一、MySQL 核心知识点(关系型数据库)
1. 基础概念与架构
(1)核心定义
- 数据库:存储数据的文件集合 + 数据库管理系统(DBMS),类比 "仓库 + 管理员",一个数据库可包含多个表。
- 表:结构化数据存储单元,由行(记录)和列(字段)组成,类比 "仓库货架"。
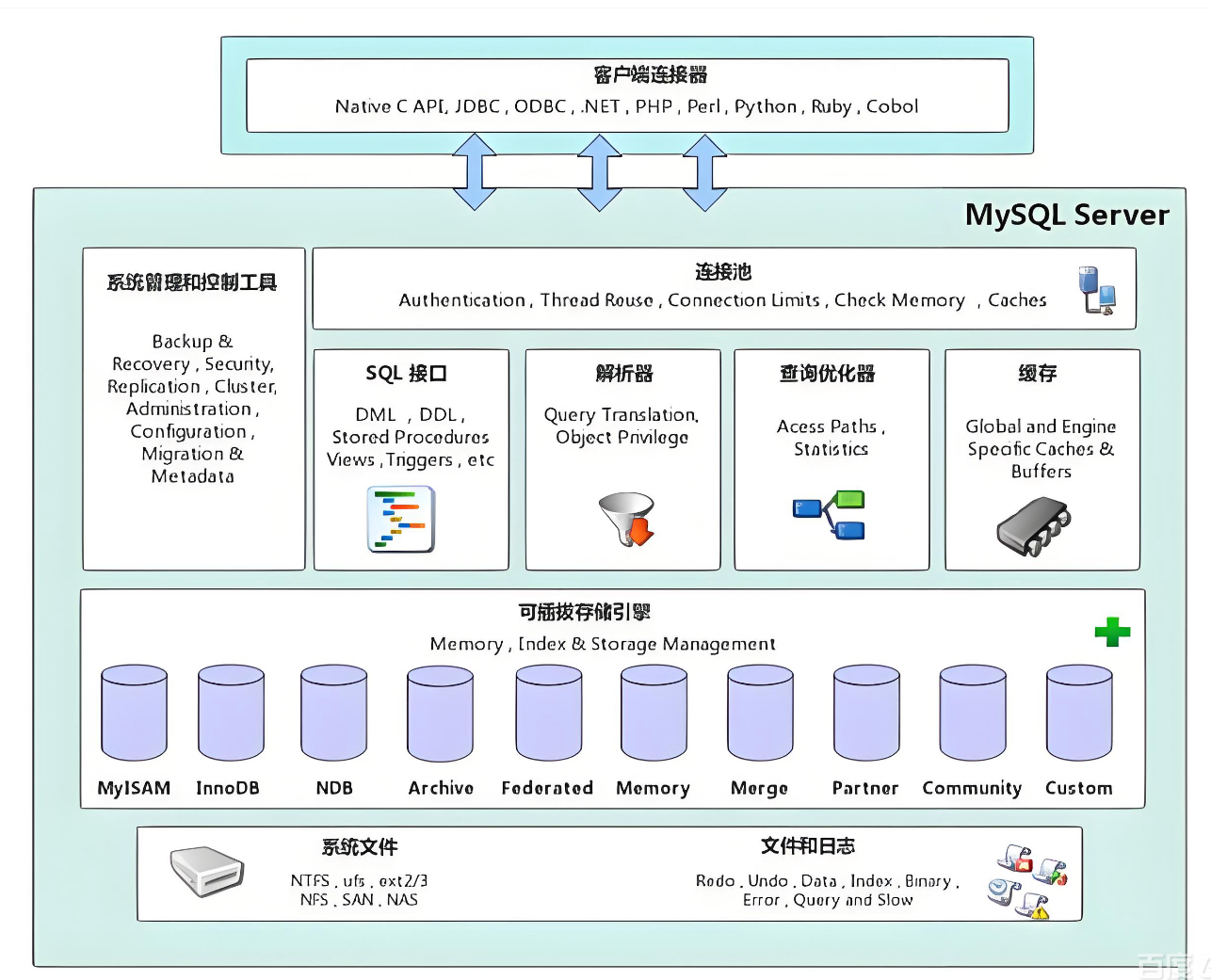
- MySQL 架构 :C/S(客户端 - 服务器)结构:
- 服务器端:
mysqld(守护进程,长期后台运行),默认端口 3306; - 客户端:
mysql(命令行客户端),通过网络连接服务器端。
- 服务器端:
- 版本:主流版本 5.5/5.6/5.7/8.0(无 6.0、7.0 版本**)。**
(2)核心用户与权限
-
默认管理员:
root(与 Linux 系统管理员同名),初始无密码; -
远程登录:需授权远程访问权限,示例指令:
bash-- 创建允许远程访问的用户(密码123456) create user 'root'@'%' identified WITH mysql_native_password by '123456'; -- 授予所有权限 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%';(3)常用系统指令(Linux)
指令 功能说明 service mysql status查看 MySQL 服务状态 service mysql start/stop/restart启动 / 停止 / 重启 MySQL 服务 mysql -uroot -p本地登录 MySQL(回车后输入密码) mysql -h 远程IP -P 3306 -u用户名 -p远程登录 MySQL(需开放 3306 端口) apt install libmysqlclient-dev安装 C/C++ 连接 MySQL 的开发库
2. 数据库与表的基础操作
(1)数据库操作
| SQL 指令 | 功能说明 |
|---|---|
create database c2411db; |
创建名为 c2411db 的数据库 |
show databases; |
查看所有数据库 |
use c2411db; |
切换到 c2411db 数据库(进入该数据库操作) |
select database(); |
查看当前所在数据库(MySQL 专属,非标准 SQL) |
(2)表操作(以 student 表为例)
| SQL 指令 | 功能说明 |
|---|---|
create table student(id int, name varchar(20), age int); |
创建 student 表,包含 id(整型)、name(字符串,最长 20 字符)、age(整型)字段 |
show tables; |
查看当前数据库的所有表 |
insert into student values(2, '小李', 13); |
插入一条记录(需按字段顺序,字符串用单引号) |
select * from student; |
查询 student 表所有记录 |
select name from student; |
仅查询 student 表的 name 字段 |
update student set name='小k' where id=2; |
修改 id=2 的记录,将 name 改为 ' 小 k'(where 指定修改范围,必加!) |
delete from student where id=2; |
删除 id=2 的记录(where 必加,否则删除全表数据) |
(3)关键注意事项
update/delete必须加where子句,否则会修改 / 删除全表数据;- 字符串类型(
varchar)的值必须用单引号括起; - 所有 SQL 指令需以
;或\g结尾。
3. 事务(ACID 特性与隔离级别)
(1)核心定义
事务是一组不可分割的 SQL 操作序列,要么全部执行,要么全部不执行(类比银行转账:A 账户扣钱和 B 账户加钱必须同时成功或同时失败)。
(2)ACID 四大特性
| 特性 | 含义说明 |
|---|---|
| 原子性(Atomicity) | 事务中所有操作要么全成功,要么全回滚(无部分执行) |
| 一致性(Consistency) | 事务执行前后,数据库数据保持逻辑正确(如转账前后 A+B 账户总额不变) |
| 隔离性(Isolation) | 多个并发事务之间相互隔离,互不干扰 |
| 持久性(Durability) | 事务提交后,数据永久保存到数据库(断电、崩溃不丢失) |
(3)事务操作指令
sql
begin; -- 启动事务
-- 执行SQL操作(如转账:扣钱+加钱)
update account set money=money-100 where id=1; -- A账户扣100
update account set money=money+100 where id=2; -- B账户加100
commit; -- 提交事务(所有操作生效)
-- rollback; -- 若出错,执行rollback回滚(恢复到事务前状态)(4)隔离级别(解决并发事务冲突)
| 隔离级别 | 核心特性 | 解决问题 | 存在问题 |
|---|---|---|---|
| 读未提交(Read Uncommitted) | 允许读取其他事务未提交的数据 | 无 | 脏读、不可重复读、幻读 |
| 读已提交(Read Committed) | 仅读取其他事务已提交的数据 | 脏读 | 不可重复读、幻读 |
| 可重复读(Repeatable Read) | MySQL InnoDB 默认级别,基于 MVCC 实现,事务内多次读同一数据结果一致 | 脏读、不可重复读 | 无(InnoDB 额外解决幻读) |
| 串行化(Serializable) | 事务按顺序执行,无并发 | 所有问题 | 性能极低,并发差 |
(5)并发事务常见问题
| 问题类型 | 通俗解释 |
|---|---|
| 脏读(Dirty Read) | 读取到其他事务未提交的修改(数据可能被回滚,为无效数据) |
| 不可重复读 | 同一事务内多次读同一数据,结果不一致(被其他事务提交修改) |
| 幻读(Phantom Read) | 同一事务内多次执行同一查询,结果集行数不一致(被其他事务提交插入 / 删除) |
4. 视图与索引
(1)视图(View)
(2)完整代码
- 核心定义:基于 SQL 查询结果的虚拟表,仅存储查询语句定义,不存储数据(数据仍在基表),每次访问时实时计算结果。
- 核心特性 :
- 虚拟性:不存储数据,基表数据变化时视图结果同步变化;
- 封装性:将复杂查询(多表关联、聚合)封装为视图,简化使用;
- 定制化:可隐藏敏感字段,仅暴露需要的数据。
sql
-- 创建视图(查询age>18的学生)
create view adult_student as select * from student where age>18;
-- 查询视图(实时执行上述查询)
select * from adult_student;(2)索引(Index)
-
核心定义:对表中一列 / 多列数据构建的有序数据结构,类比书籍目录,加快查询速度(避免全表扫描)。
-
底层结构:主流数据库(MySQL InnoDB)默认使用 B + 树(层级浅、叶子节点有序、支持范围查询)。
-
核心特性(双刃剑) :
- 优点:提升查询速度,减少 IO/CPU 消耗;
- 缺点:占用磁盘空间,降低写操作(插入 / 更新 / 删除)效率(需同步维护索引有序性)。
-
使用示例 :
sql-- 为student表的id字段创建索引 create index idx_student_id on student(id); -- 查看索引 show index from student;5. C 语言连接 MySQL 示例
(1)核心步骤
-
包含头文件:
#include <mysql/mysql.h>; -
初始化 MySQL 连接句柄;
-
连接 MySQL 服务器;
-
执行 SQL 指令;
-
处理结果;
-
关闭连接。
(2)完整代码
cpp
#include <stdio.h>
#include <mysql/mysql.h>
#include <stdlib.h>
// MySQL配置信息
#define HOST "localhost"
#define USER "root"
#define PASSWORD "123456"
#define DATABASE "c2411db"
#define PORT 3306
int main() {
// 1. 初始化MySQL连接句柄
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
printf("mysql_init 失败:%s\n", mysql_error(conn));
return 1;
}
// 2. 连接MySQL服务器
if (!mysql_real_connect(conn, HOST, USER, PASSWORD, DATABASE, PORT, NULL, 0)) {
printf("连接失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
printf("MySQL连接成功!\n");
// 3. 执行SQL指令(查询student表)
const char *sql = "select * from student;";
if (mysql_query(conn, sql) != 0) {
printf("查询失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
// 4. 处理查询结果
MYSQL_RES *res = mysql_store_result(conn); // 存储查询结果
if (res == NULL) {
printf("获取结果失败:%s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
// 获取字段数
int field_num = mysql_num_fields(res);
// 遍历结果行
MYSQL_ROW row;
while ((row = mysql_fetch_row(res)) != NULL) {
for (int i = 0; i < field_num; i++) {
printf("%s\t", row[i] ? row[i] : "NULL");
}
printf("\n");
}
// 5. 释放资源
mysql_free_result(res);
mysql_close(conn);
return 0;
}(3)编译运行
bash
gcc mysql_c_demo.c -o mysql_demo -lmysqlclient
./mysql_demo二、Redis 核心知识点(非关系型数据库)
1. 基础概念与架构
(1)核心定义
- Redis 是基于内存的非关系型数据库(NoSQL),支持持久化(内存数据存盘),适用于缓存、消息队列、排行榜等场景。
- 架构:C/S 结构,默认端口 6379,单线程模型(避免线程切换开销)。
- 默认数据库:16 个(下标 0-15),可通过
select 下标切换。
(2)常用系统指令(Linux)
| 指令 | 功能说明 |
|---|---|
redis-server |
启动 Redis 服务器 |
redis-cli |
启动 Redis 客户端(本地连接) |
redis-cli -h 远程IP -p 6379 |
远程连接 Redis 服务器 |
ctrl+L |
客户端清屏 |
(3)基础客户端指令
| 指令 | 功能说明 |
|---|---|
select 1 |
切换到下标为 1 的数据库 |
keys * |
查看当前数据库所有 key |
dbsize |
查看当前数据库 key 的数量 |
exists key |
判断 key 是否存在(返回 1 存在,0 不存在) |
del key |
删除指定 key |
expire key 10 |
设置 key 的过期时间(10 秒后失效) |
ttl key |
查看 key 剩余存活时间(-1 永久有效,-2 已过期) |
flushdb |
清空当前数据库所有 key |
flushall |
清空所有数据库所有 key(慎用!) |
type key |
查看 key 对应的值类型 |
2. 五大基本数据类型及操作总览表
| 数据类型 | 核心定义 | 典型用途 | 底层结构(Redis 3.0+) | 核心特性 |
|---|---|---|---|---|
| 字符串(String) | 存储单个值(文本 / 数字 / 二进制),键值对一对一 | 缓存简单数据、计数器、分布式锁、存储验证码 / 令牌 | 简单动态字符串(SDS) | 可增减数值、支持追加、二进制安全 |
| 列表(List) | 存储有序、可重复的元素集合,双向操作 | 消息队列(FIFO)、栈(LIFO)、最新消息列表、分页查询 | 双向链表(quicklist) | 有序可重复、两端插入 / 删除高效、中间操作低效 |
| 集合(Set) | 存储无序、不可重复的元素集合 | 去重、好友共同关注(交集)、抽奖、标签管理 | 哈希表(hashtable) | 无序唯一、支持集合运算(交 / 并 / 差) |
| 有序集合(ZSet) | 存储无序、不可重复元素,每个元素绑定分数(score),按分数排序 | 排行榜(游戏 / 销量)、延时队列、带权重的任务调度、薪资等级排序 | 哈希表(hashtable)+ 跳表(skiplist) | 唯一有序、按分数排序、集合运算支持 |
| 哈希(Hash) | 存储键值对(field-value)的集合,类比 "对象" | 存储用户信息 / 商品详情、缓存结构化数据、字段级更新 | 哈希表(hashtable) | 结构化存储、字段级操作、节省键空间 |
分类型详细指令表(核心常用指令,按需查阅)
1. 字符串(String)
| 指令分类 | 核心指令 | 功能说明 |
|---|---|---|
| 基础增删改查 | set key value |
设置键值对(覆盖已存在的 key) |
setnx key value |
仅当 key 不存在时设置(分布式锁核心) | |
get key |
获取 key 对应的值(不存在返回 nil) | |
del key |
删除指定 key | |
| 数值操作 | incr key |
对整数值 + 1(key 不存在则先设为 0 再加 1) |
decr key |
对整数值 - 1 | |
incrby key n |
对整数值 + n(n 为整数) | |
incrbyfloat key n |
对值 + n(n 为浮点数) | |
| 字符串操作 | append key value |
向 key 的值末尾追加字符串(不存在则等价于 set) |
strlen key |
获取 key 的值的字符长度 | |
getrange key start end |
获取子字符串(start/end 为下标,-1 表示最后一个字符) | |
| 批量操作 | mset key1 val1 key2 val2 |
批量设置多个键值对 |
mget key1 key2 |
批量获取多个 key 的值 | |
| 过期原子操作 | setex key seconds value |
设置键值对,并指定过期时间(秒,原子操作,等价于 set+expire) |
2. 列表(List)
| 指令分类 | 核心指令 | 功能说明 |
|---|---|---|
| 两端插入 | lpush key val1 val2 |
从列表左侧插入一个 / 多个元素(返回插入后列表长度) |
rpush key val1 val2 |
从列表右侧插入一个 / 多个元素 | |
| 两端删除 | lpop key |
从列表左侧删除并返回一个元素(列表为空返回 nil) |
rpop key |
从列表右侧删除并返回一个元素 | |
| 查看元素 | lrange key start end |
查看列表中 start 到 end 的元素(0=- 第一个,-1 = 最后一个,查全表用lrange key 0 -1) |
lindex key index |
获取列表指定下标的元素(下标越界返回 nil) | |
| 长度 / 裁剪 | llen key |
获取列表的元素个数 |
ltrim key start end |
裁剪列表,仅保留下标 start 到 end 的元素(原子操作) | |
| 阻塞操作 | blpop key timeout |
阻塞式左侧弹出(列表为空则阻塞 timeout 秒,超时返回 nil) |
brpop key timeout |
阻塞式右侧弹出(消息队列核心指令) |
3. 集合(Set)
| 指令分类 | 核心指令 | 功能说明 |
|---|---|---|
| 基础增删查 | sadd key val1 val2 |
向集合添加一个 / 多个元素(自动去重,返回新增元素个数) |
srem key val1 val2 |
从集合删除一个 / 多个元素(返回成功删除个数) | |
smembers key |
查看集合中所有元素(无序返回) | |
sismember key val |
判断 val 是否在集合中(返回 1 存在,0 不存在) | |
| 集合属性 | scard key |
获取集合的元素个数 |
spop key [n] |
随机删除并返回 1 个 /n 个元素(抽奖核心指令) | |
| 集合运算 | sinter key1 key2 |
计算 key1 和 key2 的交集(共同拥有的元素) |
sunion key1 key2 |
计算 key1 和 key2 的并集(所有不重复元素) | |
sdiff key1 key2 |
计算 key1 相对于 key2 的差集(仅 key1 有,key2 无的元素) | |
| 元素移动 | smove key1 key2 val |
将 key1 中的 val 移动到 key2(原子操作,返回 1 成功) |
4. 有序集合(ZSet)
| 指令分类 | 核心指令 | 功能说明 |
|---|---|---|
| 基础增删查 | zadd key score1 val1 score2 val2 |
向有序集合添加元素(指定分数,已存在则更新分数,返回新增元素个数) |
zrem key val1 val2 |
从有序集合删除一个 / 多个元素(返回成功删除个数) | |
zscore key val |
获取 val 对应的分数(不存在返回 nil) | |
| 排序查询 | zrange key start end [withscores] |
按分数升序查询元素(withscores 可选,返回元素 + 分数) |
zrevrange key start end [withscores] |
按分数降序查询元素(排行榜核心指令) | |
| 排名 / 计数 | zrank key val |
获取 val 的升序排名(从 0 开始,不存在返回 nil) |
zrevrank key val |
获取 val 的降序排名(排行榜核心指令) | |
zcount key min max |
统计分数在 min 和 max 之间的元素个数 | |
| 分数操作 | zincrby key increment val |
给 val 的分数增加 increment(可负数,返回更新后分数) |
| 范围删除 | zremrangebyscore key min max |
按分数范围删除元素(返回成功删除个数) |
5. 哈希(Hash)
| 指令分类 | 核心指令 | 功能说明 |
|---|---|---|
| 基础增删改查 | hset key field val |
给哈希表设置字段 - 值对(返回新增字段个数,已存在则更新值) |
hsetnx key field val |
仅当 field 不存在时设置(返回 1 成功,0 失败) | |
hget key field |
获取哈希表中 field 对应的值(不存在返回 nil) | |
hdel key field1 field2 |
从哈希表删除一个 / 多个字段(返回成功删除个数) | |
| 批量操作 | hmset key field1 val1 field2 val2 |
批量给哈希表设置字段 - 值对(返回 OK 成功) |
hmget key field1 field2 |
批量获取哈希表中多个字段的值(返回值列表,不存在的字段对应 nil) | |
| 查看哈希属性 | hgetall key |
获取哈希表中所有字段和值(按 "字段 - 值" 交替返回) |
hkeys key |
获取哈希表中所有字段名 | |
hvals key |
获取哈希表中所有字段值 | |
hlen key |
获取哈希表的字段个数 | |
| 数值操作 | hincrby key field n |
给哈希表中 field 的整数值 + n(n 为整数,不存在则先设为 0 再加 n) |
3. 高级功能
(1)GEO(地理位置)
- 核心用途:存储地理位置信息(经纬度),支持计算距离、查找附近的地点(附近的人、周边商户)。| 指令 | 功能说明 ||-----------------------------------------------------------------------|--------------------------------------------------------------------------||
geoadd shop:location 116.403963 39.915112 shop1 116.414501 39.914667 shop2| 存储 shop1、shop2 的经纬度 ||geopos shop:location shop1| 获取 shop1 的经纬度 ||geodist shop:location shop1 shop2 km| 计算 shop1 和 shop2 的距离(单位 km) ||georadius shop:location 116.408 39.914 2 km withdist| 以指定经纬度为中心,查找 2km 内的店铺(返回距离) |
(2)事务
- Redis 事务是批量执行命令的机制,基于 "事务队列" 实现,不支持回滚(语法错误则全不执行,运行错误则部分执行)。| 指令 | 功能说明 ||-------------------------------|--------------------------------------------------------------------------||
multi| 开启事务(后续命令入队,不立即执行) ||set num 100| 命令入队(返回 QUEUED) ||decr num| 命令入队(返回 QUEUED) ||exec| 提交事务(执行队列中所有命令) ||discard| 取消事务(清空队列) ||watch num| 监控 num 键(乐观锁,若其他客户端修改 num,事务取消) |
(3)持久化(RDB vs AOF)
| 持久化方式 | 核心原理 | 优点 | 缺点 |
|---|---|---|---|
| RDB | 定期生成内存数据快照(二进制文件),默认开启 | 效率高,恢复速度快 | 数据完整性差,可能丢失快照后的部分数据 |
| AOF | 记录所有写命令(类似日志),恢复时重新执行所有命令,需手动开启 | 数据完整性高,支持实时持久化 | 日志文件大,恢复速度慢 |
4. 缓存常见问题
(1)缓存穿透
- 定义:请求的数据在缓存和数据库中均不存在,导致请求直接穿透到数据库,引发数据库压力骤增。
- 解决方案:缓存空值(不存在的 key 缓存为 null,设置短期过期)、过滤无效请求(校验参数合法性)。
(2)缓存雪崩
- 定义:大量缓存 key 集中过期,或缓存服务宕机,导致所有请求穿透到数据库。
- 解决方案:key 过期时间加随机值(避免集中过期)、部署缓存集群(提高可用性)、数据库限流降级。
三、MySQL 与 Redis 核心区别
| 对比维度 | MySQL(关系型数据库) | Redis(非关系型数据库) |
|---|---|---|
| 数据结构 | 结构化(表、行、列),支持 SQL 查询 | 非结构化(字符串、列表、集合等),支持特定指令操作 |
| 存储介质 | 磁盘(内存缓存查询结果) | 内存(支持持久化到磁盘) |
| 核心用途 | 存储结构化数据(如用户信息、订单数据),支持复杂查询(多表关联、事务) | 缓存、消息队列、排行榜、地理位置查询,追求高并发、低延迟 |
| 并发性能 | 中等(支持多线程,但磁盘 IO 慢) | 高(单线程 + 内存操作,无 IO 瓶颈) |
| 事务支持 | 支持 ACID 特性,隔离级别可配置 | 支持批量命令执行,不支持回滚 |
四、补充:
不需要死记硬背这些指令这些操作指令多敲就记得住,工作的时候需要什么操作直接去查再去用就行了,不需要刻意去记,但是基本的定义如事务是什么?隔离级别有哪些就需要去牢牢的记住。