目录
[9) 补充](#9) 补充)
2、binlog增长过快,mysql性能骤降如何优化?(性能优化)
[2)常见的 MySQL 读写分离方法](#2)常见的 MySQL 读写分离方法)
[① 基于程序代码内部实现](#① 基于程序代码内部实现)
[② 基于中间代理层实现](#② 基于中间代理层实现)
[④ 三个库都创建amoeba用户,并进行授权](#④ 三个库都创建amoeba用户,并进行授权)
[⑤ 运行amoeba](#⑤ 运行amoeba)
[⑥ 测试](#⑥ 测试)
在企业应用中,成熟的业务通常数据量都比较大,单台mysql在安全性、高可用性和高并发方面无法满足实际的需求,会需要配置多台主从数据库服务器、读写分离来实现mysql的高负载和高可用。
一、主从复制【★】
两个日志三个线程
1)主从复制作用
- 实现读写分离
- 跨主机热备份数据(数据异地备份)
- 作为数据库高可用性的基础
2)主从复制的分类
1)statement 基于语句的复制(优点:执行效率高,占用空间小;缺点:无法保证在高并发高负载时候的精确度)
2)row 基于行的复制(优点:精确度高;缺点:执行效率低,占用空间大)
3)mixed 混合类型的复制(默认采用基于语句的复制,一旦发现基于语句无法保证精确复制时,就会采用基于行的复制)
3)主从复制的原理
基于二进制日志进行数据同步
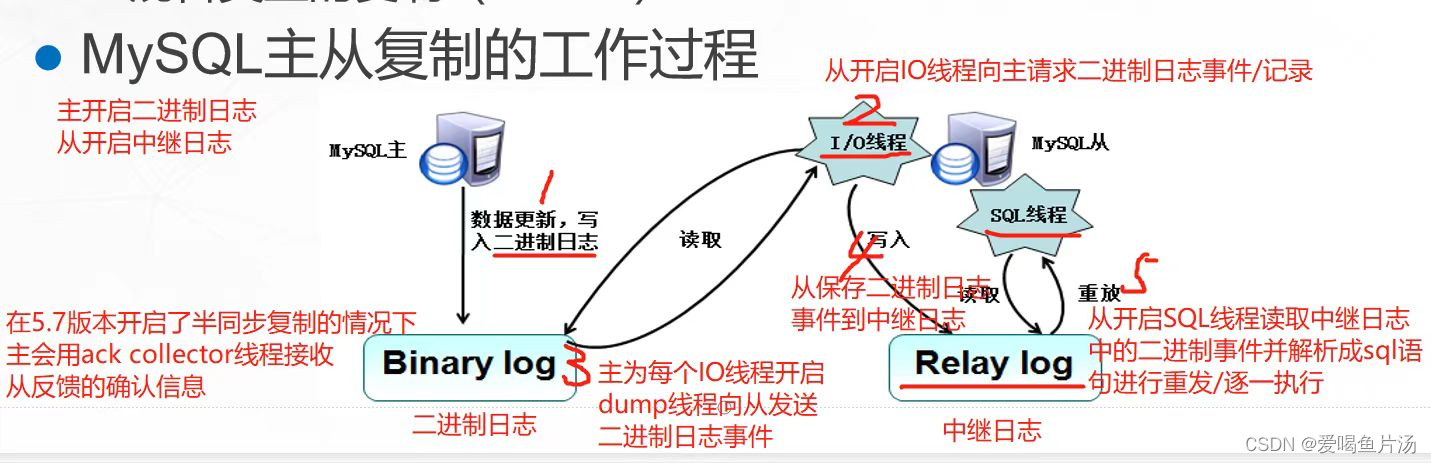
4)主从复制的主要工作过程【★★】
关键词:两个日志,三个线程
- 主库(master)如果发生数据更新,会将写入操作记录到二进制日志(bin log)里
- 从库(slave)探测到主库的二进制日志发生了更新,就会开启IO线程向主库请求二进制日志事件
- 主库会为每个从库IO线程的请求开启DUMP线程,并发送二进制日志事件给从库
- 从库接收到二进制日志事件后会保存到自己的中继日志(relay log)中, 附:在半同步模式下从库会返回确认信息给主库,主库会用ack收集线程接收从库反馈的确认信息(5.7版本开始支持)
- 从库还会开启SQL线程读取中继日志里的事件,并在本地重放(将二进制日志事件解析成sql语句逐一执行),从而实现主库和从库的数据一致
5)主从复制案例部署
|-----|-----------------|--------------------------|
| 主库 | 192.168.170.200 | 注意: 主从数据库版本相差不能大,建议使用一致的 |
| 从库1 | 192.168.170.101 | 注意: 主从数据库版本相差不能大,建议使用一致的 |
| 从库2 | 192.168.170.120 | 注意: 主从数据库版本相差不能大,建议使用一致的 |
主从复制的配置步骤
1)主从服务器先做时间同步
2)修改主从数据库的配置文件,主库开启二进制日志,从库开启中继日志
3)在主库创建主从复制的用户,并授予主从复制的权限
4)在从库使用 change master to 对接主库,并 start slave 开启同步
5)在从库使用 show slave status\G 查看 IO线程和 SQL线程的状态是否都为 YES
1、初始化操作、同步时间
注意:如果你使用克隆的方法得到三台mysql服务器,会存在uuid冲突问题导致主从复制实现不了,需要修改uuid。
bash
初始化
setenforce 0
systemctl disable --now firewalld
yum remove -y mariadb-libs.x86_64
安装MySQL。下载到opt目录中并解压,解压后的包重命名并移动到/usr/local目录中
cd /opt/
rm -rf *
rz -E
tar xf mysql-5.7.39-linux-glibc2.12-x86_64.tar.gz
mv mysql-5.7.39-linux-glibc2.12-x86_64 /usr/local/mysql
创建程序用户管理并修改mysql目录和配置文件的权限
useradd -s /sbin/nologin mysql
chown -R mysql:mysql /usr/local/mysql
修改配置文件
vim /etc/my.cnf
chown mysql:mysql /etc/my.cnf
======================================================================================
[client]
port = 3306
socket=/usr/local/mysql/mysql.sock
[mysqld]
user = mysql
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
port = 3306
character-set-server=utf8
pid-file = /usr/local/mysql/mysqld.pid
socket=/usr/local/mysql/mysql.sock
bind-address = 0.0.0.0
skip-name-resolve
max_connections=2048
default-storage-engine=INNODB
max_allowed_packet=16M
server-id = 1
sql_mode = STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
======================================================================================
设置环境变量,申明/宣告mysql命令便于系统识别并初始化数据库
echo "PATH=$PATH:/usr/local/mysql/bin" >> /etc/profile
source /etc/profile
cd /usr/local/mysql/bin
./mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
设置系统识别,进行操作:
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chmod +x /etc/init.d/mysqld
systemctl daemon-reload
systemctl restart mysqld
初始化数据库密码:
mysqladmin -u root -p password "123456"
登录数据库
mysql -u root -p123456
创建用户并设置密码:
CREATE USER 'root'@'%' IDENTIFIED BY '123456';
赋予远程连接的权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%';
刷新生效
flush privileges;
修改加密方式,可以进行远程连接
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
bash
时间同步操作
方式一:chrony自动同步时间,centOS7之后官方建议使用chrony
安装开启chrony程序
yum install -y chrony
systemctl start chronyd
修改chrony配置文件
vim /etc/chrony.conf
====================================================================================
3 #server 0.centos.pool.ntp.org iburst
4 #server 1.centos.pool.ntp.org iburst
5 #server 2.centos.pool.ntp.org iburst
6 #server 3.centos.pool.ntp.org iburst
7 server ntp.aliyun.com iburst
====================================================================================
重启检查是否同步成功,210 Number of sources = 1表示同步成功
systemctl restart chronyd
chronyc sources
方式二:ntpd自动同步时间
查看是否安装,没有安装的话就yum安装一下ntpd服务,注意ntp与chrony端口号相同不要冲突
rpm -q ntp
yum install -y ntpd
systemctl start ntpd
查看是否同步
ntpd -p
方式三:ntpdate手动同步
查看是否安装,没有安装用yum安装即可
rpm -q ntpdate
指定阿里云事件源服务器就会自动同步好
ntpdate ntp.aliyun.com
查看ntp路径,计划任务中使用绝对路径
which ntpdate
配合计划任务做每半小时自动同步
crontab -e
*/30 * * * * /sbin/ntpdate ntp.aliyun.com &> /dev/null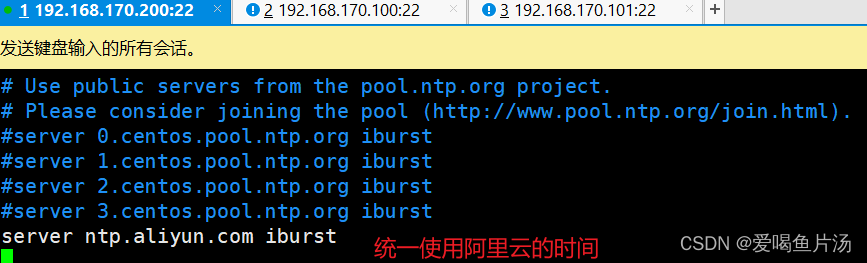
生产环境中不可能所有服务器都连接外网,会有一台跳板机或边缘服务器既可以连接内网也可以连接外网,用ntp或者chrony同步时钟源服务器,然后内网服务器server连接到边缘服务器地址,把边缘服务器作为内网服务器的时钟源,从而实现时间同步。
如何搭建ntp时间服务器?
1、主机A做ntp服务器
①安装ntp服务
bashyum -y install ntp②修改配置文件/etc/ntp.conf
bash#restrict default kod nomodify notrap nopeer noquery 注释此行内容 # nomodify 客户端不可以修改时间参数但是可以同步时间服务器,添加以下内容 restrict default nomodify 以下为 NTP服务默认的时间同步源,将其注释 #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst 添加新的时间同步源 server time1.aliyun.com③开启ntpd服务,查看同步状态
bashsystemctl start ntpd.service 查看ntp网络时间同步状态 ntpq -p remote refid st t when poll reach delay offset jitter ============================================================================== 203.107.6.88 10.165.84.13 2 u 28 64 1 15.767 708.472 0.0002、主机B做客户机
ntp服务器开启ntp服务后等待几分钟后,客户机再同步。
bashntpdate 192.168.66.11 14 Feb 11:37:25 ntpdate[1453]: step time server 192.168.66.11 offset 0.880807 sec # 将命令放入计划任务即可 crontab -l */5 * * * * /usr/sbin/ntpdate 192.168.66.11 &>/dev/null
2、主库配置
bash
主库修改配置文件
vim /etc/my.cnf
-------------------------------------------------------------------------------------------
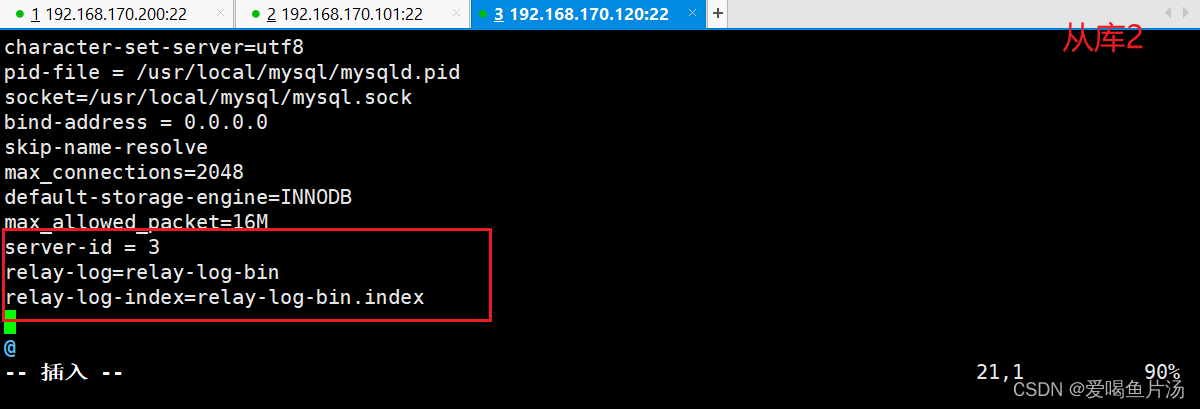
server-id = 1 #确保id不与从库冲突
log-bin=mysql-bin #添加,主服务器开启二进制日志
binlog_format=mixed
#以下为选配项
expire_logs_days=7 #设置二进制日志文件过期时间,默认值为0,表示logs不过期
max_binlog_size=500M #设置二进制日志限制大小,如果超出给定值,日志就会发生滚动,默认值是1GB
skip_slave_start=1 #阻止从库崩溃后自动启动复制,崩溃后再自动复制可能会导致数据不一致的
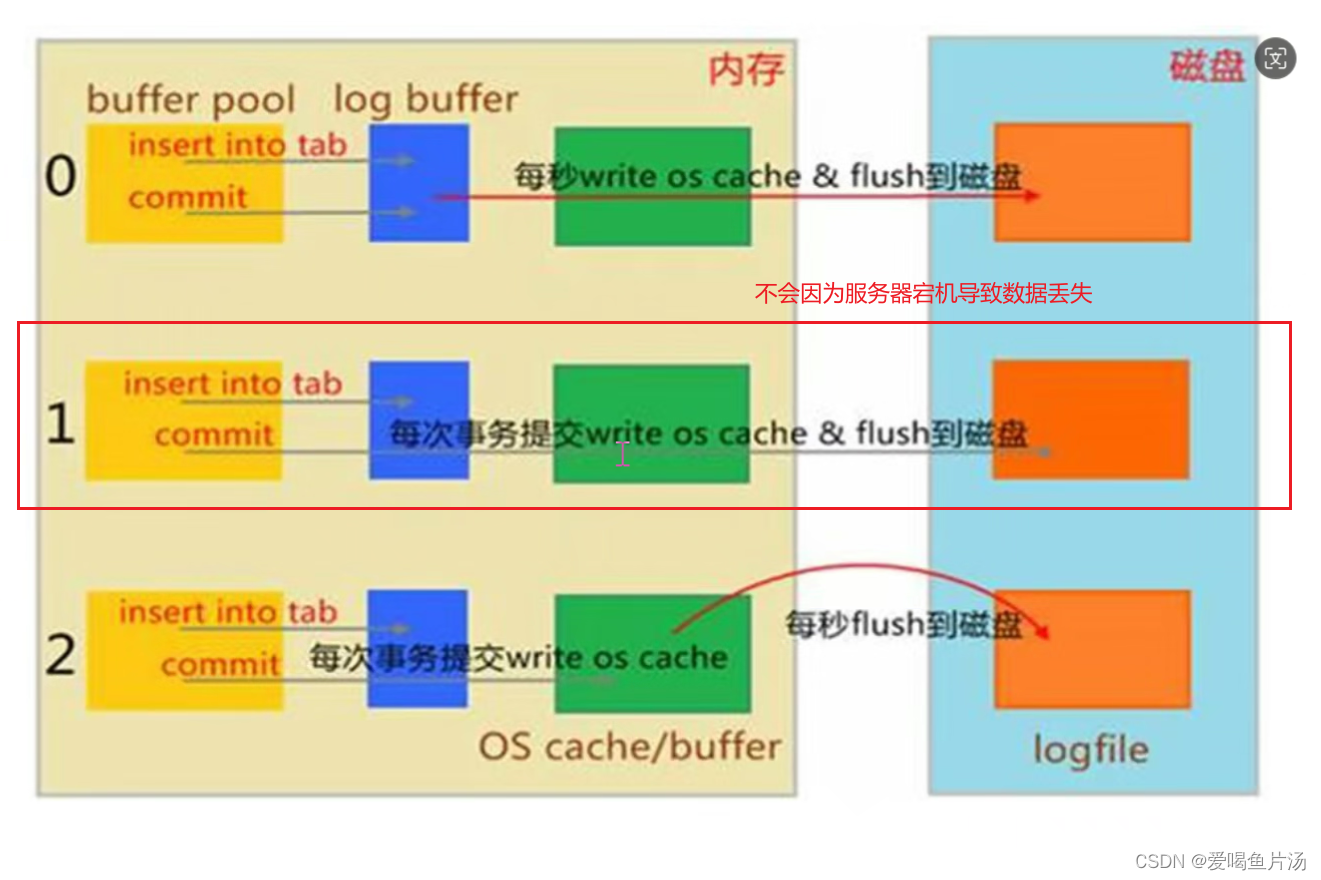
#"双1设置",数据写入最安全
innodb_flush_log_at_trx_commit=1 #redo log(事务日志)的刷盘策略,每次事务提交时MySQL都会把事务日志缓存区的数据写入日志文件中,并且刷新到磁盘中,该模式为系统默认
sync_binlog=1 #在进行每1次事务提交(写入二进制日志)以后,Mysql将执行一次fsync的磁盘同步指令,将缓冲区数据刷新到磁盘
-------------------------------------------------------------------------------------------
systemctl restart mysqld
登录数据库
mysql -u root -p密码
GRANT REPLICATION SLAVE ON *.* TO 'myslave'@'192.168.170.%' IDENTIFIED BY '123456'; 给从服务器创建用户并授权
FLUSH PRIVILEGES; #刷新二进制文件
show master status; #查看主库当前使用的二进制日志和位置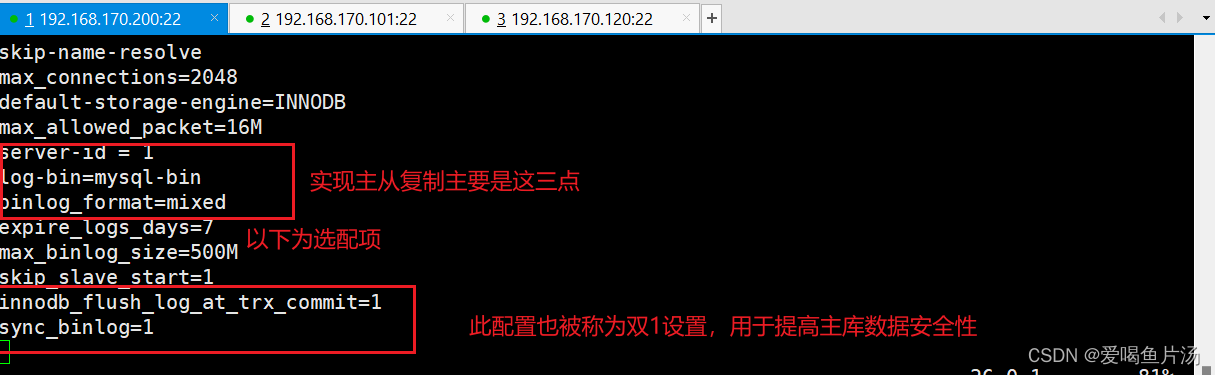

关于"双1设置"
bashinnodb_flus_log_at_trx_commit=1 sync_binlog=1"双1设置"数据写入最安全,每次事务提交都讲二进制日志和缓冲数据刷盘,双1设置适合数据安全性能要求非常高的业务,如订单付款之类的。但像大型电商活动,双1设置会成为系统性能瓶颈,推荐使用性能较快的设置,并使用带蓄电池后备电源防止系统断电异常。
bashinnodb_flus_log_at_trx_commit=2 sync_binlog=500
3、从库配置
bash
[root@localhost ~]# vim /etc/my.cnf
[root@localhost ~]# systemctl restart mysqld.service
登录数据库
mysql -u root -p123456
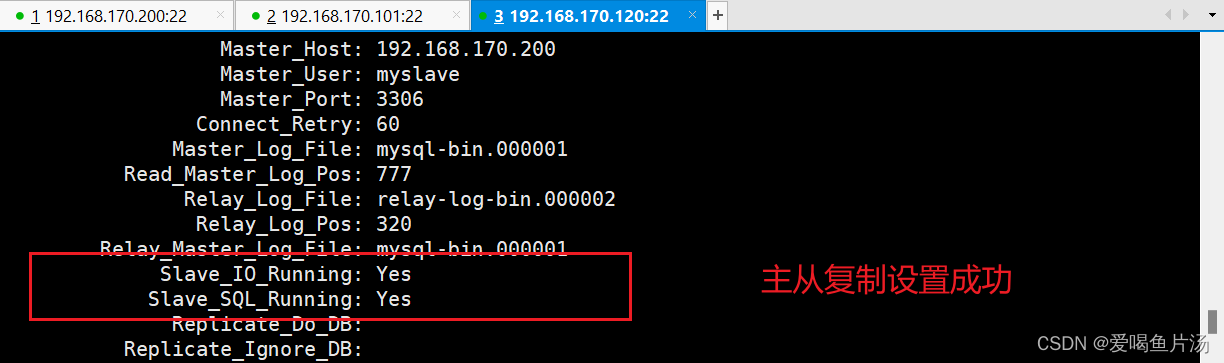
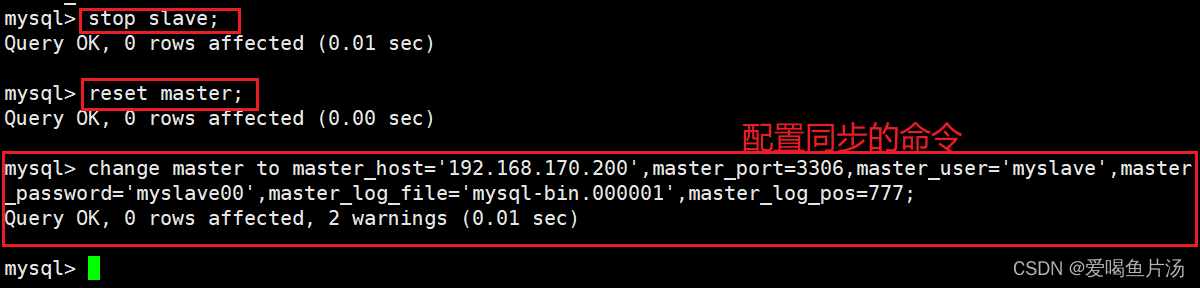
配置同步,注意 master_log_file 和 master_log_pos 的值要与主库上查询的一致
change master to master_host='192.168.170.200',master_port=3306,master_user='myslave',master_password='myslave00',master_log_file='mysql-bin.000001',master_log_pos=777;
开启同步
start slave;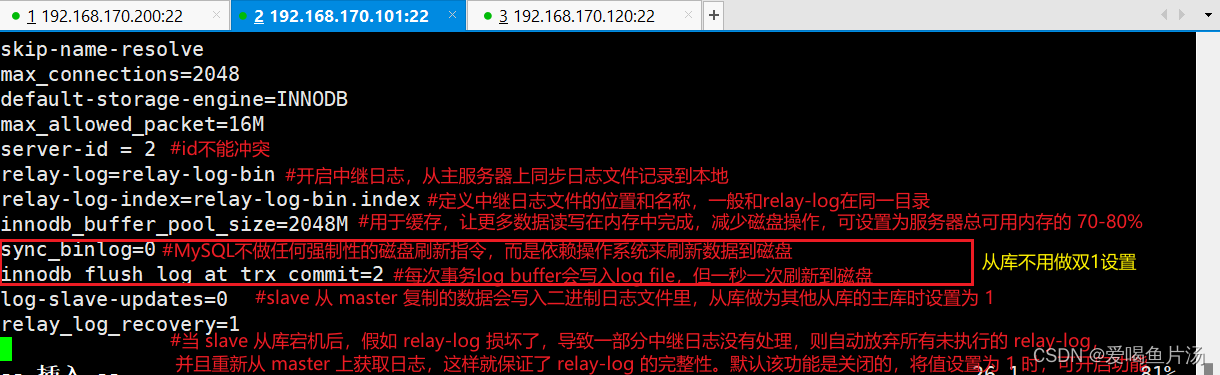
4、验证
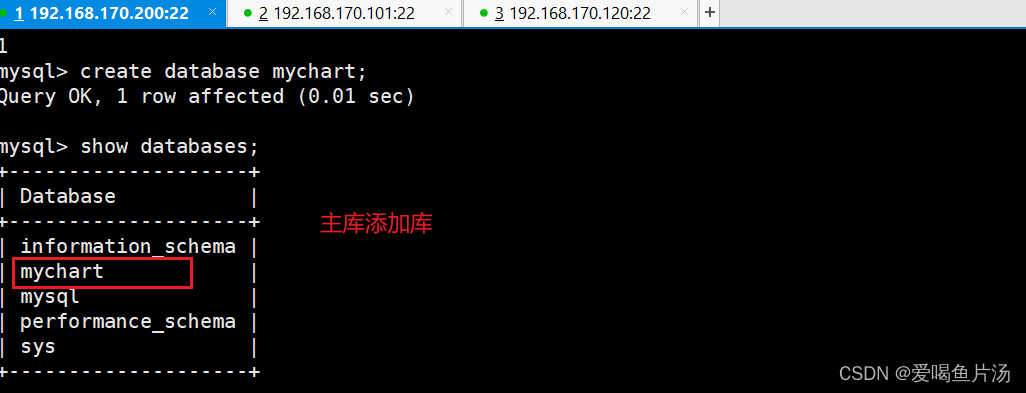
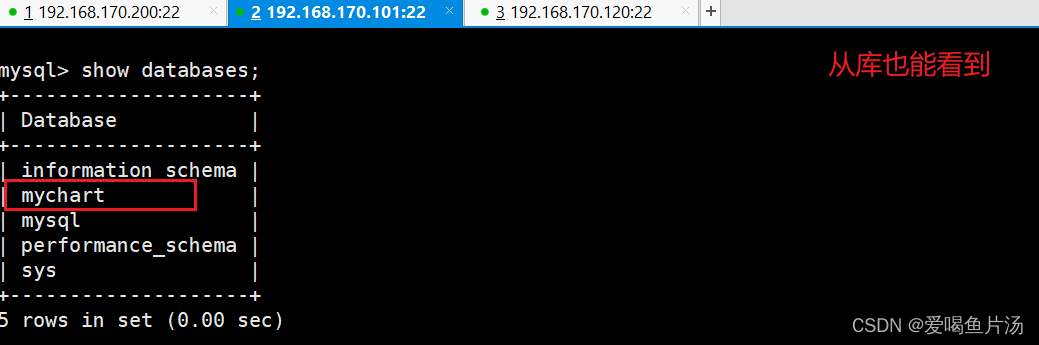
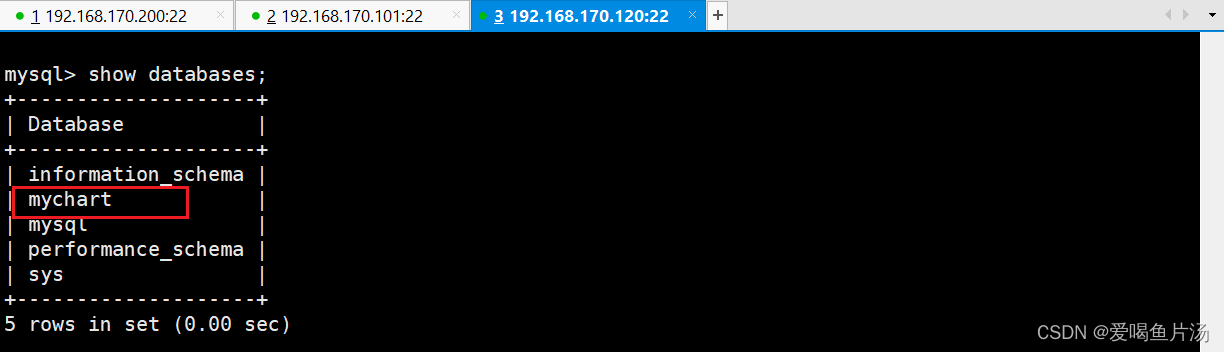
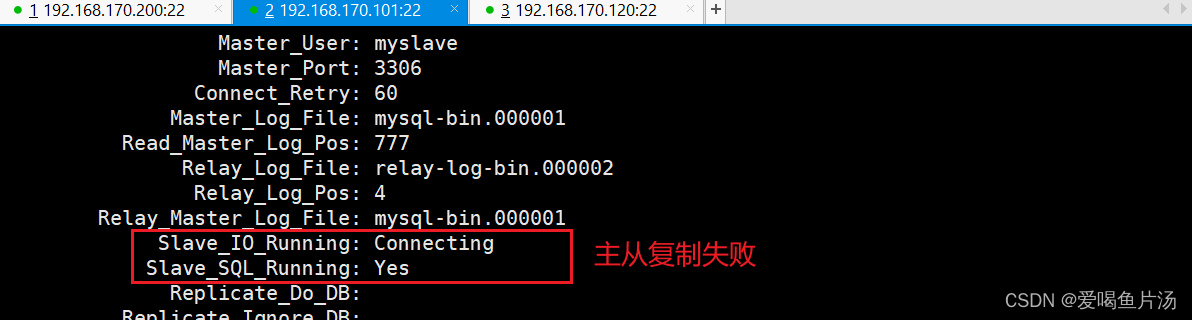
报错:主从状态不是YES,这里是我的配置命令输错导致。想要重新设置master节点,做以下操作。

6)主从复制延迟【★★】
生产环境中用量大的话会经常出现主从复制延迟的问题,会导致客户在主服务器写入数据,但长期无法及时读取到最新的数据。
主从复制延迟如何判断?可能原因?解决方案?(故障案例)
【如何判断?】通过在从库执行show slave status\G命令,查看输出的Seconds_Behind_Master参数的值来判断,是否有发生主从延时。如果为正值表示主从已经出现延时,数字越大表示从库落后主库越多。
判断方法一 :根据数据库中show slave status\G输出的second_behind_master的值为0表示延时;SQL_DELAY表示从库滞后多少秒。
判断方法二:第三方软件包mk-hearbeat(用的少,此方法略过)
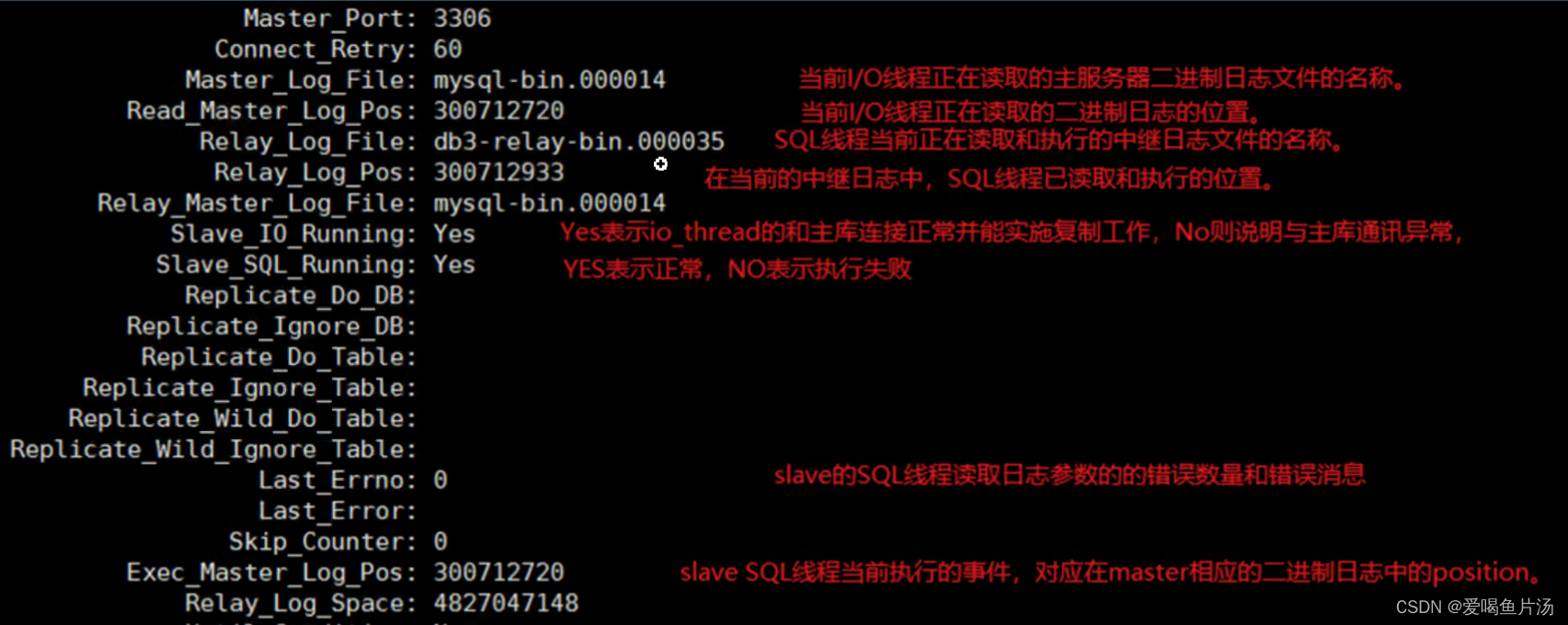
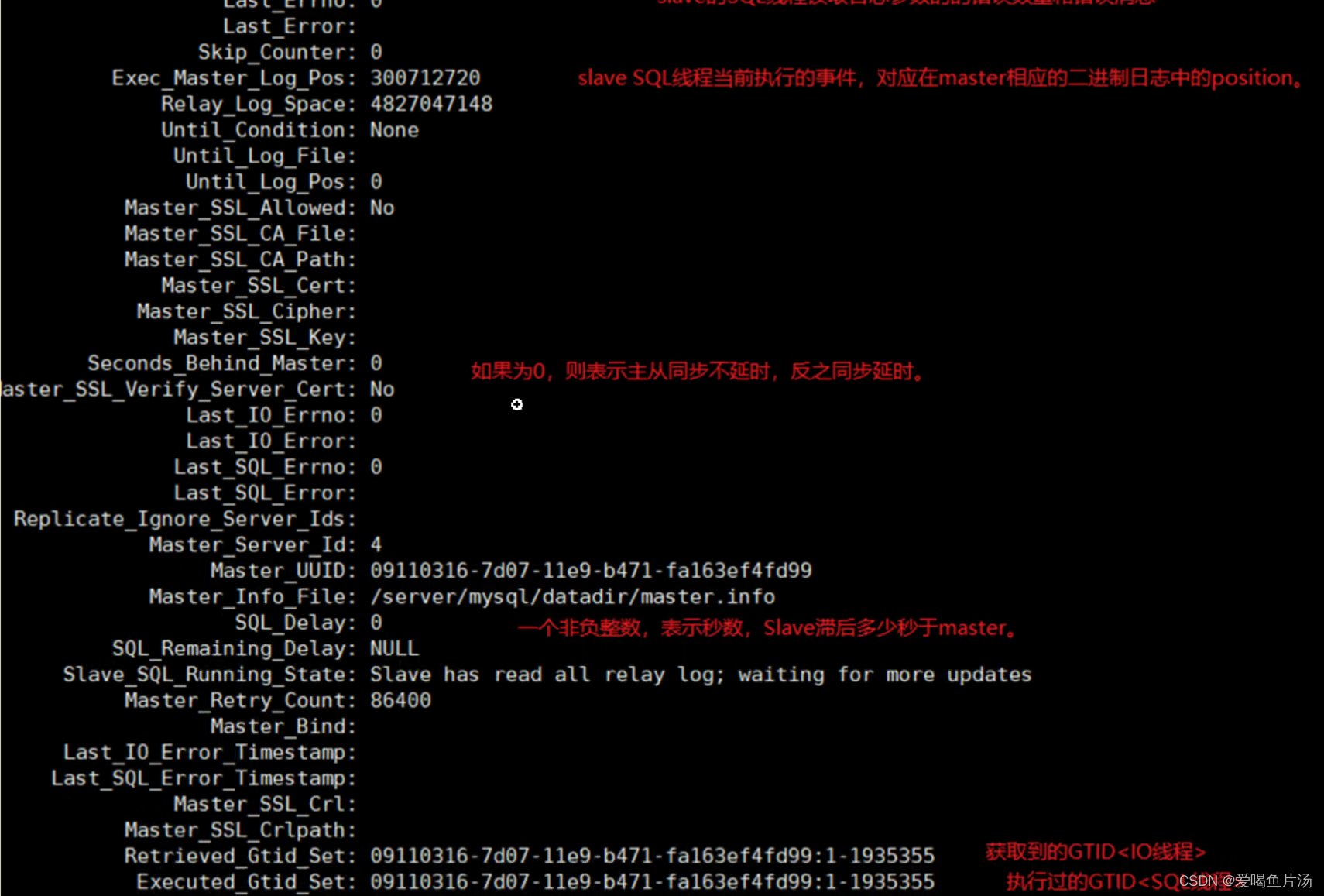
【根本原因】主库可以并发多线程执行写入操作,而从库的SQL线程默认是单线程串行化复制,从库的复制效率可能会跟不上主库的写入速度。
【导致延迟的因素】master服务器高并发有大量事务;网络延迟;从库硬件设备导致;是同步复制而不是异步复制;慢SQL语句过多。
【解决方案】
- 网络方面:将从库分布在相同局域网内或网络延迟较小的环境中。
- 硬件方面:从库配置更好的硬件(CPU 内存 固态硬盘),提升随机写的性能。
- 配置方面:sync_binlog=0、innodb_flush_log_at_trx_commit=2,由于从库不需要这么高的数据安全性,所以不使用 双1设置;logs-slave-updates=0 ,从库同步的事件不记录到从库自身的二进制日志中;innodb_buffer_pool_size=物理内存的80%,加大innodb引擎缓存池大小,让更多数据读写在内存中完成,减少磁盘的IO压力。
- 架构方面:主从复制的同步模式采用 异步复制 或 半同步复制 或 并行复制,采用读写分离架构。
- 操作方面:将大事务拆分为多个较小的事务;优化 DDL 操作,合并多个 DDL 操作为一个批处理操作
主从复制不一致如何处理?(故障案例)【★★★】
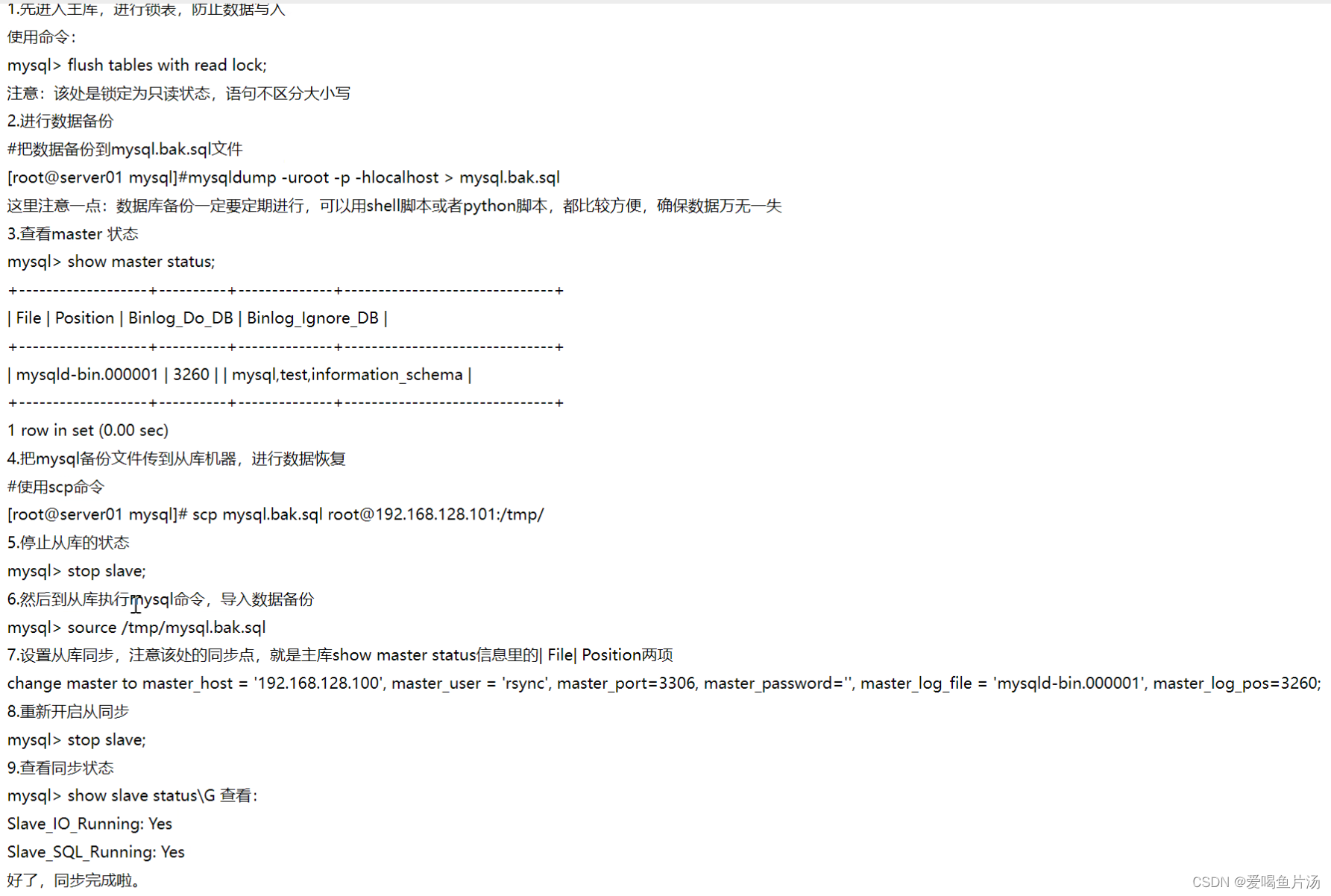
业务繁忙的情况下且数据相差不大,先忽略错误做同步,然后找个不繁忙的时间锁一下数据库,重新做主从复制同步。
重新做主从,完全同步。先进入主库,进行锁表防止数据写入。mysql> flush tabls...第二步,完全备份数据。第三步查看master状态。第四步,把mysql备份文件传导从库,进行数据恢复。第五步停止从库状态。第六步到从库执行mysql命令导入完全数据备份。第七步设置从库同步,注意该处的同步点。第八步重新开启从同步,查看同步状态。
7)MySQL主从复制的同步模式
异步复制:主库在执行完客户端提交的事务后就会立即响应给客户端
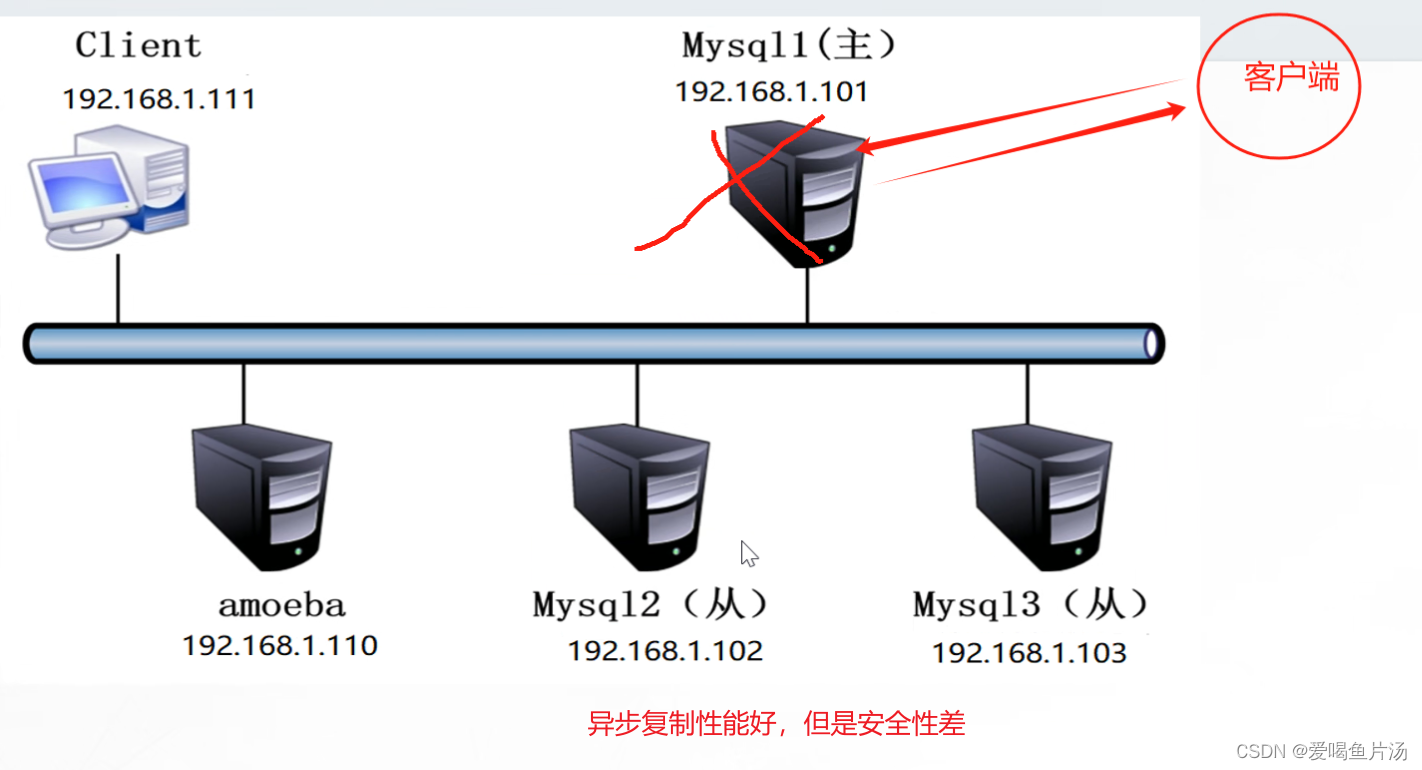
全同步复制:主库在执行完客户端提交的事务后,要等待所有从库返回都响应给主库,才会响应给客户端
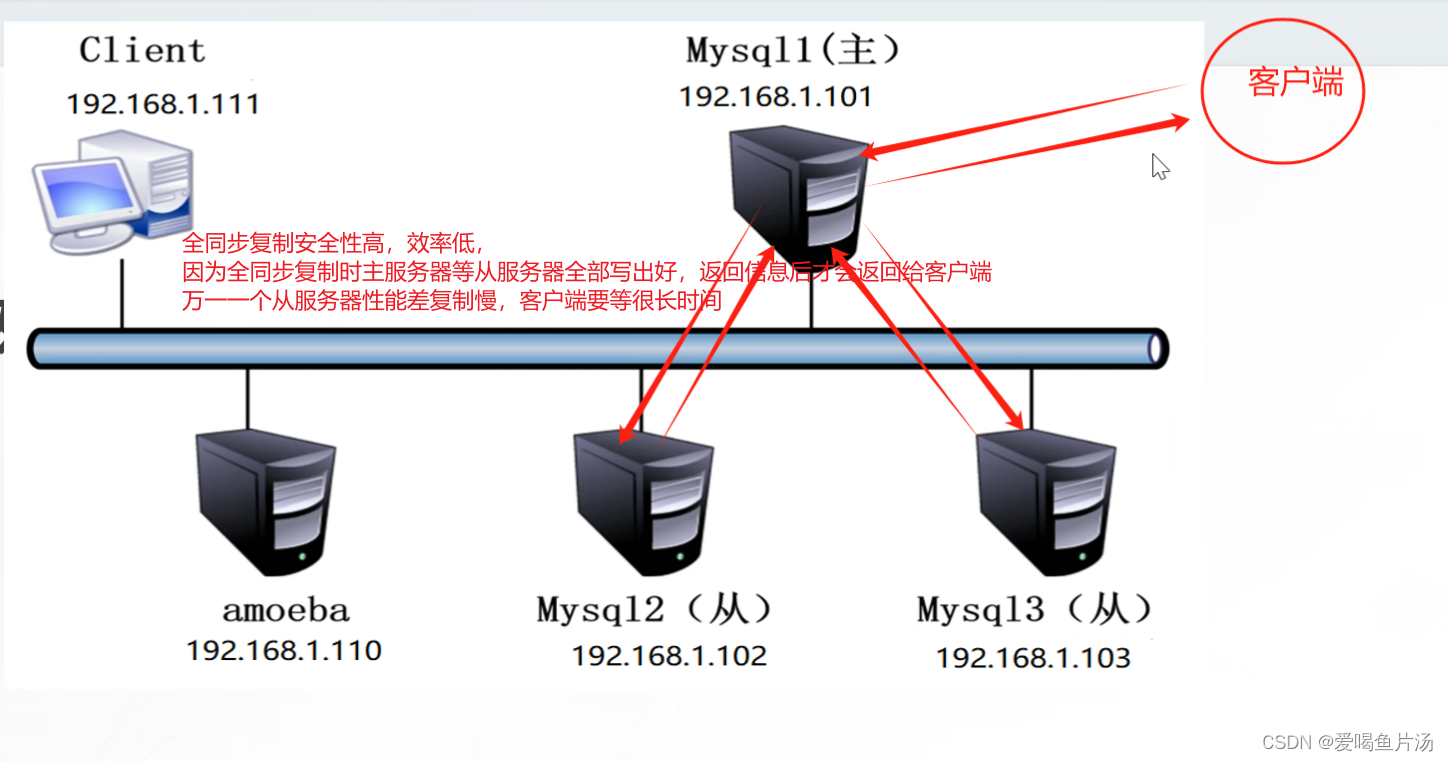
半同步复制:主库在执行完客户端提交的事务后,只要等待至少一个从库返回响应给主库,就会响应给客户端。半同步复制兼顾性能和安全性,所以生产环境中一般都会选用半同步复制模式。
8)启用半同步复制模式
① 主数据库配置
bash
修改配置文件,在 [mysqld] 区域添加下面内容
vim /etc/my.cnf
......
plugin-load=rpl_semi_sync_master=semisync_master.so #加载mysql半同步复制的插件
rpl_semi_sync_master_enabled=ON #或者设置为"1",即开启半同步复制功能
rpl-semi-sync-master-timeout=1000 #超时时间为1000ms,即1s
重启mysql
systemctl restart mysqld
重新登录数据库
mysql -u root -p123456
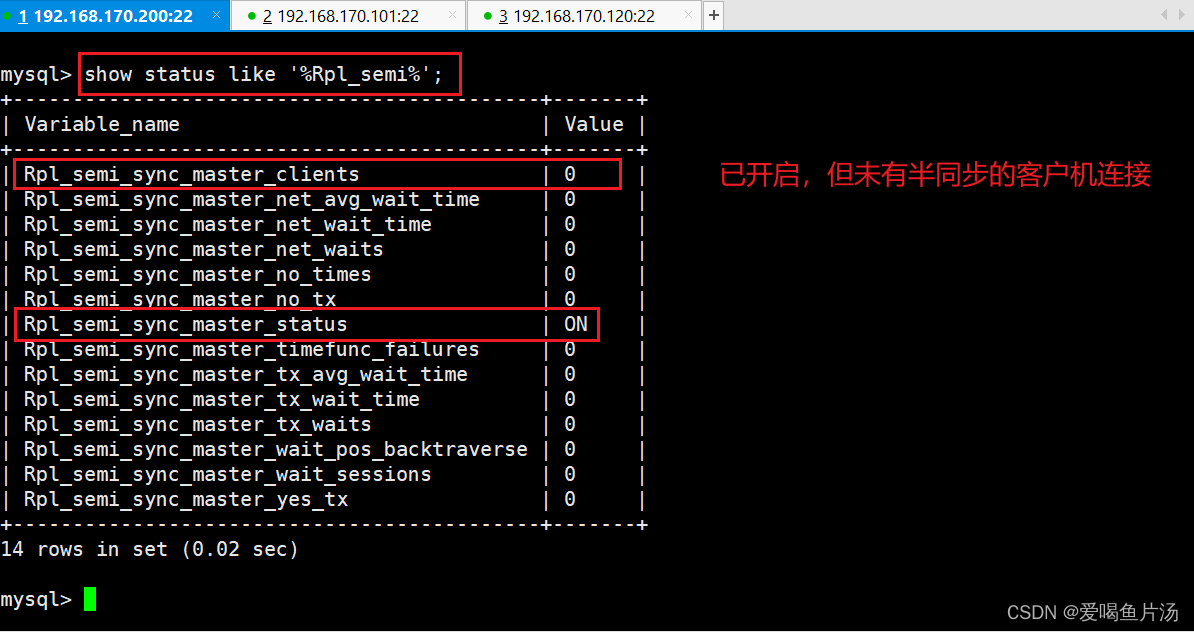
查看半同步复制开启状态和连接的客户机
show status like '%Rpl_semi%';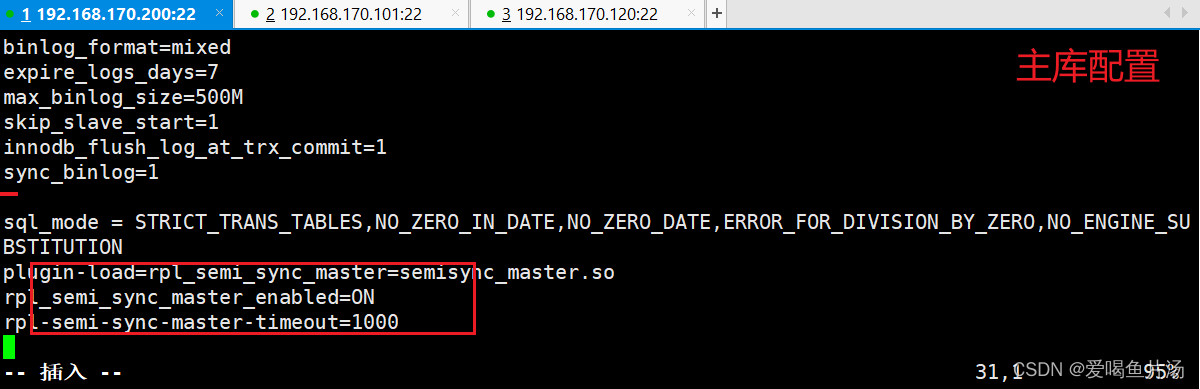
② 从数据库配置
bash
vim /etc/my.cnf
......
plugin-load=rpl_semi_sync_slave=semisync_slave.so
rpl_semi_sync_slave_enabled=ON
systemctl restart mysqld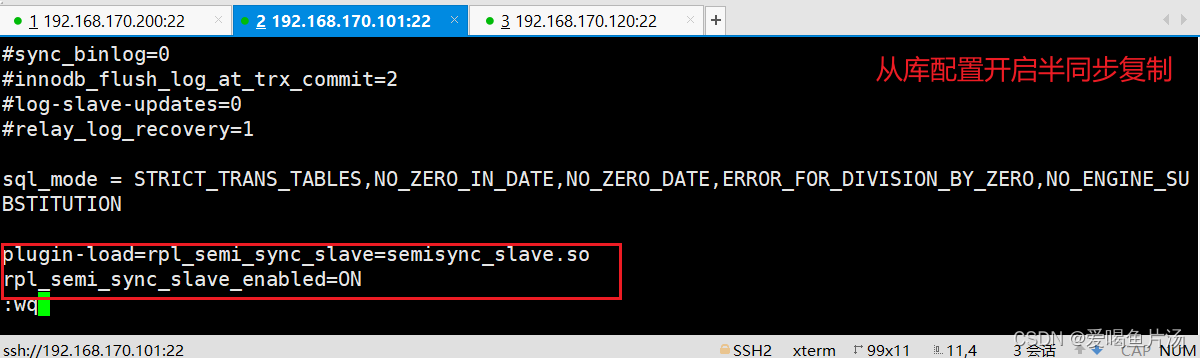
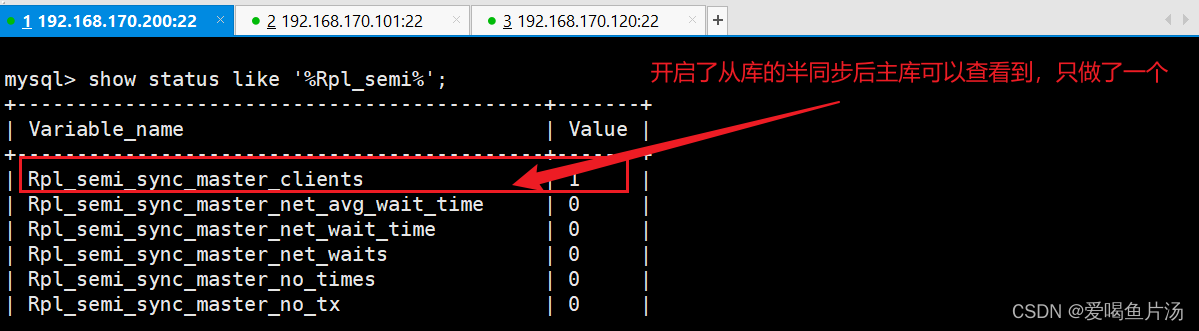
③ 查看半同步是否在运行
bash
#主数据库执行
show status like 'Rpl_semi_sync_master_status';
show variables like 'rpl_semi_sync_master_timeout';
#从数据库执行(此时可能还是OFF状态,需要在下一步重启IO线程后,从库半同步状态才会为ON)
show status like 'Rpl_semi_sync_slave_status';
#重启从数据库上的IO线程
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;参数说明:
Rpl_semi_sync_master_clients #半同步复制客户端的个数
Rpl_semi_sync_master_net_avg_wait_time #平均等待时间(默认毫秒)
Rpl_semi_sync_master_net_wait_time #总共等待时间
Rpl_semi_sync_master_net_waits #等待次数
Rpl_semi_sync_master_no_times #关闭半同步复制的次数
Rpl_semi_sync_master_no_tx #表示没有成功接收slave提交的次数
Rpl_semi_sync_master_status #表示当前是异步模式还是半同步模式,on为半同步Rpl_semi_sync_master_timefunc_failures #调用时间函数失败的次数
Rpl_semi_sync_master_tx_avg_wait_time #事物的平均传输时间
Rpl_semi_sync_master_tx_wait_time #事物的总共传输时间
Rpl_semi_sync_master_tx_waits #事物等待次数
Rpl_semi_sync_master_wait_pos_backtraverse #可以理解为"后来的先到了,而先来的还没有到的次数"
Rpl_semi_sync_master_wait_sessions #当前有多少个session因为slave的回复而造成等待
Rpl_semi_sync_master_yes_tx #成功接受到slave事物回复的次数
9) 补充
1、在什么情况下半同步复制会降为异步复制?
当主库在半同步复制超时时间内(rpl_semi_sync_master_timeout)没有收到从库的响应,就会自动降为半同步复制。当主库发送完一个事务事件后,主库在超时时间内收到了从库的响应,就会又恢复为半同步复制。一主多从的架构中,如果要开启半同步复制,可以只把一台从库开启半同步复制。
2、binlog增长过快,mysql性能骤降如何优化?(性能优化)
【binlog增长过快可能带来的问题】:磁盘空间不足、性能下降;
【增长过快的原因】①大失误生成大量binlog记录 ②频繁的DDL操作 ③长时间的读事务 ④错误的参数配置,如max_binlog_size和expire_logs_days的设置
【解决方案】①拆分大事务 ②优化DDL操作,比如零碎的操作合并一条执行 ③增加binlog的回滚点,设置binlog的保留时长为3天,保存大小为1G等 ④定期清理和归档 ⑤将row改为statement模式,row最精确但很消耗空间
二、mysql读写分离
1)读写分离的原理和作用
原理 :在主库上处理事务性操作(写入操作),在从库上处理查询操作(读操作),再通过主从复制将主库上的数据同步给从库。
作用:通过读写分离可以分担数据库单节点的负载压力,提高数据库的读写性能
2)常见的 MySQL 读写分离方法
① 基于程序代码内部实现
代码中根据select、insert 进行路由分类这类方法也是目前生产环境应用最广泛的。优点是性能较好,因为在程序代码中实现,不需要增加额外的设备为硬件开支;缺点是需要开发人员来实现,运维人员无从下手。但是并不是所有的应用都适合在程序代码中实现读写分离,大型复杂的Java应用用代码实现读写分离对代码改动就较大。
② 基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端请求后通过判断后转发到后端数据库。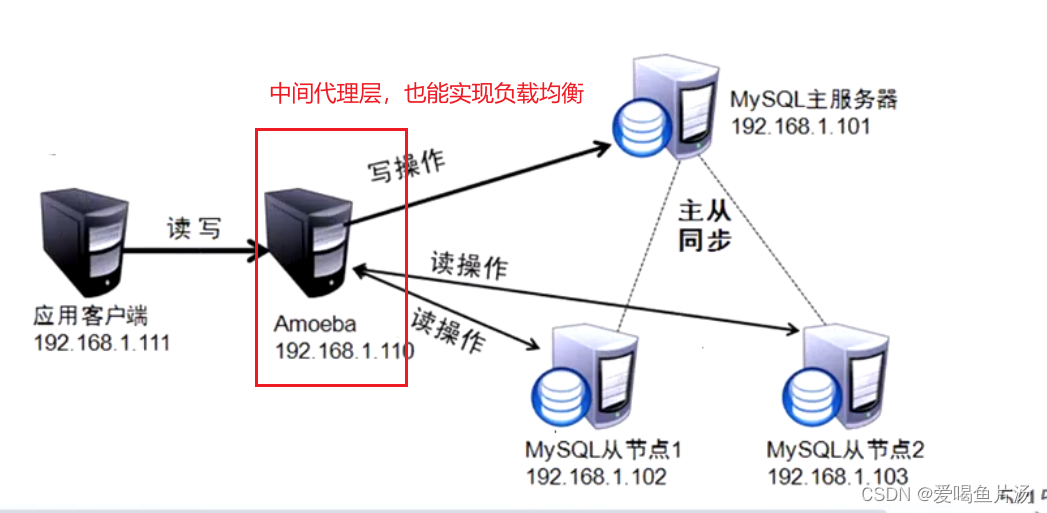
(1)MySQL-Proxy。MySQL-Proxy 为 MySQL 开源项目,通过其自带的 lua 脚本进行SQL 判断。
(2)Atlas。是由奇虎360的Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事物以及存储过程。
(3)Amoeba 。由陈思儒开发,作者曾就职于阿里巴巴。该程序由Java语言进行开发,阿里巴巴将其用于生产环境。但是它不支持事务和存储过程。
(4)Mycat。是一款流行的基于Java语言编写的数据库中间件,是一个实现了MySql协议的服务器,其核心功能是分库分表。配合数据库的主从模式还可以实现读写分离。
由于使用MySQL Proxy 需要写大量的Lua脚本,这些Lua并不是现成的,而是需要自己去写。这对于并不熟悉MySQL Proxy 内置变量和MySQL Protocol 的人来说是非常困难的。
Amoeba是一个非常容易使用、可移植性非常强的软件。因此它在生产环境中被广泛应用于数据库的代理层。
3)Amoeba实现数据库的读写分离
基于上面的主从复制部署案例,这里再添加一台服务器192.168.170.100 ,作为中间代理层,安装amoeba即可。
①安装配置amoeba中间代理层服务器
bash
yum remove java*
java -version
cd /opt/
rm -rf /
rz -E
ls
chmod +x jdk-6u14-linux-x64.bin
./jdk-6u14-linux-x64.bin 




②部署jdk环境
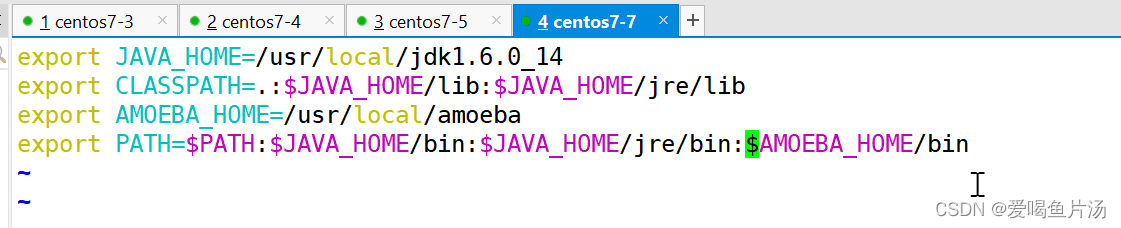


③修改amoeba配置文件
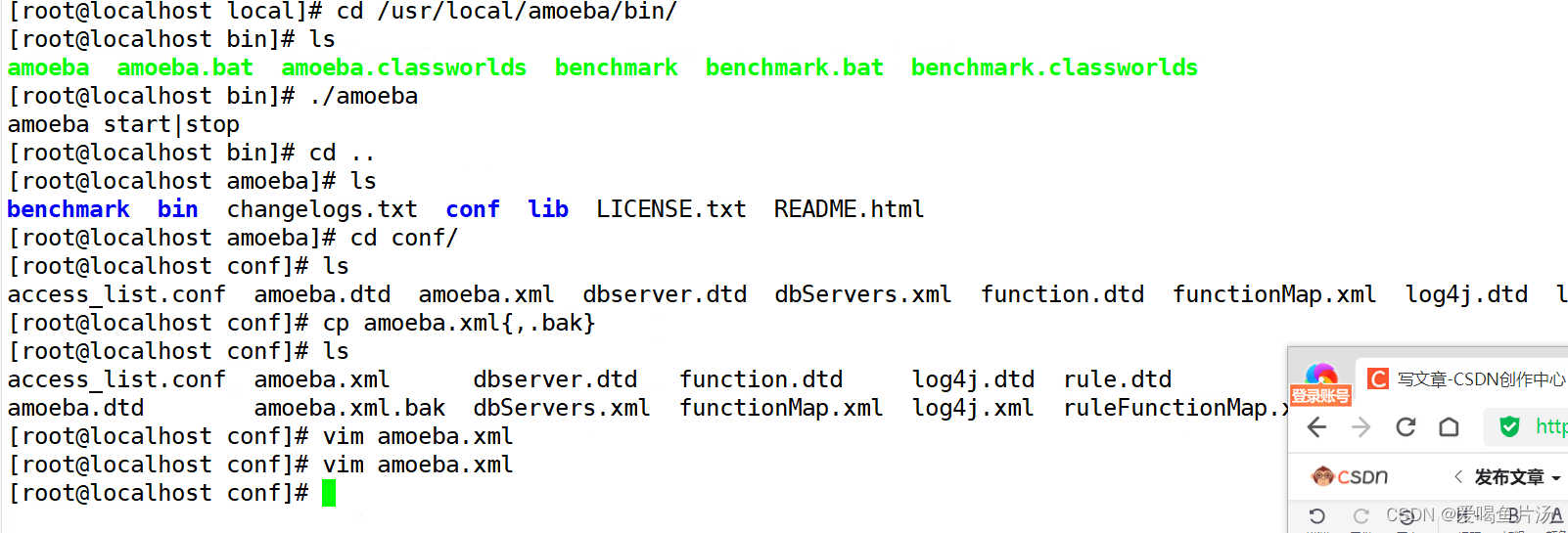
配置连接端口号以及amoeba的用户名
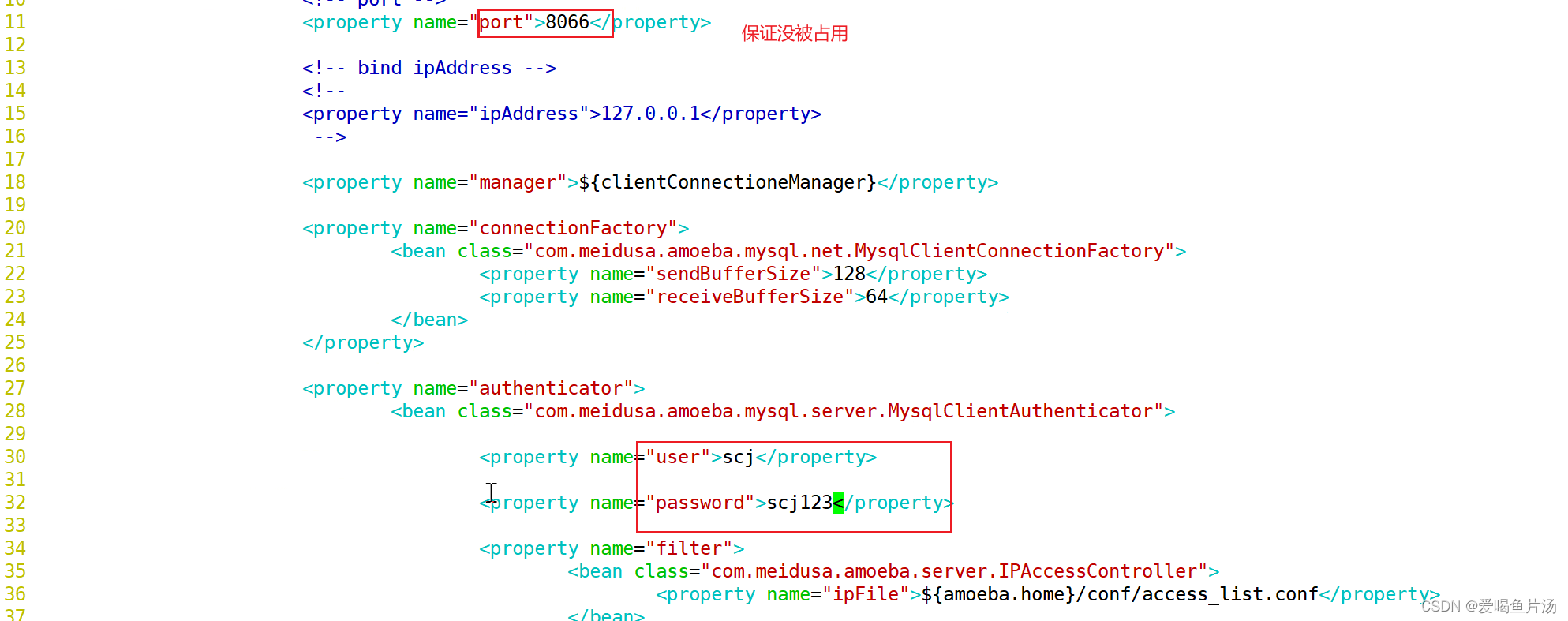

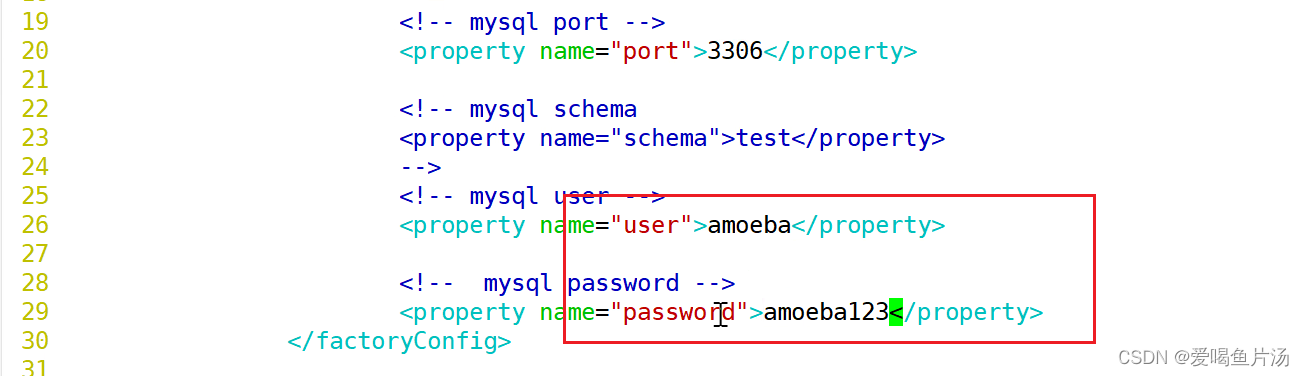

④ 三个库都创建amoeba用户,并进行授权


⑤ 运行amoeba
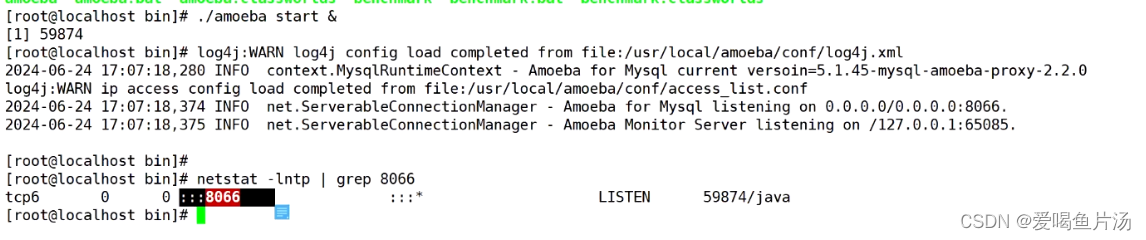
⑥ 测试

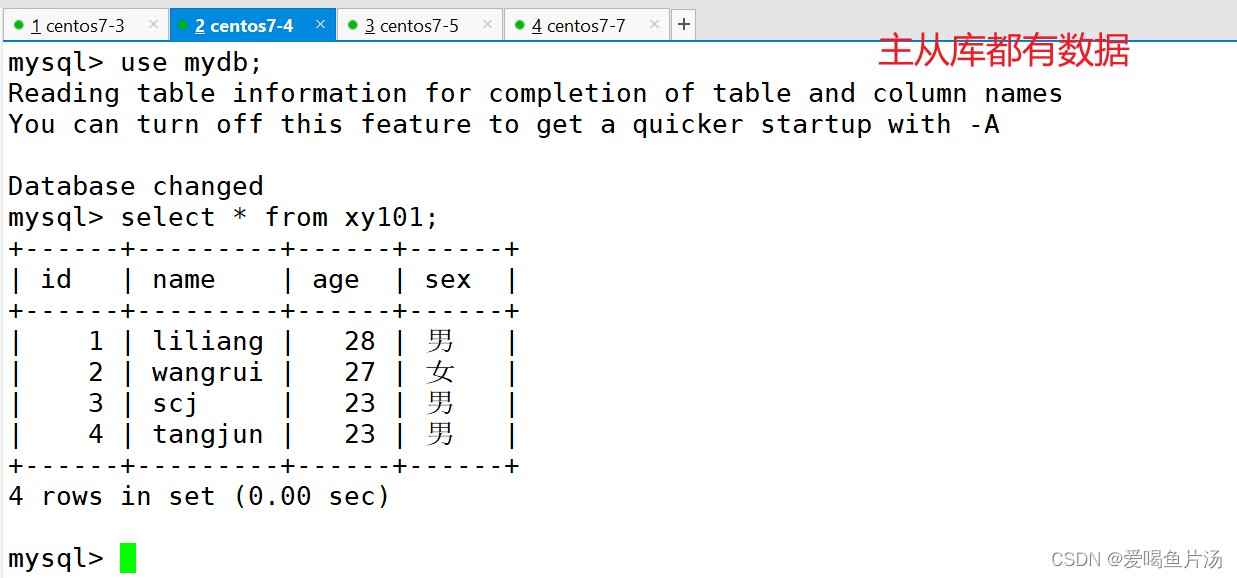
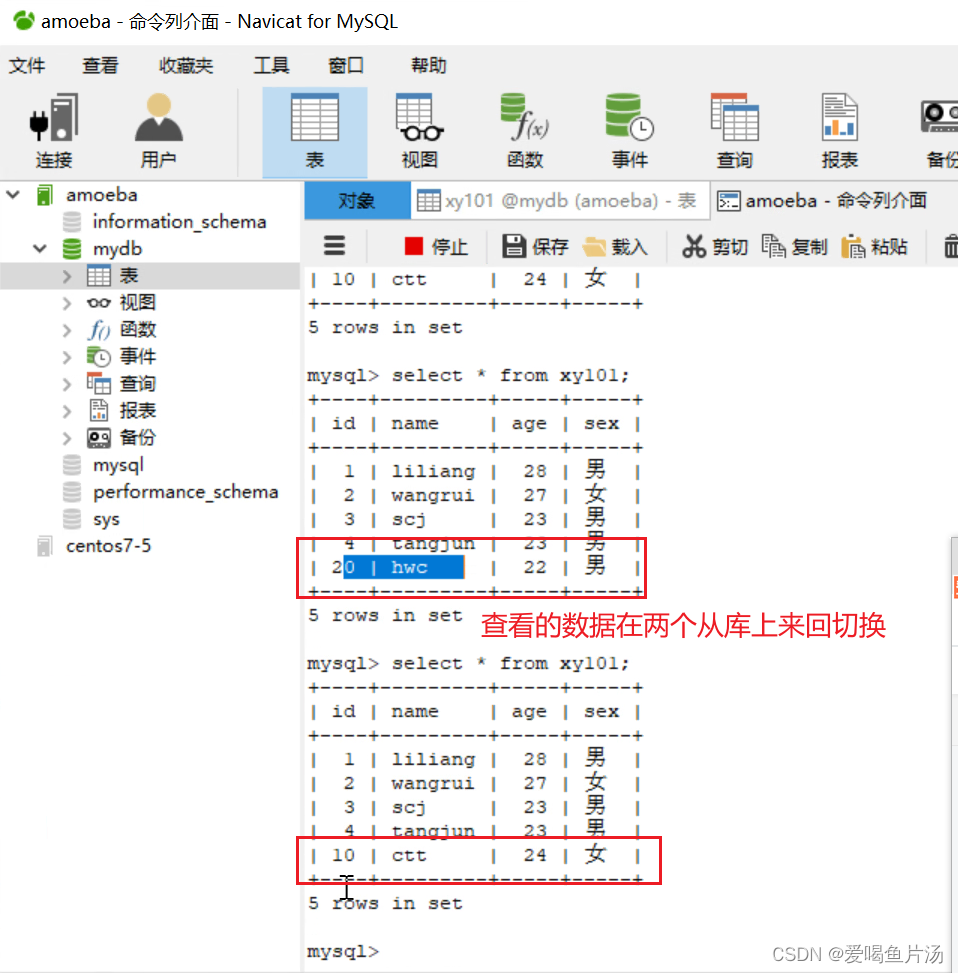
读操作是在从库完成的,写入是在主库写入的。怎么确定是在amoeba写入的数据呢?
关闭从库的slave,在客户端插入数据,主库能够看到插入了数据,但是从库是看不到的。
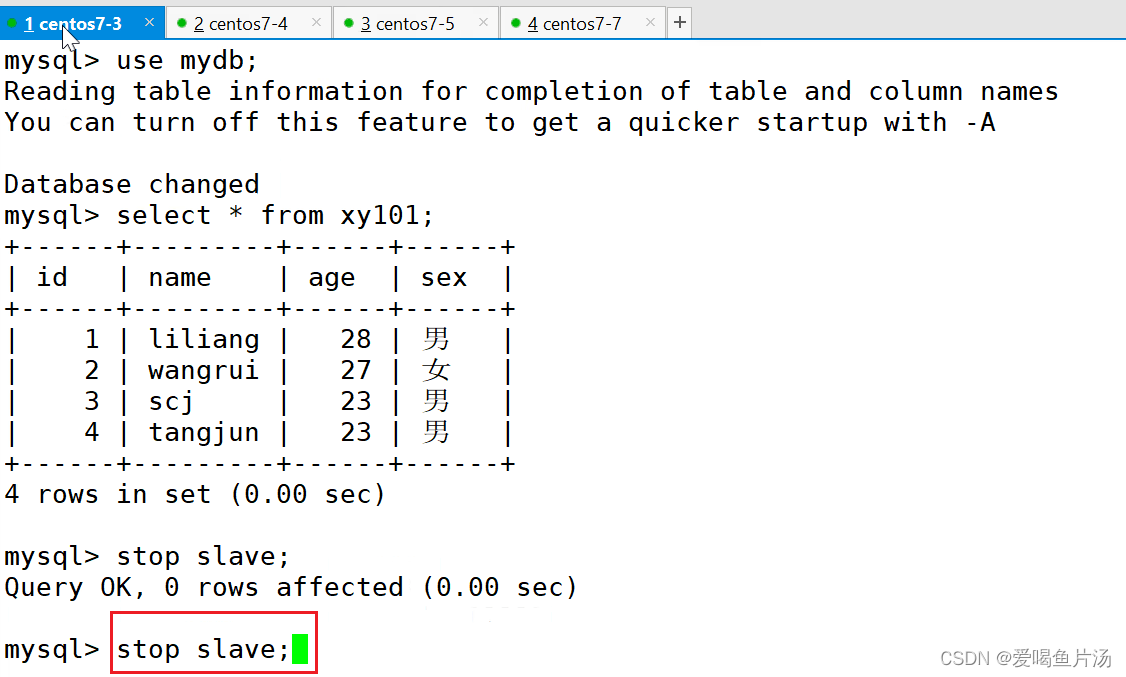
在两个从库插入数据,客户端查看的数据会是从库获取的,非主库;

三、补充mysql的一些配置优化
innodb_buffer_pool_size=2048M #增大让更多操作在Mysql内存中完成,减少磁盘操作;
innodb_log_file_size=50M #此参数确定数据日志文件的大小,以M为单位,更大的设置可以提高性能。
innodb_log_files_in_group=3 #为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3;
read_buffer_size=1M #MySQL 读入缓冲区大小。对表进行顺序扫描的请求将分配到一个读入缓冲区MySQL会为他分配一段内存缓冲区;
innodb_flush_log_at_trx_commit=1和sync_binlog=1 #双1设置,提高主库数据安全性;
innodb_flush_log_at_trx_commit=2和sync_binlog=0 #从库优化,提高性能;
expire_logs_days=7 #设置二进制日志文件过期时间,默认值为0,表示logs不过期;
max_binlog_size=500M #设置二进制日志限制大小,如果超出日志就会发生滚动,默认值是1GB;
max_connect_errors #是一个MySQL中与安全有关的计数器值,他负责阻止过多尝试失败的客户端以防止暴力破解密码的情况,当超过指定次数,MySQL服务器将禁止host的连接请求,直到mysql服务器重启或通过flush hotos命令清空此host的相关信息。(与性能并无太大的关系)
max_allowed_packet=32M #根据配置文件限制server接受的数据包大小。
bash
参数汇总:
[mysqld]
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
server_id = 1
socket = /usr/local/mysql/mysql.sock
log-error = /usr/local/mysql/data/mysqld.err
slow_query_log = 1
slow_query_log_file=/usr/local/mysql/data/slow-query.log
long_query_time = 1
log-queries-not-using-indexes
max_connections = 1024
back_log = 128
wait_timeout = 60
interactive_timeout = 7200
key_buffer_size = 256M
query_cache_size = 256M
query_cache_type = 1
query_cache_limit = 50M
max_connect_errors = 20
sort_buffer_size = 2M
max_allowed_packet = 32M
join_buffer_size = 2M
thread_cache_size = 200
innodb_buffer_pool_size = 2048M
innodb_flush_log_at_trx_commit = 1
innodb_log_buffer_size = 32M
innodb_log_file_size = 128M
innodb_log_files_in_group = 3
log-bin=/usr/local/mysql/data/mysqlbin
binlog_cache_size = 2M
max_binlog_cache_size = 8M
max_binlog_size = 512M
expire_logs_days = 7
read_buffer_size = 1M
read_rnd_buffer_size = 16M
bulk_insert_buffer_size = 64M