一、简单理解认识apiserver
1.主要功能
认证
鉴权
准入
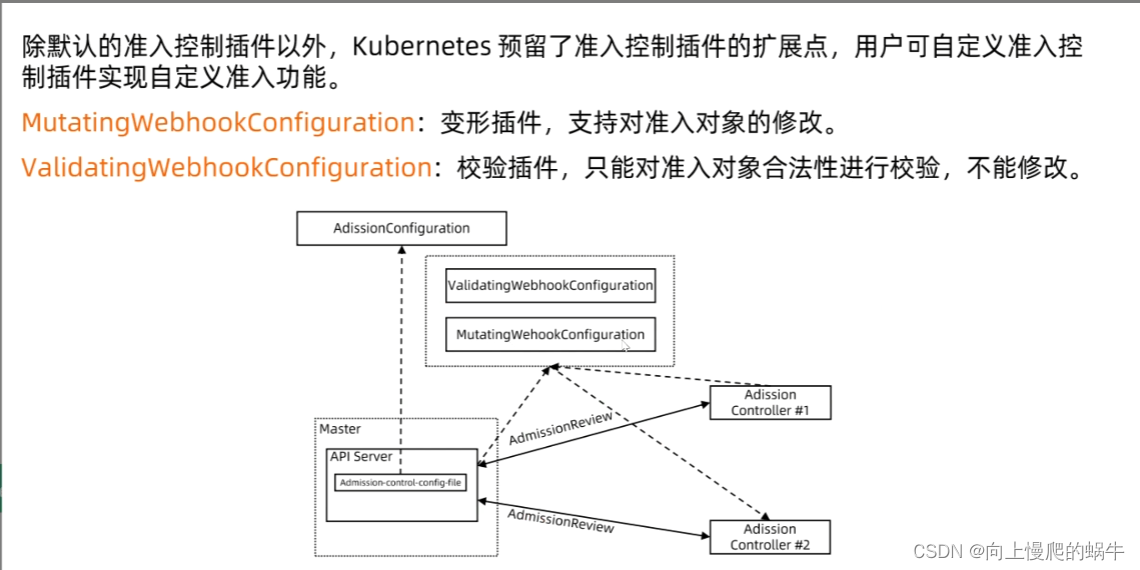
· mutating
· validating
· admission
限流
2.概念

apiserver保护etcd,缓存机制,有缓存直接返回,没缓存再去查看etcd,apiserver是担任和其他平台同信并认证
3.访问控制概览
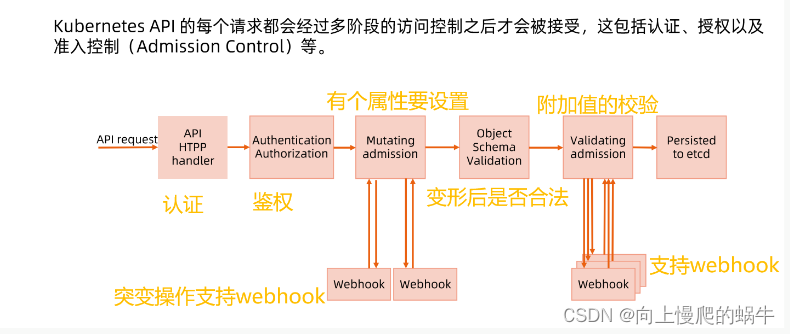
在进入之后,先注册api handler,然后会进入到认证(判断用户有没有访问我的权限)和鉴权(判定用户对我服务有没有请求权限),鉴权完之后,如果你对这个属性有其他设置,就进入到准入环节mutaing环节,这个环节要对对象进行变形,如:要设置一个pod,pod没有lables,在mutaing环节,development要控制rs,rs控制pod,rs去创建pod要求名称不能重复,所以要对pod进行随机数。可以简化通过webhook单独将mutating拎出来,自己开发mutaing插件完成资源的处理,将对象处理完成之后返回给下面流程(具体实践:传输数据时是以json格式去传输,在传输时,这个json字符串不去向api server传输,向webhook传输,在webhook里面将字符串进行二次处理,处理完之后,将字符串进行回传,然后让这个字符串继续进行后续动作),在进行突变之后查看名称、内容等是否合法,然后对一些附加值进行校验(数据范围是否合理、字符串类型是否合理,如果有很多集群,可以单拎出来,写一个插件,通过webhook进行统一实现回传),通过校验进入etcd实现落盘。
4.访问控制细节
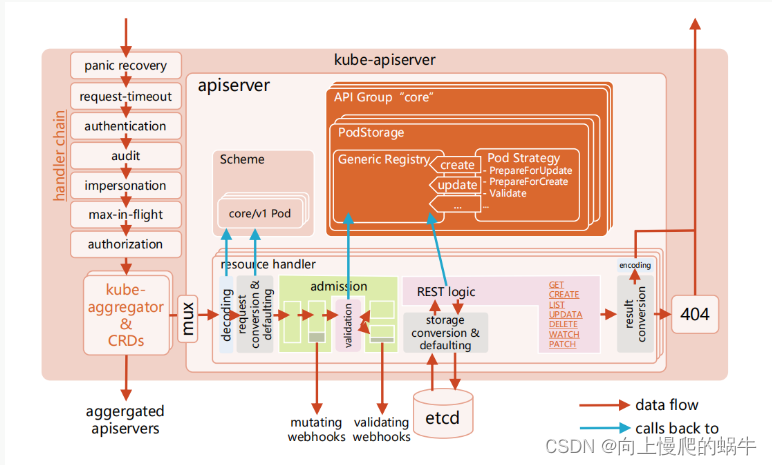
图解:
当代码进入首先执行panic recovery(作用是写一个服务的时候,不会因为一个问题导致你全部进行崩掉),然后进入request-timeout状态(请求的超时时间,会对请求设置一个缓存,设置缓存保存多长时间就是它决定的), 然后进入认证authentication,然后进入audit 审计,然后impersonation 开始做数据传输是http协议,针对header过来的时候加一点信息,集群联邦过来的时候改一点信息,max-in-flight做限流的,多少在路上,上限是多少,是否拒绝,然后是鉴权(某些用户对某些资源进行相应的操作),然后kube-aggregator&crds这里是判断request是不是标准的k8s对象,判断不是的话进入其他处理,是的话,先默认进入decoding
总结:
panic处理,不会因为某个携程panic干掉进程
audit 审计的必要性
impersonation暂时理解为一大堆k8s集群, 开始做数据传输是http协议,header过来的时候加一点信息,集群联邦过来的时候改一点信息
max-in-flight:做限流的,多少在路上,上限是多少,是否拒绝
鉴权
kube-aggregator&crds这里是判断request是不是标准的k8s对象,是的话,判断不是的话
json做反序列化为go的对象
做conversion
internal version
external version
先internel,然后admission,先webhook,没就内置validating
然后内部处理
附加validating 看有没有webhook
准入后进入etcd,然后还有个restlogic是做缓存的
二、apiserver的认证机制(你谁啊你)
1.认证概念
 insecure port(认证鉴权都是不走的,直接进行准备控制)
insecure port(认证鉴权都是不走的,直接进行准备控制)
secure port
2.认证插件

serviceaccount在进行认证时用的是token

生产化落地--认证集成

3.认证方式演示
4.基于webhook的认证服务集成
参考链接https://github.com/kubeguard/guard
集于webhook集成的一段代码

做数据传输时,apiversion这段是实际获取的东西,实际获取的东西是从外部的webhook获取的,从webhook读取到认证信息之后,根据用户和身份信息生成一个bearertoken,在注回到原来的信息中,在将其传回本地的api server中。
外部使用webhook使用的代码:




实际文档(认证规范):

5.生产过程中遇到的陷阱
很多问题都是发生在23年以前的,社区在高速发展的过程中中可能有逐渐成型的解决的方案
但还是要分享出来拓宽大家的思路

在k8s中访问接入时,要一堆循环做访问,假如是namespace请求,会向api server请求信息,假如用token做认证(token是有有效期的,一旦过了有效期就要重新颁布,这个颁布也需要时间,一个资源对象在0.1s失效可访问20次,对于集群来说能延就不丢)
三、apiserver的授权机制(你凭啥啊你)
1.授权
如果认证过程中授权失败,会返回一个http的403

授权方式ABAC和RBAC
ABAC:基于属性的访问控制,不依赖于预定义的角色,根据主体、操作、属性、环境来决定的来访问的,时间、地点、网络这些策略的设置,系统会收集主体资源、环境和属性,主体访问资源,系统会查看属性,根据先定义的策略对这些属性进行评估,如果策略是通过评估允许访问,才会授予访问权限,否则会拒绝访问。做ABAC通常要停服,相较于ABAC,RBAC在集群中更加符合集群中对资源管理的方案

2.RBAC
普遍的RBAC认知
可以新画一个流程图来解释角色,权限,绑定关系
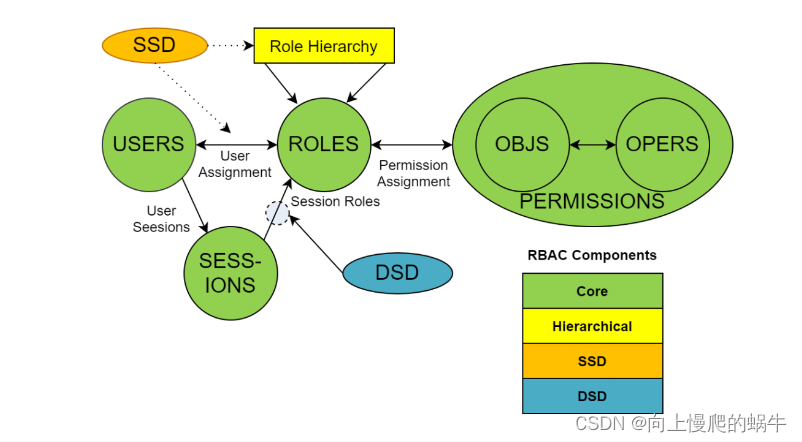
用户要访问集群中的某个资源,需要设置一定的权限,角色对权限有需求、用户对角色有需求,并进行绑定,这种访问时灵活的,可以随意改变用户底下所绑定的角色,而不用专门为集群设置一个具有权限的角色
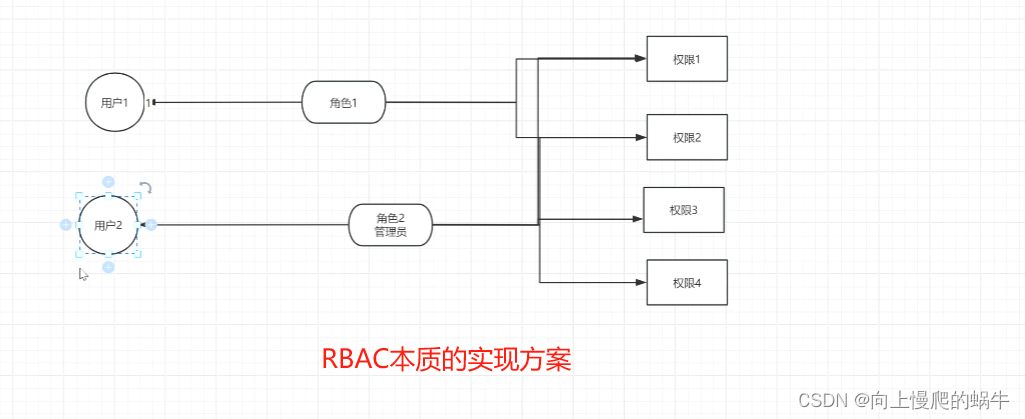
kubernetes的RBAC
这个得画图解释一下clusterroles和非cluster,比如说可不可以使用rolebinding绑定clusterrole

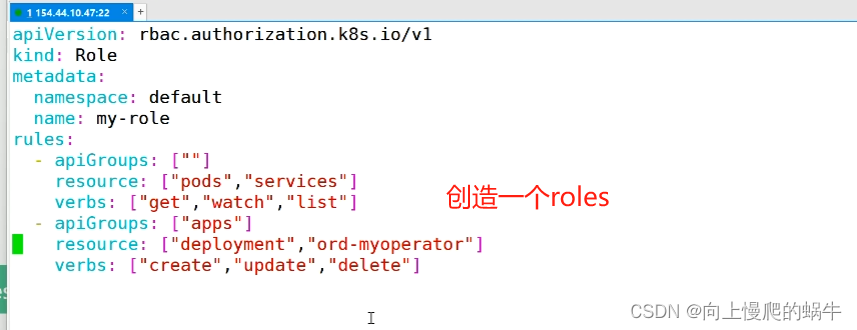
rolebings:角色绑定,role:设置权限,在某个namespace中生效,clusterRole:设置权限并全局生效
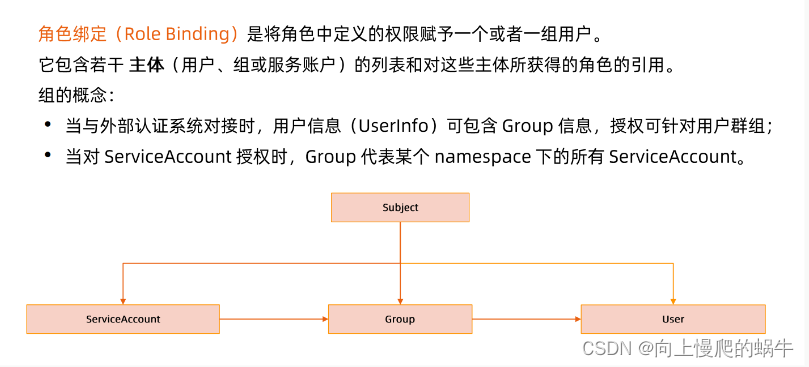
假设是一个主集群,在逻辑上时通过namespace来划分资源和部门,roles就是在其中一个namespace设置一个角色roles(可以对资源进行控制),如果某个用户想在你的namespace访问资源,需要再namespace中设置rolebings,通过rolebings绑定给你认证通过的用户user/group。对所有集群进行管理的人为clusterRole,可以通过clusterbing去绑定一个角色。user/group是从subject中选择的,subject中含盖了user/group,user/group从rolebing发生一个角色和用户的绑定关系,角色中所含的权限有roles所定义。


不用写namespace,因为其是全局生效的
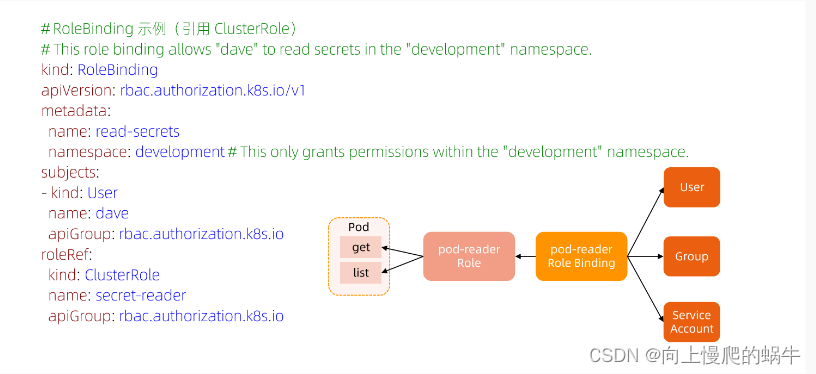
kind:rolebing绑定对象,在subject中定义和那个用户发生关系,在k8s中必须有这个用户进行绑定,不能和随意一个用户绑定
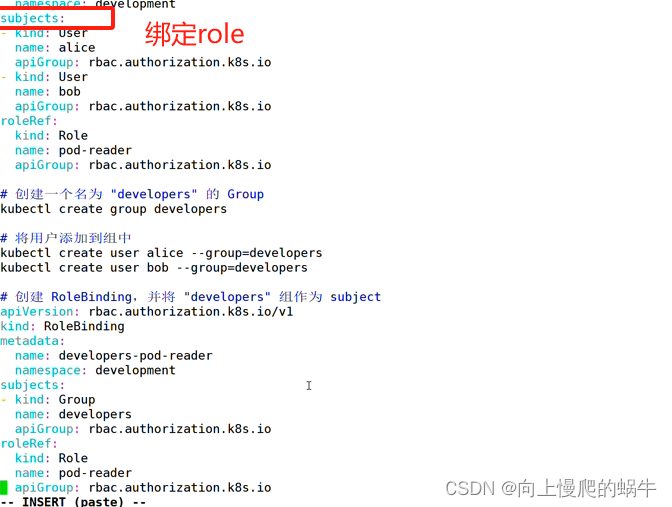
3.账户/组的管理
在角色绑定时可以是一个user、group、serviceaccount

4.规划系统角色

管理员权限得有多大,比如能不能看用户的安全相关的信息,
租户的配置,如强隔离场景,只关心自己的ns,
或者弱隔离,相信每个用户,可以read all,只保证自己的业务不被破坏
当你入职的时候应该能做哪些操作
权限是不是越高越好
这里做授权的演示视频
大家一定要对生产系统怀有敬畏,通过RABC给其一个强隔离
最好更改代码,将源文件进行注释,你在重新写
5.自动化实现方案
apiserver能收到user info信息,提出来后数据处理存一个变量



6.注意避坑


基于k8s的扩展功能,当你定义一个新的对象进去,新的对象和传统对象并不是同一类资源,之前设置的资源很可能忘记对这个资源的操作
四、apiserver的准入控制(你行不行啊你)
1.使用场景
对ns做资源配额
限制了qos,没限制besteffort
怎么做自动化
resourcequota的实验

resourcequota:可以限制创建的configmap,还可以限制创建多少个pod、service、ingress、service vip。

进行资源的限制,怎么做到自动化?
在创建 RBAC的时候,在创建一个resourcequota资源对象,这个对象对当前集群所用的资源进行限制,但是创建的时候,你需要把这个资源对象从你的RBAC中排除出去,以免租户可以控制这个对象

2.准入控制的插件
建立pod的时候可以通过准入插件扫一下镜像是不是安全扫描通过了
k exec -it -n kube-system kube-apiserver-master1

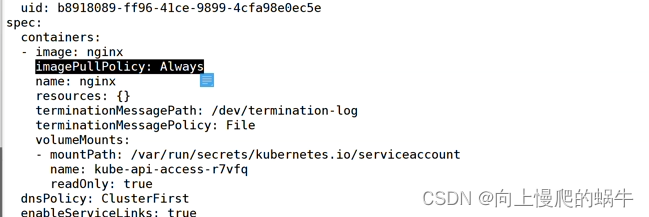
always:每次遇到镜像拉取都是从远端拉取
ifNotPresent:如果找不到镜像,才进行拉取
Nerver:只用本地的镜像,从不向远端拉取
上面选项实际上是将iamgepullpolicy置为always

3.webhook准入插件自研
现在的突变已经很简单了
如果要开webhook必须要开https
注意这里的caBundle是要填写的,就是证书做一次base64加密
流程:
api server开启了要做webhook的变形插件,插件会向远端服务器去做访问,查看你的adission是啥,有多种行为,查看这种行为对你的服务进行哪种变更,如果是变更执行变更操作,是更新就执行更新操作。如果要做变型要开启变型插件,非变型对象validatingwebhookconfigration就是做校验的

远端如果配置好webhook,这里只需要配置apiversion,如果设置好,ca认证记的放好证书,URl是必写的

五、apiserver的限流方法
1.常用的传统速率的限制算法
监听时间循环的同时要计算其流量,来确认它的流量是多少,当流量超过一定限制之后,访问给其拒绝,知道循环机制监听到下一个窗口,再去看如何处理这些访问请求


内存挤压直接om,这种方式有弊端,因为颗粒度太粗,会经常发生局部挤压,
算法:
假设一个网络接口使用计数器固定窗口算法进行流量控制,窗口大小设置为total个数据包,窗口时间设置为win_lenth秒。
窗口为1s
如果在第一秒内发送了pkg1个数据包,第二秒内发送了pkg2个数据包,第三秒内发送了pkg3个数据包...一共5秒,请计算每个时间窗口结束时的流量是否超出限制,超出延时顺延2秒,在过则丢弃,如果超出请输出第n秒有延时,实际处理时间需要多久。
使用shell实现该计算过程
要求:
输入:
第一行读入100 1
第二行读入 90 170 80 120 60
输出:
第x x x秒有延时,总耗时x秒处理完成
总结:
判断第ns有延时,因为其有超时2s的需求,所以对每个窗口来说,需要用三个窗口来储存,储存数值分别是第一窗口的延时、第二个窗口的延时、本窗口的延时,只要写三个窗口进行判断,就知道每个窗口期处理数据包是个怎么样的分布状态,然后关于总耗时x秒完成(这个只和前两个窗口有关,只需要判断前两个窗口有没有发生过包处理,就可以判断总耗时几秒完成)

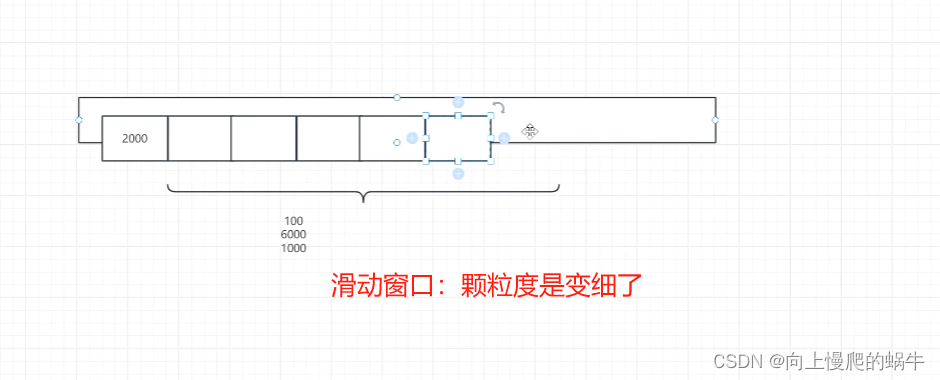
此方法是为了解决颗粒度过粗的问题,每过1s就往后移动一个窗口,这样颗粒度就从1min变成1s,
这种情况下,如果qbs保证是1w,第1个窗口过了一定的服务保证,过了一定包的时候,那么在这个窗口期内就不会增添数据了,相较于固定窗口,颗粒度是细了,但是并没有解决流量挤压这个问题,将时间无限放大来看,这个窗口期是非常大的
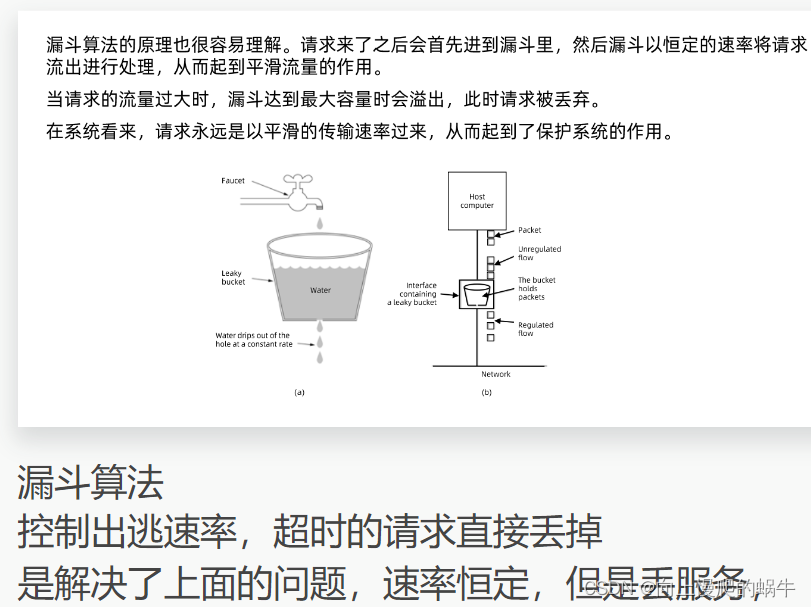
这个漏斗算法有延时,会积压请求,很容易丢请求,就是再急也得等等,而令牌算法解决了这种弊端

有弊端:多租户请求,租户一直发请求,一个用户直接把令牌都拿走,其他用户就拿不了令牌
2.apiserver的限流机制
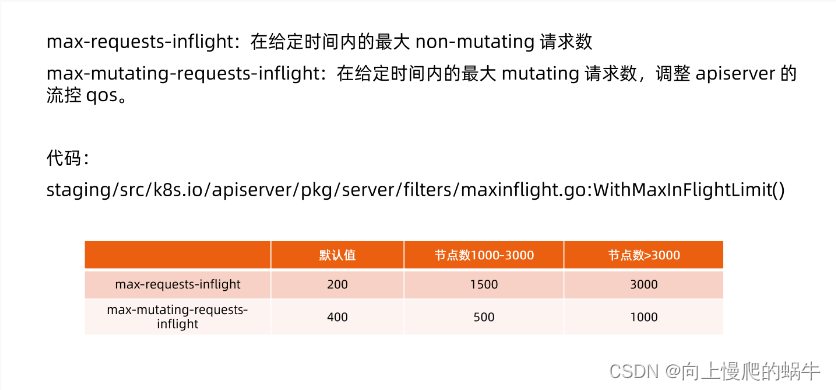
同样时间内,给的并发数过少咋整,请求遭拒,请求受缓,延时比较长,不利于服务质量保证。
请求过大,并发数太大容易把api server打崩
3.传统限流方法的局限性

4.API Priority and Fairness(APF算法)
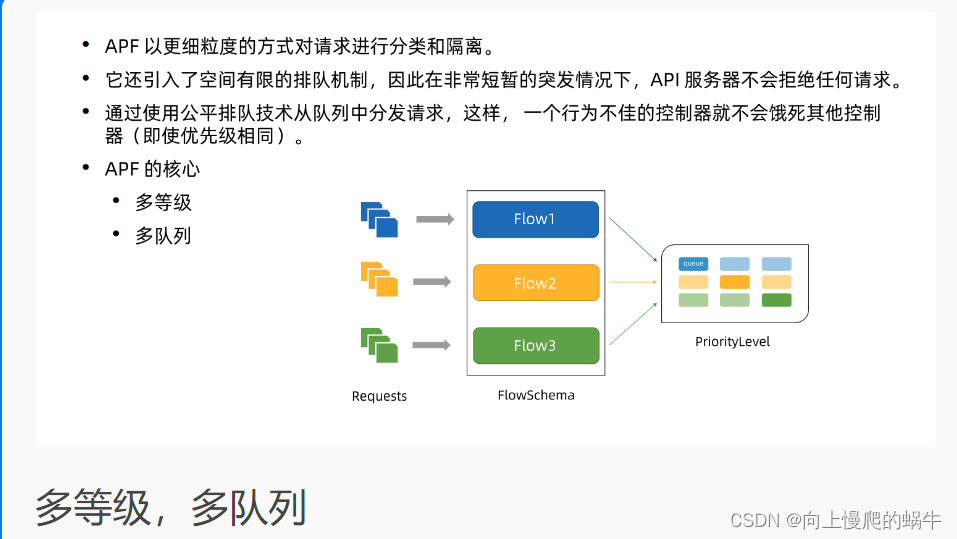
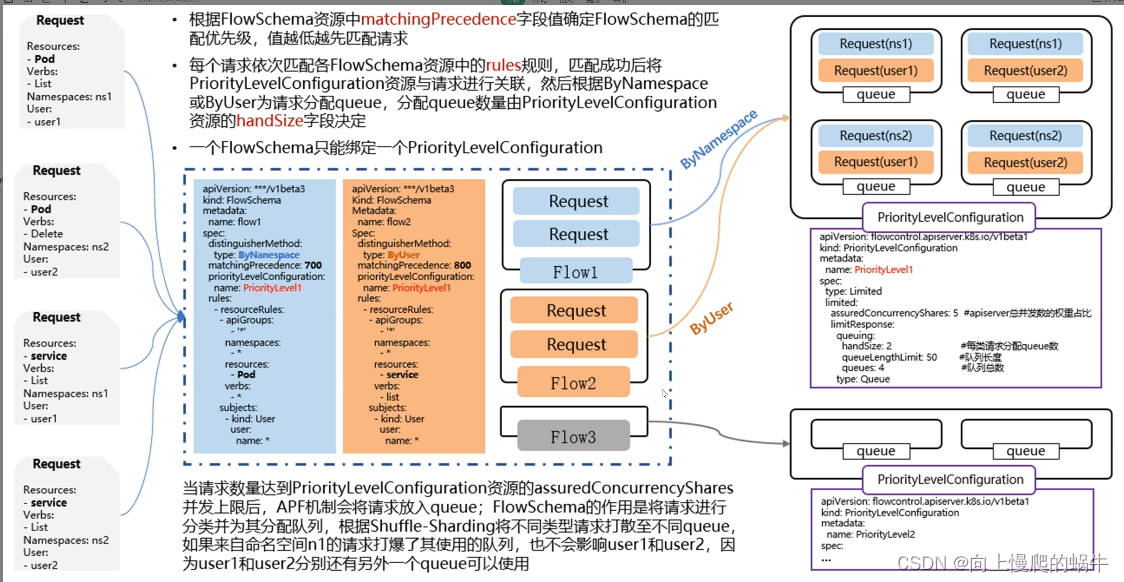
每张表都有优先级,从0到n,越靠近0的优先级变大,每张表单对应一个流,流里面可以自己设置有多少个管道,也可以设置每个管道中可以缓存多少东西,所以当一个请求来的时候,先去匹配表,然后根据标的规则查看匹配那个流,然后再流里面按照优先级规则去匹配那个管道资源,每一个请求都占对应的一个管道,按照管道的空闲程度做处理,这就是api 算法
针对恶意用户,需要设置多个管道
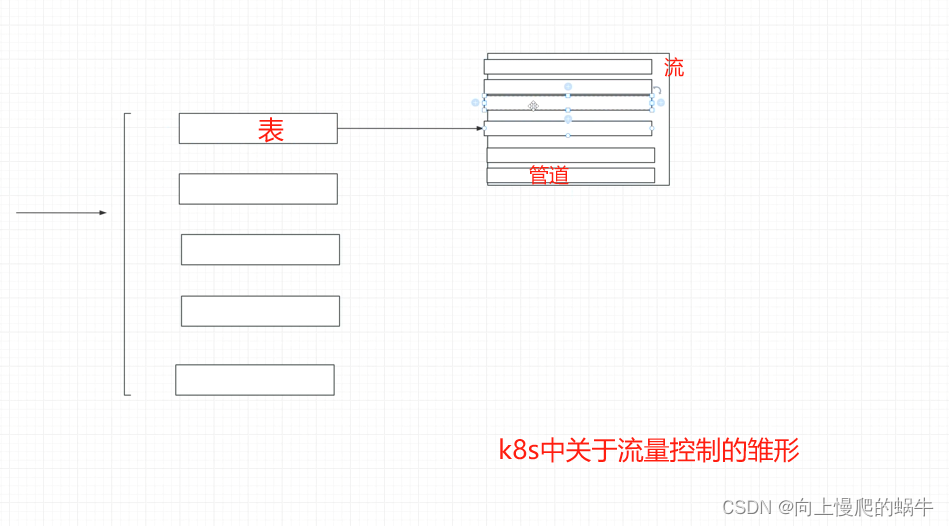


apf算法的概念,整个的工作机制
每个优先级维护自己的并发限制
限制了问题的影响,不会因为一个打满饿死了其他队列的





思考,流量来自于哪里,我们要控制的是对谁的流量
保护内部之间的流量,和控制web进来的流量。
总结:
①curl一些其他的网络手段访问你的api server资源
②集群内部的资源如果访问失败,它会对你的api server发生reset服务,如果这个服务没做指数级的递增,也会发生攻击现象
③攻击api server时,顺带把etcd击穿,看似攻击api server,实际在攻击etcd。如:注入一些非常大的对象,实质用k8s内部某些流量的特性来攻击kublets,不论是直接攻击api server,还是通过k8s特性攻击,所以控制流量首先来自外来租户请求、其次内部的资源(具有控制器可以循环访问的这类资源)
5.限流必须掌握的资源对象(FlowSchema和PriorityLevelConfiguration)
默认配置1:
默认配置2:



如果都能匹配到match,就会看优先级,谁比较高,如:400、500,先走优先级高度flowschema,去看其绑定的prioritylevelconfigration,然后进行读取,可以看到queues(管道)、handsize(队列)
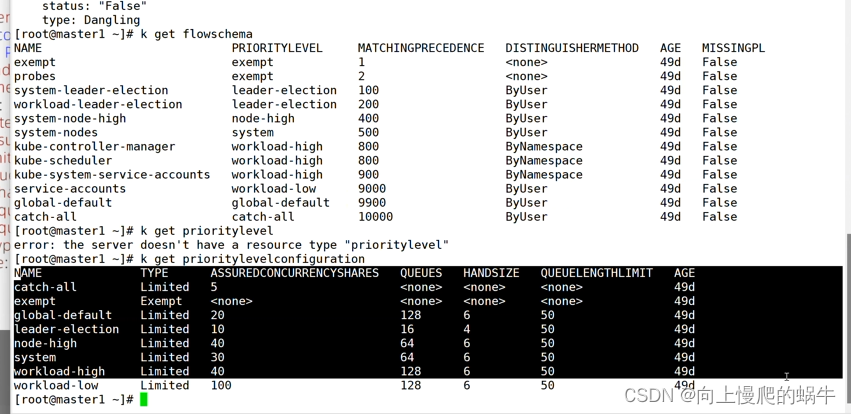
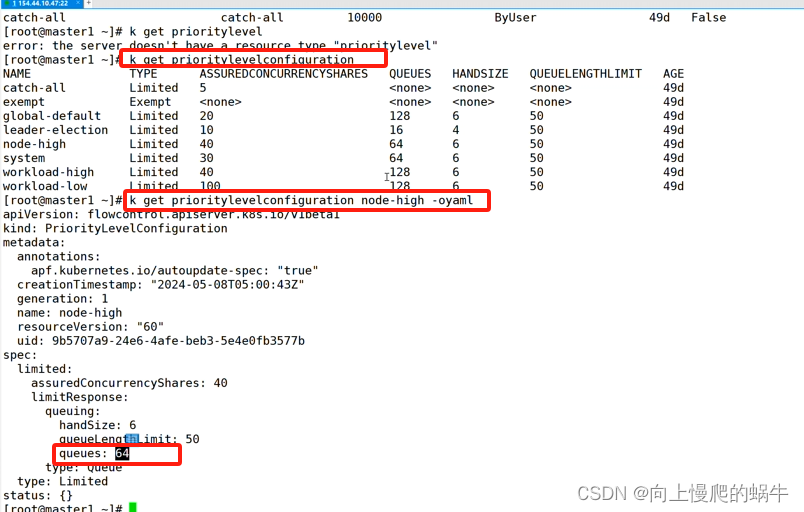
APF的常用的控制命令:

APF的工作细节:
六、高可用apiserver
1.apiserver启动参数示例
rest server(无状态):显著特点,做高可用部署几个都没问题,做冗余部署

2.构建高可用的多副本apiserver

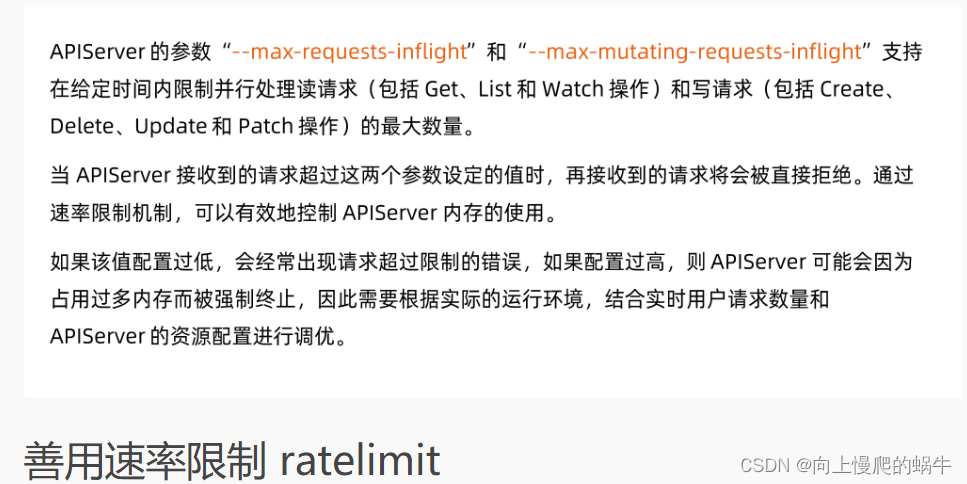
速率控制,一个是控制总的读写数量,另一个是控制写请求的数量,因为写请求数量比读的数量是消耗多的,在进行总的请求之后,可以使用API分片算法,对流量进行一个细化的管理,通过这两种手段,服务器是有一定健壮性


空间换时间的一种手段


3.流量入站需要考虑的事情
思考如何访问apiserver


认证


4.构建生产化集群要考虑的事情
规划系统角色user 、systemAccount

注意把敏感信息进行剔除

通过本地集群认证,通过webhook认证手段实现自动化

