一、HTTP协议
1.1 基本概念:
HTTP全称超文本传输协议,是一种无状态的、应用层的协议,它基于请求/响应模型。客户端(通常是Web浏览器)通过发送HTTP请求到服务器来获取或发送信息,服务器则返回HTTP响应作为回应。HTTP协议定义了客户端和服务器之间交换消息的格式和过程,使得数据能够在网络上以统一的方式传输。
1.2 HTTP工作原理
HTTP工作在TCP/IP协议栈的应用层,通常使用80端口进行通信。一个完整的HTTP交互流程包括以下几个步骤:
- 建立TCP 连接:客户端与服务器建立一个TCP连接,这是数据传输的前提;
- 发送HTTP请求:客户端向服务器发送一个HTTP请求,(如GET /index.html)、请求头部和请求体;
- 服务器处理请求:服务器解析器跪求并定位请求资源,如果需要i的话,服务器会执行相应的业务逻辑;
- 返回HTTP相应:服务器将响应数据封装成HTTP响应,包括响应状态行(如200 OK)、响应头部和响应体,然后发送回客户端。
- 关闭 TCP 连接:通信结束后,TCP连接可以被关闭,或者在持续连接(Keep-Alive)的情况下保持打开状态以供后续请求复用。
二、 数据报文结构
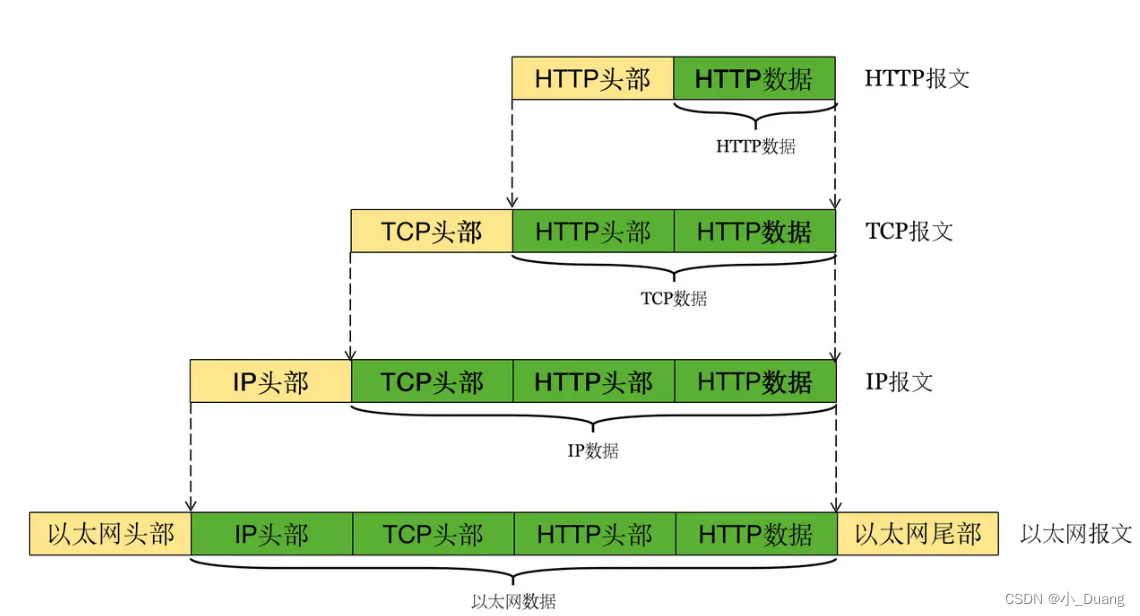
HTTP 是一个文本格式的协议. 可以通过 Chrome 开发者工具或者 Fiddler 抓包, 分析 HTTP 请求/响应的细节.
2.1 HTTP 请求格式
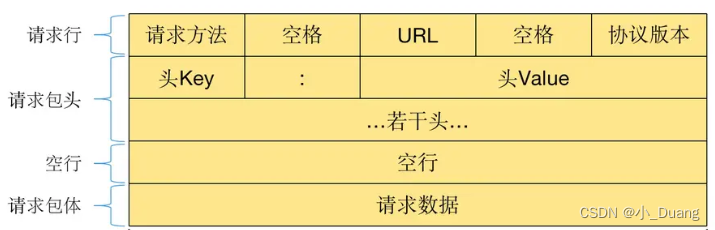
bash
POST https://beacons.gvt2.com/domainreliability/upload HTTP/1.1
Host: beacons.gvt2.com
Connection: keep-alive
Content-Length: 638
Content-Type: application/json; charset=utf-8
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9
{"entries":[{"failure_data":{"custom_error":"net::ERR_CONNECTION_TIMED_OUT"},"network_changed":false,"protocol":"","request_age_ms":136344,"request_elapsed_ms":21374,"sample_rate":1.0,"server_ip":"[2404:6800:4008:c04::54]:443","status":"tcp.connection.timed_out","url":"https://accounts.google.com/","was_proxied":false},{"failure_data":{"custom_error":"net::ERR_CONNECTION_TIMED_OUT"},"network_changed":false,"protocol":"","request_age_ms":136344,"request_elapsed_ms":21374,"sample_rate":1.0,"server_ip":"59.24.3.174:443","status":"tcp.connection.timed_out","url":"https://accounts.google.com/","was_proxied":false}],"reporter":"chrome"}2.2 HTTP 响应格式
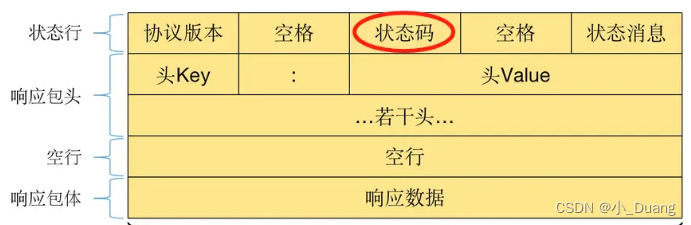
bash
HTTP/1.1 200 OK
Report-To: {"endpoints":[{"priority":1,"url":"https://beacons.gcp.gvt2.com/domainreliability/upload-nel","weight":1},{"priority":1,"url":"https://beacons.gvt2.com/domainreliability/upload-nel","weight":1},{"priority":1,"url":"https://beacons2.gvt2.com/domainreliability/upload-nel","weight":1},{"priority":1,"url":"https://beacons3.gvt2.com/domainreliability/upload-nel","weight":1},{"priority":1,"url":"https://beacons4.gvt2.com/domainreliability/upload-nel","weight":1},{"priority":1,"url":"https://clients2.google.com/domainreliability/upload-nel","weight":1},{"priority":2,"url":"https://beacons5.gvt2.com/domainreliability/upload-nel","weight":1},{"priority":2,"url":"https://beacons5.gvt3.com/domainreliability/upload-nel","weight":1}],"group":"nel","max_age":300}
NEL: {"failure_fraction":1,"include_subdomains":false,"max_age":300,"report_to":"nel","success_fraction":0.25}
Content-Type: application/javascript; charset=utf-8
Date: Wed, 26 Jun 2024 02:45:34 GMT
Server: Domain Reliability Server
Content-Length: 0
X-XSS-Protection: 0
X-Frame-Options: SAMEORIGIN
Alt-Svc: h3=":443"; ma=2592000,h3-29=":443"; ma=2592000为什么 HTTP 报文中要存在 "空行"?
因为 HTTP 协议并没有规定报头部分的键值对有多少个。空行就相当于是 "报头的结束标记",或者是 "报头和正文之间的分隔符"。TTP 在传输层依赖 TCP 协议, TCP 是面向字节流的。 如果没有这个空行, 就会出现 "粘包问题。
HTTP之 URI 和URL
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址, 以下面的这个URL 为例;
http://user:pass@www.example.jp:80/dir/index.htm?boardID=5\&ID=24618\&page=1#name
一个完整的 URL 主要包括一下几个部分
-
协议部分:该URL的协议部分为"http:",这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的"//"为分隔符;
-
域名部分:该URL的域名部分为"user:pass@www.example.jp"。一个URL中,也可以使用IP地址作为域名使用;
-
端口部分:跟在域名后面的是端口,域名和端口之间使用":"作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口;
-
拟目录部分:从域名后的第一个"/"开始到最后一个"/"为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是"/news/";
-
文件名部分:从域名后的最后一个"/"开始到"?"为止,是文件名部分,如果没有"?",则是从域名后的最后一个"/"开始到"#"为止,是文件部分,如果没有"?"和"#",那么从域名后的最后一个"/"开始到结束,都是文件名部分。本例中的文件名是"index.asp"。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名;
-
锚部分:从"#"开始到最后,都是锚部分。本例中的锚部分是"name"。锚部分也不是一个URL必须的部分
-
参数部分:从"?"开始到"#"为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为"boardID=5&ID=24618&page=1"。参数可以允许有多个参数,参数与参数之间用"&"作为分隔符。
URI,全称是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的URI一般由三部组成:
- 访问资源的命名机制
- 存放资源的主机名
- 资源自身的名称,由路径表示,着重强调于资源。
三、HTTP方法
HTTP定义了多种请求方法,常用的有:
- GET: 用于请求指定资源。
- POST: 用于提交数据到指定资源。
- PUT: 用于更新指定资源。
- DELETE: 用于删除指定资源。
- HEAD: 类似于GET,但只返回响应头(获取报文首部)。
- OPTIONS: 用于描述目标资源的通信选项(询问支持的方法)。
- CONNECT: 用于建立网络隧道。
- Link:建立和资源之间的联系.
- TRACE: 用于回显服务器收到的请求(追踪路径)。
3.1 GET方法
GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源。在浏览器中直接输入 URL, 此时浏览器就会发送出一个 GET 请求.另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求。
GET 请求的特点
- 首行的第一部分为 GET
- URL 的 query string 可以为空, 也可以不为空.
- header 部分有若干个键值对结构.
- body 部分为空。
关于 GET 请求的 URL 长度问题:
- HTTP 协议由 RFC 2616 标准定义, 标准原文中明确说明: "Hypertext Transfer Protocol --HTTP/1.1," does not specify any requirement for URL length.没有对 URL 的长度有任何的限制.
- 实际 URL 的长度取决于浏览器的实现和 HTTP 服务器端的实现. 在浏览器端, 不同的浏览器最大长度是不同的, 但是现代浏览器支持的长度一般都很长; 在服务器端, 一般这个长度是可以配置的.
3.2 POST方法
POST 方法也是一种常见的方法. 多用于提交用户输入的数据给服务器(例如登陆页面)。通过 HTML 中的 form 标签可以构造 POST 请求, 或者使用 JavaScript 的 ajax 也可以构造 POST 请求。
POST 请求的特点
- 首行的第一部分为 POST
- URL 的 query string 一般为空 (也可以不为空)
- header 部分有若干个键值对结构.
- body 部分一般不为空. body 内的数据格式通过 header 中的 Content-Type 指定. body 的长度由header 中的 Content-Length 指定
经典面试题: 谈谈 GET 和 POST 的区别
- 语义不同: GET 一般用于获取数据,POST 一般用于提交数据;
- GET 的 body 一般为空,需要传递的数据通过 query string 传递,POST 的 query string 一般为空,需要传递的数据通过 body 传递;
- GET 请求一般是幂等的,POST 请求一般是不幂等的。(如果多次请求得到的结果一样, 就视为请求是幂等的).
- GET可以被缓存,POST不能被缓存.(这一点也是承接幂等性)
四、HTTP 状态码 (重点)
HTTP响应状态码分为五大类:
*** 1xx (信息性响应): 表示接收的请求正在处理。
- 2xx (成功响应): 表示请求正常处理完毕。
- 3xx (重定向消息): 表示需要进行附加操作以完成请求。
- 4xx (客户端错误): 表示客户端请求出错。
- 5xx (服务器错误): 表示服务器处理请求出错。**
总结
以上就是今天要讲的内容,本文介绍了HTTP协议的基础知识,包括其无状态、应用层协议的特性,基于请求/响应的工作模式,以及TCP连接、HTTP请求和响应的流程。HTTP方法如GET、POST、PUT等用于不同操作,状态码则表示请求结果。