
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
每当我们精心设计的爬虫程序被目标网站的反爬机制拦截时,那种挫败感与解谜的渴望总是同时涌上心头。在这篇文章中,我将从实战角度出发,详细剖析目前主流的反爬策略原理,以及对应的破解方法和技术方案。
我曾在多个大型数据采集项目中与各种反爬系统正面交锋,从简单的User-Agent检测,到复杂的动态渲染和行为分析,每一次突破都让我对这个领域有了更深刻的理解。爬虫技术不仅仅是简单的HTTP请求,它更是一门融合了网络协议、浏览器原理、机器学习甚至心理学的综合艺术。当你站在开发者的角度思考如何保护网站数据时,你才能真正理解如何更有效地获取这些数据。
本文将系统地介绍从基础到高级的各类反爬技术,包括但不限于请求头验证、IP限制、Cookie追踪、动态渲染、行为分析等,并提供相应的破解思路和代码实现。我会尽量用通俗易懂的语言解释复杂的技术原理,并通过实际案例帮助你理解各种策略的优劣势。无论你是爬虫开发新手,还是有经验的数据工程师,相信这篇文章都能为你提供有价值的参考和启发。
在开始之前,我想强调的是:爬虫技术的应用必须遵守法律法规和网站的robots协议,尊重数据所有者的权益。本文所分享的技术仅用于学习和研究目的,希望大家在实践中能够秉持合法合规的原则。接下来,让我们一起深入探索这个充满挑战与机遇的技术领域吧!
一、基础反爬策略与破解方法
在介绍具体的反爬策略之前,让我们先通过流程图了解爬虫与反爬虫之间的基本交互过程:
验证通过 验证失败 成功 失败 爬虫发起请求 网站服务器 进行反爬验证 返回数据 拒绝访问/返回错误 爬虫尝试绕过 再次请求 放弃请求 爬虫提取数据
图1:反爬虫攻防流程图 - 展示了爬虫与网站服务器之间的交互过程,包括请求验证、数据返回和绕过策略的循环机制。
接下来,我们将详细介绍各类反爬策略及其对应的破解方法:
1.1 User-Agent验证
User-Agent是HTTP请求头中的一个重要字段,它标识了发起请求的客户端类型。许多网站会通过检查User-Agent来区分正常浏览器和爬虫程序。
反爬原理:服务器检查请求的User-Agent是否为常见浏览器的合法标识,如果不符合,则拒绝提供数据或返回错误页面。
破解方法:伪造合法的User-Agent字符串,或使用User-Agent池进行随机切换。
以下是使用User-Agent池的Python代码示例:
python
import requests
import random
# 定义一个常见浏览器的User-Agent池
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Firefox/109.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edge/109.0.1518.70",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
]
def get_random_user_agent():
"""
随机选择一个User-Agent
"""
return random.choice(USER_AGENTS)
def fetch_url(url):
"""
使用随机User-Agent发送请求
"""
headers = {
"User-Agent": get_random_user_agent(),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
return response.text
except Exception as e:
print(f"请求失败: {e}")
return None
# 使用示例
if __name__ == "__main__":
html_content = fetch_url("https://example.com")
print("获取到页面内容")关键点评:
- 第4-9行:定义了一个常见浏览器的User-Agent池,包含不同操作系统和浏览器的标识
- 第12-15行:随机选择一个User-Agent的函数,增加请求的随机性
- 第18-31行:使用随机User-Agent发送请求,同时设置了其他常见的请求头字段
- 这种方法可以有效规避简单的User-Agent检测,但对于更复杂的反爬系统可能需要更高级的策略
1.2 IP限制策略
IP限制是最常见的反爬手段之一,通过监控和限制单个IP的访问频率来识别和阻止爬虫。
反爬原理:服务器记录每个IP的访问频率,当某个IP的请求频率超过阈值时,暂时或永久封禁该IP。
破解方法:使用代理IP池、IP轮换、降低请求频率等方法来规避限制。
下面通过时序图展示爬虫如何使用代理IP池来绕过IP限制:
爬虫 代理池 目标网站 请求获取代理IP 返回可用代理IP列表 选择一个代理IP 使用代理IP发送请求 返回正常数据 标记代理IP可用 返回403/验证码 标记代理IP不可用 请求新代理IP 返回新代理IP alt 请求成功 IP被封禁 代理IP失效 loop 每次请求
图2:IP代理池工作时序图 - 展示了爬虫如何从代理池获取IP、使用代理发送请求、处理不同响应结果并更新代理状态的完整流程。
以下是使用代理IP池和随机延时的Python代码示例:
python
import requests
import random
import time
# 代理IP池
PROXY_POOL = [
"http://123.45.67.89:8080",
"http://98.76.54.32:3128",
"http://111.22.33.44:8888",
# 更多代理IP...
]
def get_random_proxy():
"""
随机选择一个代理IP
"""
return random.choice(PROXY_POOL)
def fetch_url_with_proxy(url, retry=3):
"""
使用代理IP和随机延时发送请求
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
}
for i in range(retry):
# 随机延时,模拟真实用户行为
time.sleep(random.uniform(1, 5))
# 选择随机代理
proxy = {"http": get_random_proxy(), "https": get_random_proxy()}
try:
response = requests.get(url, headers=headers, proxies=proxy, timeout=10)
if response.status_code == 200:
return response.text
else:
print(f"代理 {proxy} 返回状态码: {response.status_code}")
except Exception as e:
print(f"代理 {proxy} 请求失败: {e}")
# 指数退避策略
time.sleep(2 ** i)
return None
# 使用示例
if __name__ == "__main__":
html_content = fetch_url_with_proxy("https://example.com")
if html_content:
print("使用代理获取到页面内容")关键点评:
- 第4-9行:定义了一个代理IP池,可以根据实际情况添加更多代理
- 第12-15行:随机选择一个代理IP的函数
- 第24行:随机延时1-5秒,模拟真实用户的浏览行为
- 第27行:为HTTP和HTTPS请求分别设置代理
- 第35-36行:实现指数退避策略,每次失败后等待时间翻倍
- 这种方法通过IP轮换和行为模拟,可以有效规避大部分基于IP的限流机制
1.3 Cookie追踪机制
Cookie是网站用于识别用户身份和会话状态的重要工具,也常被用于反爬。
反爬原理:网站通过Cookie跟踪用户的浏览行为,如果发现异常模式(如过快的页面跳转),则判定为爬虫并进行限制。
破解方法:维护Cookie池、模拟正常的浏览器会话、合理管理Cookie生命周期。
以下是维护Cookie池和会话管理的Python代码示例:
python
import requests
import random
import time
from collections import defaultdict
class CookiePool:
def __init__(self):
"""
初始化Cookie池
"""
self.cookies_pool = defaultdict(list) # 域名 -> cookies列表
self.cookies_status = {} # cookie标识 -> 状态
def add_cookie(self, domain, cookies, identifier=None):
"""
添加Cookie到池中
"""
if identifier is None:
identifier = f"{domain}_{int(time.time())}"
self.cookies_pool[domain].append((identifier, cookies))
self.cookies_status[identifier] = "active"
return identifier
def get_random_cookie(self, domain):
"""
从池中随机获取一个Cookie
"""
if domain not in self.cookies_pool or not self.cookies_pool[domain]:
return None
active_cookies = [(id, cookies) for id, cookies in self.cookies_pool[domain]
if self.cookies_status.get(id) == "active"]
if not active_cookies:
return None
return random.choice(active_cookies)[1]
def mark_cookie_invalid(self, identifier):
"""
标记Cookie为无效
"""
if identifier in self.cookies_status:
self.cookies_status[identifier] = "invalid"
# 使用示例
def fetch_with_session_and_cookies(url, domain, cookie_pool):
"""
使用会话和Cookie发送请求
"""
# 创建会话
session = requests.Session()
# 设置请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
}
session.headers.update(headers)
# 获取Cookie
cookies = cookie_pool.get_random_cookie(domain)
if cookies:
session.cookies.update(cookies)
try:
response = session.get(url, timeout=10)
# 如果遇到需要登录的情况,可能需要重新获取Cookie
if response.status_code == 403 or "login" in response.url:
print(f"Cookie可能已失效,需要重新获取")
# 这里可以添加重新获取Cookie的逻辑
return None
return response.text
except Exception as e:
print(f"请求失败: {e}")
return None
# 初始化Cookie池
cookie_pool = CookiePool()
# 添加一些示例Cookie
cookie_pool.add_cookie("example.com", {
"session_id": "abc123",
"user_token": "def456"
})
# 使用Cookie池发送请求
html_content = fetch_with_session_and_cookies(
"https://example.com/data",
"example.com",
cookie_pool
)关键点评:
- 第8-11行:
CookiePool类的初始化,使用字典存储不同域名的Cookie - 第14-21行:添加Cookie到池中的方法,为每个Cookie生成唯一标识
- 第24-37行:从池中随机获取活跃Cookie的方法
- 第40-43行:标记Cookie为无效的方法
- 第48-73行:使用会话和Cookie发送请求的函数,维护会话状态
- 第61-64行:检测Cookie是否失效的逻辑,遇到问题时可以重新获取Cookie
- 这种方法通过维护多个Cookie并合理管理它们的生命周期,可以有效规避基于Cookie的反爬机制
二、中级反爬策略与破解方法
随着爬虫技术的不断发展,基础反爬策略已经无法满足网站的需求。中级反爬策略采用了更加复杂的验证机制,需要爬虫工程师具备更多的技术手段来应对。
首先,我们来看一下不同级别的反爬策略在实际应用中的使用比例:
45% 30% 15% 10% 网站反爬策略使用比例 基础策略 (UA验证/IP限制) 中级策略 (动态渲染/验证码) 高级策略 (行为分析/加密) 复合型策略
图3:网站反爬策略使用比例饼图 - 展示了不同级别的反爬策略在实际生产环境中的应用比例,基础策略仍然是最广泛使用的方法。
2.1 请求头完整性验证
除了User-Agent外,网站还会验证其他HTTP请求头字段,确保请求看起来像是来自真实浏览器。
在详细介绍中级反爬策略之前,我们先来看一个不同反爬策略的对比表格:
| 策略类型 | 具体方法 | 反爬原理 | 实现复杂度 | 防御强度 | 破解难度 | 破解方法 |
|---|---|---|---|---|---|---|
| 基础策略 | User-Agent验证 | 检测是否为浏览器UA | 低 | 低 | 低 | 使用User-Agent池 |
| IP限制 | 限制单个IP访问频率 | 中 | 中 | 中 | 代理IP池+随机延时 | |
| Cookie追踪 | 验证Cookie有效性和一致性 | 中 | 中 | 中 | Cookie池+会话管理 | |
| 中级策略 | 请求头验证 | 检查完整请求头字段 | 中 | 中 | 中 | 构造完整请求头 |
| 动态渲染 | 浏览器端JavaScript渲染 | 高 | 高 | 高 | Selenium+无头浏览器 | |
| 验证码 | 人机交互验证 | 中 | 高 | 高 | OCR+深度学习识别 | |
| 高级策略 | 行为分析 | 分析用户行为模式 | 很高 | 很高 | 很高 | 模拟真实用户行为 |
| 自适应限流 | 动态调整限流规则 | 高 | 高 | 高 | 动态调整爬取策略 | |
| 分布式系统 | 多维度联合验证 | 很高 | 很高 | 很高 | 分布式爬虫架构 |
表1:常见反爬策略对比表 - 从多个维度对比了不同级别反爬策略的特点,帮助开发者根据实际需求选择合适的防护或破解方案。
反爬原理:服务器检查请求头的完整性和合理性,包括Referer、Accept、Accept-Language等字段的组合是否符合浏览器行为。
破解方法:构造完整且合理的请求头,模拟真实浏览器的请求模式。
以下是构造完整请求头的Python代码示例:
python
import requests
import random
from datetime import datetime
def generate_complete_headers(referer=None, accept_language="zh-CN,zh;q=0.9"):
"""
生成完整的浏览器请求头
"""
# 常见浏览器User-Agent列表
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/109.0"
]
# 生成随机Accept-Encoding
accept_encodings = [
"gzip, deflate, br",
"gzip, deflate",
"br;q=0.9, gzip;q=0.8, deflate;q=0.7"
]
# 构造完整请求头
headers = {
"User-Agent": random.choice(user_agents),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": accept_language,
"Accept-Encoding": random.choice(accept_encodings),
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Cache-Control": "max-age=0",
"TE": "trailers",
}
# 如果提供了Referer,则添加
if referer:
headers["Referer"] = referer
return headers
def fetch_with_complete_headers(url, referer=None):
"""
使用完整请求头发送请求
"""
headers = generate_complete_headers(referer)
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
return response.text
except Exception as e:
print(f"请求失败: {e}")
return None
# 使用示例
if __name__ == "__main__":
# 设置合理的Referer,通常是目标网站的主页
referer = "https://example.com"
html_content = fetch_with_complete_headers("https://example.com/data", referer)
print("使用完整请求头获取到页面内容")关键点评:
- 第6-39行:生成完整浏览器请求头的函数,包含了各种常见的请求头字段
- 第11-24行:随机选择不同的User-Agent和Accept-Encoding,增加请求的多样性
- 第27-35行:构造包含多个字段的完整请求头,模拟真实浏览器的行为
- 第49行:使用raise_for_status()检查HTTP错误状态码
- 这种方法通过构造完整且合理的请求头,可以有效规避基于请求头验证的反爬机制
2.2 动态渲染与JavaScript挑战
现代网站越来越多地使用JavaScript动态生成内容,这给传统的爬虫带来了挑战。
反爬原理:网站的核心数据通过JavaScript动态加载或渲染,静态HTML中不包含完整数据;有些网站还会使用JavaScript进行人机验证。
破解方法:使用Selenium、Puppeteer等浏览器自动化工具,或分析JavaScript代码直接获取数据源。
以下是使用Selenium模拟浏览器行为的Python代码示例:
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import random
def init_driver():
"""
初始化WebDriver,配置浏览器参数以模拟真实用户
"""
chrome_options = Options()
# 禁用自动化控制特征
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
# 设置窗口大小
chrome_options.add_argument("--window-size=1920,1080")
# 禁用扩展
chrome_options.add_argument("--disable-extensions")
# 禁用沙盒模式
chrome_options.add_argument("--no-sandbox")
# 禁用共享内存使用
chrome_options.add_argument("--disable-dev-shm-usage")
# 禁用图片加载(可选,根据需要)
# prefs = {"profile.managed_default_content_settings.images": 2}
# chrome_options.add_experimental_option("prefs", prefs)
# 初始化WebDriver
driver = webdriver.Chrome(options=chrome_options)
# 绕过WebDriver检测
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
return driver
def simulate_human_behavior(driver):
"""
模拟人类浏览行为
"""
# 随机滚动页面
for _ in range(3):
scroll_height = random.randint(100, 500)
driver.execute_script(f"window.scrollBy(0, {scroll_height});")
time.sleep(random.uniform(0.5, 2))
# 随机等待一段时间
time.sleep(random.uniform(1, 3))
def fetch_dynamic_content(url, wait_element=None, max_wait=10):
"""
使用Selenium获取动态渲染的内容
"""
driver = None
try:
# 初始化驱动
driver = init_driver()
# 打开页面
driver.get(url)
# 模拟人类行为
simulate_human_behavior(driver)
# 等待特定元素加载(如果指定)
if wait_element:
WebDriverWait(driver, max_wait).until(
EC.presence_of_element_located((By.CSS_SELECTOR, wait_element))
)
# 获取页面内容
page_source = driver.page_source
return page_source
except Exception as e:
print(f"获取动态内容失败: {e}")
return None
finally:
# 关闭浏览器
if driver:
driver.quit()
# 使用示例
if __name__ == "__main__":
# 目标URL和需要等待的元素
target_url = "https://example.com/dynamic-content"
wait_selector = ".dynamic-data-container" # 根据实际情况修改
# 获取动态内容
content = fetch_dynamic_content(target_url, wait_selector)
if content:
print("成功获取动态渲染的内容")关键点评:
- 第9-35行:初始化WebDriver的函数,配置了多个参数以避免被检测为自动化工具
- 第13行:禁用blink特性中的自动化控制检测
- 第32行:通过JavaScript修改navigator.webdriver属性,绕过常见的WebDriver检测
- 第38-51行:模拟人类浏览行为的函数,包括随机滚动和等待
- 第54-82行:使用Selenium获取动态内容的主函数,包含显式等待机制
- 第66-70行:等待特定元素加载完成,确保动态内容已经渲染
- 这种方法通过真实浏览器渲染,可以有效获取JavaScript动态生成的内容,并规避大多数基于客户端的反爬机制
2.3 验证码机制
验证码是一种常见的反自动化手段,要求用户手动识别和输入特定字符或完成特定任务。
反爬原理:在关键操作(如登录、注册、频繁访问)时要求用户输入验证码,阻止自动化程序。
破解方法:使用OCR技术自动识别简单验证码,或接入第三方验证码识别服务处理复杂验证码。
以下是使用Tesseract OCR识别简单验证码的Python代码示例:
python
import cv2
import pytesseract
import numpy as np
import requests
from io import BytesIO
from PIL import Image
def preprocess_image(image):
"""
预处理验证码图片,提高识别率
"""
# 转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊去除噪声
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 自适应阈值处理,将图像二值化
thresh = cv2.adaptiveThreshold(
blurred, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY_INV,
11, 2
)
# 形态学操作,去除小的噪声点
kernel = np.ones((2, 2), np.uint8)
processed = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel)
return processed
def recognize_captcha(image_path=None, image_url=None):
"""
识别验证码
可以从本地文件或URL加载图片
"""
# 加载图片
if image_path:
image = cv2.imread(image_path)
elif image_url:
response = requests.get(image_url)
image = Image.open(BytesIO(response.content))
image = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
else:
raise ValueError("必须提供图片路径或URL")
# 预处理图片
processed_image = preprocess_image(image)
# 使用Tesseract OCR识别文字
# lang参数可以指定语言,这里使用英文
# config参数可以添加Tesseract的配置选项
text = pytesseract.image_to_string(
processed_image,
lang='eng',
config='--psm 8 --oem 3 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'
)
# 清理识别结果,去除非字母数字字符和空白
text = ''.join(char for char in text if char.isalnum())
return text
def solve_captcha_in_login(username, password, login_url, captcha_url):
"""
在登录过程中自动识别和填写验证码
"""
# 创建会话
session = requests.Session()
# 获取验证码
captcha_text = recognize_captcha(image_url=captcha_url)
print(f"识别到的验证码: {captcha_text}")
# 准备登录数据
login_data = {
"username": username,
"password": password,
"captcha": captcha_text
}
# 发送登录请求
response = session.post(login_url, data=login_data)
# 检查登录是否成功
if response.status_code == 200 and "登录成功" in response.text:
print("登录成功")
return session
else:
print("登录失败,可能是验证码识别错误")
return None
# 使用示例
if __name__ == "__main__":
# 这里只是示例,实际使用时需要替换为真实的URL和凭证
LOGIN_URL = "https://example.com/login"
CAPTCHA_URL = "https://example.com/captcha"
USERNAME = "your_username"
PASSWORD = "your_password"
session = solve_captcha_in_login(USERNAME, PASSWORD, LOGIN_URL, CAPTCHA_URL)关键点评:
- 第9-27行:验证码图片预处理函数,通过灰度转换、高斯模糊、阈值处理和形态学操作提高识别率
- 第30-57行:使用Tesseract OCR识别验证码的函数,支持从本地文件或URL加载图片
- 第48-51行:Tesseract配置参数,限定识别字符集为字母和数字,提高准确率
- 第60-81行:在登录过程中自动识别和填写验证码的函数
- 对于复杂的验证码(如旋转字符、干扰线、背景噪点等),可能需要使用深度学习方法或第三方验证码识别服务
- 这种方法适用于简单的验证码,但对于高级验证码可能需要更复杂的处理或人工干预
三、高级反爬策略与破解方法
在探讨高级反爬策略之前,我们需要铭记一个重要原则:
"技术的力量应当与责任并行。爬虫技术的目的是合理获取公开数据,而不是滥用技术侵犯网站权益。真正优秀的爬虫工程师不仅懂得如何绕过反爬,更懂得如何尊重网站规则,实现共赢。"
这段引语来自网络爬虫领域的资深专家,提醒我们在提升技术能力的同时,也要坚守道德底线。
随着AI技术的发展,高级反爬策略已经从简单的规则判断发展到智能化的行为分析和自适应防御。这类策略通常需要结合机器学习、大数据分析等技术,实现对爬虫的精准识别和阻止。
下面通过XY图表展示不同反爬策略的防御强度与实现复杂度的关系:
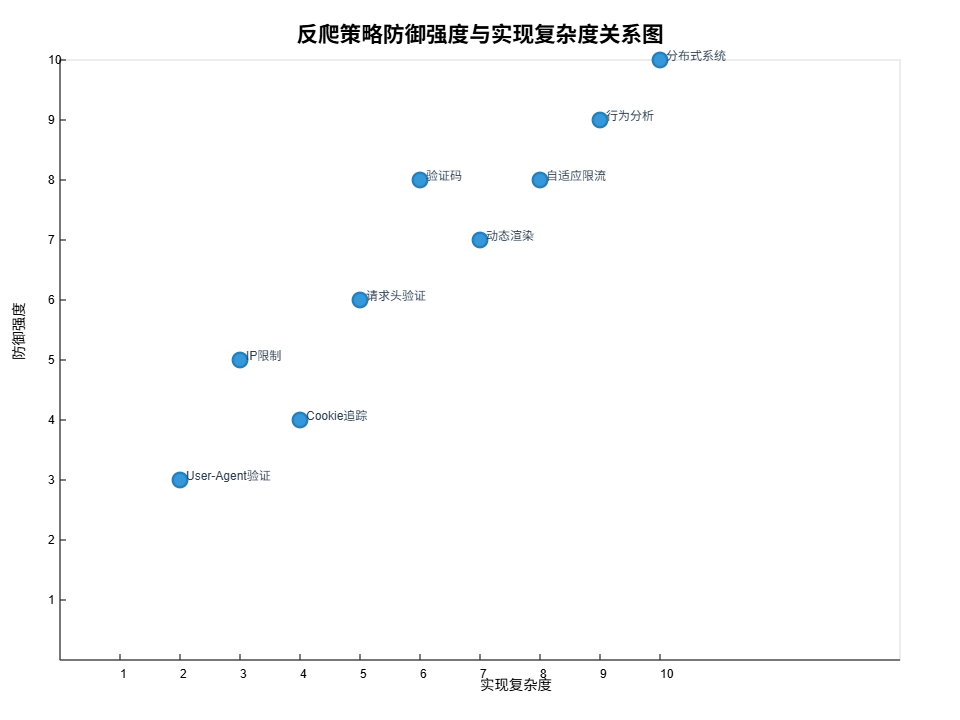
图4:反爬策略防御强度与实现复杂度关系图 - 展示了各类反爬策略在实现复杂度和防御强度两个维度上的分布情况,帮助开发者根据自身需求选择合适的策略组合。
3.1 行为分析与指纹识别
高级反爬系统会分析用户的行为模式和浏览器指纹,从而更精确地识别爬虫。
反爬原理:通过分析用户的点击、滚动、停留时间等行为模式,以及浏览器的各种特征(如Canvas指纹、WebGL指纹等),建立用户画像,识别异常行为。
破解方法:模拟真实用户的行为模式,修改浏览器指纹,使用无头浏览器的高级配置。
3.2 自适应限流与动态加密
一些高级反爬系统会根据访问情况动态调整限制策略,并使用加密技术保护数据传输。
反爬原理:系统根据实时流量和异常检测结果动态调整限流规则;API响应数据经过加密,需要在客户端解密后才能使用。
破解方法:实现智能调度和动态调整策略,逆向分析加密算法,模拟客户端解密过程。
3.3 分布式反爬系统
大型网站通常采用分布式的反爬系统,从多个维度对请求进行分析和过滤。
反爬原理:结合CDN、WAF、行为分析、机器学习等多种技术,构建多层次的防御体系,对请求进行全方位的检测和分析。
破解方法:采用分布式爬虫架构,使用真实浏览器集群,结合多种反检测技术,分散风险和压力。
四、反爬与反反爬的演进趋势
随着技术的不断发展,反爬与反反爬之间的博弈也在不断升级。从最初简单的请求头验证,到如今结合人工智能的行为分析,双方的技术手段都在不断创新。
在未来,我们可能会看到更多基于机器学习和深度学习的反爬技术,以及更加隐蔽和复杂的检测手段。同时,爬虫技术也会朝着更加智能化、分布式和模拟真实用户行为的方向发展。
作为爬虫工程师,我们需要不断学习和适应新的技术变化,同时也要坚守合法合规的原则,在技术探索和道德规范之间找到平衡点。
总结
在这篇文章中,我系统地梳理了从基础到高级的各类反爬策略,每一种策略背后都凝聚着网站开发者的心血与智慧。从简单的User-Agent验证,到复杂的行为分析系统,技术的演进速度令人惊叹。而作为爬虫工程师,我们也必须不断学习,保持技术的敏锐度,才能在这场没有硝烟的战争中保持竞争力。
然而,我想强调的是,技术永远只是手段,而不是目的。我们掌握这些破解反爬的技术,不是为了滥用,而是为了更合理、更高效地获取公开数据,从而创造更大的价值。在我看来,一名优秀的爬虫工程师应该具备三重境界:第一重是掌握基本技术,能够绕过简单的反爬措施;第二重是理解网站结构,能够智能应对各种复杂场景;第三重则是懂得尊重规则,在技术与道德之间找到平衡点。
记得几年前,我曾参与过一个数据采集项目,面对一家电商网站的高级反爬系统,我们尝试了各种技术手段都无法突破。最后,我们主动联系了网站方,说明了我们的需求和使用场景,经过协商,对方最终开放了部分API接口。这让我深刻认识到,沟通与合作有时比技术破解更有效,也更可持续。
展望未来,随着AI技术的普及,反爬与反反爬的博弈将会更加智能化。但无论技术如何发展,我始终坚信,保持开放、诚信的态度,尊重网站权益,遵守法律法规,才是爬虫技术长久发展的正道。愿每一位爬虫工程师都能在技术探索的道路上,既追求卓越,又不忘初心。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- Python官方文档 - 网络请求库 - 了解Python标准库中的网络请求相关功能
- Selenium官方文档 - 学习如何使用Selenium进行浏览器自动化
- Requests库GitHub - Python最流行的HTTP请求库
- Beautiful Soup文档 - HTML和XML解析工具
- Scrapy框架文档 - 功能强大的Python爬虫框架