下载redis数据库
首先需要下载redis数据库,可以直接去Redis官网下载。或者可以看这里下载过程。
pycharm项目文件下载redis库
python
> pip install redis 然后在程序中连接redis服务:
python
from redis import Redis
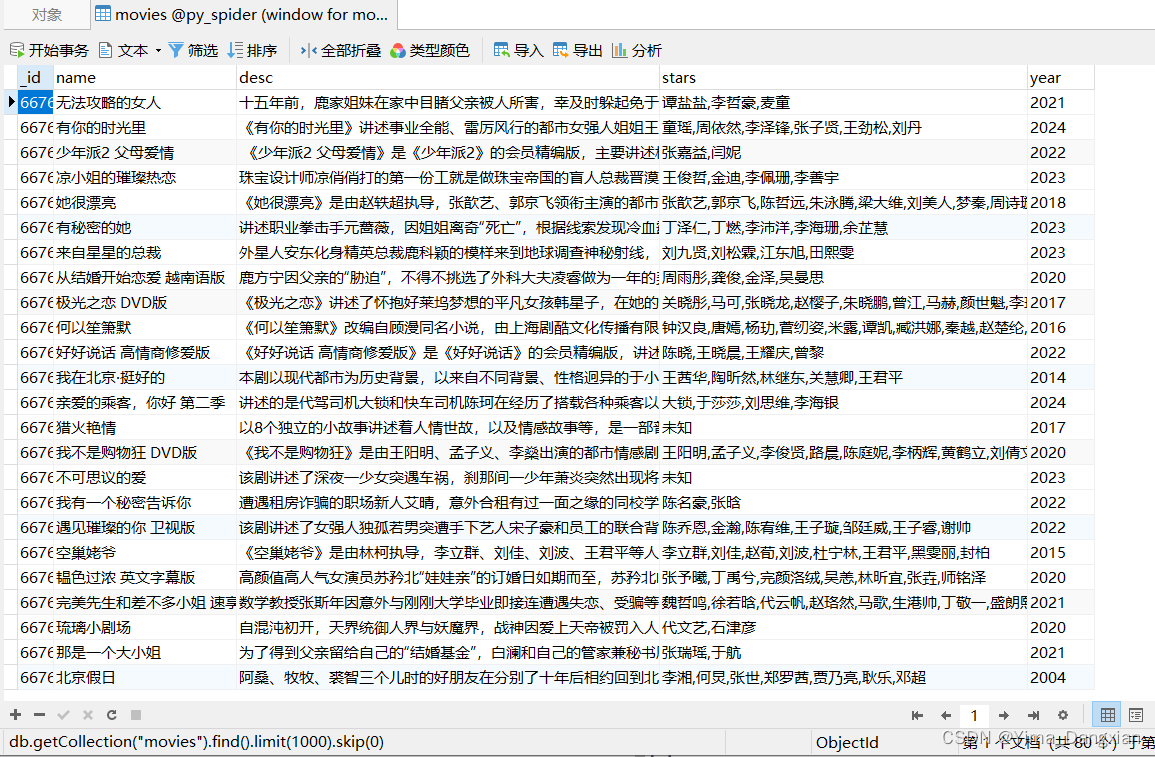
redisObj = Redis(host='127.0.0.1', port=6379)这次笔记记录爬取芒果TV的视频信息,通过md5加密并去重存入Redis数据库。
爬取视频的名称,简介、演员及上映时间吧,代码示例:
python
import requests
import redis
import pymongo
import hashlib
import json
import time
class MangGuo:
url = 'https://pianku.api.mgtv.com/rider/list/pcweb/v3?allowedRC=1&platform=pcweb&channelId=2&pn=3&pc=80&hudong=1&_support=10000000&kind=19&area=10&year=all&chargeInfo=a1&sort=c2&feature=all'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
def __init__(self):
self.redis_obj = redis.Redis(host="localhost", port=6379)
self.mongo = pymongo.MongoClient()
self.mongo_connection = self.mongo['py_spider']['movies']
@classmethod
def get_tv_list(cls):
response = requests.get(cls.url, headers=cls.headers).json()
# print(response["data"]["hitDocs"])
return response["data"]["hitDocs"]
def parse_tv_list(self):
data_lists = self.get_tv_list()
for data in data_lists:
deal_data = dict()
deal_data["name"] = data["title"]
deal_data["desc"] = data["story"]
deal_data["stars"] = data["subtitle"]
deal_data["year"] = data["year"]
print(deal_data)
# obj = hashlib.md5()
# obj.update(json.dumps(data).encode())
# res = obj.hexdigest()
hash_obj = hashlib.md5(json.dumps(deal_data).encode()).hexdigest()
self.insert_redis(deal_data, hash_obj)
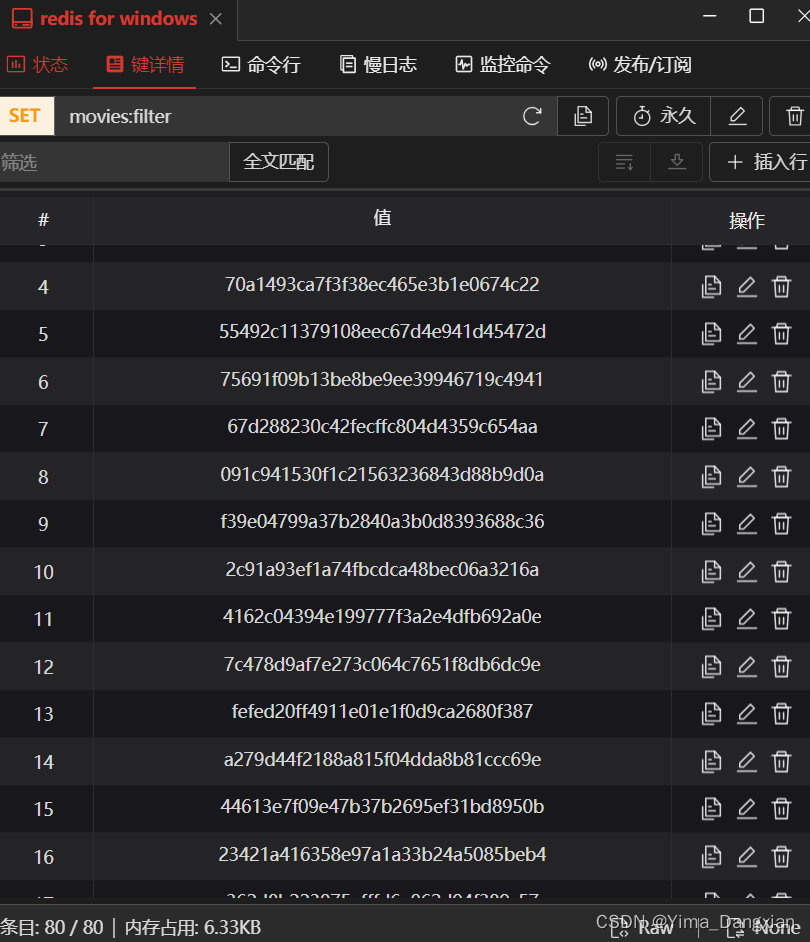
# 插入数据到Redis数据库并进行去重
def insert_redis(self, data, hash_data):
result = self.redis_obj.sadd('movies:filter', hash_data)
# 插入数据成功返回1,失败返回0
# print(result)
if result:
print('数据插入成功')
# 插入成功说明是没有重复数据的,也就是作去重后多插入一份到MongoDB数据库
self.insert_mongodb(data)
else:
print('重复数据,插入失败')
def insert_mongodb(self, data):
self.mongo_connection.insert_one(data)
# 休眠测试是否同步
# time.sleep(1.5)
def main(self):
self.parse_tv_list()
if __name__ == '__main__':
manGuo = MangGuo()
manGuo.main()结果如下图,以下是数据库的可视化界面软件:
数据进行加密存入Redis数据库:
数据存入MongoDB: