最近学习注意力机制的时候,发现相同的概念很多,有必要给这些概念做一下区分,不然后续的学习可能会混成一团。本文先区分一下自注意力机制 和传统注意力机制。我会先直接给出它们之间有何区别的结论,然后通过一个例子来说明。
一、注意力机制和自注意力机制的区别
(1)关注的对象不同
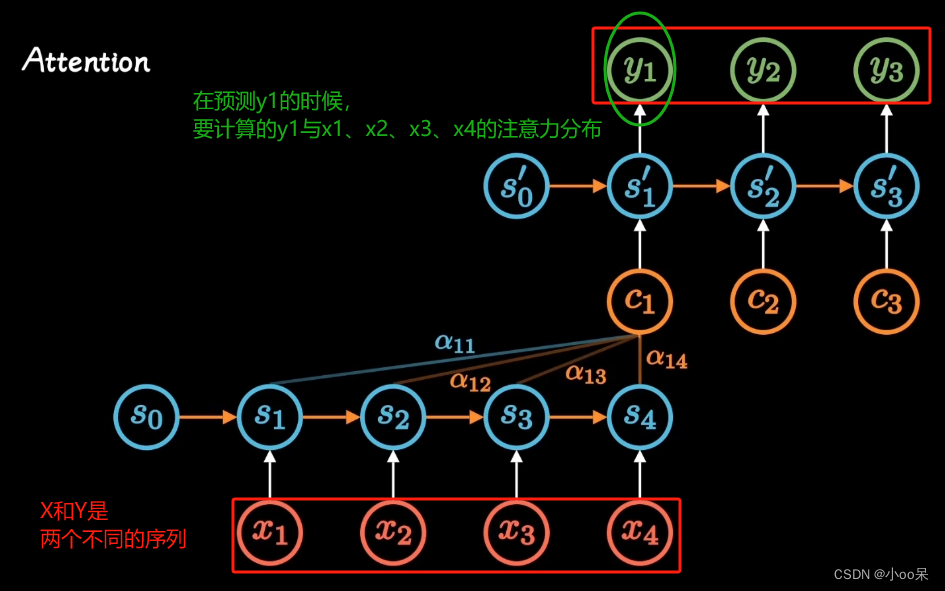
- 注意力机制通常设计两个不同的序列
- 自注意力机制则是在单一序列内部操作
(2)应用场景不同
- 注意力机制常用在跨序列的信息传输任务中,当我们说"传统注意力机制"的时候,其实是指全局注意力机制(Global Attention),比如机器翻译任务。
- 自注意力机制则多用在需要理解序列内部结构的任务,比如自然语言处理中的句子表示学习任务,Transformer架构通过自注意力机制直接建模句子中所有单词之间的相互依赖关系,生成高质量的句子表示。
(3)计算方式不同
- 注意力机制涉及跨序列的匹配和权重分配,通常在编码器和解码器之间构建一个注意力分布,强调输入序列中对生成特定输出最相关的部分。
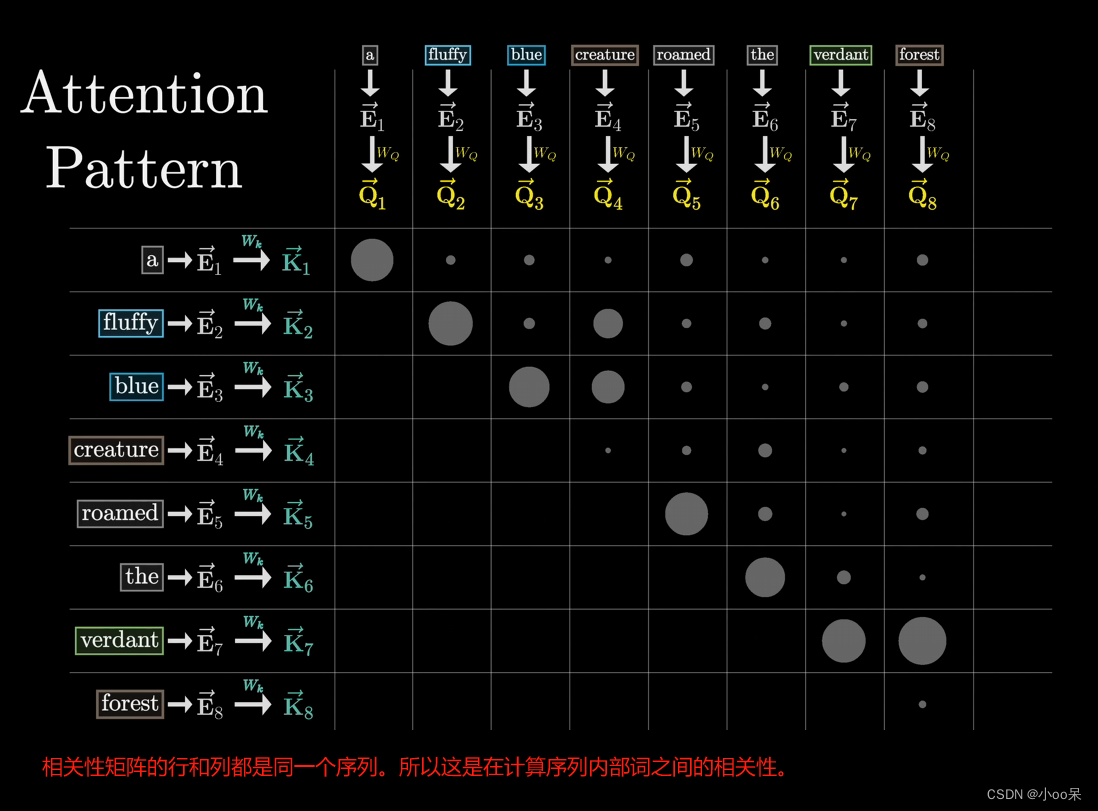
- 自注意力机制是计算序列内所有元素两两之间的相似性,然后基于这些相关性重新加权序列中的元素,以增强对序列全局上下文的理解。
二、举例说明两者的区别
(1)传统注意力机制的例子
假设我们正在处理英译法机器翻译任务,源句为"The movie was boring.",在典型的编码器-解码器架构中,源句经过编码器处理,转化为一系列向量表示,每个向量对应英语句子中的一个单词。
在生成法语句子的第一个词时,解码器会使用注意力机制"看"英语句子的不同部分。比如,如果第一个法语词应该是"Le",这很可能对应英语的定冠词"The"。此时,解码器(作为查询)会查看英语序列中的各个单词(作为键),并基于它们与"Le"这个目标词的相关性来分配注意力权重。
最终,它可能会发现"the"这个英语单词与当前输出最相关,于是给予它更高的权重,而其它单词权重较低。这样,解码器就能更加关注与当前翻译任务最相关的输入部分。
(2)自注意力机制的例子
假设我们在分析一个句子的情感色彩:"The movie was boring but the acting was superb." 使用自注意力机制,我们不是在不同序列间寻找关联,而是在这个句子内部探索词语之间的相互关系。
在自注意力的计算过程中,对于句子中的每个词(比如"boring"),模型会计算这个词与句子中所有其他词(包括它自己)的相关性。这意味着"boring"这个词会基于它与"movie"、"was"、"but"等词的上下文关系来重新加权。在这个例子中,"boring"与"movie"关系紧密,因为它修饰"movie",所以模型可能会给"movie"较高的权重,而像"superb"这样的词由于情感色彩相反,可能获得较低的权重。通过这样的过程,每个词都被赋予了一个基于其在句子中角色和上下文的新表示,从而帮助模型更好地理解整个句子的含义。