今天给小伙伴们带来了一篇详细介绍 Python 爬虫入门的教程,从实战出发,适合初学者。
小伙伴们只需在阅读过程紧跟文章思路,理清相应的实现代码,30 分钟即可学会编写简单的 Python 爬虫。
这篇 Python 爬虫教程主要讲解以下 5 部分内容:
- 了解网页;
- 使用 requests 库抓取网站数据;
- 使用 Beautiful Soup 解析网页;
- 清洗和组织数据;
- 爬虫攻防战。
不多废话,下面将内容展示给大家:
了解网页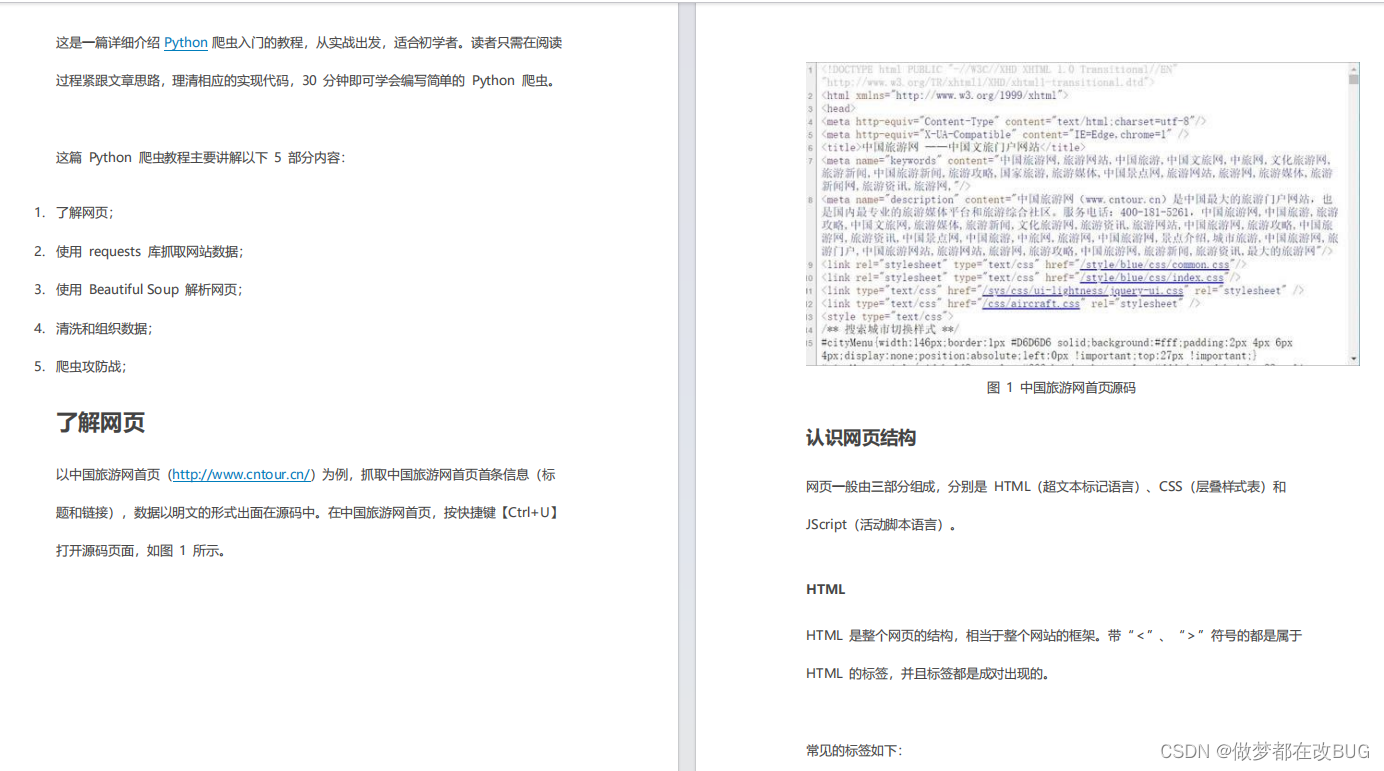

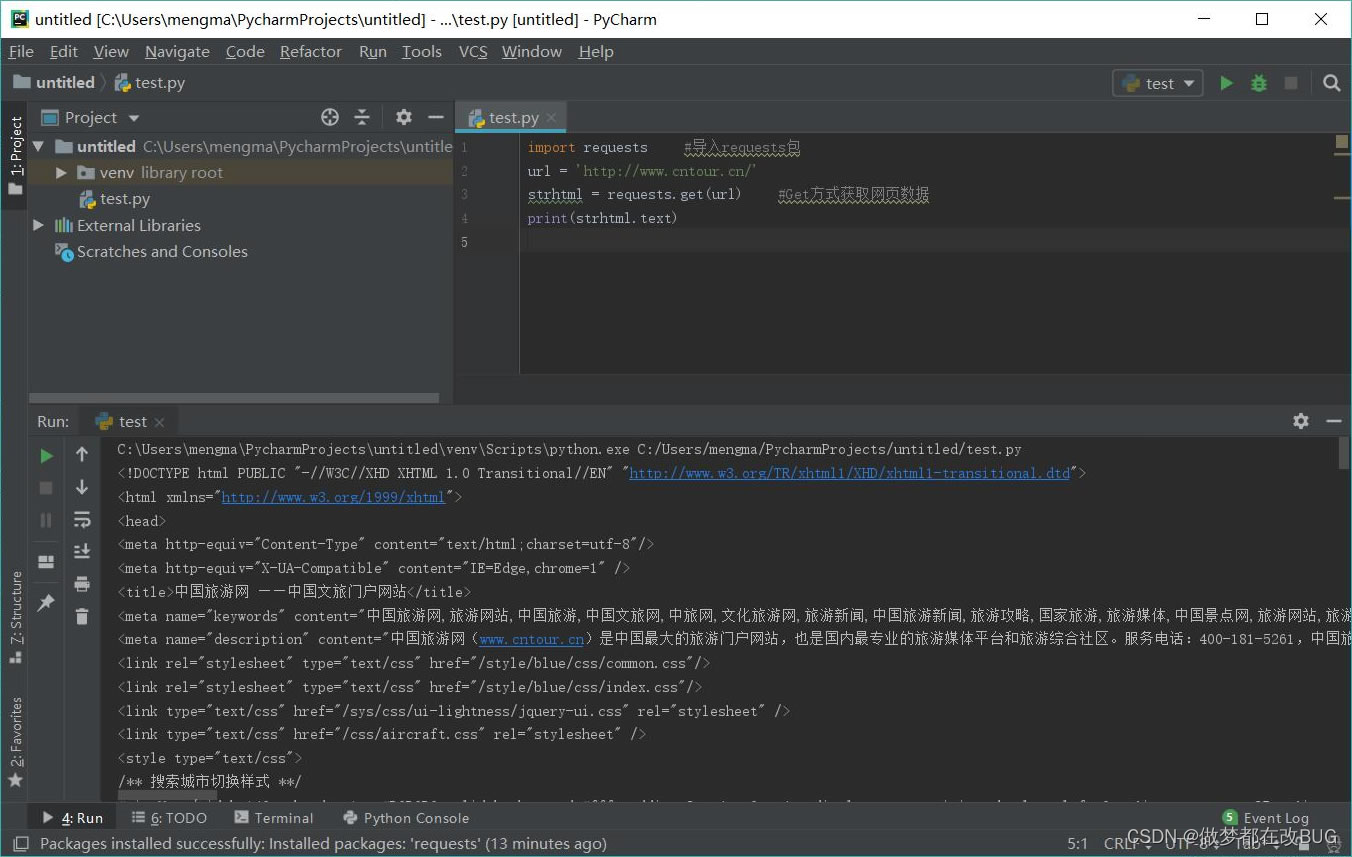
使用 requests 库抓取网站数据

使用 Beautiful Soup 解析网页

清洗和组织数据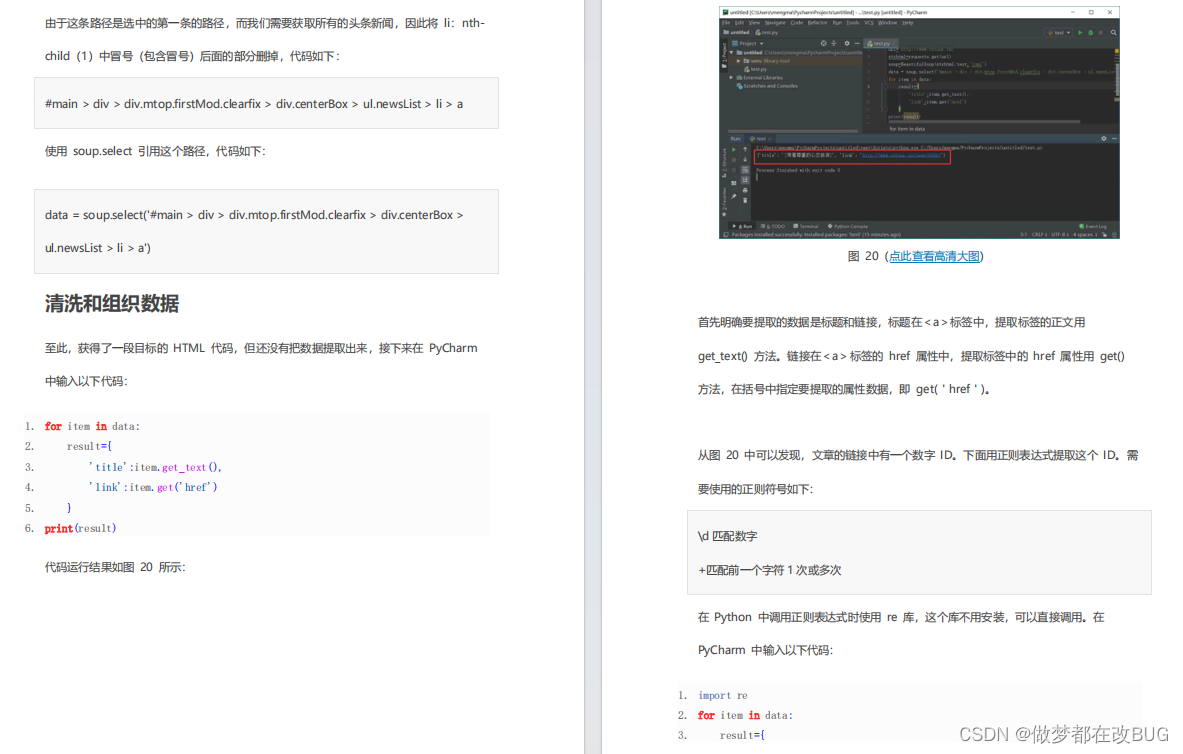
爬虫攻防战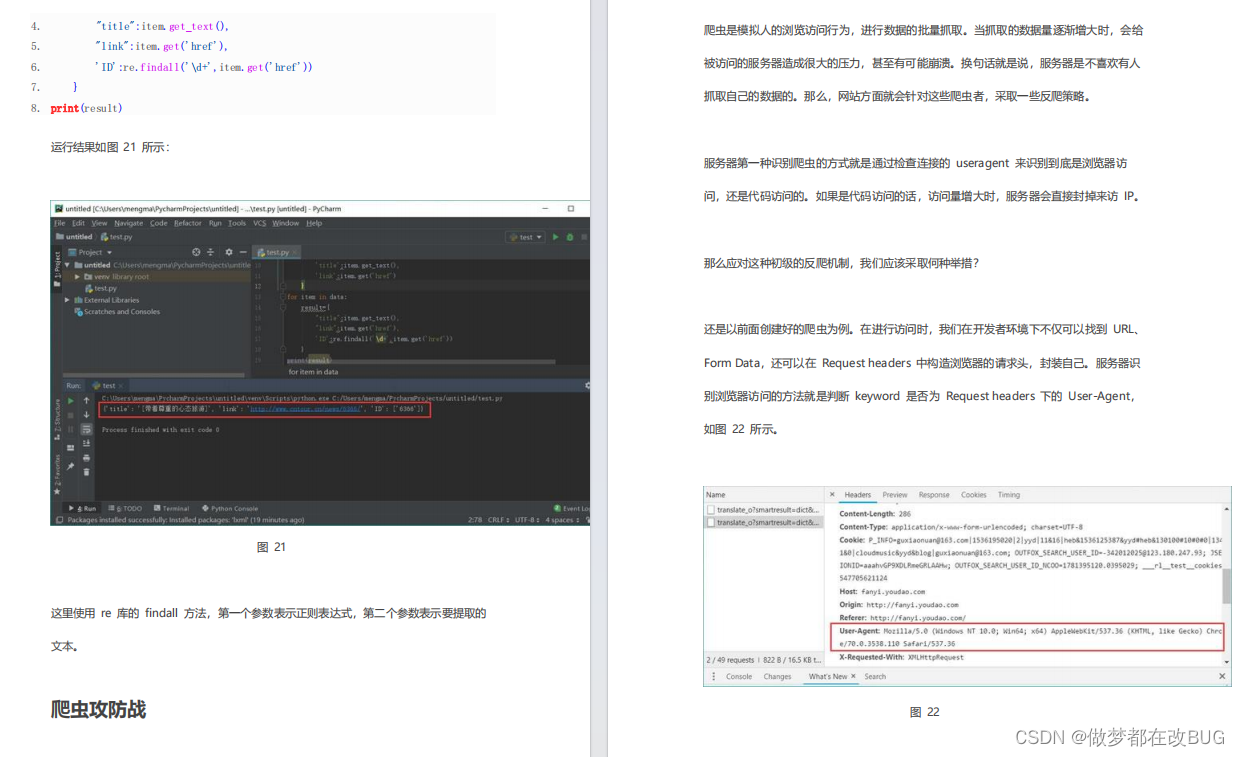
限于文章篇幅原因,就展示到这里了,有需要的小伙伴可以查看下方名片↓↓↓