目录
[1. 前言](#1. 前言)
"实战演练:利用Percona XtraBackup执行MySQL全量备份操作详解"
1. 前言
本文将继续上篇【MySQL备份】Percona XtraBackup基础篇中对Percona XtraBackup的探索,深化讨论其全量备份技术及详尽的恢复策略。本章节旨在构建一套完备的备份恢复指南,进一步巩固您的数据库安全防线,确保数据资产的万无一失。
在本篇内容中,我们将细致剖析Percona XtraBackup执行全量备份的高效实践,这一核心功能不仅能够实时捕捉数据库状态的完整映像,还依托其先进的日志处理机制,保证备份数据的绝对一致性和可靠性。您将学习到如何运用简洁明了的命令行指令,安全无碍地将数据库快照存置于指定位置,为数据保护筑起第一道坚固壁垒。
紧接着,文章将引领您步入数据恢复的精密艺术殿堂。从备份到恢复的无缝对接,是检验备份方案成色的真正试金石。我们将逐步拆解恢复流程的每一个关键环节:从安全停机、数据迁移与权限配置,到细腻的预处理步骤,直至数据库服务的顺利重启与健康状况的全面核查。每一步都精心设计,确保在面对不可预见的数据危机时,能够迅速恢复业务运营,维持数据连续性和服务稳定性。
通过本篇的深度解析,您不仅能掌握Percona XtraBackup全量备份的精髓,更能领略其在数据恢复领域的独到之处,为您的数据库管理技能树增添一份坚实保障。无论是对初学者的启蒙,还是对资深DBA的技能进阶,本篇章节均是不可或缺的知识宝典。
2.准备工作
2.1.创建备份目录
mkdir -p /data/backup2.2.配置/etc/my.cnf文件
[xtrabackup]
host=localhost
port=3306
user=root
password=123456
socket=/var/lib/mysql/mysql.sock
target_dir=/data/backup2.3.授予root用户BACKUP_ADMIN权限
grant BACKUP_ADMIN on *.* to 'root'@'%'LOCK INSTANCE FOR BACKUP 是MySQL 8.0引入的一种新的备份相关SQL语句,主要用于在进行数据库备份时,以一种更为细粒度和高效的方式控制对数据库实例的访问,以保证备份的一致性。这个命令的工作原理及特点如下:
目的:在执行备份操作时,此命令用于获取一个实例级别的锁,该锁允许在备份过程中继续执行DML(数据操作语言,如INSERT、UPDATE、DELETE)操作,同时防止那些可能导致数据快照不一致的DDL(数据定义语言,如CREATE、ALTER、DROP)操作和某些管理操作。这样可以在不影响数据库服务的情况下进行备份,特别适用于需要最小化服务中断的在线备份场景。
权限需求:执行LOCK INSTANCE FOR BACKUP语句需要用户具备BACKUP_ADMIN权限。这是一个专门为了备份相关的高级操作而设计的权限级别。
兼容性:此特性是在MySQL 8.0及以上版本中引入的,早于8.0的MySQL版本并不支持这一语句,因此在使用旧版本时,可能需要依赖其他机制(如FLUSH TABLES WITH READ LOCK)来确保备份的一致性。
解锁:执行备份后,需要使用UNLOCK INSTANCE语句来释放之前由LOCK INSTANCE FOR BACKUP获得的锁,从而恢复正常操作。
与传统备份命令的对比:相比于传统的备份方法,如使用FLUSH TABLES WITH READ LOCK,LOCK INSTANCE FOR BACKUP提供了更小的性能影响,因为它不会完全阻止写操作,只是限制了可能引起数据不一致的活动,更适合于高可用性和高性能要求的生产环境。
3.全量备份
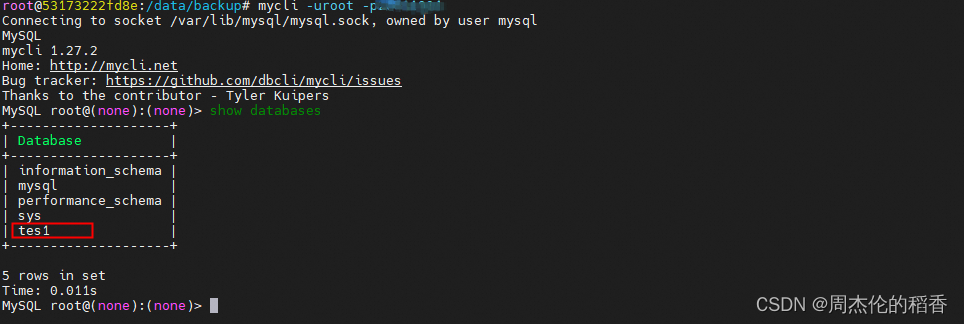
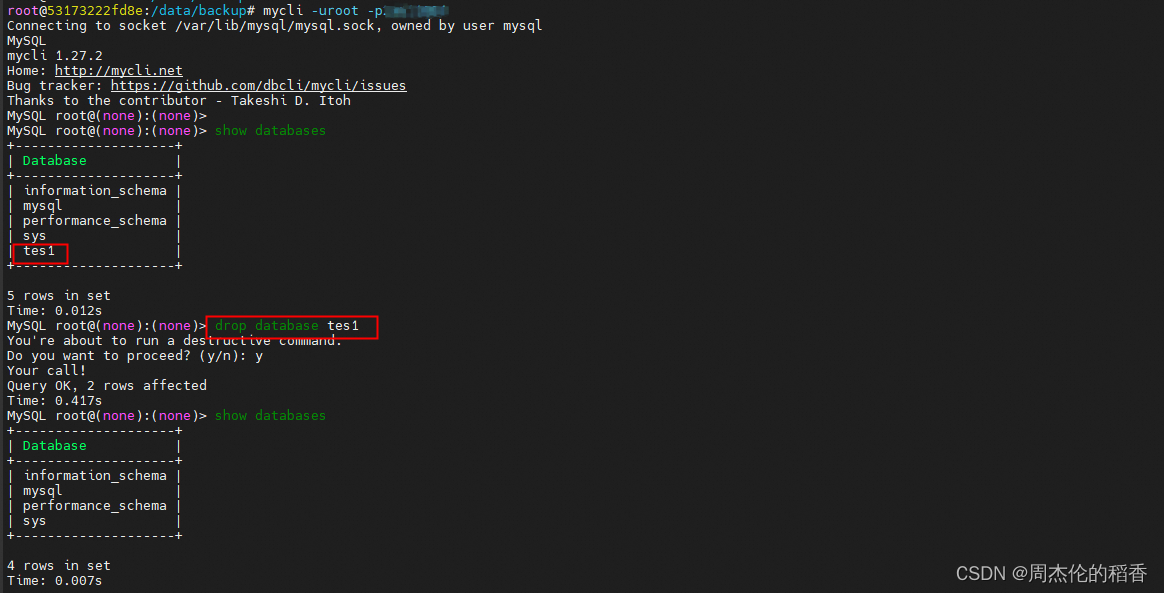
登陆数据库查看现有的的数据,可以看到现在有一个tes1的库
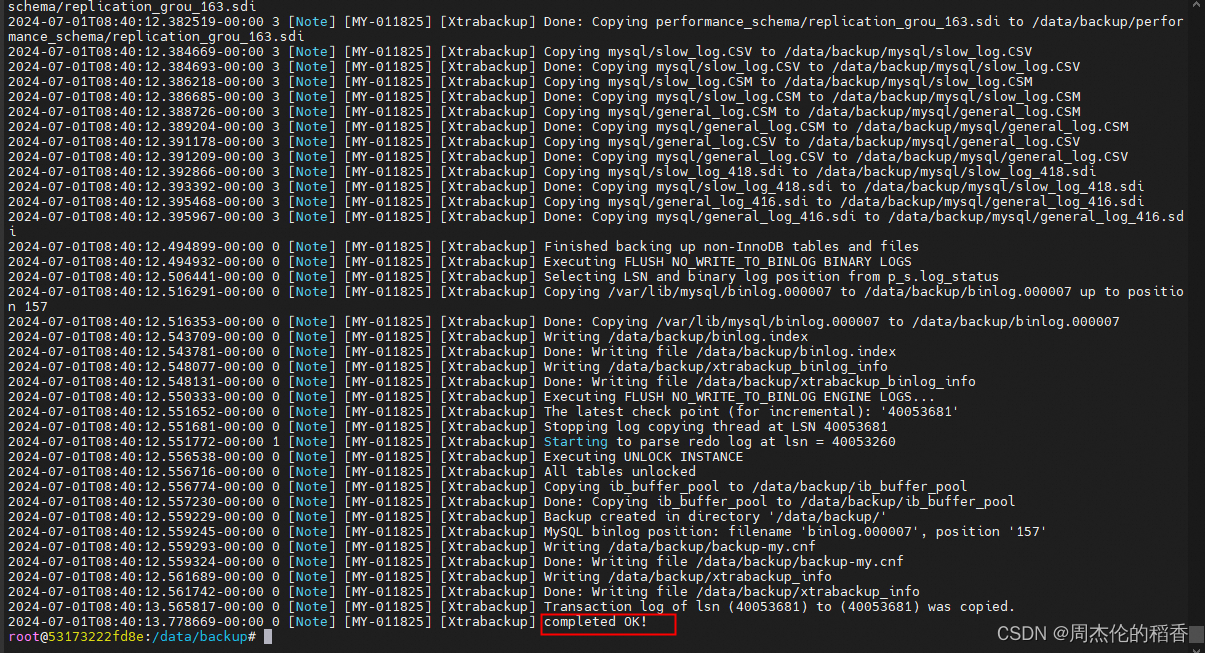
进行全量备份,最后看到 completed OK!代表成功
xtrabackup --backup --target-dir=/data/backup --datadir=/var/lib/mysql --user=root --password=123456 --host=172.17.0.2 --port=3306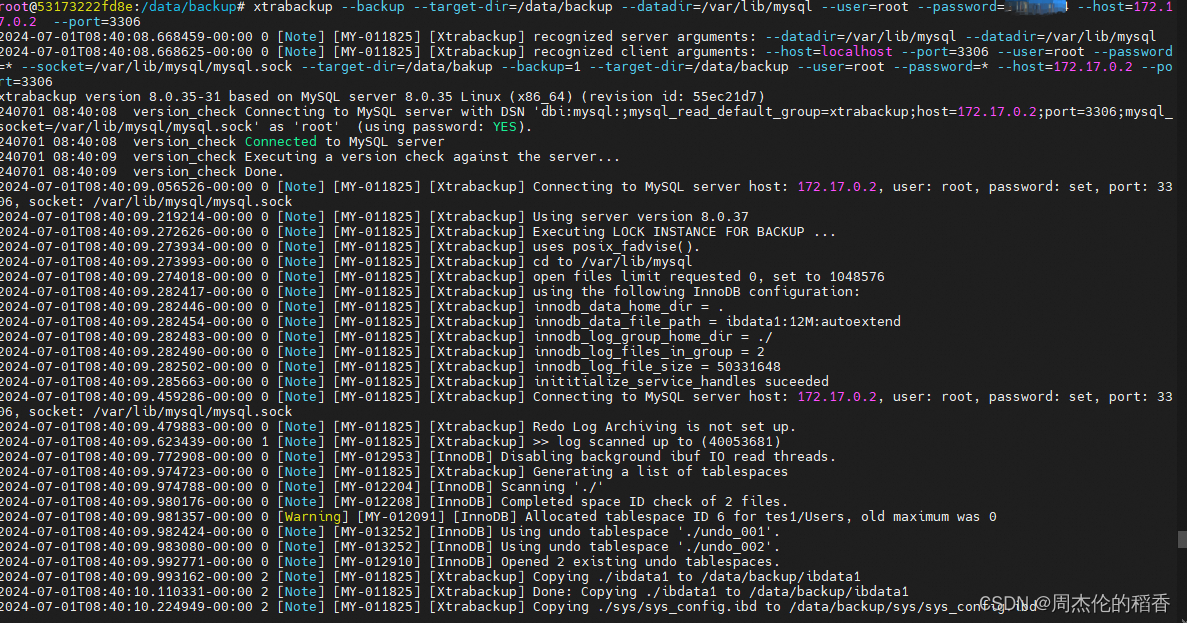
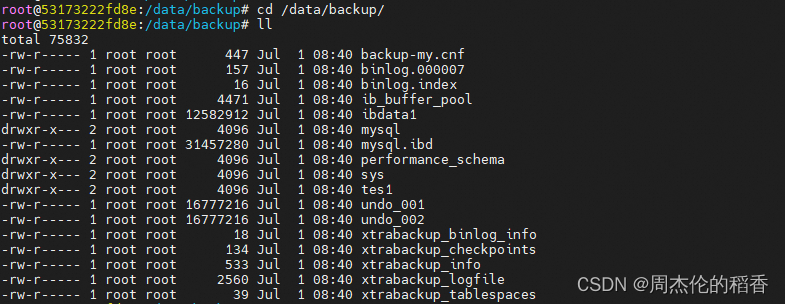
在/data/backup目录下可以看到备份的数据
登陆数据库删除tes1库
4.准备备份
使用Percona XtraBackup进行全量备份后,在某些特定场景下确实可以直接使用备份数据,但这并不意味着不需要准备备份(prepare step)。备份准备是确保数据一致性的一个重要步骤,尤其是在进行数据恢复操作之前。具体是否需要准备备份取决于你的备份目的和后续操作:
-
立即恢复: 如果你计划立即在相同或类似的MySQL环境中恢复这个备份,你应该执行备份准备步骤。这一步骤会应用未完成的事务日志(redo log),确保备份数据的一致性,并将数据文件转换成可以直接用于启动MySQL服务的状态。
xtrabackup --prepare --target-dir=<备份目录> -
备份存档或复制: 如果你只是想创建一个备份副本用于存档或者复制到其他服务器上,理论上可以在不进行准备的情况下直接复制备份目录。但请注意,未经准备的备份在恢复时仍需经过准备步骤才能使用。
-
增量备份基础: 如果计划在这个全量备份的基础上执行增量备份,也不需要立即准备这个全量备份。增量备份会记录自上次备份以来的变化,因此全量备份保持原样即可。
总结来说,尽管在某些情况下全量备份后直接存档或作为增量备份基础可以不立即执行准备步骤,但在准备将数据用于恢复或确保数据一致性时,备份准备是必不可少的。最佳实践中,建议在备份流程中包括准备步骤,以确保备份数据随时可用于快速且可靠地恢复。
5.数据恢复
停止MySQL服务进行恢复数据
systemctl stop mysqld
rsync -avrP /data/backup/ /var/lib/mysql/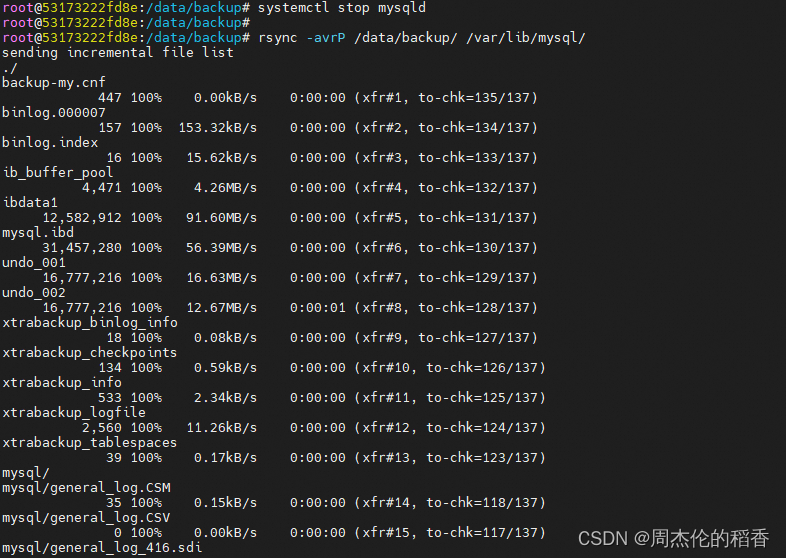
恢复数据时,一定要记得更改数据目录下的文件拥有者以及所属组权限,否则mysql无法启动
chown -R mysql:mysql /var/lib/mysql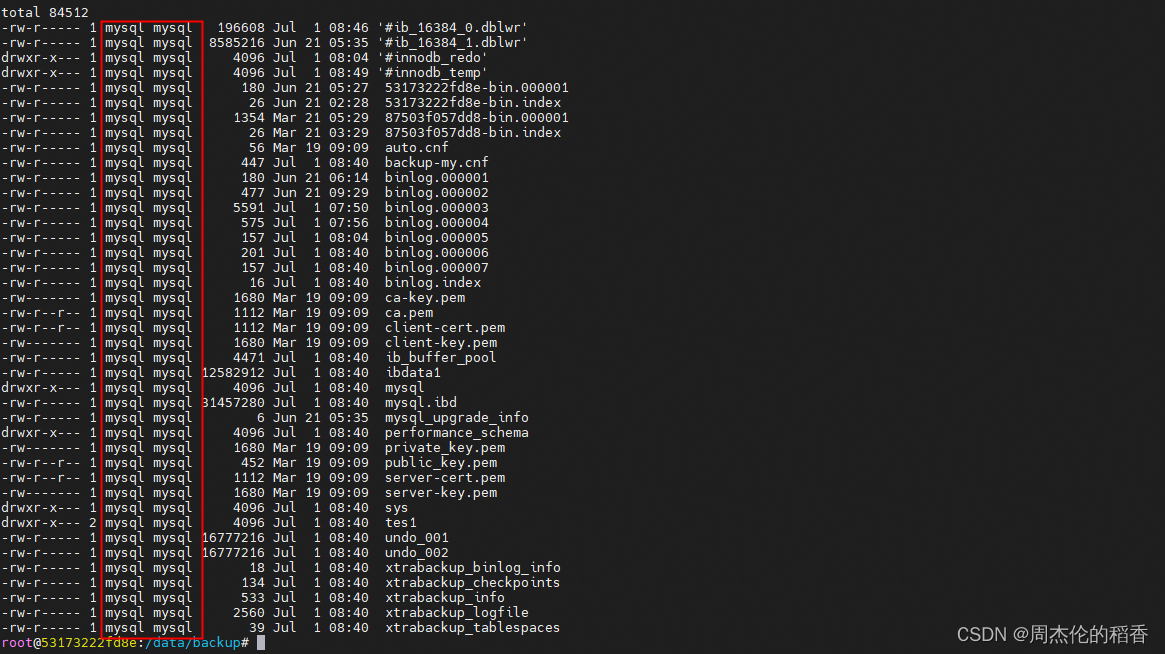
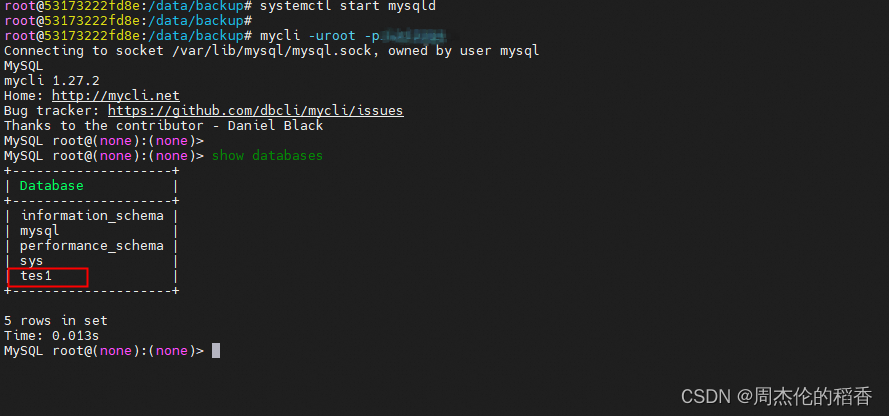
重启数据库查看数据是否恢复,可以看到之前被删除的tes1数据库已经成功恢复
6.总结
需要注意的是,在执行恢复之前需要关闭MySQL服务器。您不能恢复到正在运行的mysqld实例的数据目录(导入部分备份时除外)。由于文件的属性将被保留,在大多数情况下,您需要mysql在启动数据库服务器之前将文件的属主和属组更改为mysql.mysql。