内容:写这篇文章是因为最近帮同学改了很多的爬虫代码,感触良多。
我用豆瓣为例,并不是不会用别的,而是这个我个人感觉最经典。然后还会写我遇到的一些问题以及解决方法。
首先,我们得先知道怎样爬取。我用的scrapy框架爬取。
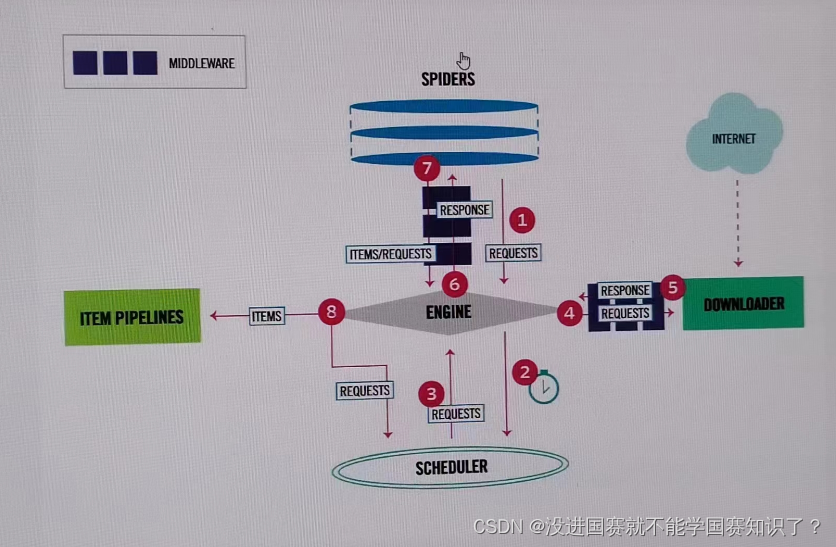
我对此图的理解就是:
从spiders中获得一个请求(REQUEST),通过引擎传递给调度器,之后再返回给引擎,引擎把url封装好后传递给下载器,下载器将资源下载好后返回一个应答(RESPONSE),之后引擎将该应答发送给spiders,让其进行抓取,返回给引擎,然后解析出实体(Items)交给实体管道进行下一步操作。
ok,原理就是这样。下面来开始讲步骤。
python
pip install scrapy首先要在虚拟环境中下载scrapy库,建议在网络好的环境里下载,最好在pycharm中配置镜像源。
python
scrapy之后找到Teiminal 中输入这个库名,先进入这个库中,看看有哪些操作。
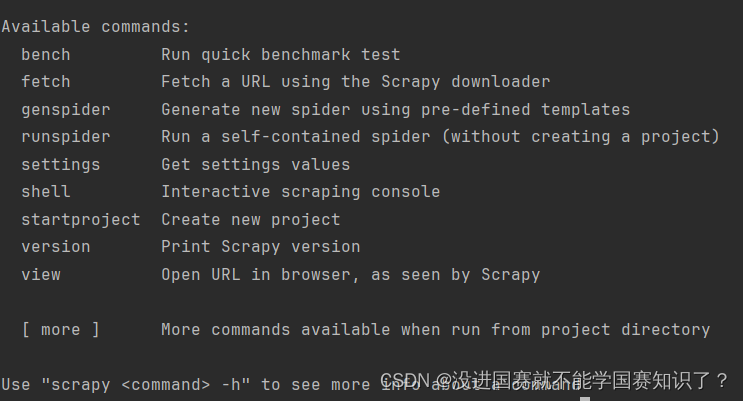
根据指示,开始建项目。
python
scrapy startprojrct pythonProject26这里就建了一个项目。
python
cd projectProject26返回上一级,我们会发现操作列表中有crawl,有了这个我们才可以进行网站爬取。
python
scrapy genspider db https://movie.douban.com/top250
python
scrapy crawl dbok,目前为止,准备工作已经搞定。
接下来我们会看到它帮我们建立了这几个py文件:
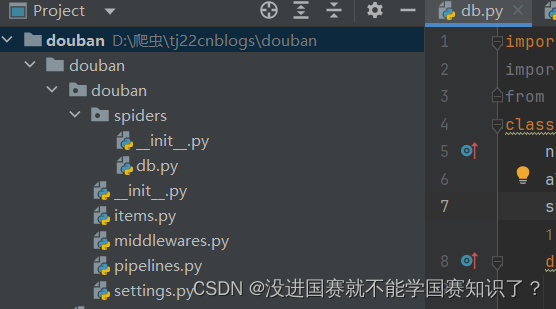
然后我们需要在这个项目下建立一个调试文件,我记作main.py,
python
import os.path
import sys
from scrapy.cmdline import execute
currentFile = os.path.abspath(__file__)
currentPath = os.path.dirname(currentFile)
# print(currentPath)
sys.path.append(currentPath)
execute(["scrapy","crawl","db"])这个是为了提取到这个项目的路径,让它可以贯穿整个项目(我是这样理解的)。
之后就是编写主程序。它自动给我们弄好了要爬取的域名,还有一个parse函数,只要前面的步骤没错的都应该是这样。
接下来我们先编辑settings.py文件,这个主要是取消对优先级的注释并改掉robots协议的遵循规则。


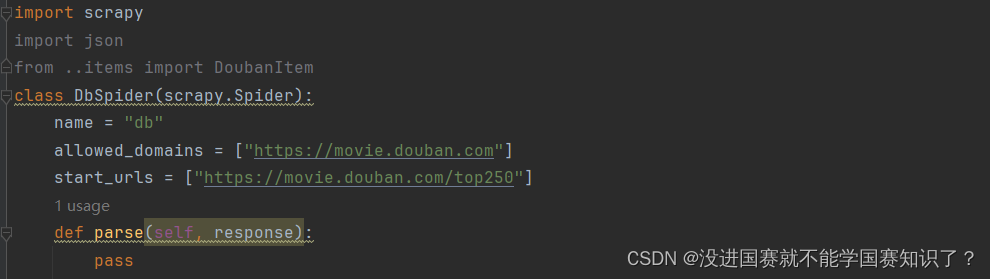
这是它自己创建出来的内容。接下来我继续编写。
先明确目标,我要爬取的是电影名字,导演,评分和简介。所以我采用了先总后分的方式,先提取总资源,再利用循环从中提取出想要的数据。
首先就是总数据:

接下来用循环取出数据:
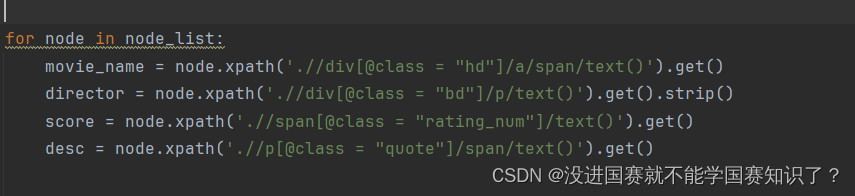
之后我把它放在字典里:

之后为了让它一直爬取,用了一个生成器函数。

这只是一页的东西,现在多爬几页。
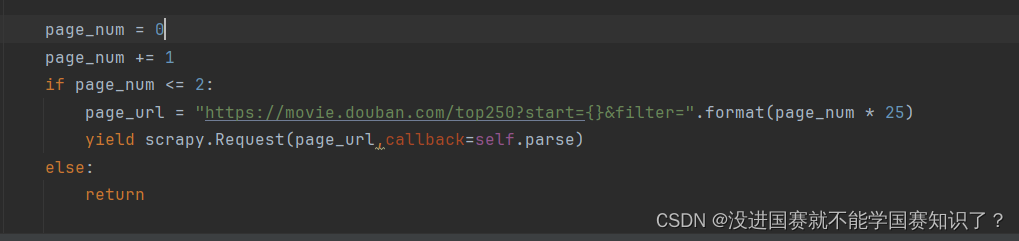
这个需要找每一页网址的规律。
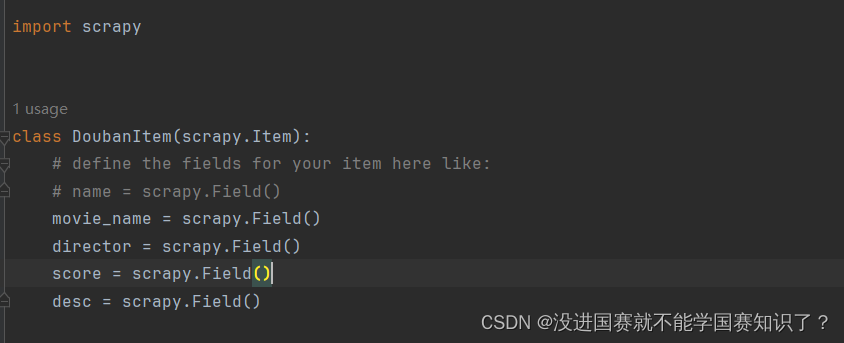
接下来我把它保存在一个data1.txt里面。在pipelines.py:

我相信大家能看懂的,看不懂再说。
接下来就是连接数据库:
我搞的有点复杂,因为我刚开始不知道有另一种方法,所以我就记录我的方法了。
首先,在数据库里创建一个新表。
然后,我们需要在pycharm中下载一个库。
python
pip install mysql-connector-python然后就是连接数据库。
python
import mysql.connector
# 连接到MySQL数据库
conn = mysql.connector.connect(
host="your_host",
user="your_username",
password="your_password",
database="my_database"
)
# 创建一个游标对象
cursor = conn.cursor()
# 打开文本文件
with open('your_data.txt', 'r') as file:
for line in file:
# 去除换行符
title = line.strip()
# 插入数据
sql = "INSERT INTO my_table (title) VALUES (%s)"
cursor.execute(sql, (title,))
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()里面的host,port,user,password,database,这些东西都要自己改。
ok,这就是完整的思路及代码。
我在帮别人改代码的过程中,发现了很多问题。首先就是网站选取。
我一直以为这个不是问题,但是终究是我认为,这不得找点有规律的网站吗?
其次就是数据提取,我用的是xpath ;
还有代码编写错误。
就不展开了,有问题欢迎来问我,这篇就这样了。