这篇文章是对之前的文章 "使用 Llama 3 开源和 Elastic 构建 RAG" 的一个补充。我们可以在本地部署 Elasticsearch,并进行展示。我们将一步一步地来进行配置并展示。你还可以参考我之前的另外一篇文章 "Elasticsearch:使用在本地计算机上运行的 LLM 以及 Ollama 和 Langchain 构建 RAG 应用程序"。

安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
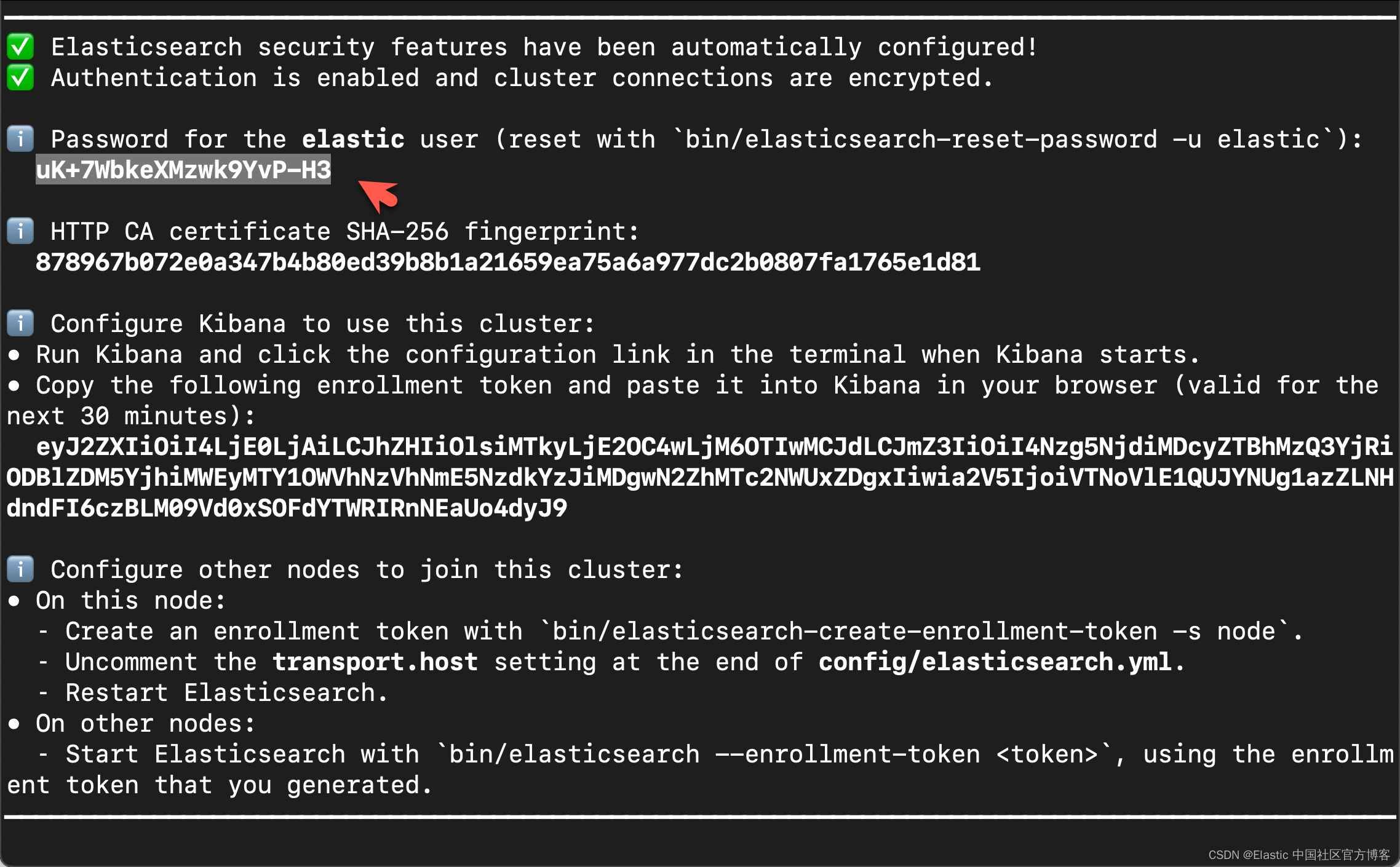
在上面,我们可以看到 elastic 超级用户的密码。我们记下它,并将在下面的代码中进行使用。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.14.1/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
我们首先克隆已经写好的代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-labs我们然后进入到该项目的根目录下:
$ pwd
/Users/liuxg/python/elasticsearch-labs/notebooks/integrations/llama3
$ ls
README.md rag-elastic-llama3-elser.ipynb rag-elastic-llama3.ipynb如上所示,rag-elastic-llama3.ipynb 就是我们今天想要工作的 notebook。
我们通过如下的命令来拷贝所需要的证书:
$ pwd
/Users/liuxg/python/elasticsearch-labs/notebooks/integrations/llama3
$ cp ~/elastic/elasticsearch-8.14.1/config/certs/http_ca.crt .
$ ls
README.md rag-elastic-llama3-elser.ipynb
http_ca.crt rag-elastic-llama3.ipynb安装所需要的 python 依赖包
pip3 install llama-index llama-index-cli llama-index-core llama-index-embeddings-elasticsearch llama-index-embeddings-ollama llama-index-legacy llama-index-llms-ollama llama-index-readers-elasticsearch llama-index-readers-file llama-index-vector-stores-elasticsearch llamaindex-py-client python-dotenv elasticsearch[async]我们可以通过如下的命令来查看 elasticsearch 安装包的版本:
$ pip3 list | grep elasticsearch
elasticsearch 8.14.0
llama-index-embeddings-elasticsearch 0.1.2
llama-index-readers-elasticsearch 0.1.4
llama-index-vector-stores-elasticsearch 0.2.0创建环境变量
为了能够使得下面的应用顺利执行,在项目当前的目录下运行如下的命令:
export ES_ENDPOINT="localhost"
export ES_USER="elastic"
export ES_PASSWORD="uK+7WbkeXMzwk9YvP-H3"配置 Ollama 和 Llama3
由于我们使用 Llama 3 8B 参数大小模型,我们将使用 Ollama 运行该模型。按照以下步骤安装 Ollama。
- 浏览到 URL https://ollama.com/download 以根据你的平台下载 Ollama 安装程序。
在我的电脑上,我使用 macOS 来进行安装。你也可以仿照文章 "Elasticsearch:使用在本地计算机上运行的 LLM 以及 Ollama 和 Langchain 构建 RAG 应用程序" 在 docker 里进行安装。
- 按照说明为你的操作系统安装和运行 Ollama。
- 安装后,按照以下命令下载 Llama3 模型。
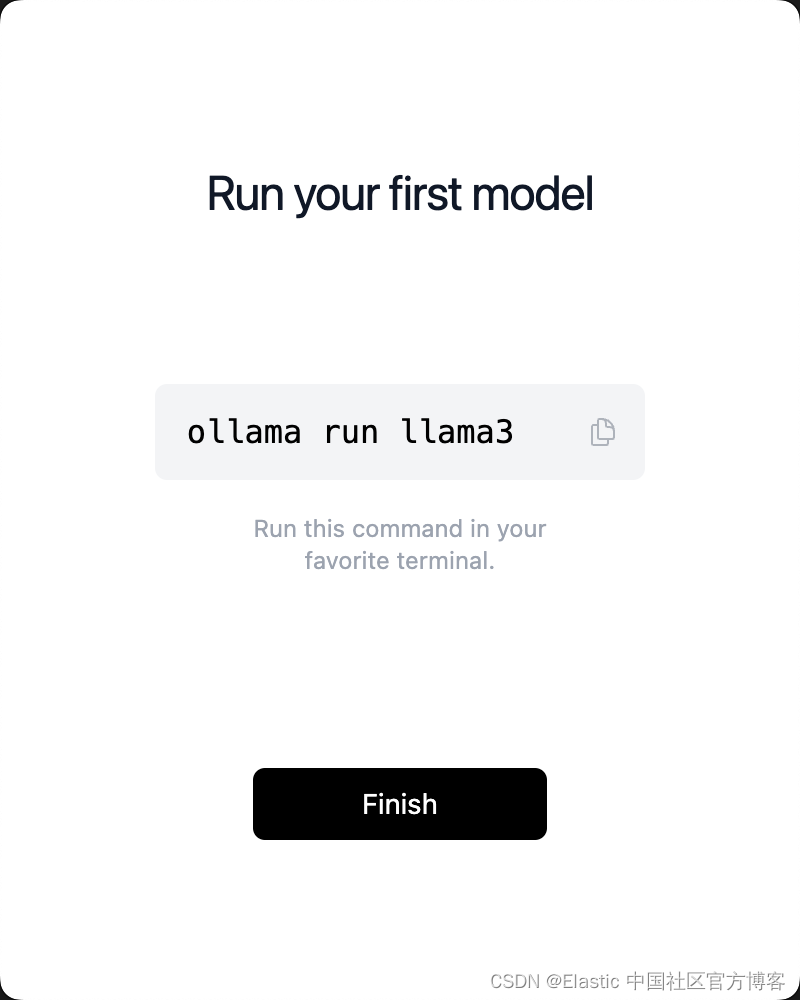
点击上面的 "Finish" 按钮,并按照上面的提示在 terminal 中运行:
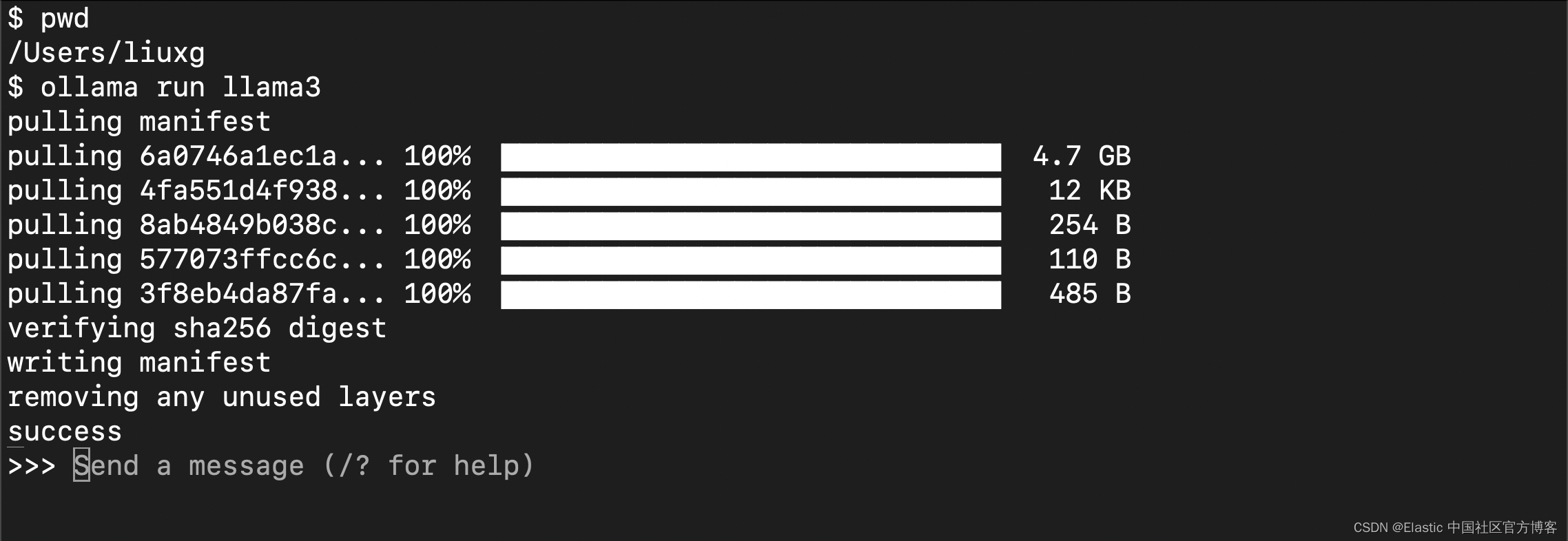
这可能需要一些时间,具体取决于你的网络带宽。运行完成后,你将看到如上的界面。
要测试 Llama3,请从新终端运行以下命令或在提示符下输入文本。
curl -X POST http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt":"Why is the sky blue?" }'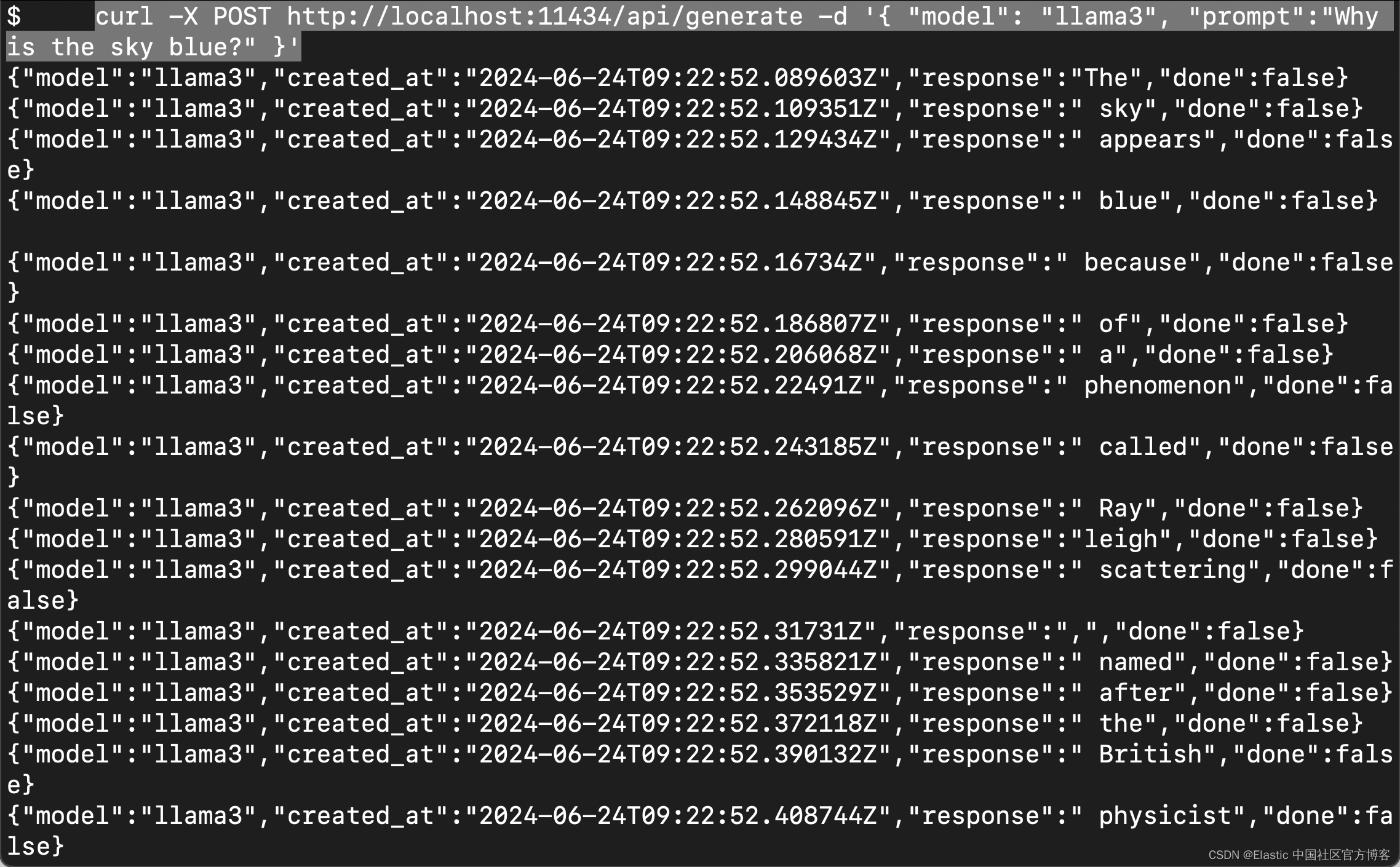
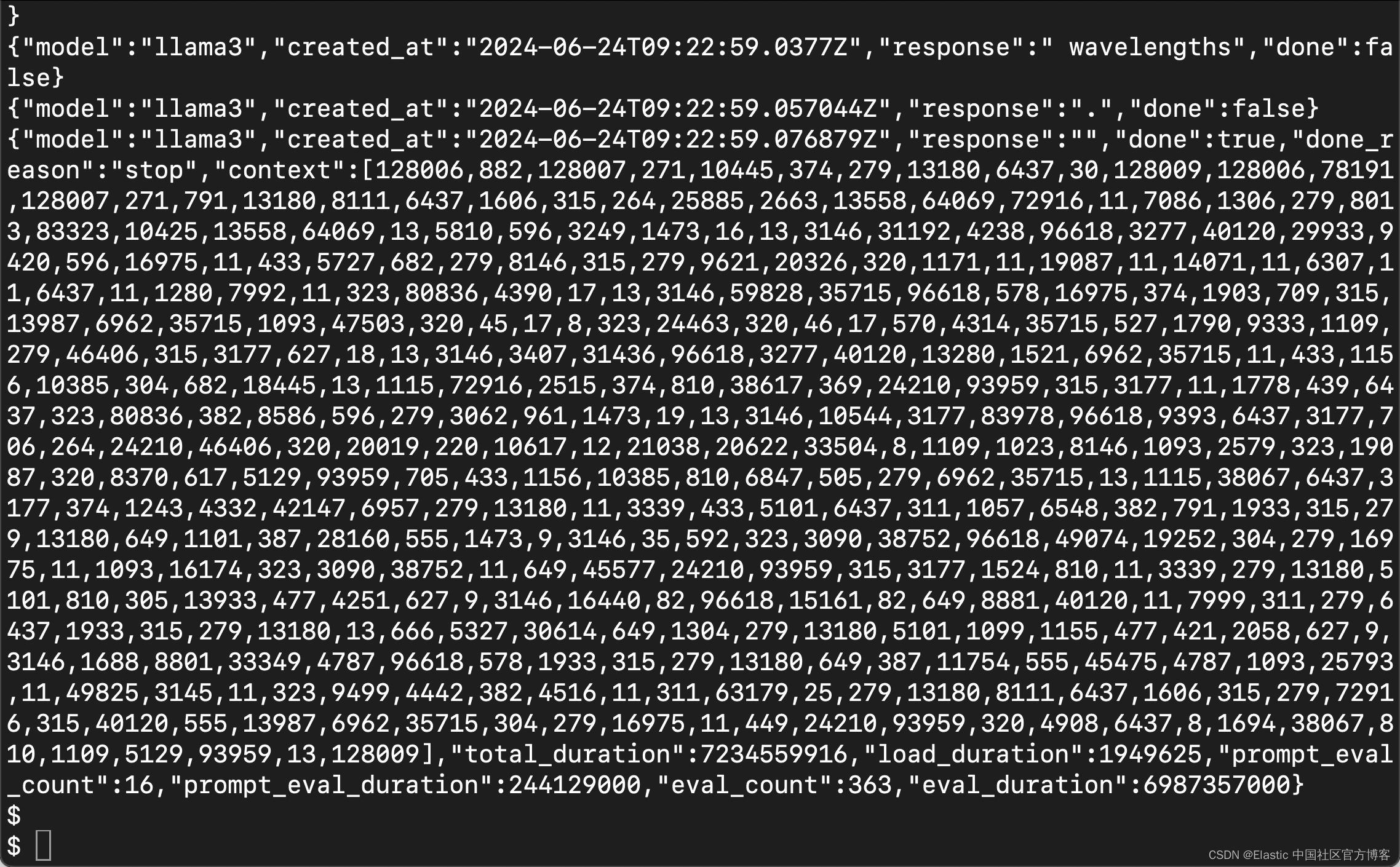
在提示符下,输出如下所示。
我们现在使用 Ollama 在本地运行 Llama3。
下载数据集文档
我们可以使用如下的命令来下载文档:
wget https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json
$ pwd
/Users/liuxg/python/elasticsearch-labs/notebooks/integrations/llama3
$ ls
README.md rag-elastic-llama3-elser.ipynb
http_ca.crt rag-elastic-llama3.ipynb
$ wget https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json
--2024-06-25 10:54:01-- https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 52136 (51K) [text/plain]
Saving to: 'workplace-documents.json'
workplace-documents.jso 100%[=============================>] 50.91K 260KB/s in 0.2s
2024-06-25 10:54:02 (260 KB/s) - 'workplace-documents.json' saved [52136/52136]
$ ls
README.md rag-elastic-llama3-elser.ipynb workplace-documents.json
http_ca.crt rag-elastic-llama3.ipynb展示
我们在项目当前的目录下打入如下的命令:
jupyter notebook rag-elastic-llama3.ipynb读入变量并连接到 Elasticsearch
from elasticsearch import Elasticsearch, AsyncElasticsearch, helpers
from dotenv import load_dotenv
import os
load_dotenv()
ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
ES_ENDPOINT = os.getenv("ES_ENDPOINT")
COHERE_API_KEY = os.getenv("COHERE_API_KEY")
url = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"
print(url)
client = AsyncElasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
info = await client.info()
print(info)
从上面的输出中,我们可以看到已经成功地连接到 Elasticsearch 了。
注意:在上面我们使用了 AsyncElasticsearch 而不是 Elasticsearch。这个是由于下面的一个 Ollama 调用所需要的。详细情况,请参阅帖子。
准备文档以进行分块和提取
我们现在准备使用 Llamaindex 进行处理的 Document 类型的数据。我们先读入文件:
import json
# from urllib.request import urlopen
from llama_index.core import Document
# url = "https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json"
# response = urlopen(url)
# workplace_docs = json.loads(response.read())
import json
# Load data into a JSON object
with open('workplace-documents.json') as f:
workplace_docs = json.load(f)
# Building Document required by LlamaIndex.
documents = [
Document(
text=doc["content"],
metadata={
"name": doc["name"],
"summary": doc["summary"],
"rolePermissions": doc["rolePermissions"],
},
)
for doc in workplace_docs
]在 LlamaIndex 中定义 Elasticsearch 和提取管道以进行文档处理。使用 Llama3 生成嵌入。
我们现在使用所需的索引名称、文本字段及其相关嵌入来定义 Elasticsearchstore。我们使用 Llama3 生成嵌入。我们将在索引上运行语义搜索,以查找与用户提出的查询相关的文档。我们将使用 Llamaindex 提供的 SentenceSplitter 对文档进行分块。所有这些都作为 Llamaindex 框架提供的 IngestionPipeline 的一部分运行。
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
es_vector_store = ElasticsearchStore(
index_name="workplace_index",
es_url = url,
es_client = client,
vector_field="content_vector",
text_field = "content",
es_user = ES_USER,
es_password = ES_PASSWORD)
# Embedding Model to do local embedding using Ollama.
ollama_embedding = OllamaEmbedding("llama3")
# LlamaIndex Pipeline configured to take care of chunking, embedding
# and storing the embeddings in the vector store.
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=512, chunk_overlap=100),
ollama_embedding,
],
vector_store=es_vector_store,
)执行管道
这将对数据进行分块,使用 Llama3 生成嵌入并将其提取到 Elasticsearch 索引中,并将嵌入到密集向量字段中。
pipeline.run(show_progress=True, documents=documents)
嵌入存储在维度为 4096 的密集向量场中。维度大小来自于从 Llama3 生成的嵌入的大小。
定义 LLM 设置。
这将连接到您的本地 LLM。有关在本地运行 Llama3 的步骤的详细信息,请参阅 https://ollama.com/library/llama3。
如果你有足够的资源(至少 >64 GB 的 RAM 和 GPU 可用),那么你可以尝试 70B 参数版本的 Llama3
from llama_index.llms.ollama import Ollama
from llama_index.core import Settings
Settings.embed_model = ollama_embedding
local_llm = Ollama(model="llama3")设置语义搜索并与 Llama3 集成
我们现在将 Elasticsearch 配置为 Llamaindex 查询引擎的向量存储。然后使用 Llama3 的查询引擎通过来自 Elasticsearch 的上下文相关数据回答你的问题。
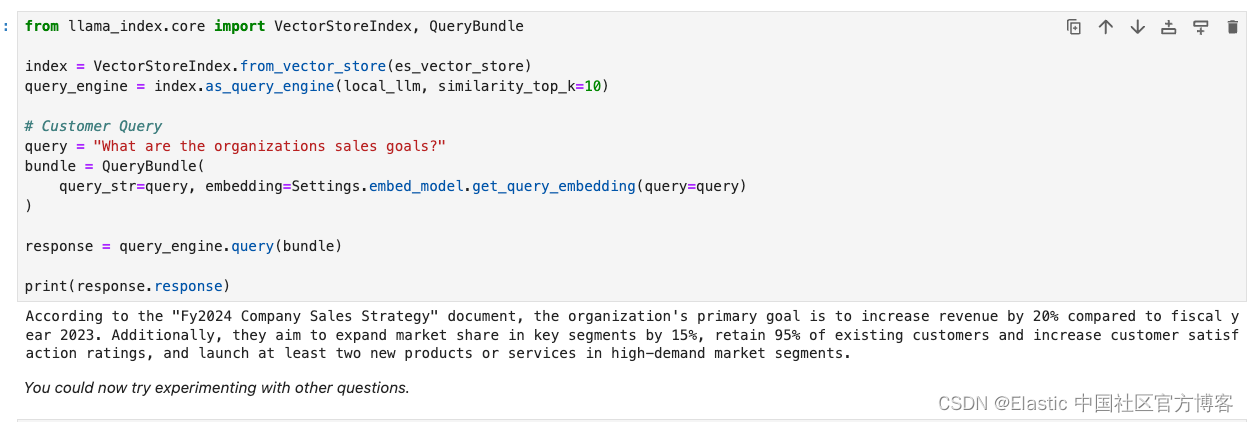
from llama_index.core import VectorStoreIndex, QueryBundle
index = VectorStoreIndex.from_vector_store(es_vector_store)
query_engine = index.as_query_engine(local_llm, similarity_top_k=10)
# Customer Query
query = "What are the organizations sales goals?"
bundle = QueryBundle(
query_str=query, embedding=Settings.embed_model.get_query_embedding(query=query)
)
response = query_engine.query(bundle)
print(response.response)