弹指间,2009年大学毕业到现在2024年,已经15年过去了。
前2天,看到自己2014年在博客园写的一个博客, 那个时候是工作之余创业。

感兴趣的朋友可以看看我10年前发的一篇博客 https://www.cnblogs.com/likwo/p/3832795.html
目前全职创业中,用过不少开源软件,比如php的workerman , swoole等,但老实话,开源的项目质量非常高,也对我的项目开发提升非常多。
目前大模型非常火爆,很多企业一直想把大模型用在企业的客服中,但是基本上没有太多的成功案例。这个事情,我思考了下
1. 企业的客服服务是非常严谨的,不能乱回答。
比如在电商场景,用户说这个产品是否可以退款, 那大模型如果回答说可以。如果产品价格非常高,比如在1万以上,那么这个产品是不是要退款?损失谁来回答。 所以企业必须要机器人严格按照企业的知识库的要求来,不能乱回答
2.企业的资料的保密性
目前的大模型,当你把资料传给大模型的时候,实际上,你把资料也给机器人当做语料去训练机器人了,你的文档就是公开的文档了,这对许多企业来说,基本上不会把敏感资料传给大模型了
还记得之前网上报道过,三星把一个芯片资料传给大模型,导致敏感技术资料泄密的问题。
ChatGPT「奶奶漏洞」又火了,扮演过世祖母讲睡前故事,骗出Win11序列号
3 大模型从问答,到企业部署到自己的客服渠道,有大多的工作量
大模型提高了接口,提供了文字问答能力,但是,企业的客户咨询,是从
1 APP里
2 公司官网
3 公众号,小程序,视频号
4 抖音
5 小红书
6 微博
这么渠道,各个场景都要去覆盖,一般的企业根本就没这个开发实力。
基于这个想法,我就想做个基于大模型的问答机器人,完全打通小程序客服,微信公众号客服,视频号小店客服,H5APP客服,公司官网,部署简单。这样企业就很方便的部署起来。
我的想法是
方法一:渠道统一管理, 把常用的渠道,全部默认支持到

方法二 :将企业知识库管理简单化
直接将doc,网址,pdf ,excel 直接上传到,就可以支持基于知识库的问答了。
上传的知识库,进行分段embedding操作
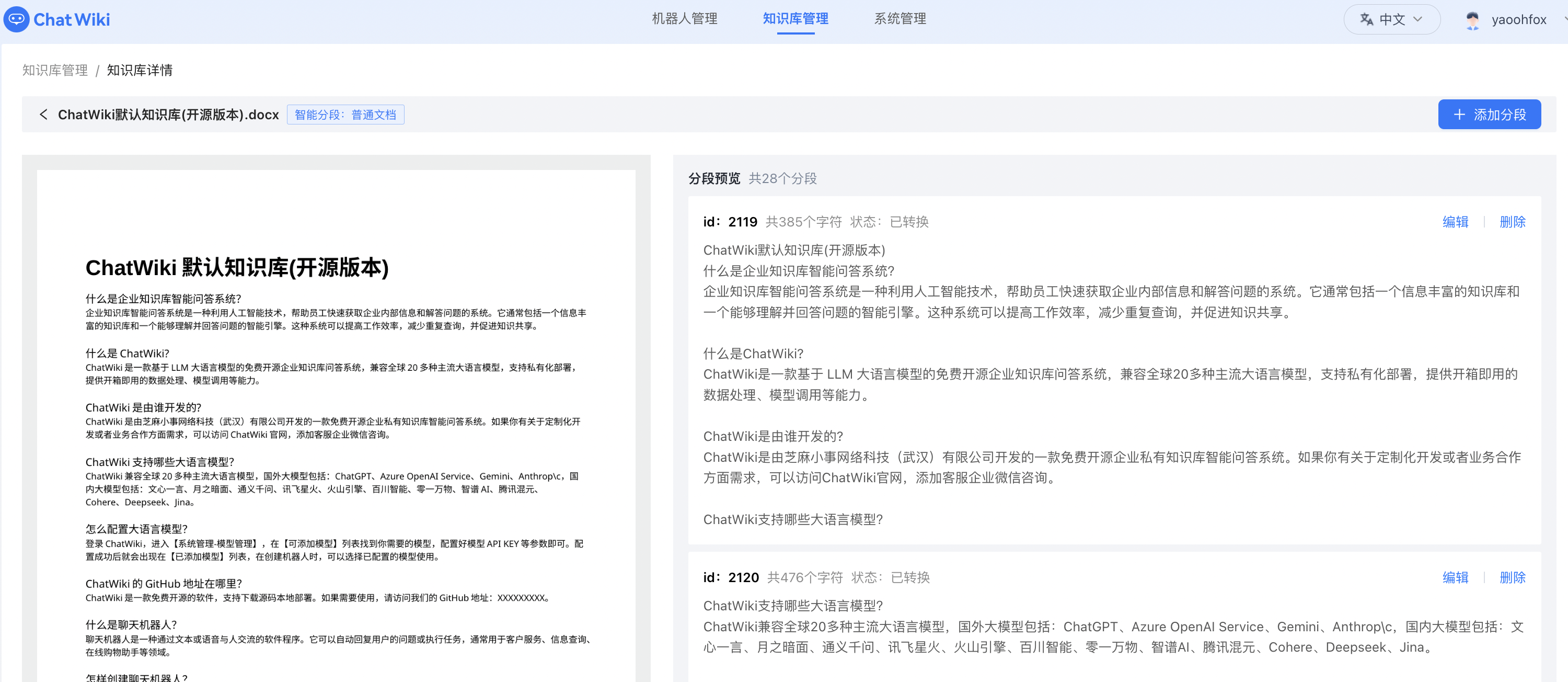
最后创建机器人,关联这个知识库,就可以对外提供服务了

以下是我们的架构图
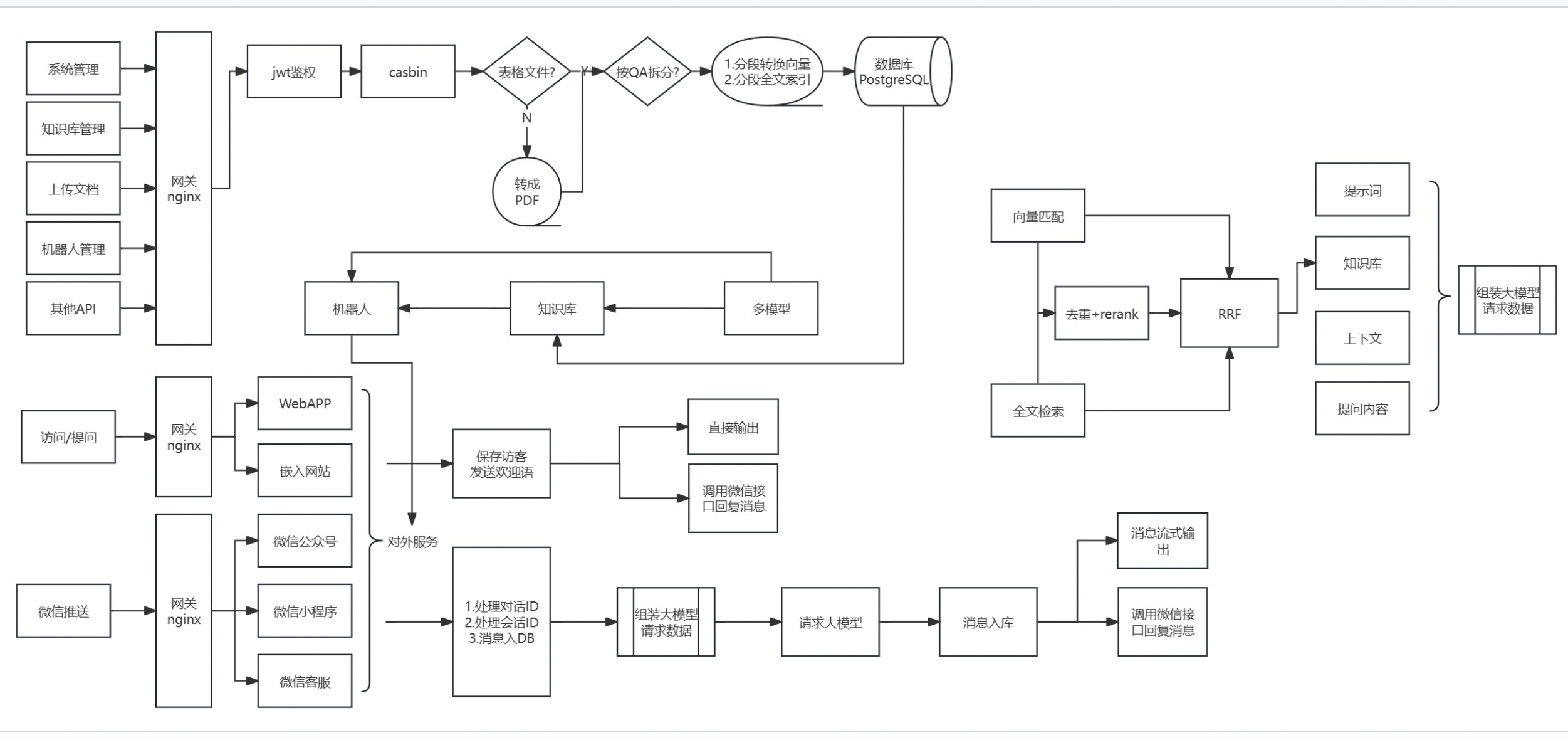
下面是具体的一些介绍
ChatWiki
ChatWiki是一款开源的知识库 AI 问答系统。系统基于大语言模型(LLM )和检索增强生成(RAG)技术构建,提供开箱即用的数据处理、模型调用等能力,可以帮助企业快速搭建自己的知识库 AI 问答系统。
能力
1、专属 AI 问答系统
通过导入企业已有知识构建知识库,让 AI 机器人使用关联的知识库回答问题,快速构建企业专属 AI 问答系统。
2、一键接入模型
ChatWiki已支持全球20多种主流模型,只需要简单配置模型API key等信息即可成功接入模型。
3、数据自动预处理
提供自动分段、QA分段、手动输入和 CSV 等多种方式导入数据,ChatWiki自动对导入的文本数据进行预处理、向量化或 QA 分割。
4、简单易用的使用方式
ChatWiki采用直观的可视化界面设计,通过简洁易懂的操作步骤,可以轻松完成 AI 问答机器人和知识库的创建。
5、适配不同业务场景
ChatWiki为 AI 问答机器人提供了不同的使用渠道,支持H5链接、嵌入网站、绑定到微信公众号或小程序、桌面客户端等,可以满足企业不同业务场景使用需求。
开始使用
准备工作
再安装ChatWiki之前,您需要准备一台具有联网功能的linux服务器,并确保服务器满足最低系统要求
- Cpu:最低需要2 Core
- RAM:最低需要4GB
开始安装
ChatWiki社区版基于Docker部署,请先确保服务器已经安装好Docker。如果没有安装,可以通过以下命令安装:
sudo curl -sSL https://get.docker.com/ | CHANNEL=stable sh安装好Docker后,逐步执行一下步骤安装ChatWiki社区版
(1).克隆或下载chatwiki项目代码
git clone https://github.com/zhimaAi/chatwiki.git(2).使用Docker Compose构建并启动项目
cd chatwiki/docker
docker compose up -d部署手册
在安装和部署中有任何问题或者建议,可以联系我们获取帮助,也可以参考下面的文档。
界面









技术架构

技术栈
-
前端:vue.js
-
后端:golang +python
-
数据库:PostgreSQL16+pgvector+zhparser
-
缓存:redis5.0
-
web服务:nginx
-
异步队列:nsq
-
进程管理:supervisor
-
模型:支持OpenAI、Google Gemini、Claude3、通义千文、文心一言、讯飞星火、百川、腾讯混元等模型。
感兴趣的朋友,可以去我们github https://github.com/zhimaAi/chatwiki 地址里点个star, 多谢多谢!