常规k8s的监控指标
单独
1、集群维度
- 集群状态
- 集群节点数
- 节点状态(正常、不可达、未知)
- 节点的资源使用率(CPU、内存、IO等)
2、应用维度
-
应用响应时间
-
应用的错误率
-
应用的请求量
3、系统和集群组件维度
- API服务器状态
- 控制器状态
- etcd状态
常用的 Prometheus Operator 指标
常用监控 Kubernetes 性能的 Prometheus Operator 指标 如下:
- Kubernetes 资源相关
- Kubernetes 存储相关
- kubernetes system 相关
- APIServer 相关
- kubelet 相关
- 集群组件
- 应用相关
- 节点相关
- Etcd 相关
- CoreDNS 相关
1、集群维度
K8s集群指标可以按维度分为节点指标和容器pod指标。
-
节点维度指标包括节点CPU使用率,节点内存使用率等
-
pod维度指标包括pod CPU 使用率等
1.1 Node监控
1、内存指标
bash
node_memory_MemTotal_bytes: Node总内存大小
node_memory_MemAvailable_bytes:Node剩余可用内存
node_memory_MemAvailable_bytes :从应用程序的角度看到的可用内存;linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据。就是buffer和cache,对于内核来说 buffer和cache 都属于已经被使用的内存,只是应用程序需要内存时,如果没有足够的free内存可用,内核就会从buffer和cache中回收内存满足应用程序的请求。所以从应用程序角度来说avaliable = free + buffer +cache, 不过这只是一个理想的公式,实际中的数据会有较大偏差
node已用的内存大小计算公式:
node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes
理想情况下节点内存使用率可以 这样计算:
(1-(node_memory_Buffers_bytes+node_memory_Cached_bytes+node_memory_MemFree_bytes)/node_memory_MemTotal_bytes)*100
或者使用以下计算方式:
(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)*100
2、CPU
bash
node_load1:CPU1分钟负载
node_load5:CPU5分钟负载
node_load15:CPU15分钟负载
node_cpu_seconds_total (counter类型指标,用来统计CPU每种模式下所花费的时间,是CPU时间片的一个累积值)
CPU使用率计算公式:
1-avg(irate(node_cpu_seconds_total{mode="idle"}[30m])) by (instance)
bash
如果需要计算node节点CPU使用率:CPU使用率是cpu除空闲(idle)状态之外的其他所有CPU状态的时间总和除以总的CPU时间得到的结果。即:
(1-sum(rate(node_cpu_seconds_total{mode="idle"}[1m]))by(instance)/sum(rate(node_cpu_seconds_total[1m]))by(instance))*100
bash
如果需要采集节点vcpu指标信息:例如4u的一个节点,监控每个u的使用率,可参考公式:
(1-sum(rate(node_cpu_seconds_total{mode="idle"}[1m]))by(instance,cpu)/sum(rate(node_cpu_seconds_total[1m]))by(instance,cpu))*100
3、分区使用
bash
nodenode_filesystem_size_bytes:各个分区总空间
node_filesystem_avail_bytes:各分区剩余空间4、磁盘I/O
bash
node_disk_io_time_seconds_total:磁盘I/O操作耗费时间
每秒磁盘读取速度:
irate(node_disk_writes_completed_total[30m])
每秒磁盘写入速度:
irate(node_disk_written_bytes_total[30m])
每秒磁盘I/O操作耗费时间计算公式:
irate(node_disk_io_time_seconds_total[30m])
每次I/O读取耗时计算公式:
irate(node_disk_read_time_seconds_total[30m]) / irate(node_disk_reads_completed_total[30m])
每次I/O写入耗时计算公式:
irate(node_disk_write_time_seconds_total[30m]) / irate(node_disk_writes_completed_total[30m])
磁盘IO表示磁盘的输入和输出(向磁盘写入数据,从磁盘读取数据)
node_disk_reads_completed_total:读IO
node_disk_writes_completed_total :写IO
sumby(instance)(rate(node_disk_reads_completed_total[5m]))
sumby(instance)(rate(node_disk_writes_completed_total[5m]))

bash
节点磁盘监控,主要说明下磁盘空间使用率相关指标,磁盘使用率通常是指挂载在某个目录的磁盘分区的使用率。一个磁盘分区会由对应的文件系统进行管理,通过该文件系统就能获取到该分区的使用情况。
node_filesystem_avail_bytes 磁盘可用空间
bash
node_filesystem_size_bytes 磁盘总空间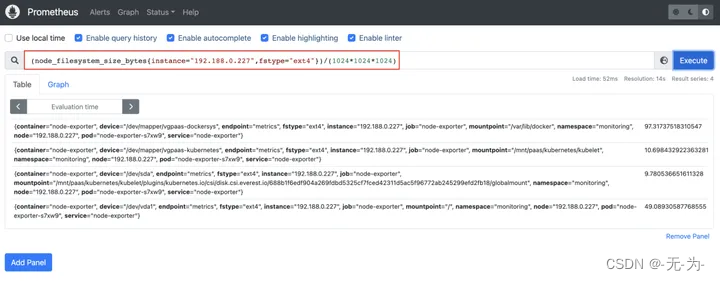
bash
K8s集群中磁盘使用率可以这样计算:
1-(node_filesystem_avail_bytes{fstype="ext4"})/(node_filesystem_size_bytes{fstype="ext4"})
不同的磁盘文件分区,磁盘使用情况不一样,一般关注容器引擎空间和pod容器空间的使用率: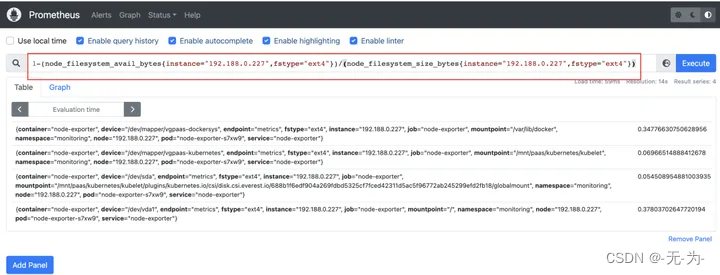
5、网络流量
bash
网络流量下载统计计算公式:
irate(node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[30m])*8
网络流量上传统计计算公式:
irate(node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[30m])*81.2 pod监控
1、POD内存使用率
bash
container_memory_rss : 是Pod实际使用内存数
container_spec_memory_limit_bytes: 是分配给Pod的内存配额
sum(container_memory_rss{container!="POD",container!="alermanager",image!="",pod!=""})by(pod) / sum(container_spec2、POD的CPU使用率
container_cpu_usage_seconds_total 是容器累计使用的CPU时间,用它除以CPU总时间,就可以得到容器的cpu使用率,首先计算容器的CPU占用时间,由于节点上的cpu有多个,所以需要将容器在每个CPU上占用的时间累加起来。pod在3m 内累积使用的CPU时间为(根据pod和namespace 进行分组查):
(sum(rate(container_cpu_usage_seconds_total{namespace="default",pod!=""}[3m]))by(pod))
然后计算CPU的总时间,这里的CPU数量是容器分配到的CPU数量,container_spec_cpu_quota 这个指标就是容器的cpu配额。它的值是容器指定的 cpu核数100000 ,所以pod在1s内cpu总时间为: Pod 的 CPU 核数1s。
(sum(container_spec_cpu_quota{namespace="default",pod!=""})by(pod)/100000
container_spec_cpu_quota是容器的CPU配额。所以只有配置了resource.cpu.limits CPU 的pod 才有该指标。将上面 这两个语句的结果 相除。就得到了容器的CPU利用率:
bash
container_cpu_usage_seconds_total:container累计使用的CPU时间,除以CPU的总时间,就得到了容器的CPU使用率
container_spec_cpu_quota:container的配额,为容器指定的CPU个数*100000
sum(rate(container_cpu_usage_seconds_total{image!="",container!="POD",container!=""}[1m])) by (pod,namespace) / (sum(container_spec_cpu_quota{image!="",container!="POD",container!=""}/100000) by (pod,namespace)) * 1003、POD的文件系统使用量
bash
sum(container_fs_usage_bytes{image!="",container!="POD",container!=""}) by(pod, namespace) / 1024 / 1024 / 1024