一、Web基础
1.HTML概述
HTML(Hypertext Markup Language)是一种标记语音,用于创建和组织Web页面的结构和内容,HTML是构建Web页面的基础,定义了页面的结构和内容,通过标记和元素来实现
2.HTML文件结构
<html>
<head>网页的头部信息</head>
<body>网页内容</body>
</html>
3.HTML基本标签
|---------------|---------------------------------|
| 基本标签 | 含义 |
| <html> | HTML文档的根元素,包含文档的全部内容 |
| <head> | 文档的头部,通常用于引入样式表、脚本以及设置文档的元信息 |
| <title> | 文档的标题,显示在浏览器的标题栏或标签页上 |
| <body> | 文档的主体部分,包含页面上的可见内容 |
| <h1>到<h6> | 标题标签,用于表示不同级别的标题,<h1>是最高级别的标题 |
| <p> | 段落标签,用于表示一个段落 |
| <a> | 链接标签,用于创建一个超链接,并指定链接的目标URL |
| <img> | 图像标签,用于插入图像到页面中,并指定图像的源文件路径 |
| <ul>和<li> | 无序列表标签,用于创建一个无序列表和列表项 |
| <ol>和<li> | 有序列表标签,用于创建一个有序列表和列表项 |
| <div> | 通用的容器标签,用于分组和组织页面中的内容 |
| <span> | 内联容器标签,用于对文本的一部分进行特殊处理,如应用样式或事件 |
4.URI和URL
URI:统一资源标识,分为URL和URN
URL:统一资源定位符,用于描述某服务器某特定资源位置
URI和URL区别:
**定义范围:**URI是一个广义的概念,用于标识和命名互联网上的资源,可以是URL、URN或其他形式,URL是URI的一种具体实现形式,用于资源的定位和访问
**功能重点:**URI强调资源的标识性,用于唯一标识和命名资源,URL则更注重资源的位置性,其中包含了定位和访问资源所需的详细信息
二、静态资源和动态资源
静态资源和动态资源是两种常见的网络资源类型
静态资源和动态资源的区别在于内容是否固定不变
1.静态资源
静态资源指的是在服务器上保存的文件,其内容在请求和传输过程中不发生变化
静态资源可以是图片、CSS样式表、JavaScript文件、HTML文件等
静态资源的请求一般是通过URL直接访问,当客户端发送请求时,服务器直接将这些文件返回给客户端,不进行任何处理
2.动态资源
动态资源则是在服务器端通过执行脚本或程序生成的内容,需要占用服务器的资源
服务器会根据请求中的参数和数据,执行相应的脚本或程序来生成动态内容,然后将生成的内容返回给客户端
动态资源可以是动态网页、API接口等
三、HTTP协议
1.HTTP协议
HTTP协议采用了请求/响应模型
客户端向服务器发送一个请求,请求包含请求的方法、URL、协议版本、以及包含请求修饰符、客户信息和内容的类似于MIME的消息结构
服务器以一个状态行作为响应,响应的内容包括消息协议的版本,成功或者错误编码加上服务器信息、实体元信息以及可能的实体内容
2.HTTP协议版本
|----------|-----------------------------------------------------------------------------|
| http 0.9 | 功能简陋,仅支持GET方法 |
| http 1.0 | 相较以前版本可以支持POST、HEAD方法,支持HTML文件以外的其他类型,但不支持持久连接 |
| http 1.1 | 支持持久连接,即在一个TCP连接里面完成多个http请求和响应,但是每个请求和响应是按照顺序一一对应的 |
| http 2.0 | http 2.0 支持完全多路复用,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应( 也支持压缩,服务端主动推送) |
3.HTTP方法作用
HTTP定义了一组请求方法,用于指定客户端对资源的操作方式,这些请求命令成为HTTP方法
|---------|------------------------------|
| 方法 | 作用 |
| GET | 对服务器资源获取的简单请求 |
| PUT | 向服务器上传指定的资源,如果资源已存在,则替换为新的内容 |
| POST | 向服务器提交数据 |
| DELETE | 删除服务器上的某些资源 |
| HEAD | 请求页面的首部,获取资源的元信息 |
| CONNECT | 用于ssl隧道的基于代理的请求 |
| OPTIONS | 返回所有可用的方法,常用于跨域 |
| TRACE | 追踪 请求--响应的传输路径 |
1、GET请求会向数据库发索取数据的请求,从而来获取信息,该请求不会产生副作用。无论进行多少次操作,结果都是一样的
2、与GET不同的是,PUT请求是向服务器端发送数据的,从而改变信息,无论进行多少次PUT操作,其结果并没有不同
3、POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,几乎目前所有的提交操作都是用POST请求的
4、DELETE请求顾名思义,就是用来删除某一个资源的
4.HTTP请求访问的完整过程
建立连接>接收请求>处理请求>访问资源>构建响应报文>发送响应报文>记录日志
5.HTTP状态码
HTTP状态码是服务器在处理请求时返回给客户端的数字代码,用于表示请求的处理结果
HTTP协议状态码分类
|-----------|---------|------------------------|
| 状态码首位 | 范围 | 含义 |
| 1xx | 100-101 | 信息提示,表示请求已被接收,需要进一步处理 |
| 2xx | 200-206 | 成功,表示请求已成功处理 |
| 3xx | 300-305 | 重定向,表示需要进一步的操作以完成请求 |
| 4xx | 400-415 | 客户端错误,表示客户端发送的请求有错误 |
| 5xx | 500-505 | 服务器错误,表示服务器在处理请求时发生了错误 |
HTTP协议常用的状态码
|---------|---------------------------------------------------------------|
| 状态码 | 含义 |
| 200 | 一切正常 |
| 301 | 永久重定向 |
| 302 | 临时重定向 |
| 307 | 浏览器内部重定向 |
| 401 | 用户名或密码错误 |
| 403 | 禁止访问(客户端IP地址被拒绝) |
| 404 | 请求的资源在服务器上不存在 |
| 414 | 请求URL头部过长 |
| 500 | 服务器内部错误。比如脚本错误,编程语言语法错误 |
| 502 | 无效网关 |
| 503 | 服务器暂时无法处理请求,通常用于服务器维护或过载 |
| 504 | 网关请求超时。程序执行时间过长导致响应超时,例如程序需要执行20秒,而nginx最大响应等待时间为10秒,这样就会出现超时 |
产生502(无效网关)的原因:
1.数据包没有送到网卡,网络问题
2.数据包送进去了(交换机能抓到包),但是网卡没收到,网卡问题或防火墙问题
3.网卡接收到了,处理不了,服务问题。(比如服务器当前连接太多,响应太慢;页面素材太多,带宽不够。)
6.HTTP的请求报文和响应报文
1.请求报文
curl -v 192.168.7.20 |head ##从此服务器获取内容
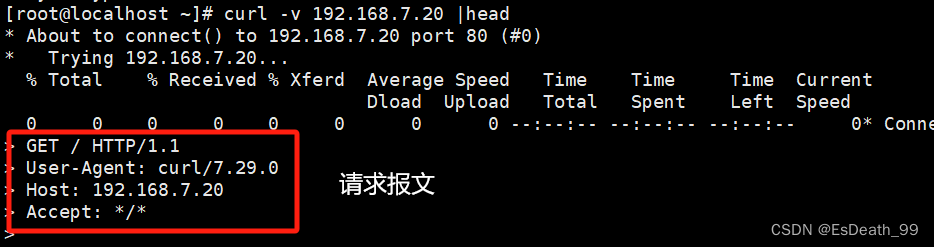
#状态行
>GET / HTTP/1.1
#HTTP GET请求,即获取指定路径的内容,请求的路径为根路径("/"),表示请求服务器的默认页面
#头部字段
>User-Agent:curl/7.29.0
#指定客户端使用的User-Agent,该请求由curl/7.29.0发送
>Host:192.168.7.20
#指定了要访问的服务器的主机地址
>Accept:*/*
#指定了客户端可以接受的响应内容的类型,表示客户端可以接受任何类型的内容
2.响应报文
curl -v 192.168.7.20 |head ##从此服务器获取内容
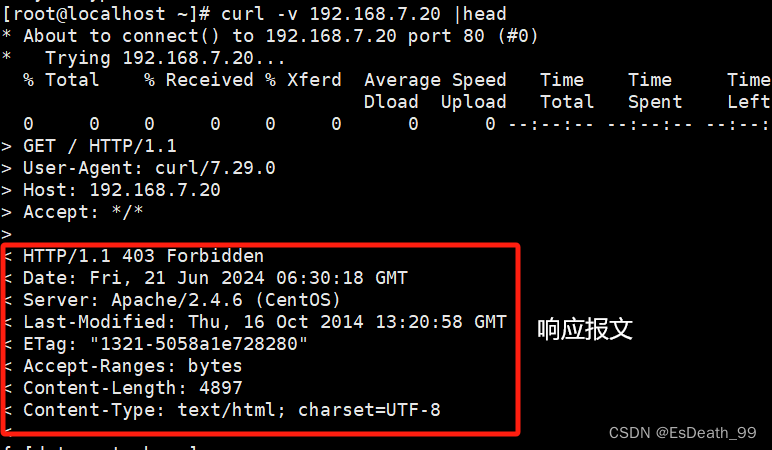
#响应状态行
< HTTP/1.1 403 Forbidden
#表示请求被拒绝,状态码403表示禁止访问
#头部字段
<Date:Fri,21 Jun 2024 06:30:18 GMT
#表示响应的日期和时间
<Server:Apache/2.4.6 (CentOS)
#表示服务器正在使用的软件名称和版本
<Last-Modified:Thu,16 Oct 2014 13:20:58 GMT
#表示所请求资源的最后修改日期和时间
<ETag:"1321-5058a1e728280"
#表示所请求资源的实体标签
<Accept-Ranges:bytes
#服务器是否支持断点续传
<Content-Length:4897
#响应实体主体的长度
<Content-Type:text/html;charset=UTF-8
#实体主体的类型和字符编码,表示响应内容是以UTF-8编码的HTML文本
7.HTTP连接优化
1.并行连接:并行连接通过同时建立多个连接 ,使得客户端可以并发地发送多个请求,以提高并发性和响应速度
2.持久连接 :持久连接允许客户端和服务器之间在单个连接上发送多个HTTP请求和响应 ,而不是每个请求都要重新建立连接
3.管道化连接:管道化连接是一种在持久连接上发送多个请求而无需等待服务器响应的机制
四、httpd
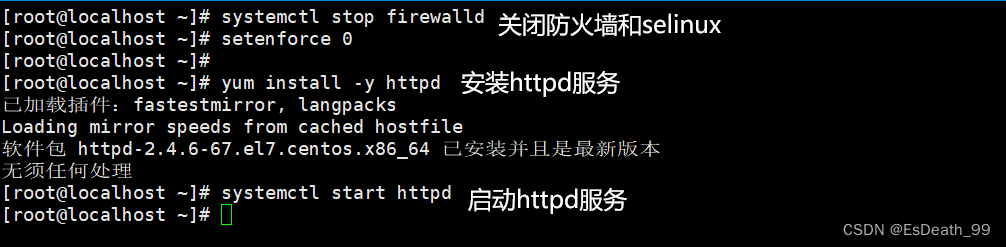
1.安装
2.httpd相关文件配置
#主配置文件
/etc/httpd/conf/httpd.conf
#子配置文件
/etc/httpd/conf.d/*.conf
#模块加载的配置文件
/etc/httpd/conf.d/conf.modules.d/
#检查配置语法
httpd -t或apache2 -t
#站点网页文档根目录
/var/www/html
3.服务单元文件和主服务器程序文件
服务单元文件
/usr/lib/systemd/system/httpd.service
配置文件:/etc/sysconfig/httpd
主服务器程序文件
/usr/sbin/httpd
4.模块文件
/etc/httpd/modules
/usr/lib64/httpd/modules
5.httpd服务控制和启动(命令部分)
#开机自启动/开机自动关闭httpd服务
systemctl enable |disable httpd.service
开启httpd服务的三种方式(任选其一)systemctl start httpd.service
apachectl start
service httpd start
重启httpd服务的三种方式(任选其一)systemctl restart httpd.service
apachectl restart
service httpd restart
停止httpd服务的三种方式(任选其一)systemctl stop httpd.service
apachectl stop
service httpd stop
查看httpd服务的运行状态systemctl status httpd
配置文件语法检查的两种方式(任选其一)apachectl configtest
service httpd configtest
五、Apache的三种工作模式
1.Worker模式
工作线程(Worker)模式适用于资源利用率高的场景
1.Apache在启动时会创建一组预定义数量的线程池
2.每个线程都可以处理多个请求,线程之间共享服务器的内存和资源
3.当一个请求到达服务器时,一个空闲的线程将被选择来处理该请求
4.线程可能会处理多个请求,通过线程池重用来更高效地处理请求
5.这种模式下需要注意线程安全的问题,以确保多个线程间的数据访问不会导致冲突
2.Event模式
事件驱动(Event MPM)模式适用于高并发场景
1.在事件驱动模式下,Apache使用I/O多路复用(如epoll或kqueue)来监听多个连接
2.当一个连接有数据到达时,Apache将发出事件通知,表示该连接有可读数据
3.Apache将事件分发给一个空闲的工作线程来处理请求
4.工作线程处理请求的过程通常是非阻塞的,通过事件驱动方式读取数据和发送响应
5.这种模式下可以处理大量的并发请求,因为它不需要为每个请求创建一个新的进程或线程
3.Pre-Fork模式
预产生(Pre-Fork)模式适用于稳定性要求高的场景
1.Apache在启动时会创建一组预定义数量的子进程(称为工作进程)
2.每个工作进程都是独立的,有自己的内存空间和资源
3.当一个请求到达服务器时,主进程选择一个空闲的工作进程来接受该请求
4.选中的工作进程处理该请求,生成响应并将其发送回客户端
5.这种模式下每个工作进程只能处理一个请求,处理完请求后会继续等待下一个请求
六、Cookie和Session
Cookie和Session都用于解决HTTP协议无状态问题
1.Cookie
Cookie是服务器在用户的浏览器中存储的小型文本文件。当用户访问一个网站时,服务器可以通过HTTP响应的Set-Cookie标头将一个或多个Cookie发送给浏览器。浏览器会将这些Cookie存储在用户的计算机上,并在以后的请求中将它们发送回服务器。每个Cookie都包括一个名称、一个值和一些可选的属性,如过期时间、域名、路径等。服务器可以使用Cookie来存储用户的偏好设置、会话标识符、购物车数据等。浏览器会在每次请求中自动发送与特定域名相关联的Cookie,使得服务器能够识别用户
2.Session
Session是在服务器端存储用户状态的一种机制。当用户首次访问一个网站时,服务器会为该用户创建一个唯一的会话标识符(Session ID)。这个标识符通常被存储在Cookie中,但也可以通过其他方式(如URL参数)进行传递。服务器使用Session来存储用户信息和其他相关数据。在每个请求中,浏览器会将Session ID作为Cookie发送给服务器,使得服务器能够识别并恢复与该用户相关联的会话数据。Session数据通常存储在服务器的内存或持久化存储中
七、httpd配置
httpd虚拟主机的作用是通过一个物理服务器来托管多个域名或网站,实现资源共享、个性化配置和多域名指向不同网站的功能,提高服务器资源利用率和降低成本
1.虚拟主机(基于ip地址)
原理:每个虚拟主机分配一个唯一的IP地址,并通过服务器软件(httpd)来指定每个虚拟主机使用的IP地址,客户机访问服务器时,服务器会根据客户机的IP地址,在配置文件中寻找对应关系,根据对应关系跳转
服务端配置:
进入主站点配置文件
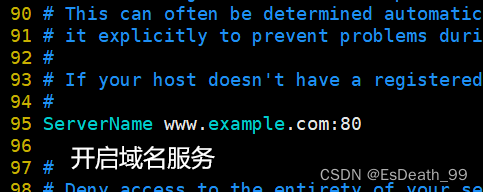
vim /etc/httpd/conf/httpd.conf
#开启域名服务
ServerName www.example.com:80
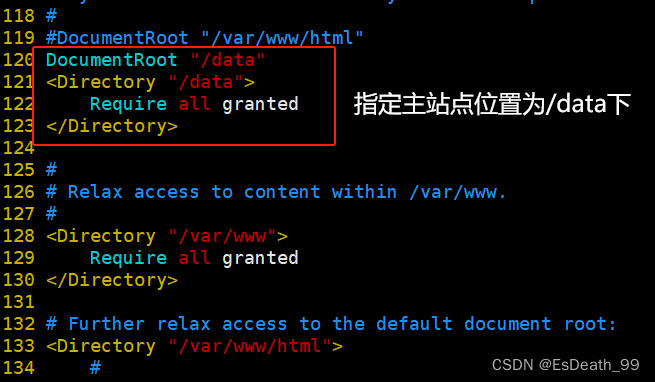
#指定主站点到/data
DocumentRoot "/data"
<Directory "/data">
Require all granted
</Directory>
#复制虚拟主机模板文件到/etc/httpd/conf.d并改名为xuni.conf
cp /usr/share/doc/httpd-2.4.6/httpd-vhosts.conf /etc/httpd/conf.d/xuni.conf

#移动到/etc/httpd/conf.d目录下编辑xuni.conf配置
cd /etc/httpd/conf.d
vim xuni.conf
<VirtualHost 192.168.7.10:80>
DocumentRoot "/data/eva"
ServerName www.eva.com
ErrorLog "/var/log/httpd/dummy-host.example.com-error_log"
CustomLog "/var/log/httpd/dummy-host.example.com-access_log" common
</VirtualHost>
<VirtualHost 192.168.7.99:80>
DocumentRoot "/data/esdeath"
ServerName www.esdeath.com
ErrorLog "/var/log/httpd/dummy-host2.example.com-error_log"
CustomLog "/var/log/httpd/dummy-host2.example.com-access_log" common
</VirtualHost>
<Directory "/data">
Require all granted
</Directory>


#建立data文件下的esdeath和eva并输入内容,重启httpd配置文件

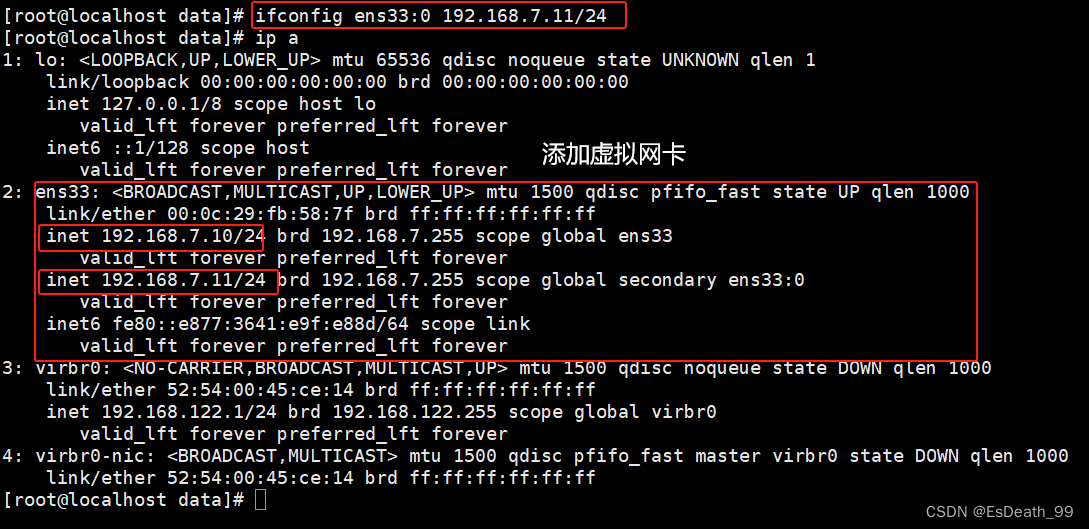
添加虚拟主机的网卡:有几台虚拟主机加几个
ipconfig ens33:0 192.168.7.11/24
此时拿客户端访问服务端ip是否出现内容:
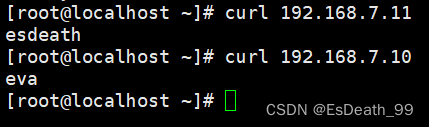
2.虚拟主机(基于域名)
cd /etc/httpd/conf.d
vim xuni.conf
IP、端口相同,域名不同
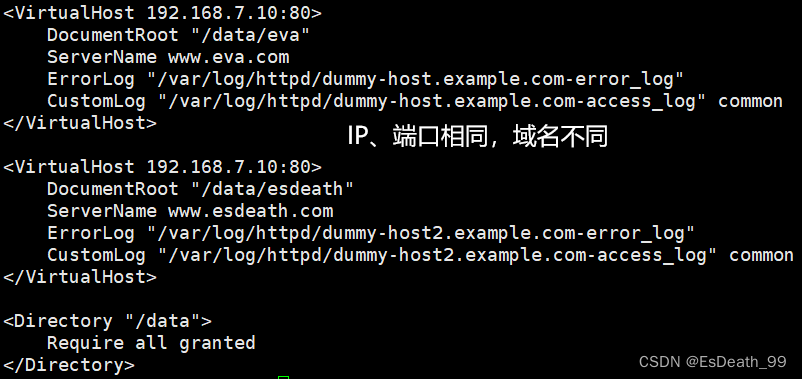
在客户机编辑本地hosts文件,添加地址映射:

用客户机访问服务端,查看是否成功:
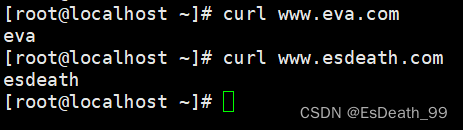
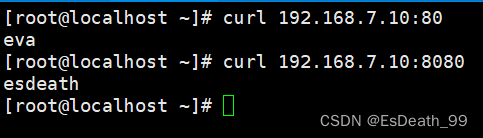
3.虚拟主机(基于端口)
cd /etc/httpd/conf.d
vim xuni.conf
IP、域名相同,端口号不同
添加监听8080端口
listen 8080
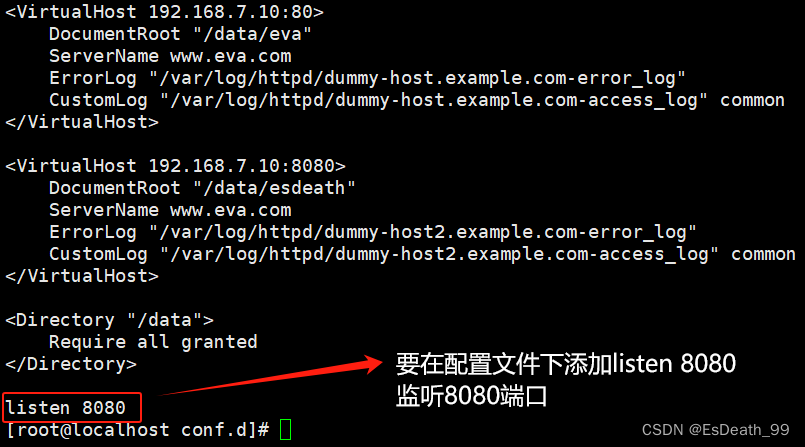
拿客户机curl服务端是否成功