机器学习
- 3.分类算法
-
- [3.1 sklearn转换器和估计器](#3.1 sklearn转换器和估计器)
-
- [3.1.1 转换器](#3.1.1 转换器)
- [3.1.2 估计器(在sklearn实现机器学习算法)](#3.1.2 估计器(在sklearn实现机器学习算法))
- [3.2 K-近邻算法](#3.2 K-近邻算法)
-
- [3.2.1 什么是K-近邻算法](#3.2.1 什么是K-近邻算法)
- [3.2.2 K-近邻算法API](#3.2.2 K-近邻算法API)
- [3.2.3 案例:鸢尾花种类预测](#3.2.3 案例:鸢尾花种类预测)
- [3.2.4 K-近邻总结](#3.2.4 K-近邻总结)
- [3.3 模型选择与调优](#3.3 模型选择与调优)
-
- [3.3.1 交叉验证(cross vaildation)](#3.3.1 交叉验证(cross vaildation))
- [3.3.2 超参数搜索-网络搜索(Grid Search)](#3.3.2 超参数搜索-网络搜索(Grid Search))
- [3.3.3 鸢尾花案例增加K值调优](#3.3.3 鸢尾花案例增加K值调优)
- [3.4 朴素贝叶斯算法](#3.4 朴素贝叶斯算法)
-
- [3.4.1 复习概率](#3.4.1 复习概率)
- [3.4.2 应用于文章分类](#3.4.2 应用于文章分类)
- [3.4.3 API](#3.4.3 API)
3.分类算法
3.1 sklearn转换器和估计器
3.1.1 转换器
特征工程的接口被称为转换器,其中转换器调用有这么几种形式:
- fit_transform
- fit
- transform
3.1.2 估计器(在sklearn实现机器学习算法)
在sklearn里面,估计器(estimator)是一类实现了算法的API。
- 用于分类的估计器:
- sklearn.neighbors KNN算法
- sklearn.naive_bayes 贝叶斯
- sklearn.linear_model.LogisticRegression 逻辑回归
- sklearn.tree 决策树与随机森林
- 用于回归的估计器:
- sklearn.linear_model.LinearRegression 线性回归
- sklearn.linear_model.Ridge 岭回归
- 用于无监督学习的估计器
- sklearn.cluster.KMeans 聚类
如何使用?
- 实例化一个estimator.
- estimator.fit(x_train , y_train) 生成模型
- 模型评估:
- 直接比对真实值和预测值
- y_predict = estimator.predict(x_test)
- y_test == y_predict
- 计算准确率
- estimator.score(x_test,y_test)
- 直接比对真实值和预测值
3.2 K-近邻算法
3.2.1 什么是K-近邻算法
-
核心思想:根据你的"邻居"来推断出你的类别。
-
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于一个类别,则该样本也属于这个类别。
其中k值
- 不能太小,容易受到异常值的影响。
- 不能太大,会受到样本不均衡的影响。
-
如何计算距离:
- 欧式距离
- 曼哈顿距离
- 闵可夫斯基距离
3.2.2 K-近邻算法API
python
sklearn.neighbors.KNeighborsClassifier(n_neighbors = 5,algorithm = 'auto')
# n_neighbors : int, default=5 Number of neighbors to use by default for :meth:`kneighbors` queries.
# alogrithm : {'auto','ball_tree','kd_tree','brute'} 可选用计算最近邻居的算法
# algorithm : {'auto', 'ball_tree', 'kd_tree', 'brute'}, default='auto'
# Algorithm used to compute the nearest neighbors:
# - 'ball_tree' will use :class:`BallTree`
# - 'kd_tree' will use :class:`KDTree`
# - 'brute' will use a brute-force search.
# - 'auto' will attempt to decide the most appropriate algorithm
# based on the values passed to :meth:`fit` method.
# Note: fitting on sparse input will override the setting of
# this parameter, using brute force.3.2.3 案例:鸢尾花种类预测
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
def neighbor_demo():
"""
KNN算法进行鸢尾花种类预测
:return:
"""
# 1. 导入数据
data = load_iris()
# 2. 划分数据集
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.25, random_state=10)
# random_state可以保证每次运行结果相同
# 3. 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test) # 测试集要用训练集的标准差和均值进行标准化,不然两者就不能投射到一块,后续无法进行模型评估
# 4. 模型训练
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5. 模型评估
# 方法1: 直接对比真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接对比真实值和预测值:\n", y_test == y_predict)
# 方法2: 计算准确率
score = estimator.score(x_test, y_test)
print("准确率:\n", score)
return None
if __name__ == '__main__':
neighbor_demo()3.2.4 K-近邻总结
- 优点:简单、易于理解、易于实现、无需训练(KNN 是一种懒惰学习(lazy learning)算法,这意味着它在训练阶段并不构建模型,而是在测试阶段才进行计算。)
- 缺点:
- 懒惰算法,对测试样本分类时计算量大,内存开销大
- 必须指定k值,k值选择不当则分类精度不能保证
- 使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
3.3 模型选择与调优
3.3.1 交叉验证(cross vaildation)
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分为4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称为4折交叉验证。
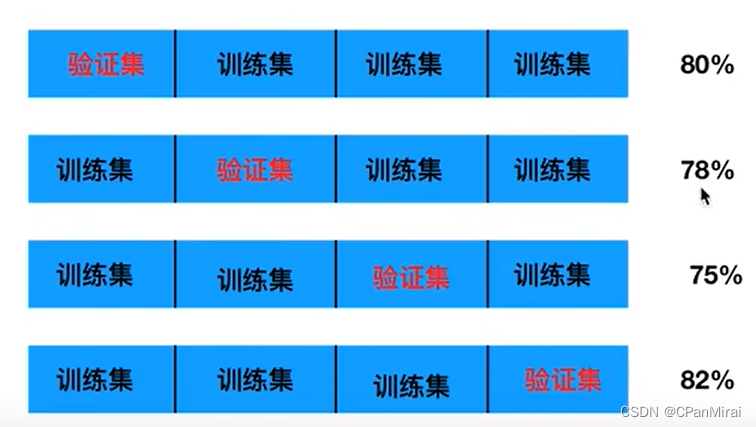
交叉验证目的:为了让被评估的模型更加准确可信。
3.3.2 超参数搜索-网络搜索(Grid Search)
-
通常情况下,有很多参数是需要手动指定的,这种叫超参数。但是手动过程繁琐,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
-
模型的选择与调优API
- sklearn.model_selection.GridSearchCV(estimator,param_grid = None,cv = None)
- 对估计器的指定参数值进行详尽搜索
- estimator : 估计器对象
- param_grid : 估计器参数(dict) {'n_neighbors':1,3,5}
- cv : 指定几折交叉验证
- score() : 准确率
- 结果分析:
- 最佳参数 :best_params_
- 最佳结果 : best_score_
- 最佳估计器 :best_estimator_
- 交叉验证结果 : cv_results_
- sklearn.model_selection.GridSearchCV(estimator,param_grid = None,cv = None)
3.3.3 鸢尾花案例增加K值调优
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
def neighbor_demo():
"""
KNN算法进行鸢尾花种类预测
:return:
"""
# 1. 导入数据
data = load_iris()
# 2. 划分数据集
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=10)
# random_state可以保证每次运行结果相同
# 3. 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test) # 测试集要用训练集的标准差和均值进行标准化,不然两者就不能投射到一块,后续无法进行模型评估
# 4. 模型训练
estimator = KNeighborsClassifier()
# 5. 参数调优
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11, 13, 15]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=5) # 返回拟合估计器实例
estimator.fit(x_train, y_train)
# 5. 模型评估
# 方法1: 直接对比真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接对比真实值和预测值:\n", y_test == y_predict)
# 方法2: 计算准确率
score = estimator.score(x_test, y_test)
print("准确率:\n", score)
# 最佳参数
print("最佳参数:\n", estimator.best_params_)
print("最佳结果:\n", estimator.best_score_)
print("最佳模型:\n", estimator.best_estimator_)
print("交叉验证结果:\n", estimator.cv_results_)
return None
if __name__ == '__main__':
neighbor_demo()3.4 朴素贝叶斯算法
朴素贝叶斯算法 = 朴素(假设特征与特征之间是相互独立的) + 贝叶斯(概率里面的贝叶斯公式)
常应用于文本分类
3.4.1 复习概率
- 联合概率:包含多个条件,且所有条件同时成立的概率。 记作:P(A,B)
- 条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率。 记作:P(A | B)
- 相互独立:如果P(A,B) = P(A) * p(B),则称事件A与事件B相互独立。
- 贝叶斯公式:
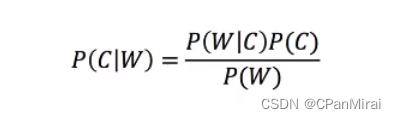
3.4.2 应用于文章分类

如果计算出来某个概率为0的话,需要引入拉普拉斯平滑系数,从而去防止计算出来的分类概率为0。

3.4.3 API
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- aplha:拉普拉斯平滑系数,默认为 1.0 。