一、爬虫
网络资源的下载工具,工作与万维网环境,持续获取网页网站中的网络信息。可持续的数据采集机器人
1、搜索引擎技术使用爬虫
2、数据分析、数据挖掘领域,需要爬虫进行数据准备
3、数据批处理、采集,大量获取某些网站中的网络资源
爬虫进行数据准备截断,数据下载完毕、如何处理与爬虫无关,爬虫只负责下载
网站之间、网页之间是强关联的,通过超链接技术指向新的网页或网站。通过强关联特性,完成若干网页的拓扑跳转与处理
网页与网页之间有关联:出链接、入链接
理论上,通过一个有效的网页可以拓扑所有的网页。
爬虫在网页的工作:
-
获取资源
-
获取跳转地址(新链接)
二、网络资源的种类:
-
文本资源(txt,html,shtm,xml)
-
二进制数据(jpg,png,gif,bmp)
-
音频数据(mp3)
-
视频数据(mp4,rmvb,flv)
URL网络资源定位符,所有的网络资源,都有唯一的URL

三、关于B/S架构(浏览器/web服务器模型)
爬虫属于客户端,模拟浏览器行为,获取网站资源
使用http协议(基于TCP),只要获取了目标的端口和IP,可以直接对网站web服务进行连接
如果网站使用https协议(SSL),我们需要与网站进行安全连接openssl,否则无法与网站交互
① http协议的使用
② 正则表达式技术(html语言)
1)下载网页
2)提取关键数据
3)匹配更多新地址
爬虫的步骤:
1、下载资源
2、持续拓扑执行,获取若干资源
四、http下载
资源的下载流程(http 80,https 443):
(一)URL地址解析
-
资源完整的URL
-
协议类型
-
网站域名
cs
#include<netdb.h>
struct hostent* ent = gethostbyname(域名);
//ent->h_addr_list;地址表中存储指向服务的公网IP,大端序-
存储路径
-
资源名
-
端口
-
ip地址
cs
//Analytical_url.c
#include<spider.h>
int Analytical_url(url_t* url){
int flag=0;//遍历下标
int j=0;//写入下标
int start_len;//协议头长度
int fsize=0;//文件名长度
char* array[]={"http://","https://",NULL};
//初始化url中未使用数组
bzero(url->save_path,1024);
bzero(url->domain,1024);
bzero(url->file,1024);
bzero(url->ip,16);
//判定协议类型
if(strncmp(url->origin,array[0],strlen(array[0]))==0){
url->type=0;
url->port=80;
start_len=strlen(array[0]);
}
else{
url->type=1;
url->port=443;
start_len=strlen(array[1]);
}
//获取域名
for(flag=start_len;url->origin[flag]!='/';flag++){
url->domain[j]=url->origin[flag];
j++;
}
j=0;
//获取文件名长度
for(flag=strlen(url->origin);url->origin[flag]!='/';flag--,fsize++);
//获取文件名
for(flag=strlen(url->origin)-fsize+1;url->origin[flag]!='\0';flag++){
url->file[j]=url->origin[flag];
j++;
}
j=0;
//获取路径
for(flag=start_len+strlen(url->domain);flag<strlen(url->origin)-fsize+1;flag++){
url->save_path[j]=url->origin[flag];
j++;
}
//获取ip
struct hostent* ent=NULL;
if((ent=gethostbyname(url->domain))==NULL){
printf("gethostbyname fail\n");
exit(0);
}
inet_ntop(AF_INET,ent->h_addr_list[0],url->ip,16);
printf("spider [1] Analytical_url:\norigin:%s\ndomain:%s\npath:%s\nfile:%s\nip:%s\nport:%d\ntype:%d\n",url->origin,url->domain,url->save_path,url->file,url->ip,url->port,url->type);
}(二)网络初始化
cs
//Net_initalizer.c
#include<spider.h>
int Net_initalizer(){
int sock;
if((sock=socket(AF_INET,SOCK_STREAM,0))==-1){
perror("sock create fail");
exit(0);
}
printf("spider [2] sock create sucess\n");
return sock;
}(三)连接
cs
//Connection_web.c
#include <spider.h>
int Connection_web(int sock,url_t* url){
//构造网络信息
struct sockaddr_in webaddr;
webaddr.sin_family=AF_INET;
webaddr.sin_port=htons(url->port);
inet_pton(AF_INET,url->ip,&webaddr.sin_addr.s_addr);
if((connect(sock,(struct sockaddr*)&webaddr,sizeof(webaddr)))==1){
perror("connection failed");
exit(0);
}
printf("spider [3] connection sucess\n");
return 0;
}(四)资源下载
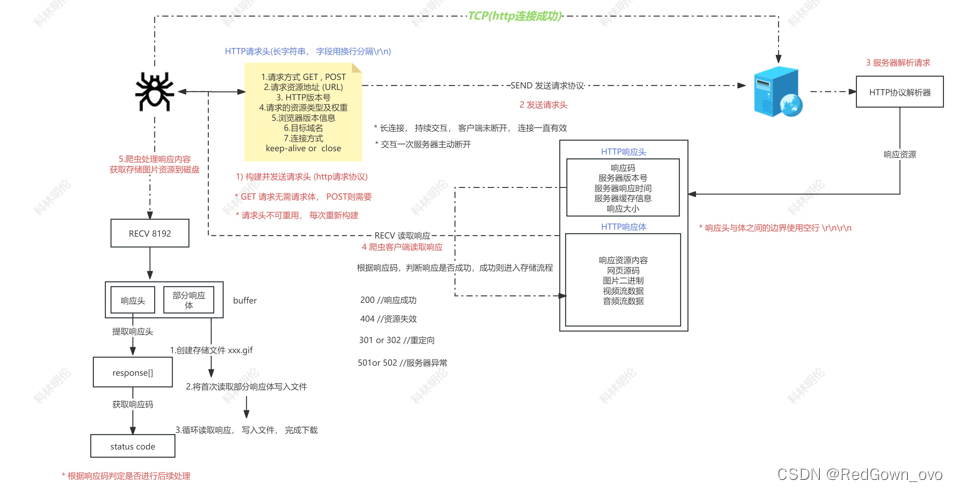
- 构建请求头(http请求协议)
页面请求方式:GET POST
请求资源权重:对于一个网页的性能和体验来讲,控制好请求发起的优先级是非常重要的,网络带宽是有限的,优先去加载重要的资源,让次要的资源延后,就可以让我们的网站体验提升一个台阶。
长链接:客户端主动连接,客户端主动断开
短连接:客户端主动连接,服务端主动断开,请求响应交互一次
cs
#include<spider.h>
int Create_request_str(char* request,url_t* node){
bzero(request,4096);
sprintf(request,"GET %s HTTP/1.1\r\n"\
"Accept:text/html,application/sgtml+xml;q=0.9,image;q=0.8\r\n"\
"User-Agent:Mozilla/5.0 (X11; Linux x86_64)\r\n"\
"Host:%s\r\n"\
"Connection:close\r\n\r\n"\
,node->origin,node->domain);
printf("spider [4] create_requeset:%s sucess\n",request);
return 0;
}-
发送请求头
-
服务器解析请求
-
爬虫客户端读取响应
根据响应码,判断响应是否成功,成功则进入存储流程
响应头一般都小于8192,为了一次完整的读完响应头,第一次读直接读8192。会读到完整的响应头和一部分响应体
HTTP/1.1 响应码 响应信息\r\n
cs
#include<spider.h>
int Get_response_code(char* response){
regex_t reg;
regmatch_t match[2];
int code;
char str_code[10];
bzero(str_code,10);
char* reg_str="HTTP/1.1 \\([^\r\n]\\+\\?\\)\r\n";
regcomp(®,reg_str,0);
if((regexec(®,response,2,match,0))==0){
snprintf(str_code,match[1].rm_eo-match[1].rm_so+1,"%s",response+match[1].rm_so);
}
sscanf(str_code,"%d",&code);
return code;
}- 爬虫处理响应内容获取存储资源到磁盘
cs
//Download.c
#include<spider.h>
int Download(char* request,int sock,url_t* url){
char buf[8192];
char response[4096];
bzero(buf,sizeof(buf));
bzero(response,sizeof(response));
int len;
char* pos=NULL;
int fd;
//发送请求头
if((send(sock,request,strlen(request),0))==-1){
perror("first send request faile");
return -1;;
}
printf("spider [5] send_requset sucess\n");
//首次读取响应
if((len=recv(sock,buf,sizeof(buf),0))==-1){
perror("firsr recv failed");
return -1;
}
if((pos=strstr(buf,"\r\n\r\n"))==NULL){
printf("strstr error\n");
return -1;
}
snprintf(response,pos-buf+4,"%s",buf);//提取响应头
printf("spider [6] Get_response head:%s sucess\n",response);
//提取响应码
int code;
code=Get_response_code(response);
if(code==200){
fd=open(url->file,O_RDWR|O_CREAT,0664);
//写入部分
write(fd,pos+4,len-(pos-buf+4));
bzero(buf,sizeof(buf));
while((len=recv(sock,buf,sizeof(buf),0))>0){
write(fd,buf,len);
}
close(fd);
printf("spider [7] %d download sucess\n",code);
}
else{
printf("spider [7] %d download fail\n",code);
close(sock);
return -1;
}
close(sock);
return 0;
} 五、https下载
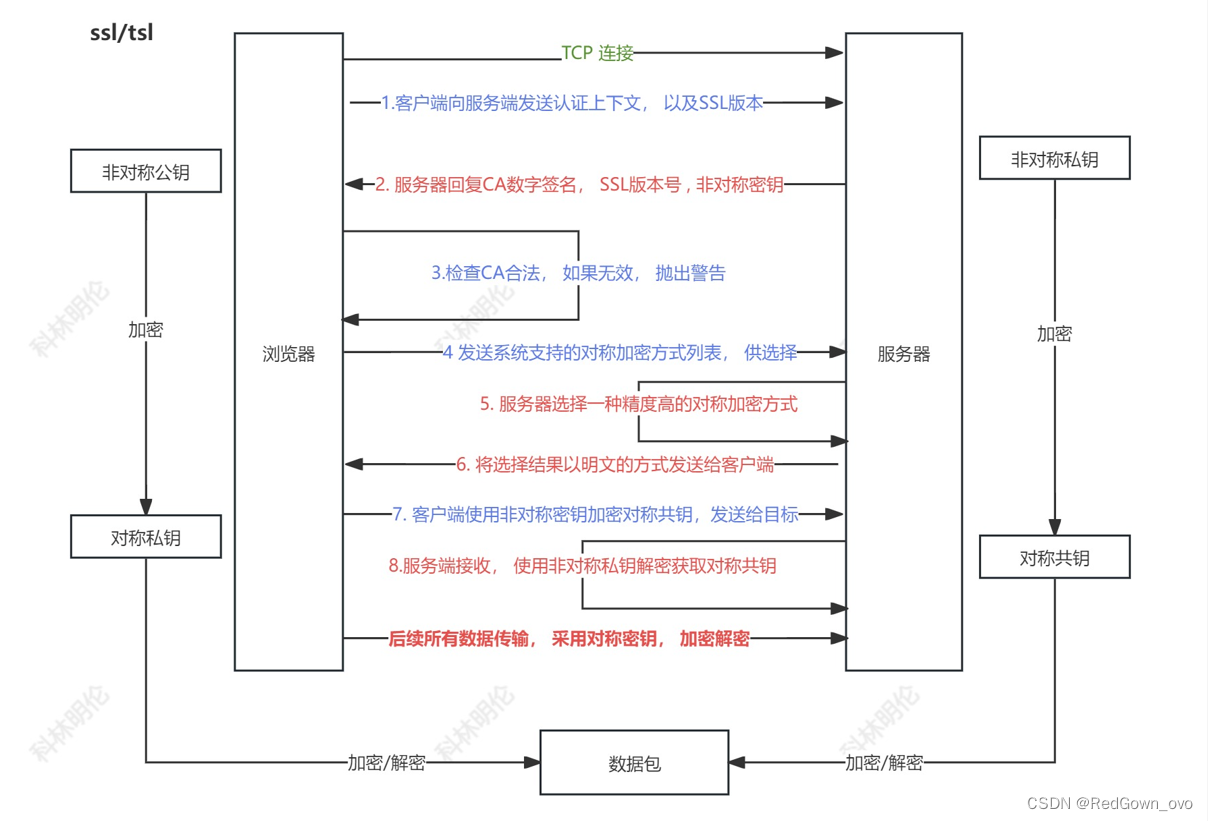
关于HHTPS协议,最大限度保证传输安全
openssl技术,可以完成https协议的安全认证
bash
sudo apt-get install libssl-dev
sudo apt-get install libssl-doc
man SSLhttp不安全,数据未加密保护,https如何改善?
-
https协议采用嵌套加密方式,最大限度保证传输安全
-
通过认证,让客户端验证服务器的CA数字证书,看是否有效
加密:
密钥对。多个公钥和一个私钥构成,密文串由128位随机码组成,保证唯一性
私钥加密数据,公钥解密
对称加密:安全性低,适合加密大段数据,速度快
非堆成加密(RSA):安全性高,适合加密小段重要数据,速度慢

https 单向认证
bash
gcc *.c -I ../include -lssl -lcrypto -o download
cs
//Openssl_init.c
#include<spider.h>
ssl_t* Openssl_init(int sock){
ssl_t* ssl=NULL;
if((ssl=(ssl_t*)malloc(sizeof(ssl_t)))==NULL){
perror("malloc ssl faile");
return NULL;
}
SSL_load_error_strings();//初始化错误处理函数
SSL_library_init();//初始化ssl库函数
OpenSSL_add_ssl_algorithms();//初始化加密散列函数
ssl->sslctx=SSL_CTX_new(SSLv23_method());
ssl->sslsock=SSL_new(ssl->sslctx);
SSL_set_fd(ssl->sslsock,sock);//使用tcp sock设置安全套接字
SSL_connect(ssl->sslsock);//发起https安全认证
return ssl;
}
cs
//Download.c
#include<spider.h>
int Download(char* request,int sock,url_t* url,ssl_t* ssl){
char buf[8192];
char response[4096];
bzero(buf,sizeof(buf));
bzero(response,sizeof(response));
int len;
char* pos=NULL;
int fd;
if(ssl){
//发送请求头
if((SSL_write(ssl->sslsock,request,strlen(request)))==-1){
perror("first send request faile");
return -1;;
}
printf("spider [5] HTTPS send_requset sucess\n");
//首次读取响应
if((len=SSL_read(ssl->sslsock,buf,sizeof(buf)))==-1){
perror("firsr recv failed");
return -1;
}
if((pos=strstr(buf,"\r\n\r\n"))==NULL){
printf("strstr error\n");
return -1;
}
snprintf(response,pos-buf+4,"%s",buf);//提取响应头
printf("spider [6] HTTPS Get_response head:%s sucess\n",response);
//提取响应码
int code;
code=Get_response_code(response);
if(code==200){
fd=open(url->file,O_RDWR|O_CREAT,0664);
//写入部分
write(fd,pos+4,len-(pos-buf+4));
bzero(buf,sizeof(buf));
while((len=SSL_read(ssl->sslsock,buf,sizeof(buf)))>0){
write(fd,buf,len);
}
close(fd);
free(ssl);
ssl=NULL;
printf("spider [7] %d HTTPS download sucess\n",code);
}
else{
printf("spider [7] %d HTTPS download fail\n",code);
close(sock);
free(ssl);
ssl=NULL;
return -1;
}
close(sock);
}
else{...}
return 0;
} 五、持续拓扑与下载资源
种子URL
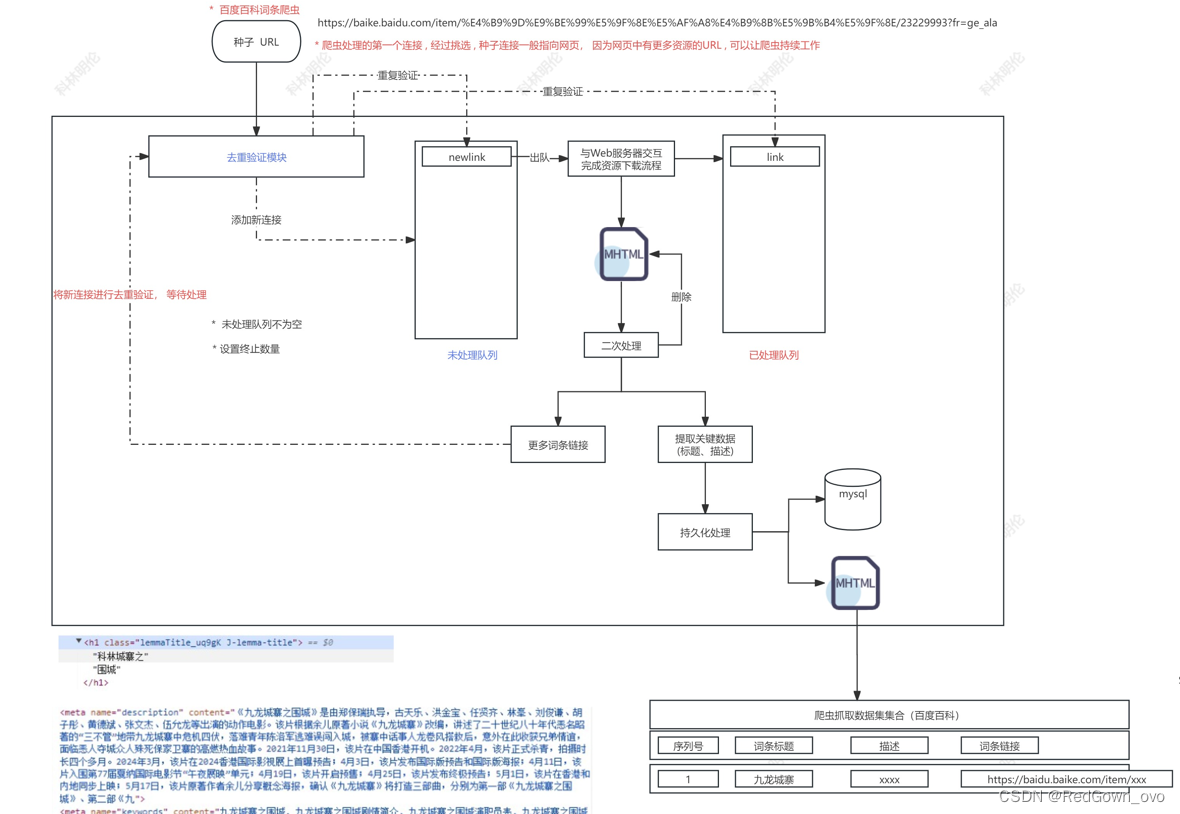


优化选项
1、DNS 优化

进程中自建缓存地址,便于后续的使用与访问,减少gethostbyname(开销大)的调用
2、去重优化
使用Hash表保存url,进行哈希去重。为了提高去重效率(哈希冲突),可以采用布隆过滤器。但是使用hash的内存占用问题无法解决
3、并发优化,线程池并发爬虫
获取更多时间片,提高爬虫的工作能力。随不能提高下载速度,但是可以多线程存储、多线程解析,缩减任务的完成时间
4、UA池 IP池
爬虫的抓取策略
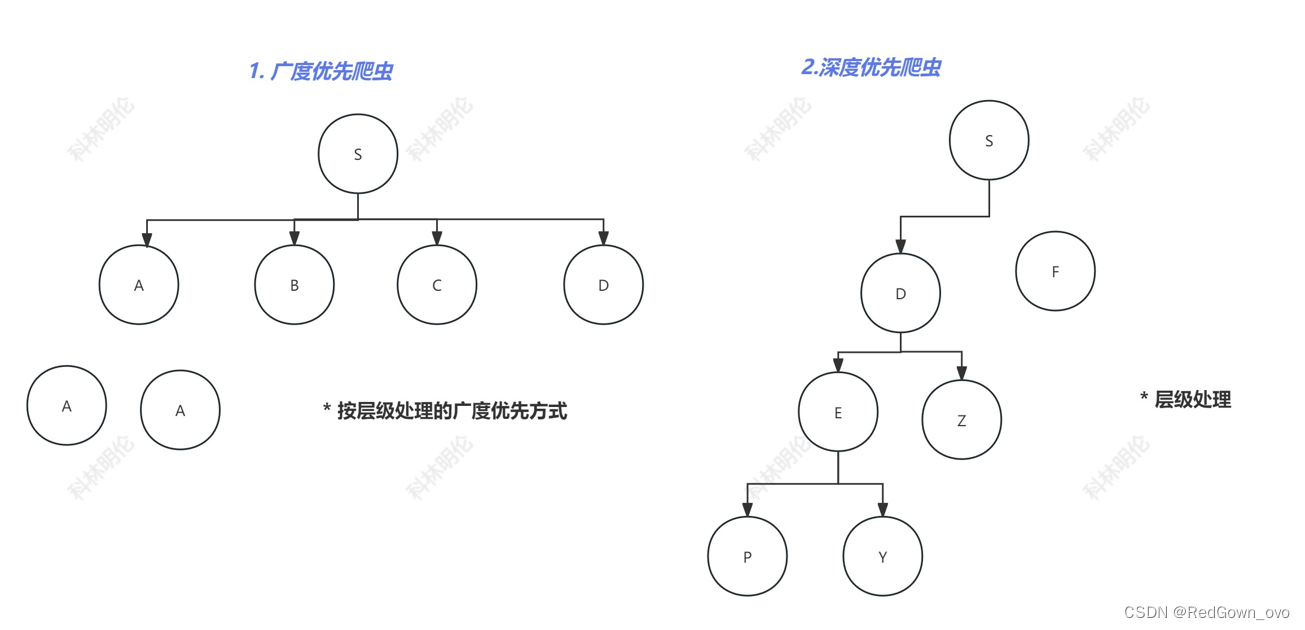
可以用图改变爬虫的工作方式
反爬虫机制

反反爬虫
