云计算综合测试题
单选题
- 这里选择题,直接以填空题展示,并给出解析
- Bigtable是(Google)开发的分布式存储系统
- 解析:分布式结构化数据表Bigtable是Google基于GFS和Chubby开发的分布式存储系统。
- WAS的存储名空间中,账户名负责将访问请求定位(集群)
- 解析:WAS(Windows Azure Stroage)实现单一的全局命名空间(账户名、分区名、对象名)。账户名经DNS翻译可定位到数据中心和主存储集群;分区名可进一步定位到存储节点;对象名定位到对象
- 于WAS的文件流层,以下说法正确的(可以追加写,但不能修改现有的数据)
- 解析:文件流层只为分区层提供一个内部使用的接口,所有的写只能追加。允许用户的操作有:打开、关闭、删除、重命名、读、追加以及合并(没有修改操作)
- 关于SimpleDB和DynamoDB,以下描述正确的(SImpleDB限制了每张表的大小,DynamoDB不限制每张表的大小)
- 解析:
- SimpleDB:限制每张表的大小,更适合于小规模负载的工作
- DynamoDB:不限制表的大小、适用于大规模的工作
- vNetwork的虚拟交换机通过(上行链路)连接到物理以太网适配器。
- 解析:上行链路是指从虚拟交换机到物理网络设备的连接,这个连接使得虚拟网络能够与外部物理网络进行通信。
- Bigtable中,数据划分和负载均衡的基本单位是(表)。
- 解析:由于规模问题,单个的大表不利于数据的处理,因此Bigtable将一个表分成了很多子表(Tablet),每个子表包含多个行。子表是Bigtable中数据划分和负载均衡的基本单位。
- GFS使用Chubby主要用来(选取主服务器)
- 解析:GFS使用Chubby选取一个GFS主服务器,Bigtable使用Chubby指定一个主服务器并发现、控制与其相关的子表服务器。
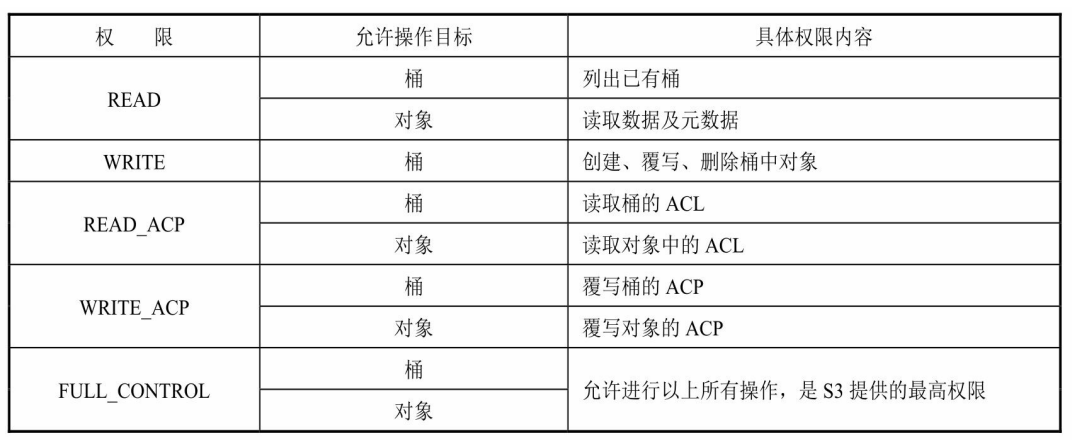
- S3的访问控制策略中,"所有者"拥有(WRITE_ACP)权限,相当于拥有了最高权限。
- 解析:所有者是桶或对象的创建者,默认具是WRITE_ACP权限。但是所有者可以通过覆写相应桶或对象的ACP获取想要的权限,从这个意义上来说,所有者默认就是最高权限拥有者。
- GFS的默认Chunk大小(64MB)
- 解析:GFS将文件按照固定大小进行分块,默认是64MB,每一块称为一个Chunk(数据块)
- Windows Azure平台的四个组成部分中,(AppFabric)为在云中或本地系统中的应用提供基于云的基础架构服务
- 解析:
组成部分 说明 Windows Azure 微软云计算操作系统,提供在微软数据中心服务器上运行应用程序和存储数据的Windows环境 SQL Azure 云中的关系数据库,为云中基于SQL Server的关系型数据提供服务 Windows Azure AppFabric 为在云中或本地系统中的应用提供基于云的基础架构服务 Windows Azure Marketplace 为购买云计算环境下的数据和应用提供在线服务
填空题
- Paxos算法是为了解决分布式系统的(一致性)问题
- 解析:Paxos算法一种基于消息传递(Messages Passing)的一致性算法,用于解决分布式系统中的一致性问题。
- EC2中的实例由(AMI)启动,可以像传统的主机一样提供服务。
- 解析:Amazon机器映像(Amazon Machine Image,AMI)是包含操作系统、服务器程序、应用程序等软件配置的模板,可以用于启动不同实例,进而像传统的主机一样提供服务。
- (Chunk Server)的数目决定了Google文件系统GFS的规模。
- 解析:Chunk Server负责具体的存储工作。数据以文件的形式存储在Chunk Server上,ChunkServer的个数可以有多个,它的数目直接决定GFS的规模。
- 云计算是在2006年8月,由(Google)公司首席执行官提出。
- 解析:2006年8月9日,谷歌首席执行官埃里克·施密特在搜索引擎大会上首次提出云计算的概念,并说谷歌自1998年创办以来,就一直采用这种新型的计算方式。
- Megastore中共有三种副本,分别是完全副本、(见证者副本)和只读副本。
- 解析:Megastore的基本架构,最底层的数据是存储在Bigtable中的。不同类型的副本存储不同的数据。在Megastore中共有三种副本,分别是完整副本(Full Replica)、见证者副本(Witness Replica)和只读副本(Read-only Replica)。
- 虚拟拟机的迁移过程中,以共享的方式共享数据和文件系统,而非真正迁移的是(存储设备的迁移)
- 解析:迁移存储设备的最大障碍在于需要占用大量时间和网络带宽,通常的解决办法是以共享的方式共享数据和文件系统,而非真正迁移。
- Dremel中的重复深度只考虑(可重复)类型的字段。
- 解析:重复深度主要关注的是可重复类型,而定义深度同时关注可重复类型(repeated)和可选类型(optional)。
- WAS的存储域包括前端、分区层和(文件流层)三层结构
- 解析:WAS存储域的层次结构:前端、分区层和文件流层
- 前端:由一组无状态服务器构成来处理访问请求。一旦接收到一个请求,该层便会查找账户名,认证请求,再把请求路由到分区层的服务器。
- 分区层。该层负责管理和理解上层数据抽象类型(Blob、表、队列和文件),提供一个可扩展的名空间,保证数据对象事务处理顺序和强一致性,在数据流层之上存储数据,缓存数据对象来减少磁盘I/O。
- 文件流层:该层存储数据在硬盘上,负责在多个服务器间分布和复制数据来保持存储域中数据的可用性。
- 当虚拟机中的操作系统通过特权指令访问关键系统资源时,每条特权指令的执行都要产生(自陷),Hypervisior才能接管其请求。
- 解析:为了使这种机制能够有效地运行,每条特权指令的执行都需要产生"自陷",以便Hypervisor能够捕获该指令,从而使VMM能够模拟执行相应的指令
- SQLAzure数据库同步服务使用(轮辐式)模型,所有的变化首先被复制到SQLAzure数据库hub上,然后再传送到其他spoke上。
- 解析:SQL Azure数据同步服务使用"轮辐式(hub-and-spoke)"模型,所有的变化将会首先被复制到SQL Azure数据库"hub"上,然后再传送到其他"spoke"上。
判断题
- Google的监控基础架构中,为了尽可能地减少开销,采用的方案是二次压缩(❎)
- 解析:监控开销的大小直接决定Dapper的成败,为了尽可能地减小开销,进而将Dapper广泛部署在Google中,设计人员设计了一种非常巧妙的二次抽样方案。
- Bigtable中,客户端和服务器之间传输的是数据流(❎)
- 解析:客户端与主服务器之间传输的是控制流;客户端与子表服务器之间的传输的是数据流
- Bigtable中,实际的数据都是以子表的形式保存在子表服务器中(✅)
- 解析:Bigtable中实际的数据都是以子表的形式保存在子表服务器上的,客户一般也只和子表服务器进行通信
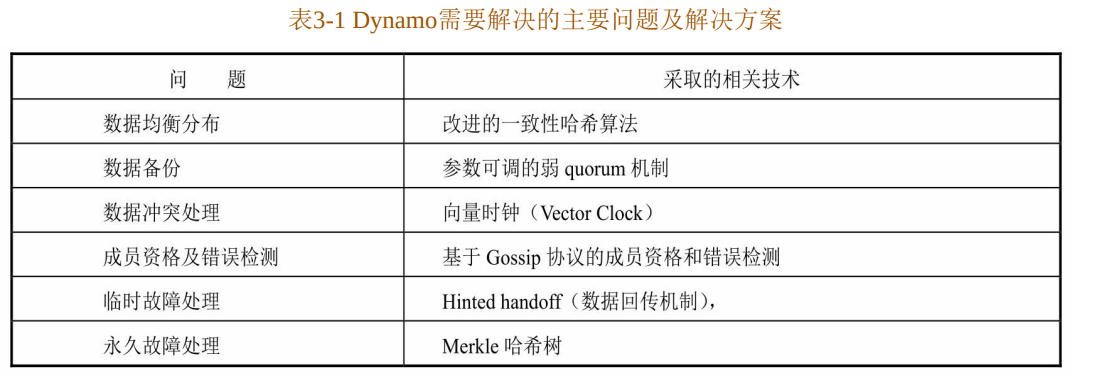
- Dynamo采用一致性哈希算法解决数据冲突的问题(❎)
- 解析:
- 虚拟机的迁移过程中,最有难度和挑战性的是CPU的迁移(❎)
- 解析:内存的迁移是虚拟机迁移最困难的部分
- Google云计算系统采用的是完全的分布式和去中心化结构(✅)
- 解析:为了保证其稳定性,Amazon的系统采用完全的分布式、去中心化的架构。其中,作为底层存储架构的Dynamo也同样采用了无中心的模式。
- Bigtable中的SSTable数量过多,将会显著影响写操作的速度(❎)
- 解析:由于读操作要使用SSTable,数量过多的SSTable显然会影响读的速度
- Amazon限制用户在S3中创建桶的数量,但不限制每个桶中对象的数量(✅)
- 解析:Amazon限制了每个用户创建桶的数量,但没有限制每个桶中对象的数量。
- 半虚拟化技术包括软件辅助虚拟化和硬件辅助虚拟化(❎)
- 解析:半虚拟化技术是一种虚拟化技术,它要求操作系统知道自己是虚拟化的,并对操作系统内核进行修改以适应虚拟化环境。。典型的半虚拟化技术代表是Xen。软件辅助虚拟化和硬件辅助虚拟化是指全虚拟化技术(Full Virtualization)中的两种实现方式。
- Megastore三种读中,Current允许读的时候还有部分事务提交了但还未生效(❎)
- 解析:在Megastore中共有三种副本,分别是完整副本(Full Replica)、见证者副本(Witness Replica)和只读副本(Read-only Replica)
- 完整副本,Bigtable中存储完整的日志和数据
- 见证者副本:决议时参与投票,Bigtable只存储其日志而不存储具体数据。无法参与投票。作用只是读取到最近过去某一个时间点的一致性数据
简答题
- Windows Azure存储服务采用了双复制引警,请简要回答什么是域内复制,什么是域间复制,它们各有什么作用。
- 解析:
- 域内复制:WAS在文件流层实现同步复制,保证存储域内的所有数据在其内部是可靠的。
- 域内复制的作用:域内复制专门为硬件失效而设计,保证WAS提供快速见状的存储响应
- 域间复制:WAS系统在分区层实现跨存储域的异步复制。
- 域间复制的作用:域间复制提供跨地域冗余来防止地域灾难,和位置服务结合起来,提供跨数据中心的数据处理。
- Google云计算中,大规模分布式系统的监控基础架构Dapper为了解决低开销及广泛可部署性的问题,采用了二次抽样技术。试简述二次抽样中,每次抽样的原理和作用。
- 解析:
- 首次抽样:在数据收集阶段,Dapper首先对所有的请求进行初步抽样。这个抽样率通常设置得较低,例如1%或更少,只有一小部分请求会被记录和跟踪。
- 二次抽样:在首次抽样的基础上,Dapper进一步对已经抽样的数据进行再次抽样。抽样的目的是进一步减少数据量,同时保持数据的代表性。
- 二次抽样的作用:降低开销、提高可部署性、确保分析结果的准确性和可靠性、
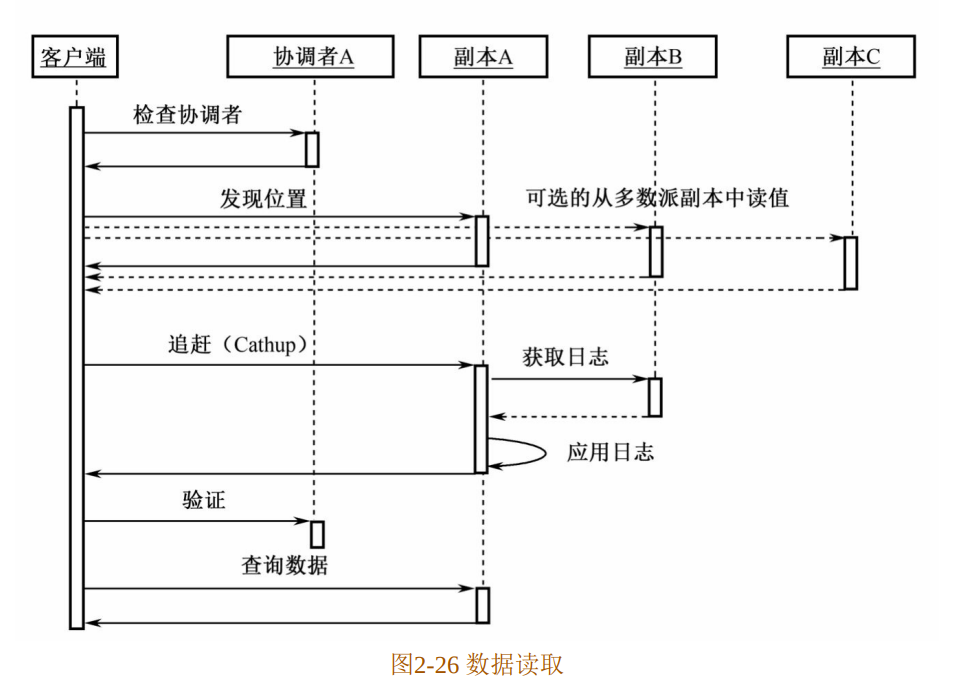
- 简述Magastore数据读取操作的五个步骤
- 解析:
- 本地查询:查询协调者判断实体组上数据是否已经最新
- 发现位置:确定最新日志位置,选择一个已生效的副本。采用本地读取(Local Read)或者多数派读取值
- 追赶:一旦某个副本被选中,就使其追赶到已知的最大日志位置处。
- 验证:如果本地副本被选中且数据不是最新,发送验证消息到协调者断定对能够反馈所有提交的写操作。无须等待回应,如果请求失败,下一个读操作会重试。
- 查询数据:在所选的副本中利用日志位置的时间戳读取数据。
- S3数字签名的实施过程图所示,试用文字简述该过程。
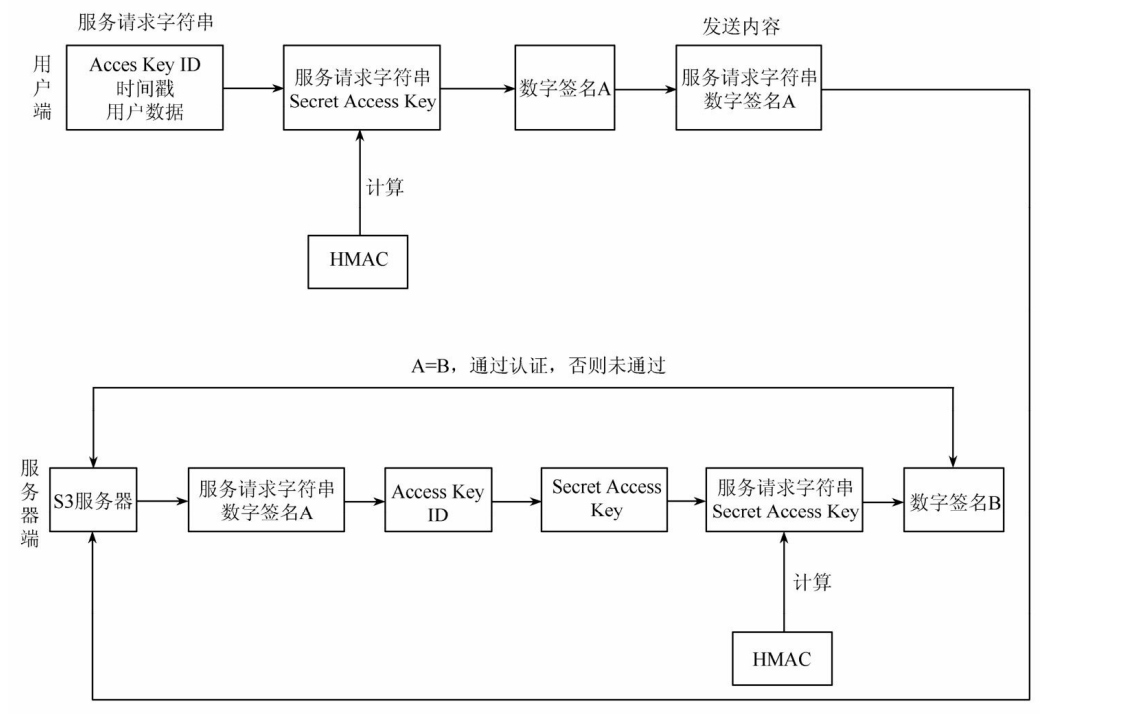
- 解析:
- S3用户首先发出服务请求,系统自动生成一个服务请求字符串。HMAC函数根据用户的服务请求字符串和Secret Access Key生成数字签名A,并将签名A和服务请求字符串传给S3服务器。
- 服务器接收到信息后,分离出用户的AccessKey ID,通过查询S3数据库得到用户的Secret Access Key。利用和上面相同的过程生成数字签名B,然后和数字签名A做比对,相同则通过验证,反之拒绝。