成与图 3 类似的曲线图。
python
def plot_learning_curve(X, y, Xval, yval, l):
"""画出学习曲线,即交叉验证误差和训练误差随样本数量的变化"""
xx = range(1, len(X) + 1) # 定义样本数量的范围,从1到训练集大小
training_cost, cv_cost = [], [] # 初始化训练误差和交叉验证误差的列表
for i in xx:
res = trainLinearReg(X[:i], y[:i], l) # 用前i个样本训练模型
training_cost_i = costReg(res, X[:i], y[:i], 0) # 计算训练误差,不正则化
cv_cost_i = costReg(res, Xval, yval, 0) # 计算交叉验证误差,不正则化
training_cost.append(training_cost_i) # 将当前训练误差加入列表
cv_cost.append(cv_cost_i) # 将当前交叉验证误差加入列表
plt.figure(figsize=(8,5)) # 设置图表大小
plt.plot(xx, training_cost, label='training cost') # 画出训练误差曲线
plt.plot(xx, cv_cost, label='cv cost') # 画出交叉验证误差曲线
plt.legend() # 显示图例
plt.xlabel('Number of training examples') # 设置x轴标签
plt.ylabel('Error') # 设置y轴标签
plt.title('Learning curve for linear regression') # 设置图表标题
plt.grid(True) # 显示网格
plot_learning_curve(X, y, Xval, yval, 0)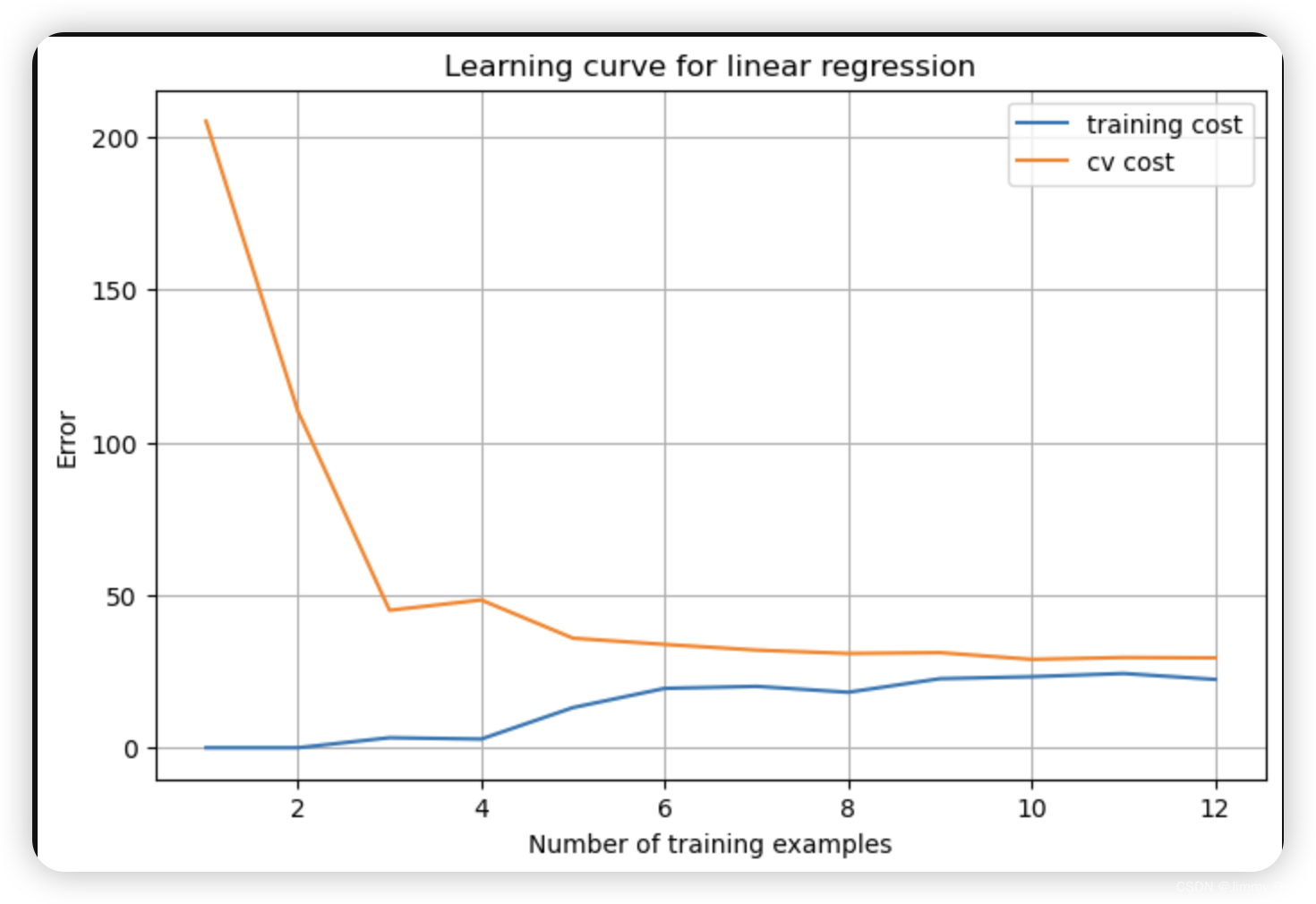
3.多项式回归
我们的线性模型的问题在于对于数据来说过于简单,导致拟合不足(偏差大)。在这部分练习中,您将通过添加更多特征来解决这个问题:
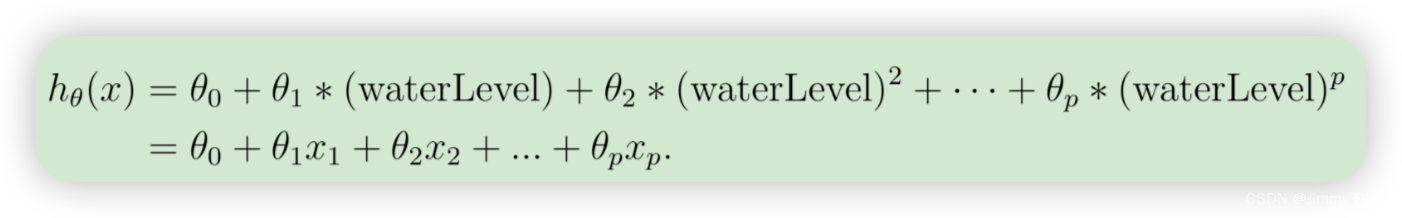
请注意,通过定义 x1 = (水位),x2 = (水位)2,... , xp =(水位)p,我们就得到了一个线性回归模型,其中的特征是原始值(水位)的不同幂次。现在,您将使用数据集中现有特征 x 的高次幂来添加更多特征。这部分的任务是完成 polyFeatures.m 中的代码,使函数能将大小为 m × 1 的原始训练集 X 映射为其高次幂。具体来说,当大小为 m × 1 的训练集 X 被传入函数时,函数应返回一个 m×p 矩阵 X poly。
其中第 1 列是 X 的原始值,第 2 列是 X.^2 的值,第 3 列是 X.^3 的值,以此类推。请注意,在此函数中不必考虑 0-eth 幂。现在您有了一个可以将特征映射到更高维度的函数,ex5.m 的第 6 部分将把它应用于训练集、测试集和交叉验证集(您还没有使用过)。
3.1 学习多项式回归
完成 polyFeatures.m 后,ex5.m 脚本将继续使用线性回归成本函数训练多项式回归。请记住,即使我们的特征向量中包含了多项式项,我们解决的仍然是线性回归优化问题。多项式项只是变成了我们可以用于线性回归的特征。我们使用的成本函数和梯度与本练习前半部分所写的相同。在这部分练习中,您将使用阶数为 8 的多项式。 事实证明,如果我们直接在投影数据上运行训练,效果并不好,因为特征会严重缩放(例如,x = 40 的示例现在的特征为 x8 = 408 = 6.5 × 1012)。因此,您需要对特征进行归一化处理。在学习多项式回归的参数 θ 之前,ex5.m 将首先调用 featureNormalize 对训练集的特征进行归一化,并分别存储 mu 和 sigma 参数。我们已经为您实现了这个函数,它与第一个练习中的函数相同。学习完参数 θ 后,您会看到两幅图(图 4、图 5),这两幅图是为λ = 0 的多项式回归生成的。从图 4 可以看出,多项式拟合能够很好地跟踪数据点,因此训练误差很小。然而,多项式拟合非常复杂,甚至在极值处会出现下降。为了更好地理解非正则化(λ = 0)模型的问题,您可以看到学习曲线(图 5)显示了相同的效果,即训练误差低,但交叉验证误差高。训练误差和交叉验证误差之间存在差距,表明存在高方差问题。
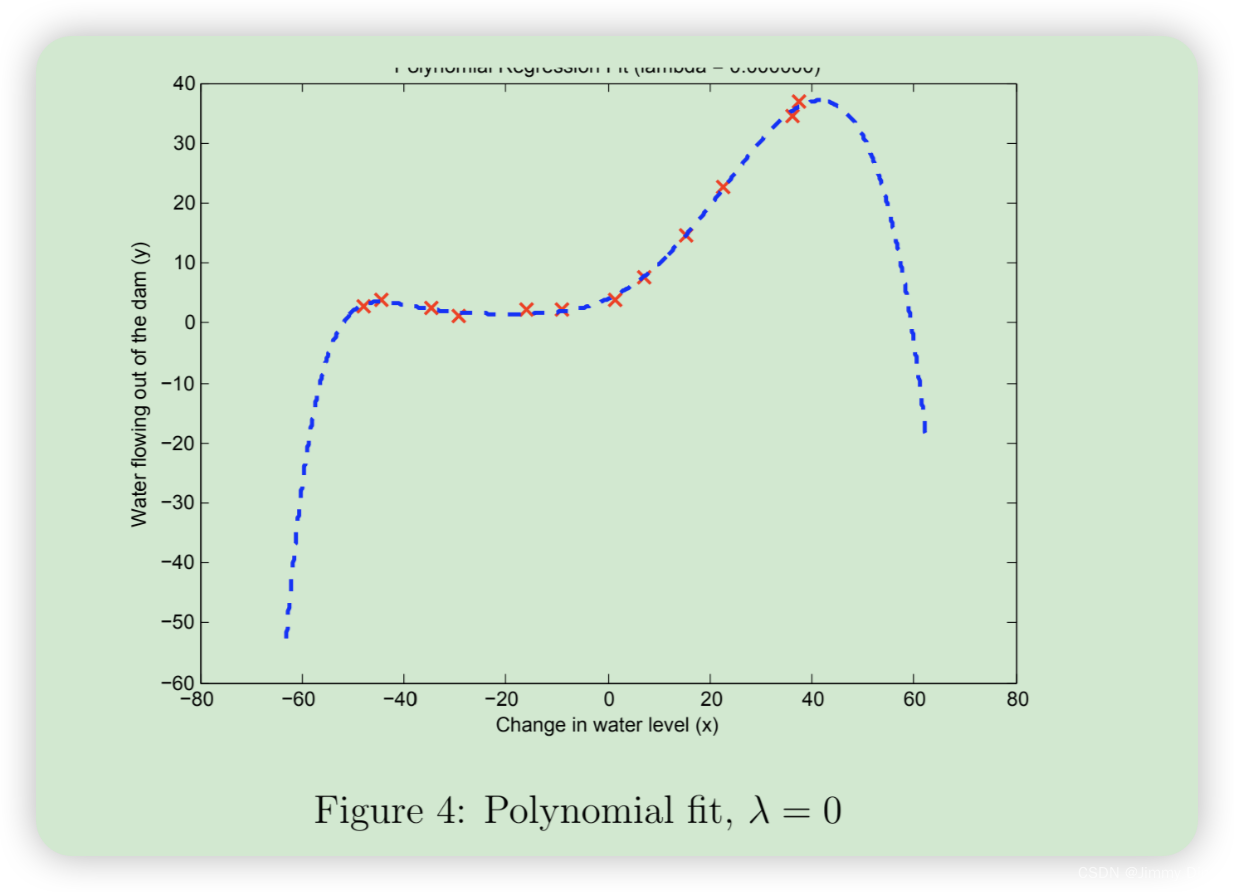
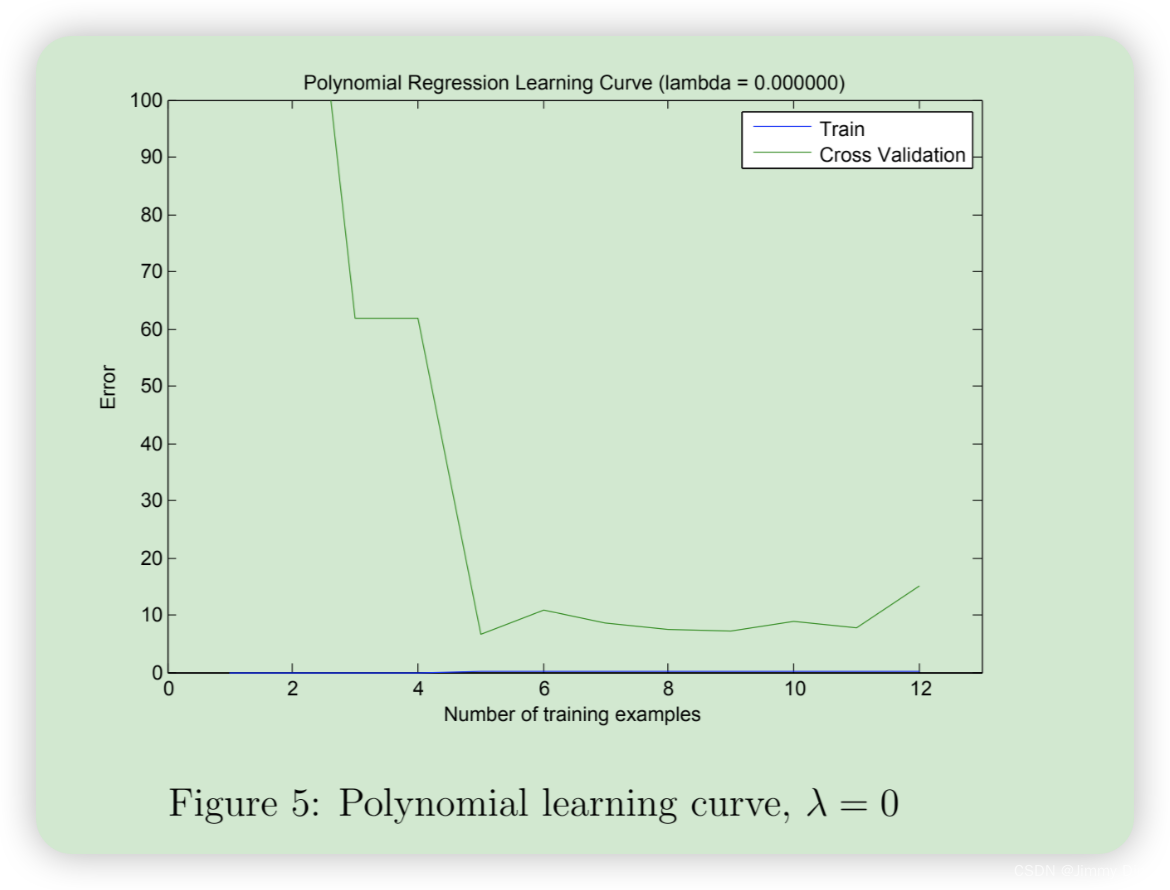
解决过拟合(高方差)问题的方法之一是为模型添加正则化。在下一节中,您将尝试不同的 λ 参数,以了解正则化如何带来更好的模型。
python
def genPolyFeatures(X, power):
"""
添加多项式特征。
每次在数组的最后一列插入第二列的i+2次方(第一列为偏置)。
从二次方开始插入(因为本身含有一列一次方)。
"""
Xpoly = X.copy() # 复制原始数据,以免修改原数据
for i in range(2, power + 1):
# 在数组的最后一列插入第二列的i次方
Xpoly = np.insert(Xpoly, Xpoly.shape[1], np.power(Xpoly[:, 1], i), axis=1)
return Xpoly # 返回包含多项式特征的数据
def get_means_std(X):
"""
获取训练集的均值和标准差,用来标准化所有数据。
"""
means = np.mean(X, axis=0) # 计算每列的均值
stds = np.std(X, axis=0, ddof=1) # 计算每列的标准差,ddof=1表示样本标准差
return means, stds # 返回均值和标准差
def featureNormalize(myX, means, stds):
"""
标准化特征。
"""
X_norm = myX.copy() # 复制输入数据,以免修改原数据
X_norm[:, 1:] = X_norm[:, 1:] - means[1:] # 每列减去均值
X_norm[:, 1:] = X_norm[:, 1:] / stds[1:] # 每列除以标准差
return X_norm # 返回标准化后的数据
python
# 扩展到 x 的 6 次方
power = 6
# 生成多项式特征并获取训练集的均值和标准差
train_means, train_stds = get_means_std(genPolyFeatures(X, power))
# 对训练集进行特征标准化
X_norm = featureNormalize(genPolyFeatures(X, power), train_means, train_stds)
# 对验证集进行特征标准化
Xval_norm = featureNormalize(genPolyFeatures(Xval, power), train_means, train_stds)
# 对测试集进行特征标准化
Xtest_norm = featureNormalize(genPolyFeatures(Xtest, power), train_means, train_stds)
python
def plot_fit(means, stds, l):
"""画出拟合曲线"""
# 使用训练数据和正则化参数训练线性回归模型,得到模型参数 theta
theta = trainLinearReg(X_norm, y, l)
# 生成从 -75 到 55 的等间距数值,共 50 个,用于绘制拟合曲线
x = np.linspace(-75, 55, 50)
# 将 x 转换成列向量,并在第一列插入 1(偏置项)
xmat = x.reshape(-1, 1)
xmat = np.insert(xmat, 0, 1, axis=1)
# 生成 xmat 的多项式特征,扩展到 power 次方
Xmat = genPolyFeatures(xmat, power)
# 使用训练集的均值和标准差对 Xmat 进行特征标准化
Xmat_norm = featureNormalize(Xmat, means, stds)
# 画出原始数据点
plotData()
# 画出拟合曲线
plt.plot(x, Xmat_norm @ theta, 'b--')
python
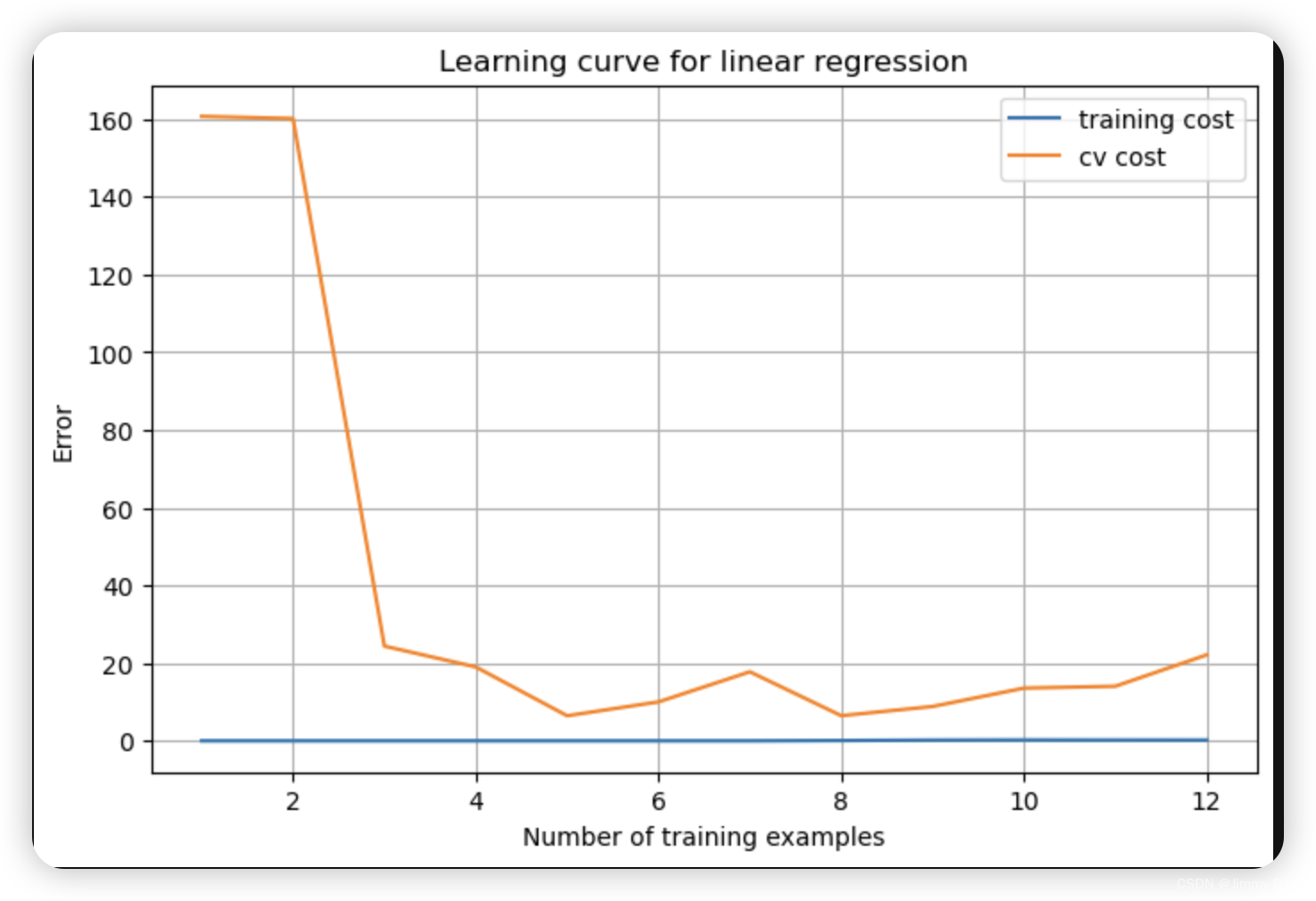
plot_fit(train_means, train_stds, 0)
plot_learning_curve(X_norm, y, Xval_norm, yval, 0)
3.2 正则化参数的调整
当 λ = 0时,我们从上图可以看出明显处于过拟合状态。
在本节中,您将观察正则化参数如何影响正则化多项式回归的偏差-方差。现在,您应该修改 ex5.m 中的 lambda 参数,并尝试 λ = 1、100。对于每一个值,脚本都会生成一个多项式拟合数据和一条学习曲线。
对于 λ = 1,你应该看到一个能很好地跟随数据趋势的多项式拟合(图 6)和一个显示交叉验证和训练误差都收敛到一个相对较低值的学习曲线(图 7)。这表明 λ = 1 正则化多项式回归模型不存在高偏差或高方差问题。实际上,它在偏差和方差之间实现了很好的权衡。
python
plot_fit(train_means, train_stds, 1)
plot_learning_curve(X_norm, y, Xval_norm, yval, 1)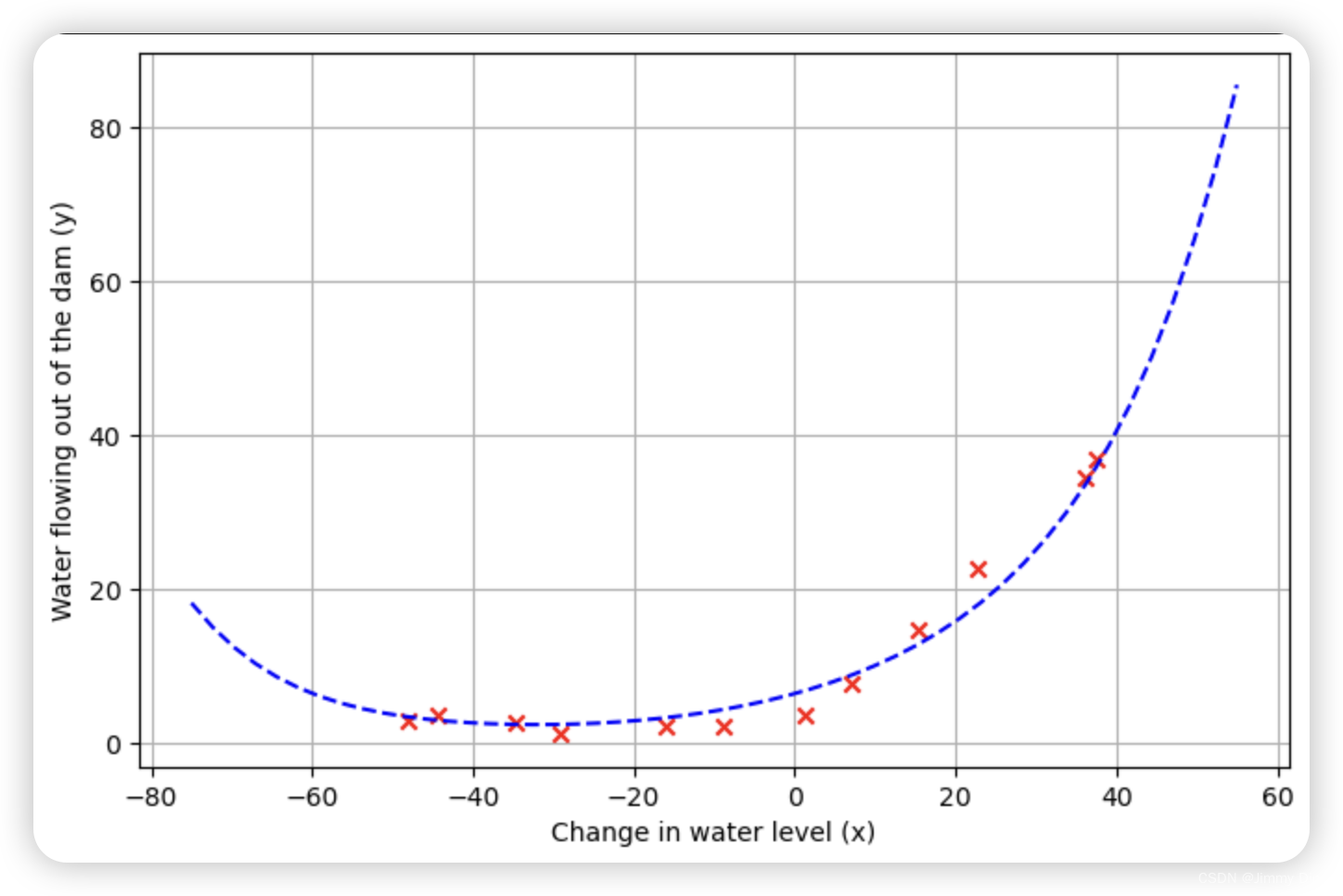
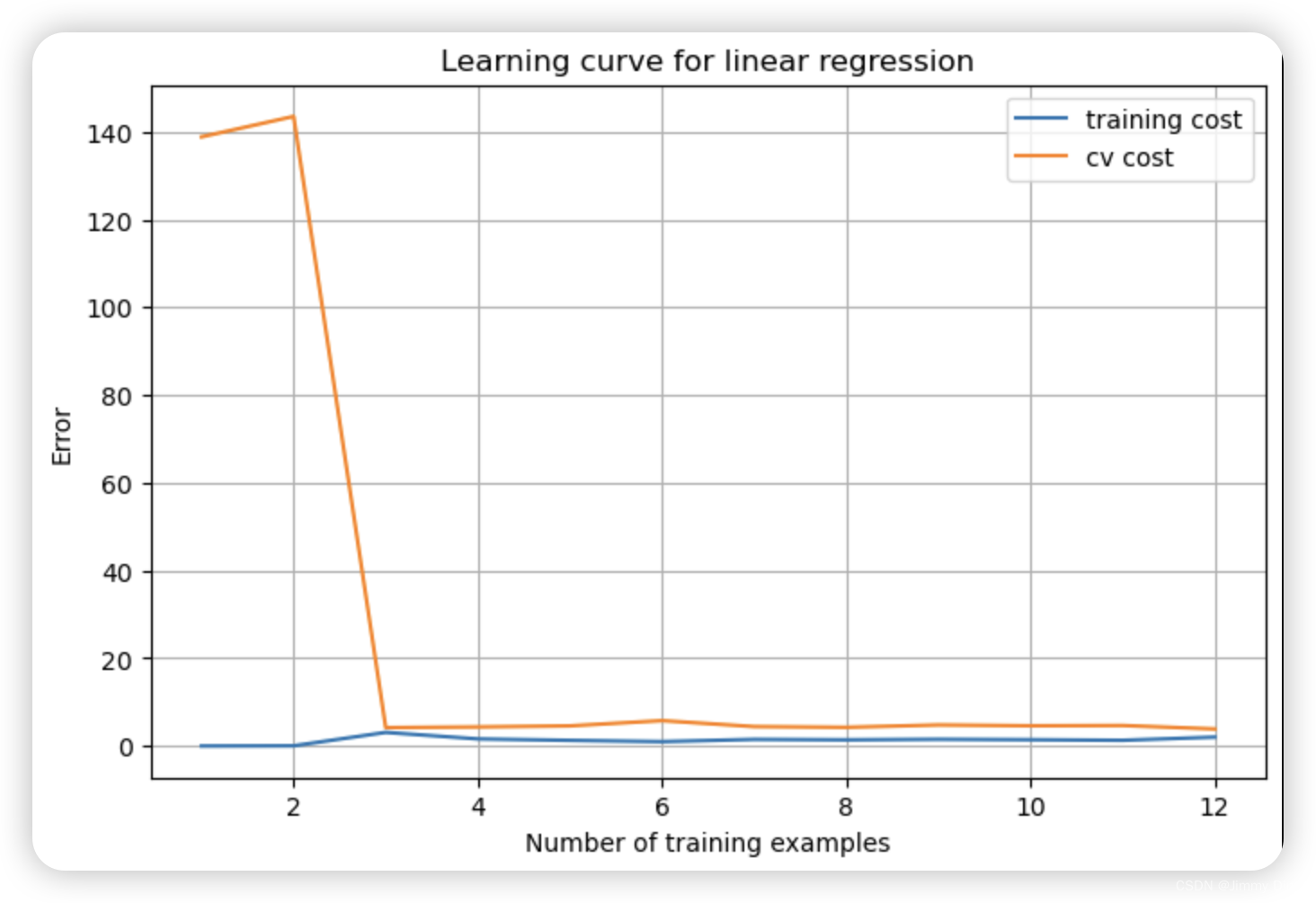
在 λ = 100 的情况下,您应该会看到一个多项式拟合结果(图 8),该拟合结果与数据不符。在这种情况下,正则化过多,模型无法拟合训练数据。
python
plot_fit(train_means, train_stds, 100)
plot_learning_curve(X_norm, y, Xval_norm, yval, 100)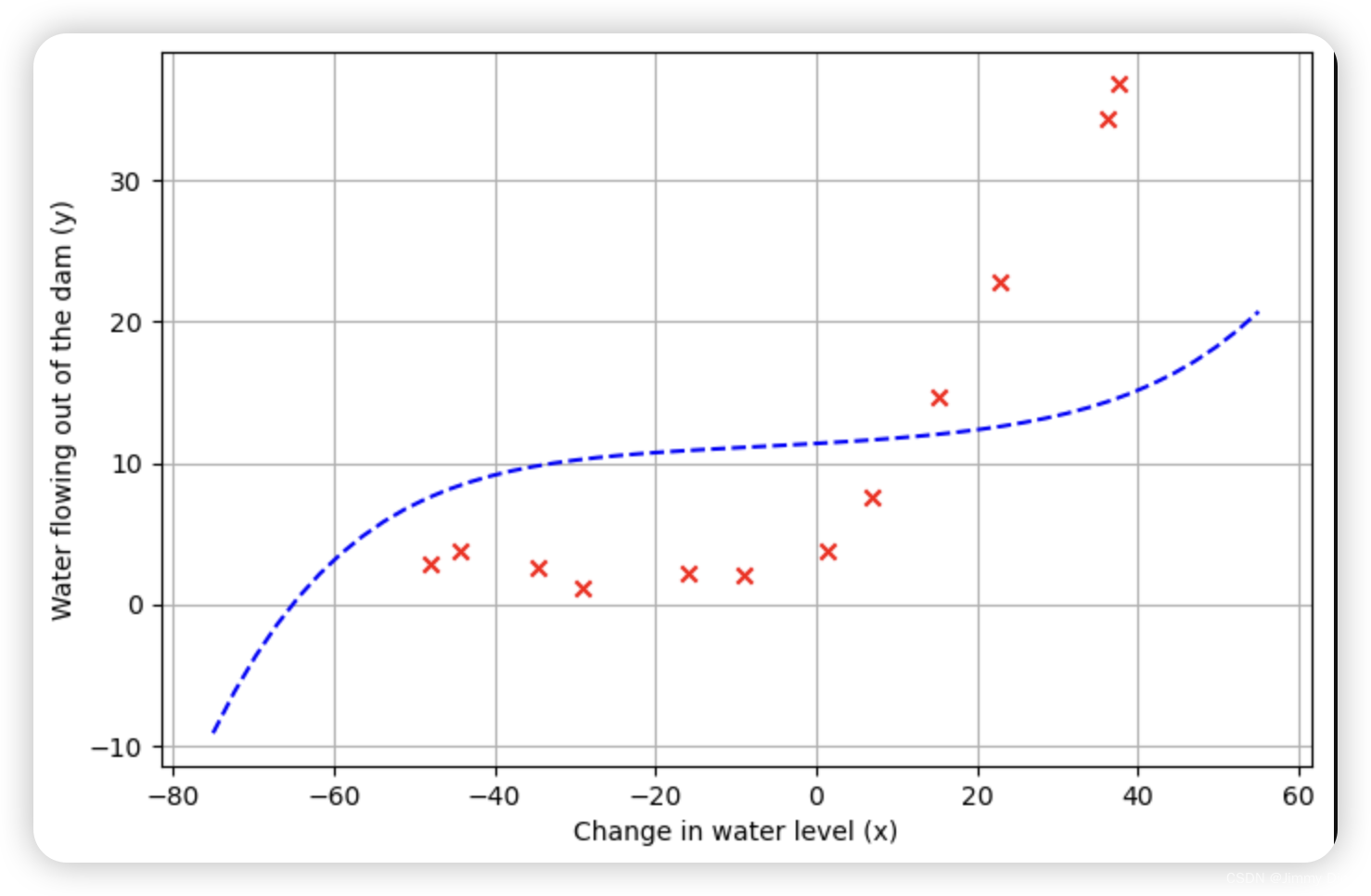

3.3 使用交叉验证集选择 λ
在前面的练习中,您发现 λ 值会显著影响训练集和交叉验证集上的正则化多项式回归结果。特别是,没有正则化的模型(λ = 0)能很好地拟合训练集,但不能泛化。相反,正则化程度过高的模型(λ = 100)则不能很好地适应训练集和测试集。选择一个好的λ(例如λ = 1)可以很好地拟合数据。在本节中,您将使用一种自动方法来选择 λ 参数。具体来说,您将使用交叉验证集来评估每个 λ 值的优劣。使用交叉验证集选出最佳 λ 值后,我们就可以在测试集上评估模型,以估计模型在实际未见数据上的表现。您的任务是完成 validationCurve.m 中的代码。具体来说,您应该使用 trainLinearReg 函数使用不同的 λ 值训练模型,并计算训练误差和交叉验证误差: {0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10}.
python
# 定义不同的正则化参数 lambda 值列表
lambdas = [0., 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1., 3., 10.]
# 初始化列表,用于存储训练误差和交叉验证误差
errors_train, errors_val = [], []
# 遍历每个 lambda 值
for l in lambdas:
# 使用当前的 lambda 值训练线性回归模型,得到模型参数 theta
theta = trainLinearReg(X_norm, y, l)
# 计算当前 lambda 值下的训练误差,并将其添加到 errors_train 列表中
errors_train.append(costReg(theta, X_norm, y, 0)) # 计算训练误差时 lambda = 0,不进行正则化
# 计算当前 lambda 值下的交叉验证误差,并将其添加到 errors_val 列表中
errors_val.append(costReg(theta, Xval_norm, yval, 0))
# 创建绘图窗口
plt.figure(figsize=(8, 5))
# 绘制训练误差随 lambda 变化的曲线
plt.plot(lambdas, errors_train, label='Train')
# 绘制交叉验证误差随 lambda 变化的曲线
plt.plot(lambdas, errors_val, label='Cross Validation')
# 添加图例
plt.legend()
# 设置 x 轴标签
plt.xlabel('lambda')
# 设置 y 轴标签
plt.ylabel('Error')
# 添加网格线
plt.grid(True)
# 显示图像
plt.show()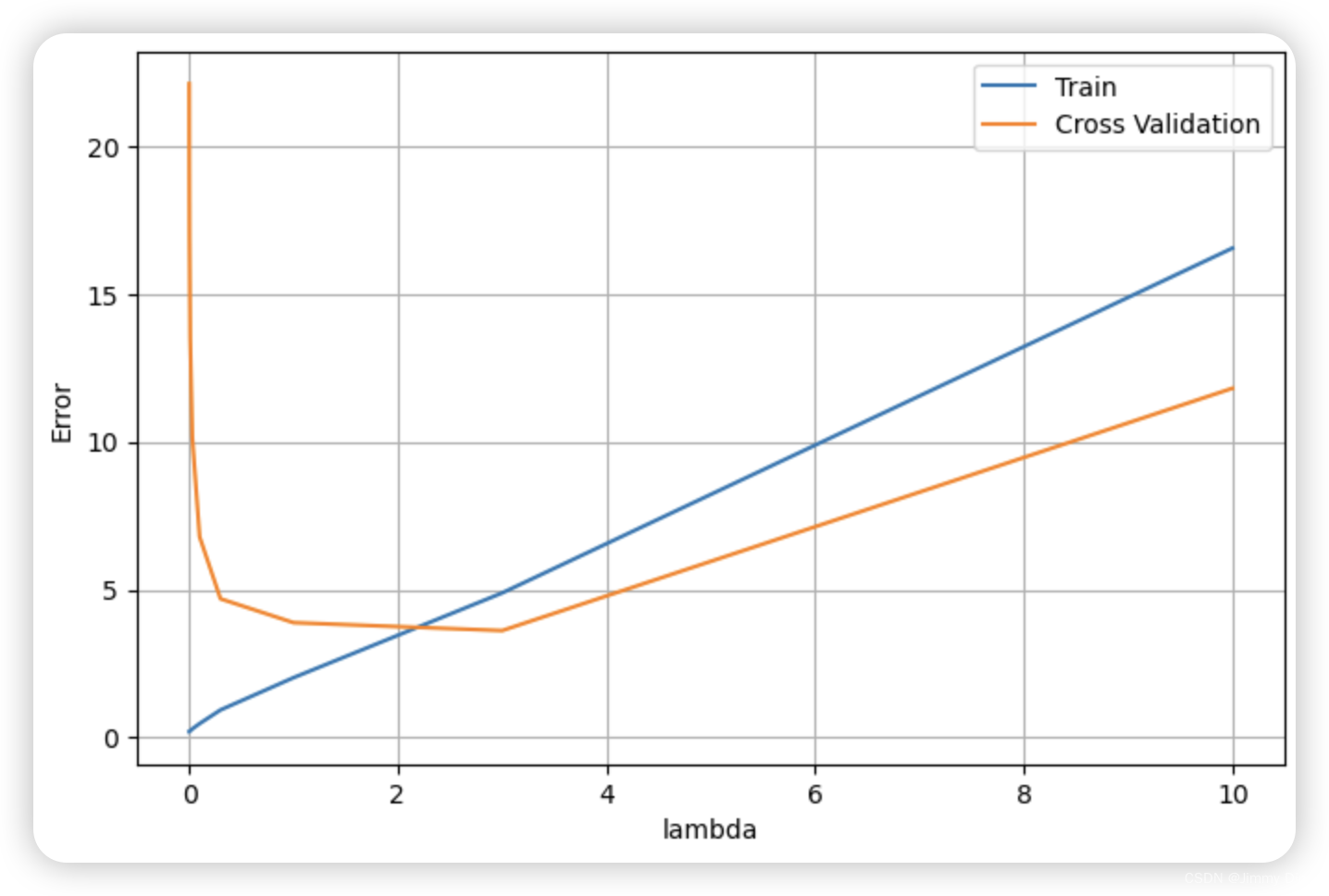
python
# 可以看到时交叉验证代价最小的是 lambda = 3
lambdas[np.argmin(errors_val)] # 3.03.4 计算测试集误差
然而,为了更好地反映模型在现实世界中的性能,在没有用于任何训练部分(即既没有用于选择 λ 参数,也没有用于学习模型参数 θ)的测试集上评估 "最终 "模型是非常重要的。对于这个可选(不计分)练习,您应该使用您发现的最佳 λ 值计算测试误差。在交叉验证中,λ = 3 时的测试误差为 3.8599。
python
theta = trainLinearReg(X_norm, y, 3)
print('test cost(l={}) = {}'.format(3, costReg(theta, Xtest_norm, ytest, 0)))