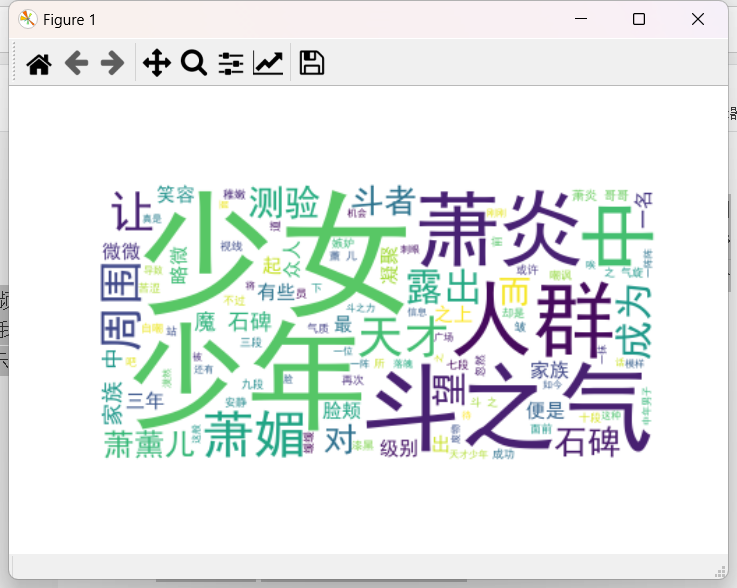
使用Python和jieba库生成中文词云
在文本分析和数据可视化的领域中,词云是一种展示文本数据中关键词频率的直观方式。Python作为一种强大的编程语言,提供了多种库来帮助我们生成词云,如wordcloud和jieba。在本文中,我们将通过一个简单的示例,展示如何使用Python生成中文词云。
环境准备
首先,确保您的Python环境中安装了以下库:
jieba:用于中文分词。wordcloud:用于生成词云。matplotlib:用于显示词云图像。
如果尚未安装,可以通过以下命令进行安装:
bash
pip install jieba
pip install wordcloud
pip install matplotlib示例代码
以下是生成中文词云的完整代码示例:
python
import jieba
import wordcloud
import matplotlib.pyplot as plt
# 读取文本文件
with open('斗破苍穹第一章.txt', 'r', encoding='utf-8') as file:
text = file.read()
# 使用jieba进行分词
words = jieba.cut(text)
result = ' '.join(words)
# 定义停用词集合
stopwords = set([
# 停用词列表...
])
# 创建词云对象
wc = wordcloud.WordCloud(
font_path='C:\\Windows\\Fonts\\simhei.ttf', # 指定字体路径
background_color='white',
max_words=100, # 最大显示词数
max_font_size=100, # 字体最大大小
random_state=42, # 使结果可复现
stopwords=stopwords # 停用词集合
)
# 生成词云
wc.generate(result)
# 使用matplotlib显示词云
plt.figure(figsize=(8, 6))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off') # 不显示坐标轴
plt.show()
python
stopwords={
'了', '的', '和', '是', '我', '你', '这', '就', '有', '在', '也', '一', '不', '人', '都', '一个',
'我们', '他', '她', '得', '地', '很', '到', '说', '要', '去', '上', '说', '知道', '能', '看',
'自己', '出来', '过', '着', '听', '觉得', '但是', '而且', '因为', '所以', '虽然', '如果', '就是',
'只有', '可以', '什么', '哪', '哪个', '那些', '什么', '怎么', '怎样', '这么', '那么', '这样', '那样',
'一点', '一些', '一点', '一些', '一下', '一下', '一会儿', '一点儿', '现在', '然后', '再', '曾经',
'曾经', '曾经', '曾经', '或者', '或者', '以及', '或者', '跟', '跟', '同', '和', '与', '跟', '同',
'跟', '与', '跟', '和', '与', '而且', '并且', '或者', '还是', '或者', '或者', '又', '也', '还',
'再', '另外', '那',
'然后',
'接着',
'之后',
'起来',
# ... 其他词 ...
}代码解析
- 读取文本:首先,我们读取了《斗破苍穹》第一章的文本内容。
- 中文分词 :使用
jieba库对文本进行分词处理。 - 定义停用词:创建了一个包含常见中文语气助词和虚词的停用词集合,以提高词云的质量。
- 生成词云 :通过
wordcloud.WordCloud类创建词云对象,并使用分词后的结果生成词云。 - 显示词云 :使用
matplotlib库显示生成的词云图像。
小结
通过上述步骤,我们成功地生成了一个中文词云。这种方法可以应用于任何中文文本分析项目,帮助我们快速识别文本中的关键信息。词云不仅是一种美观的数据可视化手段,也是探索和理解文本数据的有效工具。